BigQuery のパフォーマンスを各種ダッシュボードでトラブルシューティング
Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery は Google を代表するデータ分析サービスであり、あらゆる規模の企業が分析ワークロードを実行することを支援しています。BigQuery を最大限に活用するには、アプリケーション運用の信頼性を確立するためにワークロードの状況を把握して監視することが重要です。そこで、Google の INFORMATION_SCHEMA ビューを利用すれば、組織内の使用状況を、規模を問わず、かつてないほど簡単にモニタリングできます。ここでは、BigQuery の予約のモニタリングとパフォーマンスの最適化の方法についてご説明します。
ワークロードと予約を理解する
最初のステップは、組織内全体のスロット使用率を、その履歴も含めて分析することです。予約を使用すると、組織内で容量(スロット)を GCP プロジェクトの特定グループに割り当てることができます。プロジェクトの編成時に、ワークロード、チーム、部門を考慮してグループ分けをします。これらのグループ、または特定のワークロードを、個別の予約に分けることをおすすめします。そうすることで、モニタリングと全体的なリソース プランニングが容易になり、増加傾向を継続的に把握できるようになります。
実際には、次のような作業が考えられます。ビジネス ユニット単位(マーケティング、財務など)で分割し、既知の永続的なワークロード(ETL パイプラインなど)を一時的なワークロード(ダッシュボード作成など)から切り離します。このようなワークロードの分離を行えば、ある予約から突発的なリソース使用率の増加が生じても、他の予約に悪影響を及ぼすことがありません。たとえば、ダッシュボード作成からの負荷が急上昇しても ETL スケジュールを阻害しません。これにより、予期しない負荷の上昇によって業務が中断されるリスクを最小限に抑え、予約が SLO を満たしてジョブを予定どおりに完了させることができます。
スケジューラの仕組み
ワークロードを分離することの重要性を理解するには、BigQuery スケジューラについて知ることが重要です。BigQuery では、スロットの割り当てに公平性の概念を適用しています。第一に、スロットは予約単位で割り当てられます。予約内において、スロットはすべての有効なプロジェクトに均等に割り当てられます。「有効な」とはプロジェクトが現在クエリを実行中という意味です。個々の有効なプロジェクト内では、スロットは実行中のすべてのジョブに割り当てられます。それにより、各ジョブが確実に処理を遂行できるようになります。
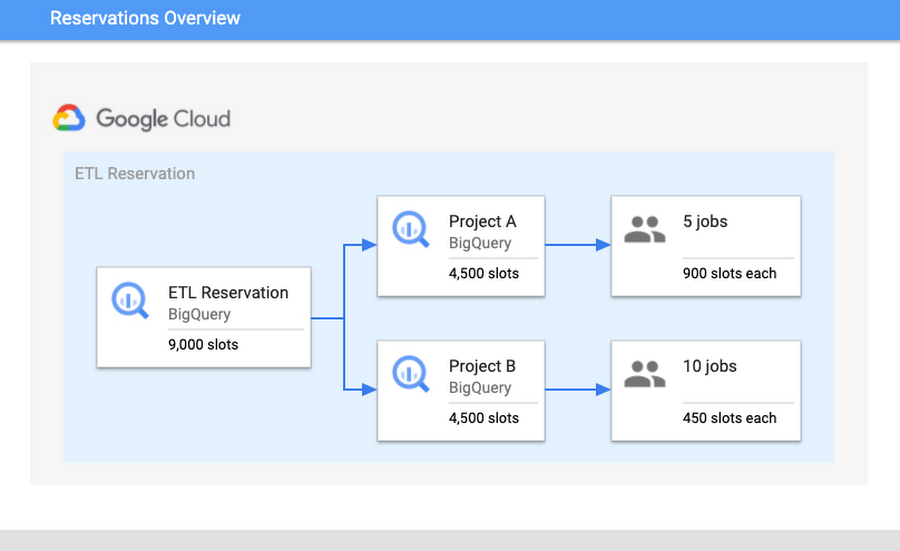
