Preparing for serverless big data open source software
Susheel Kaushik
Group Product Manager
Big data open source software (OSS) like Apache Hadoop, Apache Spark, Presto, and others continue to become industry-standard in enterprise data lakes and big data architectures. As enterprises turn to on-prem OSS deployments to avoid vendor lock-in, lower costs, and harness the power of community innovation, they struggle to balance the requirements of the enterprise (security, SLAs, etc.) with the needs of the business. We’re at a moment of change in this industry, and our Dataproc platform offers a way forward to manage, analyze and take full advantage of your data and the OSS systems you’re already using.
It all started with on-prem deployments of Apache Hadoop in 2010, which left much to be desired as big data architects had to work with rigid machines that couldn’t scale independently, and required significant tuning and testing. They couldn’t tell if the next spike in data or the next OSS release would break pipelines or queries. Then the cloud came along and solved many of these issues. With the launch of Google Cloud’s Dataproc in 2015, enterprises could now decouple compute from storage and allow custom OSS clusters to be built with custom machines. Automating the cluster build and scaling avoided common on-prem challenges and helped set our customers up for the next massive transition in OSS: serverless.
Before we examine the serverless future, let’s first discuss where the industry started and where we are today.
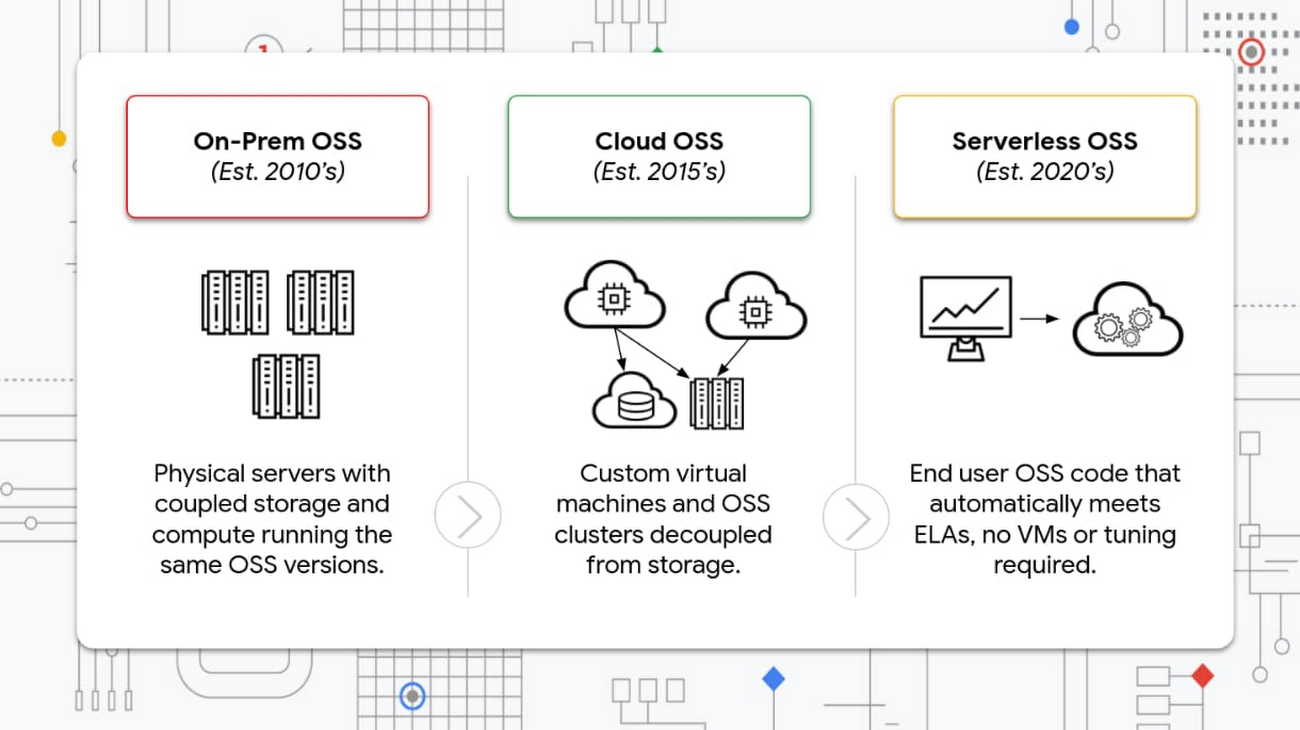
On-prem OSS: Where we started and the challenges
Big data open source software started with a mission to simplify the hardware setups for clusters in the data center and minimize the impact of hardware failures on data applications. Big data OSS also delivers cost optimizations by simplifying management and efficiently utilizing all available resources, while also taking advantage of innovation across the open source community. These strategies must be used cautiously so you don’t prohibit developers’ freedom in leveraging underlying hardware any way they see fit without data center reconfiguration.
