夏の締めくくり: データ分析カテゴリでの新しい導入事例や発表のまとめ
Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
8 月は、椅子に深く腰掛けてくつろぎながら、終わりゆく夏を楽しむときです。また、南半球の人にとって 8 月は、少しずつ暖かくなり、水着やサングラスに注目が集まり始める月です。しかし、皆様がどこにお住まいであるかにかかわらず、8 月は Google のデータ分析部門から興味深い情報や記事が数多く発表される時期でもあります。
今回の月間ダイジェストでは、先月の興味深い記事を「新しい機能と発表」、「導入事例」、「ハウツー」の 3 つのグループに分けてお届けします。順番にすべてのセクションをお読みいただくことも、興味のあるセクションだけをご覧いただくこともできます。
機能と発表
データセットとデモ用クエリ - 再帰的な機能の追加というのは関心の高いトピックですが、先日の発表では素晴らしいメタファーでもありました。8 月に Google は、これまでで最も自己言及的なデータセットをリリースしました。これは、Google Cloud リリースノートに BigQuery からアクセスできるようにするものです。この新しい Google Cloud リリースノート データセットを使用すれば、必要なプロダクトや機能の発表を迅速に見つけることができます。また、Google トレンドでの上位 25 件の検索キーワードもリリースされました(Looker ダッシュボード)。
Pub/Sub のトピック保持機能でメッセージを保存し、費用と時間を節約できるようになりました。トピックの保持を有効にすると、選択した保持期間内でトピックに送信されたすべてのメッセージが、すべてのトピックのサブスクリプションで利用できます。サブスクリプションを追加してもストレージの費用が増えることはありません。さらに、メッセージをパブリッシュした時点でトピックにサブスクリプションが関連付けられていなくても、メッセージは保持され、再生できるようになります。これにより、サブスクライバーは特定のトピックに送信されたメッセージの全履歴を見ることができます。