たとえば、次のようなシナリオが考えられます。予約「ETL」に 9,000 個のスロットがあり、プロジェクト A とプロジェクト B が含まれているとします。プロジェクト A では現在 5 件のジョブが、プロジェクト B では 10 件のジョブが実行中です。すべてのジョブが各ジョブを完了するために最大限のスロットを必要としているとすると、各プロジェクトにはそれぞれ 4,500 個のスロットが割り当てられます。したがって、プロジェクト A の 5 件のジョブにはそれぞれ 900 スロットが割り当てられ、プロジェクト B の 10 件のジョブにはそれぞれ 450 スロットが割り当てられます。このジョブ単位のスロット割り当ては、各ジョブのニーズと最新の状態に基づいて常に再計算され、ジョブが進むように図られます。
ワークロードを分離する構成を最適化したら、次のステップは使用率を検証してスロット割り当てを構成することです。スロット使用率が高いことは、コスト効率が良好であり、費用をかけたリソースがアイドル状態にはなっていないことを示します。しかし、使用率を 100% に近づけすぎるのは得策ではありません。100% ぎりぎりまで稼働すると、急な使用率の上昇に対応するための余裕が残されません。もしも急上昇が起きて 100% を超過すると、リソースの取り合いが生じて、全体的な処理速度の低下を引き起こします。
クエリ パフォーマンスの改善とモニタリング
ここでは、パフォーマンスのモニタリングを目的として、潜在的な問題に共通する根本原因や注意すべき危険信号を、想定される対策手順とともに紹介します。ここで提示する例を通じて、クエリのパフォーマンスを向上させることを目指します。
まずは INFORMATION_SCHEMA ビューのデータを比較することから始めましょう。具体的には、クエリ パフォーマンスの違いを理解するために、類似する 2 つのクエリを取り上げ、その INFORMATION_SCHEMA ジョブのデータを比較します。このとき、この 2 つのジョブには十分な類似性があり、結果が比較可能であることが重要です。たとえば、時間 A と時間 B に実行された同じジョブや、日付 A と日付 B のパーティションで読み込まれた同じジョブの比較が該当します。
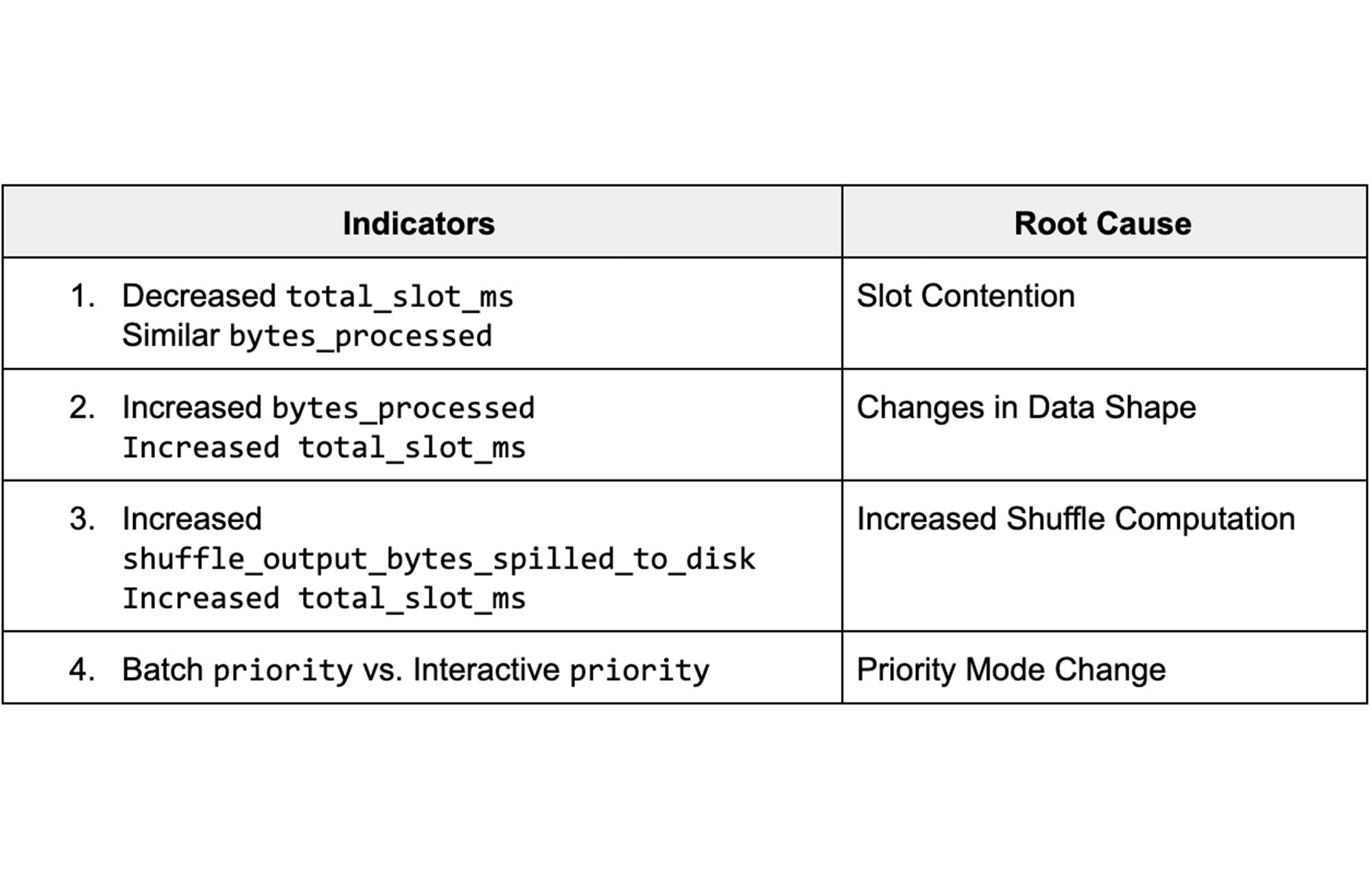
これらのビューのデータは、クエリのパフォーマンスに影響するさまざまなジョブ統計情報を表します。異なる実行でフィールドの統計情報がどのように違うかを把握すれば、処理速度が低下した隠れた根本原因と対策手順を特定することができます。次の表は、特に重要な指標とそれに対応する根本原因の概要を示しています。
ジョブ比較ダッシュボード
ジョブのパフォーマンスを比較するための Google のテスト用 INFORMATION_SCHEMA データを表示する公開ダッシュボードから見ていきましょう。