Instead of the traditional approach of bringing the data to the processing, early versions of big data analytics changed the processing paradigm by bringing the processing to the data. Other design simplifications allowed the data center team to focus on setting up interconnected racks of commodity servers running Linux. These racks were then handed over to big data developers so that they could configure and optimize their data application processing environments. Hadoop, a key big data open source component, implemented a distributed file system and processing framework (MapReduce) that simplified the execution of the data applications and gracefully handled any hardware failures.
All of this meant that a small team of data center engineers could now manage thousands of machines.
Although there was separation of processing and data, application developers paid special attention to data proximity. They still relied on physical servers’ locations to give the necessary I/O bandwidth required for their data processing applications. As a result, these processing environments’ configuration required detailed understanding of how the processing environment was laid out (physical server configuration, connected storage and network links within the rack and across racks). Developers also designed software to take full advantage of the underlying physical environment, such as the available memory, I/O characteristics, storage, and compute.
These environments did come with their own challenges, however.
On-prem OSS challenges
Capital investment and lead times: Setting up on-prem infrastructure requires upfront investments and lengthy lead times. Building data centers takes multiple years, upgrading power and cooling capacity takes multiple quarters, and installing new servers requires many months just to configure. All of these additions require significant planning and execution that most data developers cannot do.
Selecting hardware configurations to meet all needs: Careful experimentation with multiple machine configurations for various workloads is necessary to finalize hardware configurations. Most of the open source software relies on standardization, and making changes to hardware configuration to support new business needs is disruptive. Refreshing the hardware to take advantage of the new technologies also requires careful planning to minimize disruption to the user ecosystem.
Data center constraint management: Data center planning requires optimization of power, cooling, and physical space to maximize utilization.
Migration: Relocating a data center is a hassle, as the cost to move the data across the network is non-trivial. To avoid the cost and effort of relocating the data and applications, users have sometimes resorted to manually migrating the hardware on trucks.
Disaster planning: Disaster recovery planning is problematic, as multiple data center locations need enough network bandwidth to minimize network latency while ensuring successful recovery from failures. Of course, takeover needs to be designed and validated prior to the actual events.
Cloud-based OSS
Innovation in virtualization technologies erased some of on-prem environments’ design constraints, such as available I/O bandwidth, virtualization penalty, and storage performance. Cloud computing also enabled quick access to storage and compute capacity, allowing the data developers to take advantage of on-demand scaling. Cloud computing lets data developers select custom environments for their processing needs, allowing them to focus more on their data applications and less on the underlying infrastructure. All of these capabilities have resulted in a surge in popularity of cloud-based data analytics environments. Developers can now focus more on the high-level application configurations and can design software to take advantage of these new cloud economics.
Cloud-based OSS challenges
Infrastructure configuration: Although cloud infrastructure as a service eliminated the need for logistics planning for the data center, the complex task of cluster configuration continues to be a challenge. Users need to understand the specific cloud infrastructure challenges and the constraints when configuring their data processing environments.