UDF を使用して Dataflow テンプレートを拡張できるようになりました。Google は、お客様が頻繁に行うデータタスクで一般的に使われる Dataflow テンプレートのセットを提供しています。これは、デベロッパーが拡張できる参照用のデータ パイプラインとしても利用できます。この Dataflow テンプレートを、テンプレートのコード自体の変更や保守を行わずにカスタマイズできるようになりました。JavaScript のユーザー定義関数(UDF)を使用することで、特定の Dataflow テンプレートをカスタム ロジックで拡張し、レコードをその場で変換できるようになっています。これは特に、再コンパイルやテンプレートのコード自体の保守を行わずにパイプラインの出力形式をカスタマイズしたい場合に便利です。
下の図は、UDF に対応した Dataflow テンプレートのプロセスフローを示します。
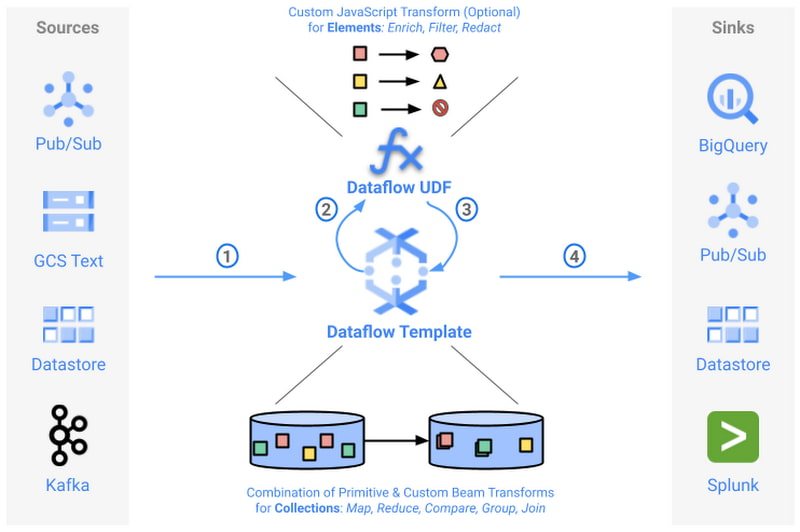
導入事例
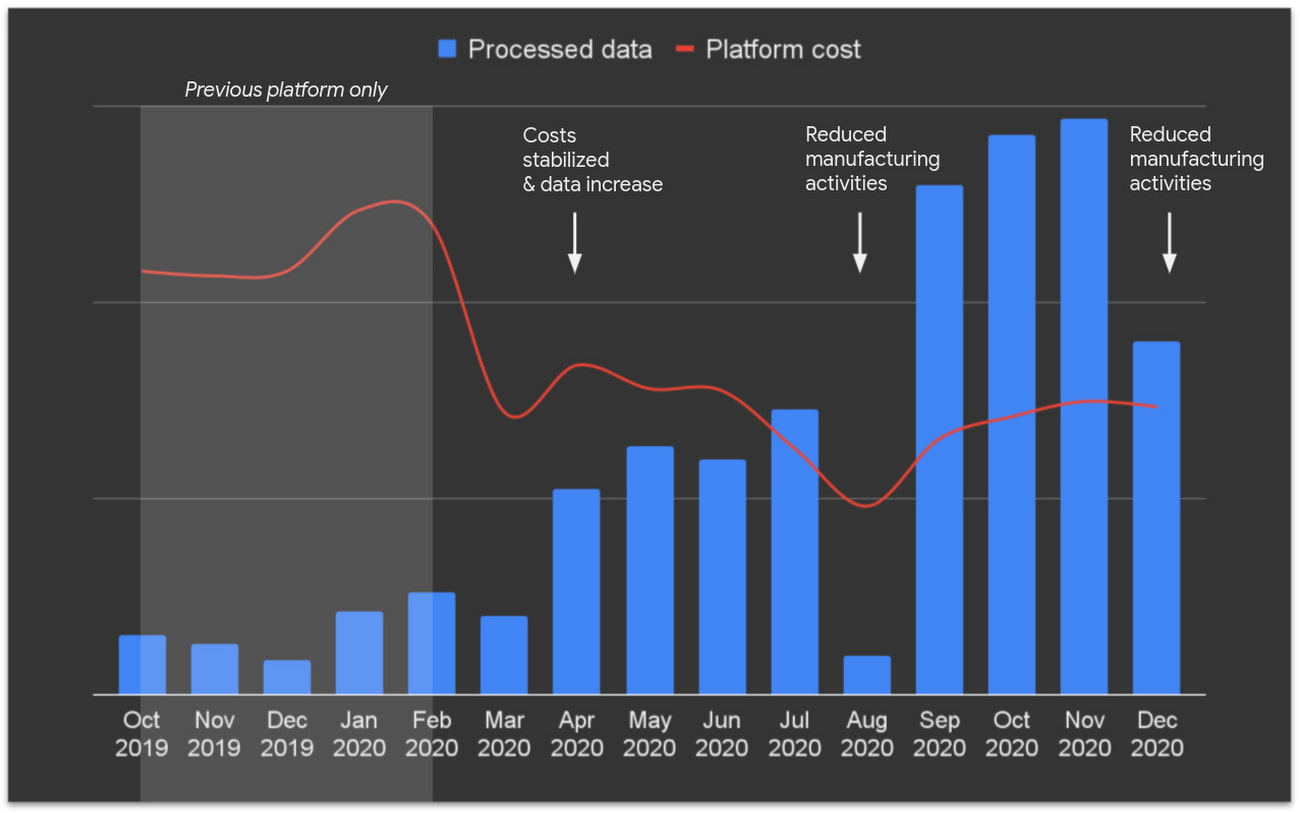
ルノーが BigQuery を使用して自社の産業データ プラットフォームを改善
先月、ツールと製品のトレーサビリティの向上とオペレーション効率の測定を目的として産業用 IoT 分析システムを確立したルノーの取り組みとその影響を紹介したブログ記事を投稿しました。このシステムは、Dataflow、Pub/Sub、BigQuery を使用して構築されています。複数のデータサイロを BigQuery に整理統合することで、同社の IT インフラストラクチャ チームは、処理するデータの量がレガシー システムを使用していたときより数倍多くなっていたにもかかわらず、ストレージ費用を 50% 削減できました。
下のグラフは、ルノーが毎月処理していたデータ量の数倍の伸び(青のバー)と、以前のシステム(明るいグレー部分)を Google ソリューションに切り替えた後の費用の低下(赤の線)を示しています。
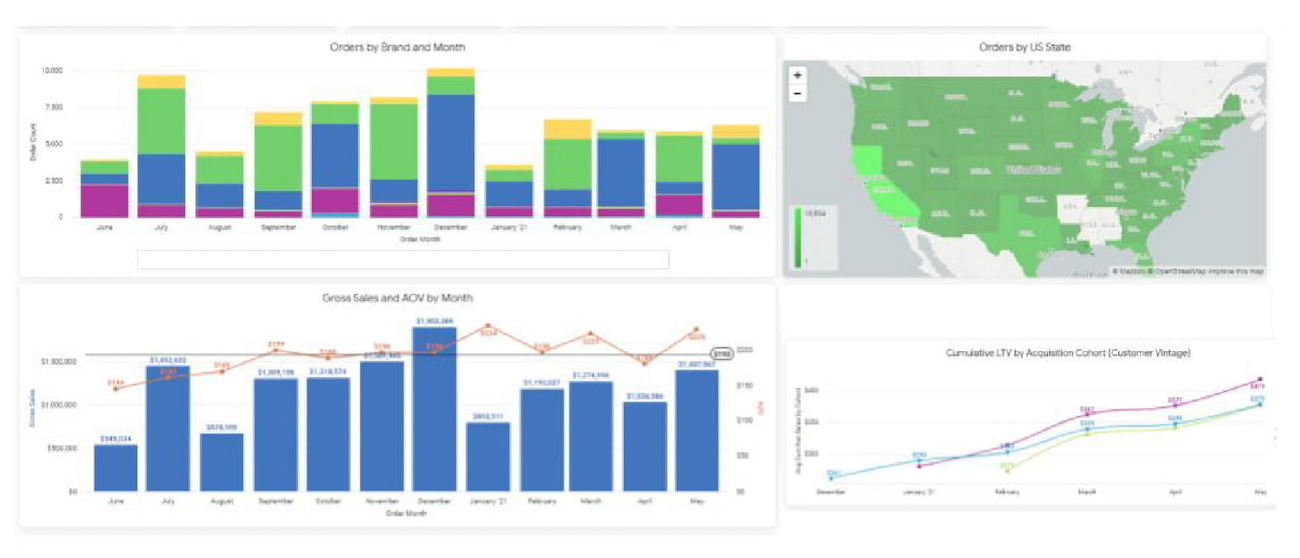
Constellation Brands が消費者直接取引(DTC)への転換を促進するために Google Cloud を選択
Constellation Brands で消費者直接取引戦略担当ディレクター兼責任者を務める Ryan Mason 氏に、DTC チャネルのビジネス価値や、同社のパイプラインの実装方法とその影響についての記事を執筆していただきました。この記事では、Google マーケティング プラットフォーム(アナリティクス 360、タグ マネージャー 360)から複数のストリームを収集して BigQuery に取り込む方法が説明されています。すべての Google マーケティング プラットフォームのデータにネイティブにアクセスし、BigQuery 内での分析に利用できることが重要な差別化要因となっています。