これらの根本原因を個々に検証し、Systems Tables ダッシュボードを使用して診断する方法を紹介します。はじめに、処理速度の遅いジョブと速いジョブの ID を入力して、ジョブの統計情報を比較します。
1. スロット競合
背景
スロットに対する需要が予約に割り当てられた容量よりも高いときに、スロット競合が発生します。同一予約内のプロジェクトやジョブはスロットを均等に分け合うので、有効なプロジェクトやジョブが多いほど、個々のプロジェクトまたはジョブに割り当てられるスロットは少なくなります。スロット競合を診断するには、INFORMATION_SCHEMA タイムライン ビューを使用して、プロジェクト単位でもジョブ単位でも同時実行を分析できます。
モニタリング
このユースケースでは、いくつかの異なるシナリオを見ていきましょう。第一に、クエリ間で異なる「total_slot_ms」を確認します。あるジョブの実行に時間がかかり、他のジョブよりも使用しているスロットが明らかに少ない場合、通常は、このジョブは他の有効なジョブとの競合により少ないリソースにしかアクセスできなかったことを意味します。この仮説を検証するには、同時実行について詳しく調べる必要があります。
1. プロジェクトの同時実行: 対象ジョブが予約内にある場合、JOBS_BY_ORGANIZATION タイムライン ビューを使用して、遅いクエリ実行中と速いクエリ実行中の双方の有効プロジェクト数を計算します。クエリジョブの処理速度は、予約内の有効プロジェクト数が増えるほど低下します。数式で表すと、1 つの予約に Y 件のプロジェクトがある場合、各プロジェクトへのスロット割り当ては予約の合計スロットの 1/Y 個になります。これは、前述した BigQuery のスケジュール設定アルゴリズムの公平性によるものです。
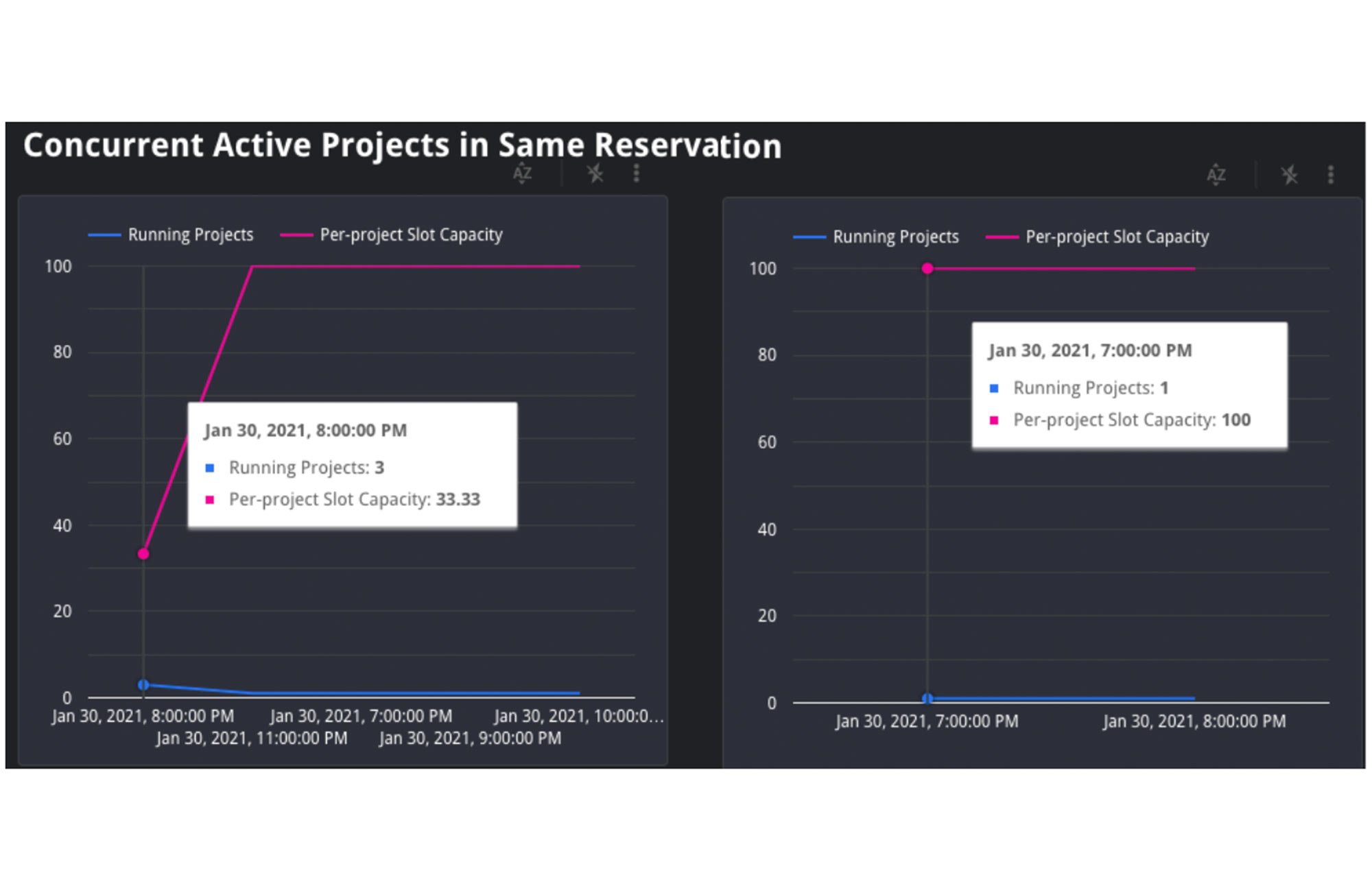
上のグラフでは、左側のジョブが開始されるとき合計 3 件のプロジェクトが同時実行され、予約の 35 スロットに対して競合しているのがわかります。このシナリオでは、各プロジェクトに予約の 35 スロットの 1/3 が割り当てられます。つまり、それぞれ約 12 個のスロット割り当てになります。一方、右側のグラフには有効なプロジェクトが 1 件しかなく、35 スロットをすべて独占することになります。
2. ジョブの同時実行: 同様に、JOBS_BY_PROJECT タイムライン ビューを使用してプロジェクト内の状況も理解できます。同時実行されているジョブの数が多ければ、すべてのジョブが同時にリソースを取り合うことになります。需要が高いところに、各ジョブが利用できるスロット リソースが限られ、クエリの完了までに通常より時間がかかる可能性が高くなります。