Processing environment configuration: The cloud provides an easy way to configure complex processing environments. Cloud users still find optimizing the processing environments requires a detailed understanding of the data and workload characteristics. Sometimes changes to the data or the processing algorithms carry over to the environment, such as changes to data organization, storage format, and location.
Cost optimization: Configuration settings to minimize the total cost of the execution environment require continuous monitoring and management of data and workloads.
Latency optimization: As workloads evolve over time, the need for managing SLOs is critical and requires constant monitoring and fine tuning. In extreme cases, a redesign of the storage format or processing paradigm is necessary to maintain SLOs.
Dataproc is helping alleviate OSS cloud challenges today, while preparing us for a serverless future
Dataproc is an easy-to-use, fully managed cloud service for running managed open source, such as Apache Spark, Apache Presto, and Apache Hadoop clusters, in a simpler, more cost-efficient way. We hear that enterprises are migrating their big data workloads to the cloud to gain cost advantages with per-second pricing, idle cluster deletion, autoscaling, and more. Dataproc recently launched these preview capabilities to simplify management of the open analytics environment:
Personal cluster authentication: Allows interactive workloads on the cluster to securely run as your end-user identity. As a Cloud IAM Notebook user, your workloads will run and perform data access as the user. This allows for improved identity access controls and logging, thereby allowing administrators to effectively manage the security of their environments while simplifying user access management.
Flex mode: Dataproc supports Preemptible VMs (PVMs) and Autoscaling, which allows right-sizing the cluster based on demand to ensure that you are using your budget wisely. Flex mode feature allows you to further optimize cluster operations costs while reducing job failures. You can leverage Flex mode to save all intermediate Spark data on primary worker nodes, allowing you to set aggressive autoscaling policies and/or take more advantage of preemptible VMs for secondary nodes. Intermediate shuffle data is stored outside of “workers” (mappers in MapReduce and executors in Spark) such that job progress is not lost during scale-down events following the removal (or preemption) of worker machines during a job.
Persistent history server: You can now view job logs and cluster configurations even when the cluster is offline. Offline implies either an ephemeral cluster is currently not running or the cluster has been deleted. You have to configure the clusters to persist their job logs to Cloud Storage and then configure the Persistent History Server to view the logs from a set of Cloud Storage locations. A single Persistent History Server can be configured to aggregate logs from multiple clusters, simplifying manageability and debuggability of your workflows and data applications.
Dataproc allows enterprises to quickly test new OSS, develop code, deploy pipelines and models, and automate processes so that the business focuses more on building and less on maintaining. As Dataproc continues to provide enhancements to your OSS test/dev, deploy, and automate development cycle, we will continue to build intelligence into our service so that we are prepared for the serverless future.
The next phase: serverless OSS
The complexity of tuning/configuring data analytics platforms (processing and storage) due to the plethora of choices available to customers add to the complexity of selecting an ideal platform over the life of the data application as the usage and use case evolves. Serverless OSS will change that.
In the future, serverless concepts will focus on taking complexities and challenges away from you, enabling you to focus more on quality of service (QoS) while the platforms underneath make intelligent choices. This can be intimidating; however, it can be solved in multiple steps. There are three major aspects that can be selected when delivering on QoS:
Cluster: Selection of the appropriate cluster to run the workload for the desired QoS.
Interface: Selection of the appropriate interface for the workload (Hive, SparkSQL, Presto, Flink and many more)
Data: Selection of the location, format, and data organization.
In the serverless world, you focus on your workloads and not on the infrastructure. We will do the automatic configuration and management of the cluster and job to optimize around metrics that matter to you, such as cost or performance
Serverless is not new to Google Cloud. We have been developing our serverless capabilities for years and even launched BigQuery, the first serverless data warehouse. Now it’s time for OSS to have its turn. This next phase of big data OSS will help our customers accelerate time to market, automate optimizations for latency and cost, and reduce investments in the application development cycle so that they can focus more on building and less on maintaining. Check out Dataproc, let us know what you think, and help us build the serverless generation of OSS.