同社は、BigQuery に集約されたデータから、顧客獲得コスト(CAC)、顧客のライフタイム バリュー(CLV)、ネット プロモーター スコア(NPS)などの重要業績評価指標(KPI)を計算し、Looker ダッシュボードを通じて社内全体に配信できるようにしました。このようにして誰もが同じ KPI にアクセスできるようにすることで、組織全体でビジネスの健全性を追跡できるようになりました。
Looker(ダッシュボード)は運営面にも大きな影響を与えています。担当チームの推計では、重要なビジネス上の意思決定にかかる時間が約 60% 減少しました。
ハウツー
Google の DevRel Rockstar 担当 Leigha Jarett は、BigQuery 管理者向けリファレンス ガイドのブログシリーズで、有益な記事を 4 本公開しました。先月彼女が取り上げたテーマは、モニタリング、API 環境、データ ガバナンス、クエリの最適化でした。
その中で私が特におすすめする記事は、クエリの最適化です。そこには、パーティショニングやクラスタリングによってクエリ時にスキャンするデータ量を削減するといった一般的なものから、式の適切な順番のようなあまり知られていないものまで、優れたヒントが詰まっています。
この BigQuery でのワークロード管理に関する記事では、便利なヒントがいくつか示され、コミットメント、予約、アサインメントを構成する主要な概念が解説されています。

ゲームをストリーミングしている場合は、DF と PS を使用してストリーミング パイプラインの重複データを処理する方法を取り上げたこの Zeeshan Kahn の投稿が役立ちます。
Google 社員の Firat Tekiner と Susan Pierce は、データレイクとデータ ウェアハウスの集約について俯瞰的な視点から議論し、大局的な知見を示しています。ユーザーは 2 組のインフラストラクチャを管理することを望んでいないため、統合されたデータ プラットフォームを目指すべきだというのが 2 人の共通した見解です。
以上で、Google Cloud からお届けするゆったりとした空気感の 8 月の総括は終わりです。10 月には Google Cloud Next が控えています。さらなる発表、ハウツーブログ、導入事例にご期待ください。
-データ分析担当プロダクト管理ディレクター Sudhir Hasbe