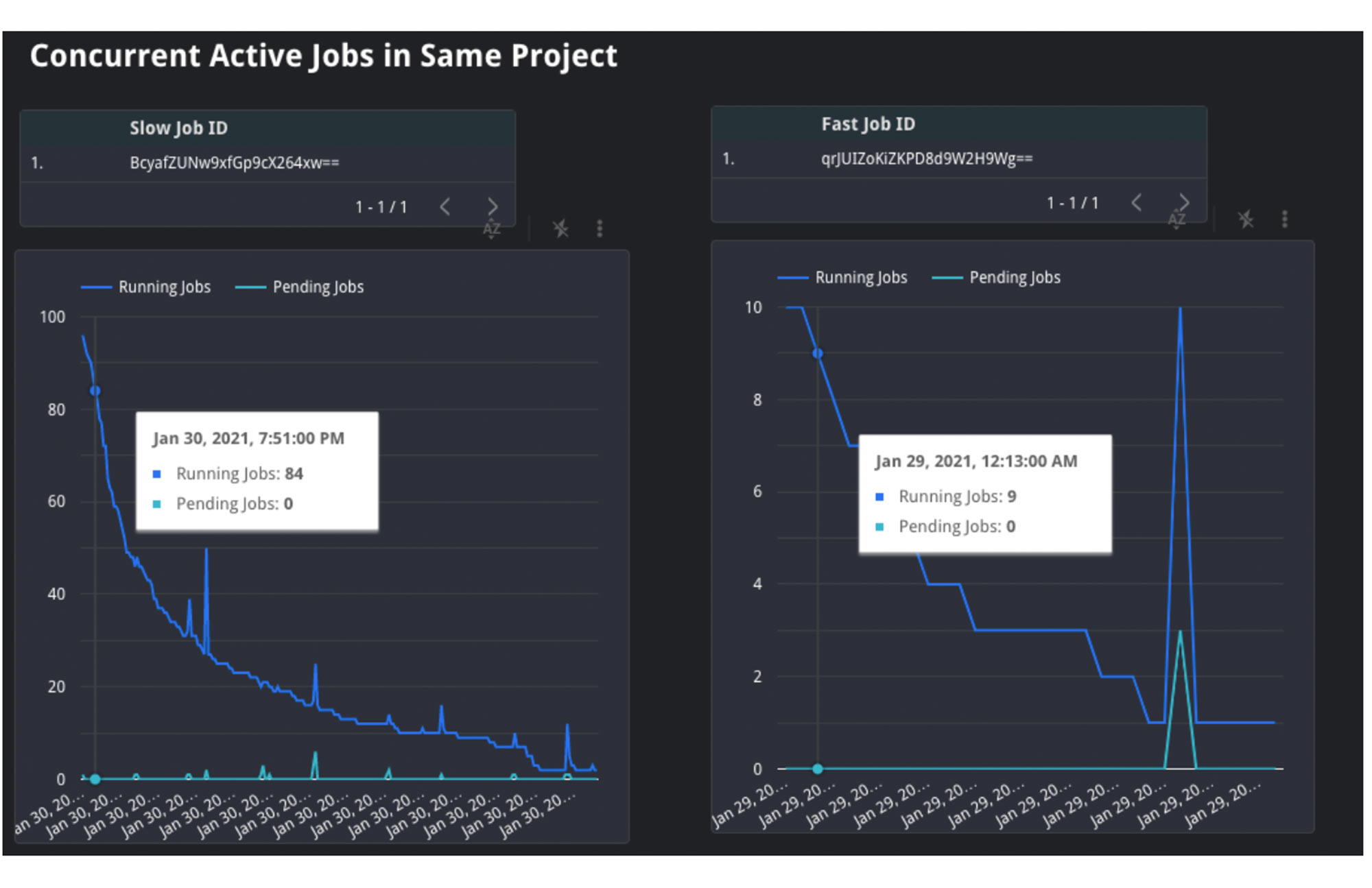
上のグラフでは、左側の処理速度の遅いクエリがその実行過程で他の 20 件から 100 件のジョブと競合しています。一方、右側の処理速度の速いジョブはその実行過程で 4 件から 26 件のジョブとしか競合していません。これは、左側のジョブが示すように、同時に実行される有効なジョブの数量が処理速度の低下と処理時間の遅延の原因であることを示唆しています。
3. 最後に、アイドル スロットが使用されていたかどうかも検証してみましょう。アイドル スロットは予約に任意で構成することができます。この構成を有効にすると、利用可能なスロットはすべて予約間で分け合うことになり、未使用状態のスロットが非アクティブな予約によって無駄に占有されたままにならずに済みます。ジョブが最初に実行されたときにアイドル スロットにアクセスできれば、予約の通常の割り当てに加えて使用できるため、実行のためのリソースに余裕ができ、処理速度の向上が期待できます。現在、これを INFORMATION_SCHEMA で確認することはできません。しかし、アイドル スロットが利用可能であるかどうかは、クエリ実行中の予約の使用率を確かめることで推測できます。予約の使用率が 100% を越えていれば、他の予約からスロットを借用したことを意味します。
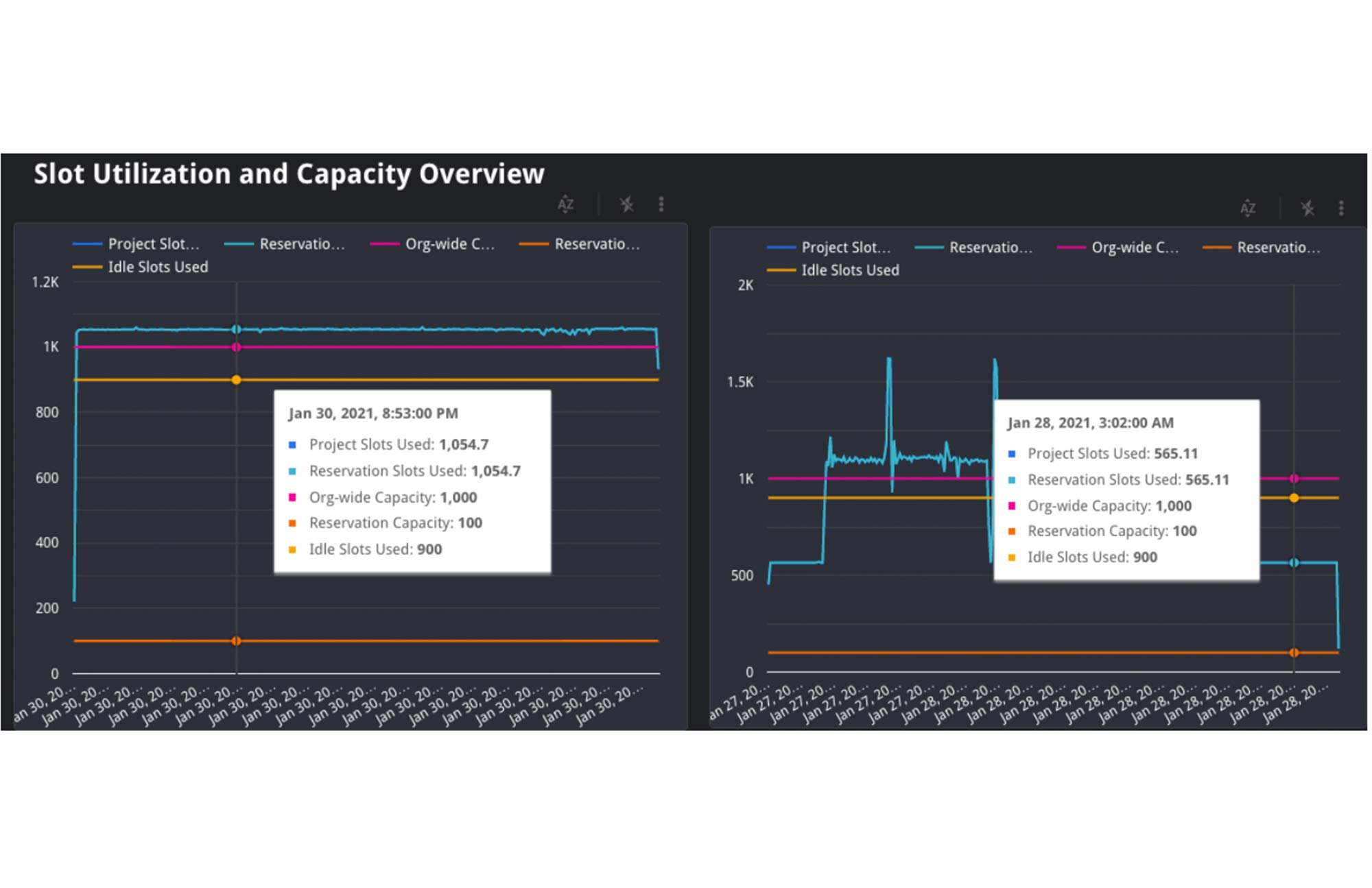
上のグラフでは、組織と予約の容量に加え、予約に使用されるスロット数も確認できます。このケースでは、左側の予約内のジョブが容量の 100 を超えて 1,055 スロットを使用しています。容量は組織が 1,000、予約が 100 だけなので、組織内の他の予約から 900 個のアイドル スロットを借りて使用したことになります。注: まれに、組織は購入した許容量を超えるスロットを使用する場合があります。データセンター内での移行であったり、組織内のプロジェクトでオンデマンドの追加スロットが使用されたりするようなケースがそれに当たります。
可能な対策
パフォーマンス低下の根本原因がスロット競合である場合、ジョブがアクセスできるスロット数を増やす必要がありますが、スロット容量は複数の方法で増やせます。
1. スロットを追加購入する: 最もシンプルな方法です。予約のスロットに新しいコミットメントを購入して、より多くのリソースを確保することができます。ニーズの予測に応じて、年間、月間、または Flex プランで追加購入を設定することもできます。
2. 予約ごとのスロット割合を再分配する: スロットの総量を追加購入で増やすことができない場合は、現在あるスロットを優先順位に基づいて予約間で再分配することができます。つまり、予約 A から予約 B に一定量のスロットを移して再割り当てします。この方法で予約 B のスロットの割り当てを増やすと、容量の増加に応じて予約 B のジョブがこれまでよりも速く完了します。その分予約 A は遅くなる可能性があります。
3. ジョブを再スケジュールして現在進行中のジョブを最小限にする: 予約間でリソースを移動することができない場合は、ジョブのタイミングを調整して、長い目で見た予約の使用率を最大限に引き上げることができます。つまり、緊急ではないジョブを週末や夜間などのオフピーク時に移動します。一日の負荷を全体にならせば、ピーク時のスロット競合を減らすことができます。使用率の動向は、Hourly Utilization レポートを検証すれば、より的確に理解できます。
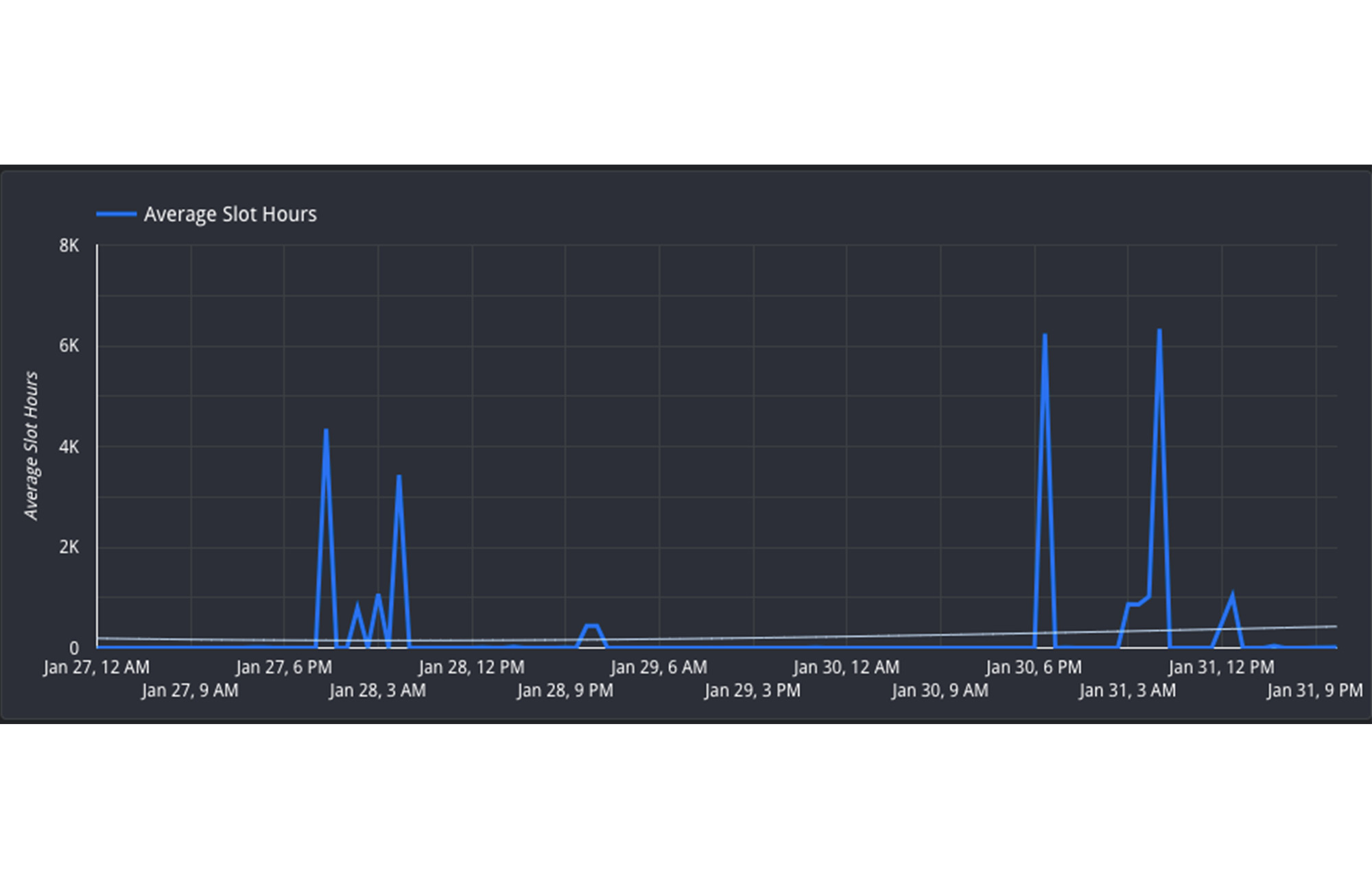
このビューでは、1 月 27 日と 30 日の両方の日付で午後 4 時~午前 8 時(UTC)の間に予約が活発に使われていることが確認できます。一方、午前 8 時~午後 4 時(UTC)の時間は利用率が低く、「オフピーク」と考えられます。ジョブをこの時間帯に再スケジュールして、リソースの使用を分散すれば効率的です。
2. データ形態の変更
背景
処理時間の予期しない変化の原因としては、他にもデータそのものの状態が考えられます。これには、根底にあるソーステーブルに当初のクエリ実行時よりも多くのデータがある、あるいは、クエリの実行過程で中間サブクエリの結果としてより多くのデータが生じた、という 2 パターンが考えられます。
モニタリング
この場合、まず [total bytes processed] フィールドがクエリの変更によって増加していないか確認します。これが、処理の速いジョブから遅いジョブへの変更に応じて増加するようなら、ジョブが通常より多くの処理を行ったことになります。この根本的な原因は、次の 2 つの方法で確認できます。
1. ジョブの処理量の増加は、クエリで分析する必要があるデータ量の増加を意味します。クエリのテキスト自体に変化がないかを確認します。たとえば、JOIN が移動されていたり、WHERE 句による絞り込み方法が更新されていたりすれば、読み込むデータ量が増えた可能性があります。
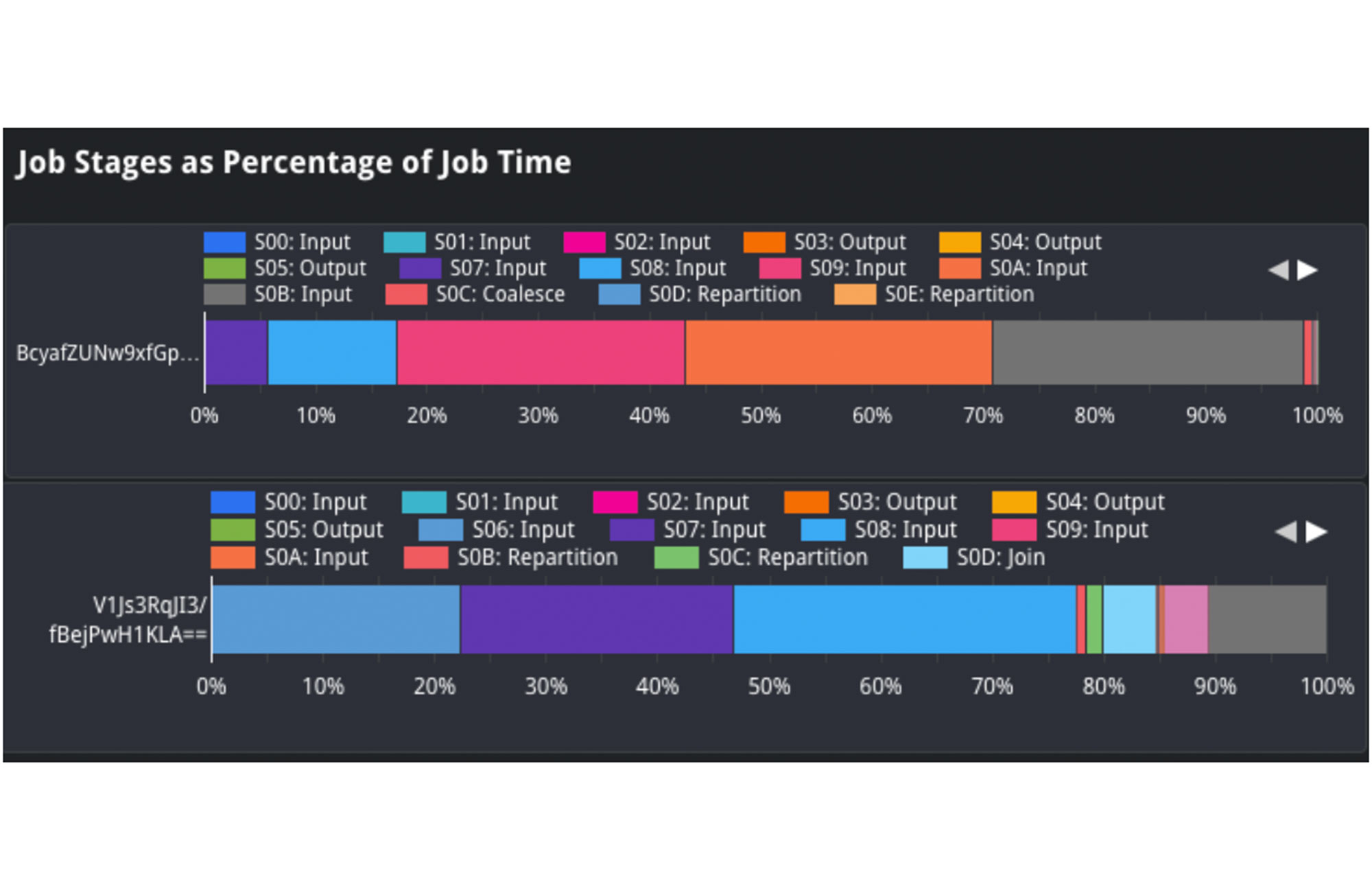
Job Stages as a Percentage of Job Time ビューで、入力データの形態を分析してクエリ間で比較することができます。たとえば、取り込まれたデータ量を示す「Input」の割合を、遅いジョブと速いジョブで比較します。ステージ 2 の Input を見ると、上のジョブでは処理時間の約 25% を占めているのがわかります。一方、下のジョブでは、処理時間の約 1~2% しか占めていません。これは、ソーステーブルでステージ 2 にデータの取り込みが増加し、ジョブの低速化につながった可能性を示唆しています。
2. また、クエリのソーステーブルのサイズも分析する必要があります。クエリに使用されたソーステーブルはすべて、referenced_tables フィールドで確認できます。クエリ実行時の個々のソーステーブルのサイズを比較してみましょう。サイズの増加が顕著なら、それが処理速度を低下させた原因の可能性があります。
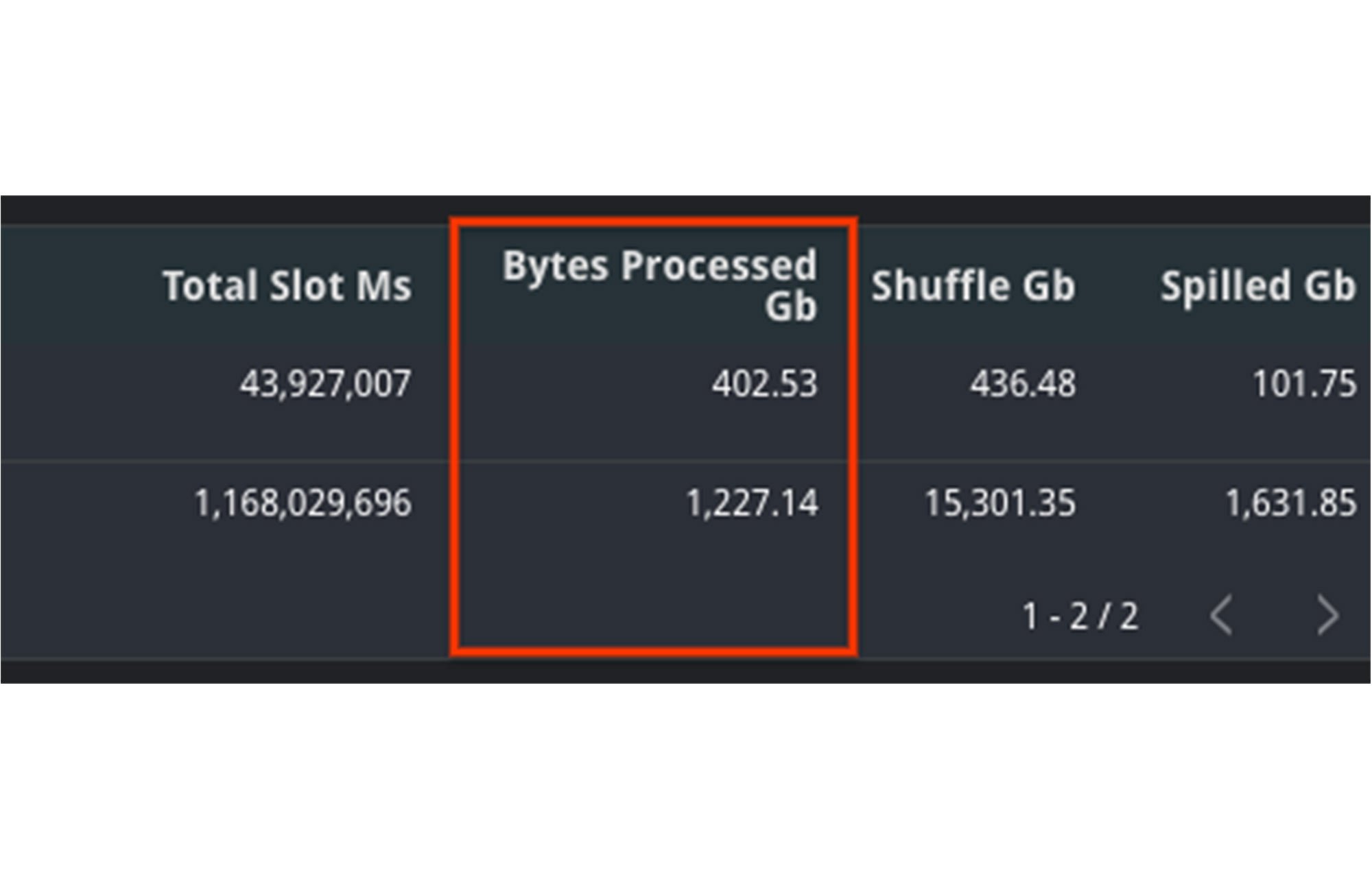
この例では、処理されたバイト数がジョブ間で大幅に上昇しており、これがパフォーマンス低下の原因と思われます。さらに total_slot_ms の増加も考慮すれば、より多くのスロットが利用可能であったにもかかわらず、より時間がかかったことがわかります。
可能な対策
1. クラスタリング: クエリによっては、クラスタリングを使用してパフォーマンスを改善できます。クラスタリングはソーステーブルの類似する列を並べ替えるので、データの絞り込みや集約を行うクエリは円滑化されます。これは、スキャンするデータ量がクラスタリングのおかげで減少するためですが、パフォーマンスに著しい効果が見られるのは、テーブルのサイズが 1 ギガバイトを超える場合に限られます。
2. 入力データを最小限に抑える: 必要なデータだけを読み込むようにクエリのテキストを最適化できれば、パフォーマンスを改善する効果があります。これには、クエリの冒頭に WHERE 文を追加して不要なレコードを除去したり、SELECT 文を SELECT * とせずに必要な列だけを含めるように修正したりするなど、早い段階で条件を絞り込むいくつかの方法が考えられます。
3. データを非正規化する: データに親子関係やその他の階層関係が存在する場合は、スキーマでネストされたフィールドや繰り返しフィールドの適用をお試しください。そうすることで、BigQuery でクエリの実行を並列化でき、ジョブの完了が速まります。
3. シャッフル メモリの増加
背景
ジョブのコンピューティング リソースにはスロットが使用されますが、ジョブの状態をトラッキングするにはシャッフル メモリも使用されます。ジョブの状態は、クエリの進行過程における実行ステージ間のデータ移行のためにトラッキングが必要になります。ジョブの状態を共有することで、結果的にクエリの並列処理や最適化が可能になります。シャッフル メモリと予約で利用可能なスロット数の間には相関関係があります。
シャッフルはインメモリで行われるため、クエリの各ステージで利用可能なメモリ量には限りがあります。クエリの実行中に、大規模な結合などでデータの処理量が超過するときがあると、あるいは結合にまたがる過度のデータスキューが生じると、ステージの負荷が高すぎてシャッフル メモリの割り当てを超えてしまう場合があります。その時点で、シャッフルのバイトはディスクにあふれ出て、クエリの処理速度が低下します。
モニタリング
この状況を診断するには、2 つの異なる指標に注目します。ジョブが消費したシャッフル メモリと使用されたスロット数です。シャッフル メモリの割り当てはスロットの容量に関連付けられています。スロットの数量が安定しているのに、ディスクにあふれ出たシャッフルの数量が増加していれば、パフォーマンス低下の原因の疑いがあります。
TIMELINE ビューで集約された shuffle_output_bytes_spilled_to_disk を比較してみましょう。ディスクにあふれ出たバイト数の増加は、ジョブが予定どおりに完了できるほどの処理速度がなく、停滞していることを示しています。
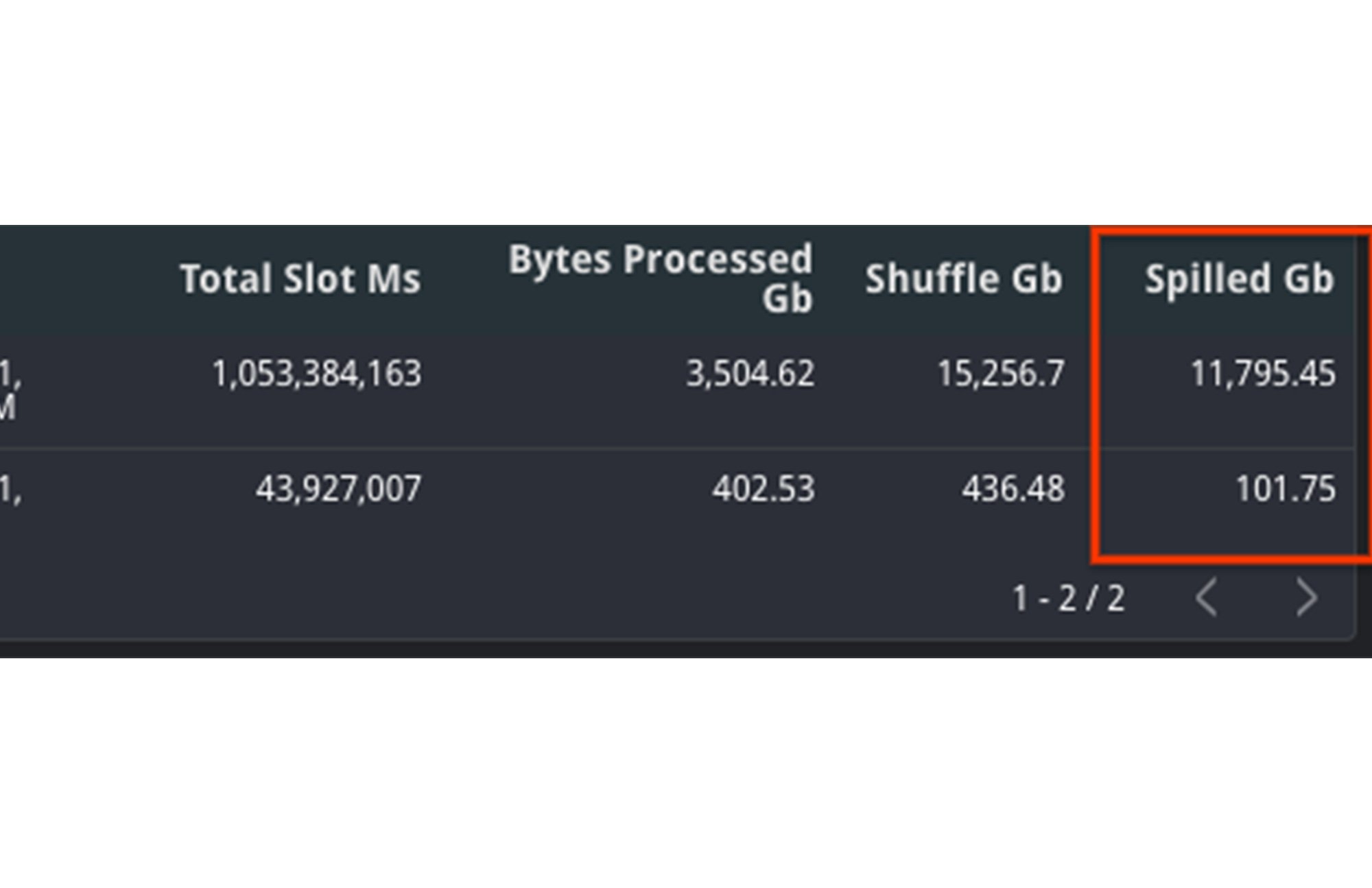
この例では、ディスクにあふれ出たデータ量が、遅いクエリに対して著しく高くなっていることがわかります。加えて、スロット数の合計も上昇しているので、より多くのリソースが利用可能であったのにもかかわらず、ジョブの完了に余計に時間がかかったことになります。
可能な対策
ディスクにあふれ出たバイト数の増加は、BigQuery がクエリの実行ステージ間でジョブの状態を適正に維持できていないことを意味します。したがって、クエリプラン自体を最適化して、ステージ間でのバイトの受け渡しを抑えれば、改善が期待できます。
1. データを早期にフィルタする: データを WHERE 句を使って、テーブルを結合する前の早い段階で絞り込めば、クエリに取り込むデータ量を減らすことができます。また、SELECT は SELECT * のようにワイルドカードを使わず、必要な列だけを選択するように徹底します。
2. シャーディングではなくパーティションで分割されたテーブルを使用する: シャーディングされたテーブルを使用している場合は、代わりにパーティション分割テーブルを使用します。シャーディングされたテーブルを使用すると、BigQuery では状態情報の保持に加え、スキーマやメタデータのコピーも保持しなければならず、パフォーマンスの低下につながります。
3. スロットを増やす: シャッフル メモリの量はスロットの数量と相関関係があるので、スロット数を増やせば、ディスクにあふれ出るメモリ超過を緩和できます。スロット競合の対策手順で述べたように、スロット数を増やすには、新しいコミットメントを購入するか、対象となる特定の予約により多くのスロットを割り当てます。
4. クエリを書き換える: ジョブはデータの状態をステージにまたがって保持できないため、クエリを書き換えるのもパフォーマンスを改善させる方法の一つです。これには、サブクエリを減らしたり、CROSS JOIN を削除したりするなど、SQL アンチパターンを回避するための最適化を試すことも含まれます。また、クエリを分割して連鎖する複数クエリに書き換え、クエリ間の出力データを一時テーブルに保存する方法も試す価値があります。
4. 優先順位モード
背景
BigQuery では、クエリはインタラクティブモードとバッチモードの 2 つの優先順位方式のいずれかに基づいて実行されます。デフォルトでは、インタラクティブ モードでジョブが実行されます。これは、リソースが利用可能になると直ちにジョブを実行する仕組みです。
モニタリング
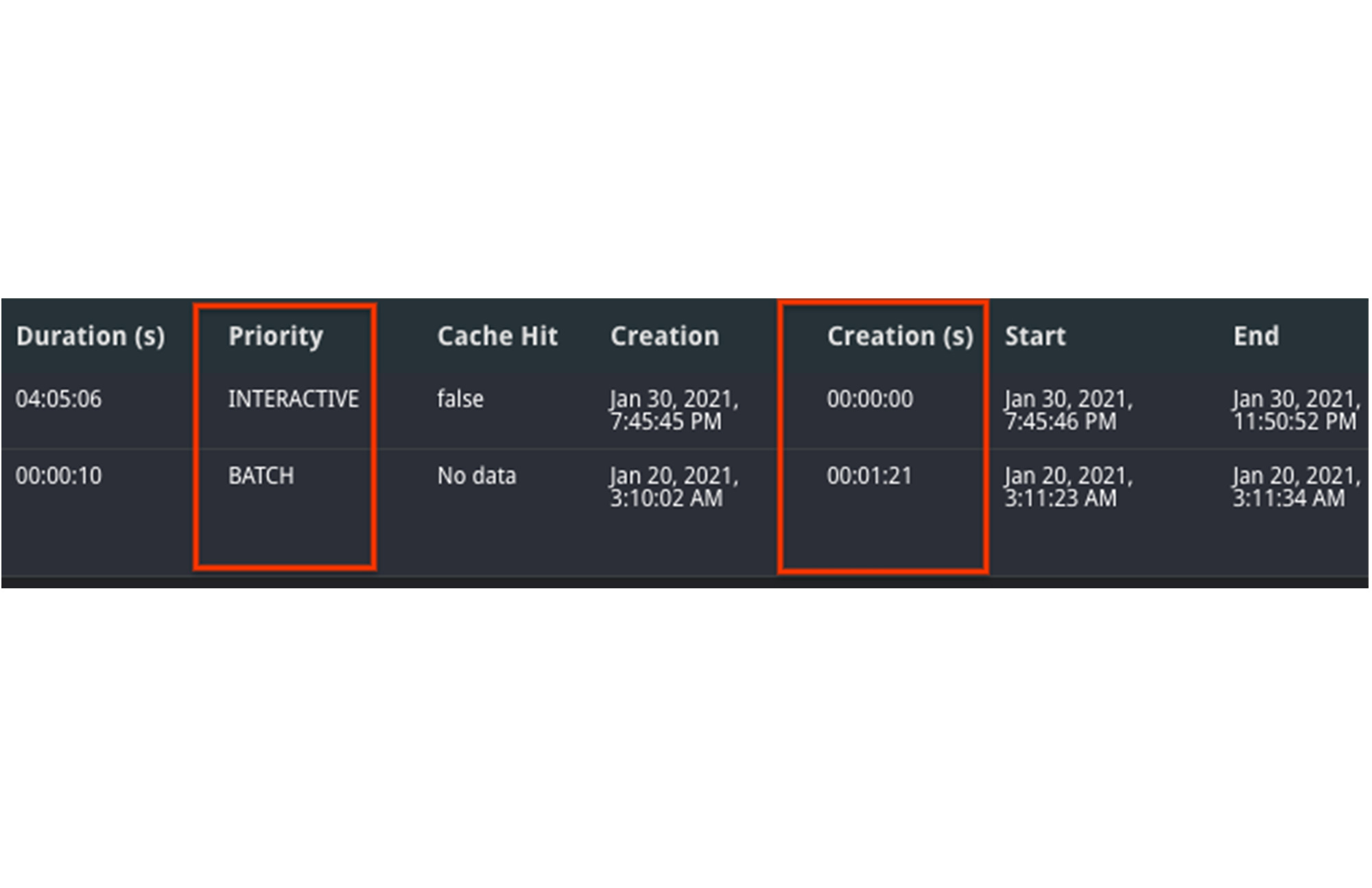
1. モードを確認するには、ジョブの優先順位の列を参照します。ジョブの処理速度は、バッチジョブのほうがインタラクティブ ジョブよりも遅くなる可能性があります。
2. いずれのジョブもバッチモードで実行された場合は、実行中の状態の変化を比較します。1 つのジョブが長い間 PENDING 状態でキューイングしていた可能性があります。その場合、作成時間には利用可能なリソースが不十分だったことになります。テーブルの Creation (s) 時間を調べれば、ジョブが開始前にキューイングしていた時間がわかるので、この問題の発生を確認できます。
対策
1. ジョブの相対的な優先順位と SLO を理解する。組織内に重要度の比較的低いジョブがある場合は、それらをバッチモードで実行し、重要度のより高いジョブを先に実行できるようにします。バッチジョブは、インタラクティブ ジョブが完了するか、アイドル スロットが利用可能になるかのいずれか、または両方の条件が整うまで実行されず、キューに入れられる可能性があります。
2. バッチジョブとインタラクティブ ジョブの同時実行割り当ての違いを特定する。バッチジョブとインタラクティブ ジョブには、それぞれ異なる同時実行割り当てがあります。デフォルトでは、プロジェクトの同時実行インタラクティブ クエリは最高 100 件までに限られています。必要な場合は、この限度の引き上げを販売チームまたはサポートに問い合わせることができます。また、インタラクティブ ジョブが 6 時間のタイムアウト時間枠内で必ず終わるように、バッチジョブが必要に応じて待機する場合もあります。
3. スロット競合に関して紹介したのと同様に、対策としては、予約にスロットの追加購入を検討するか、リソースの需要が下がるオフピーク時間にジョブを再スケジュールする方法があります。
ご覧いただいたように、クエリジョブを INFORMATION_SCHEMA のデータに基づいてトラブルシューティングする方法は多種多様です。ぜひ、ご自分でお試しください。2 つの任意のジョブ ID を使ってこちらでお試しいただけます。
-戦略的クラウド エンジニア Kaitlin Ardiff