Dataflow と Pub/Sub を使用して、ストリーミング パイプラインの重複データを処理する
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
目的
ストリーミング データを処理して分析情報を抽出し、リアルタイム アプリケーションを強化することはますます重要になっています。Google Cloud Dataflow と Pub/Sub には、ミッション クリティカルなパイプラインを実行するための、スケーラビリティと信頼性に優れた、完成されたストリーミング分析プラットフォームが用意されています。このようなパイプラインの設計に際して、デベロッパーは、重複データの処理をどのように行うかという課題に頻繁に直面します。
このブログでは、ストリーミング パイプラインで重複データがよく発生する場所や、その処理に利用できるいくつかの方法について説明します。また、同じトピックについて説明しているこちらの技術解説もぜひご覧ください。
ストリーミング データ パイプラインで重複が発生する場所
このセクションでは、ストリーミング パイプラインで重複データが発生する可能性のある場所について、概要を示します。以下の図の赤い箱で囲まれた番号が、発生する可能性のある場所になります。
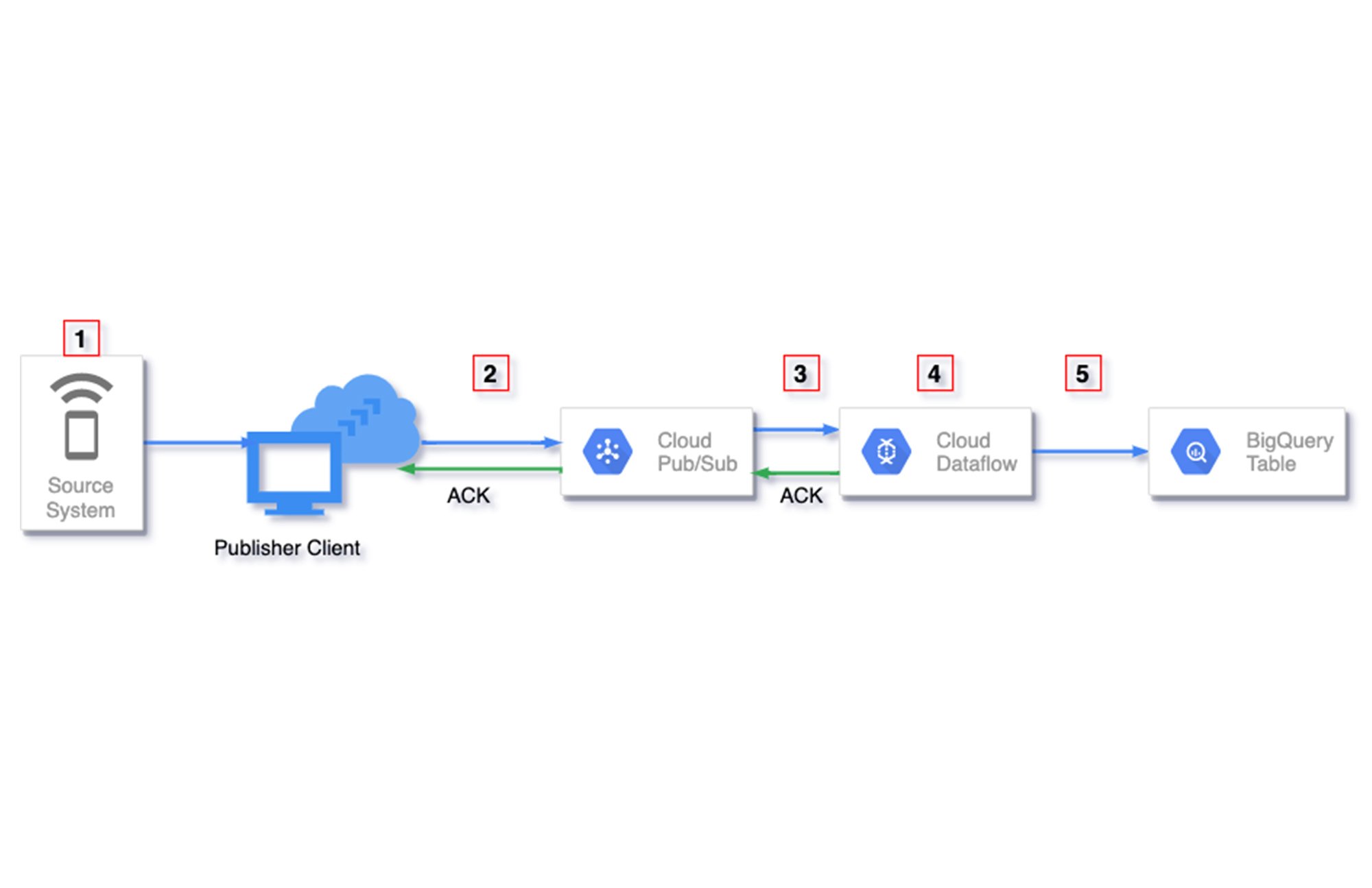
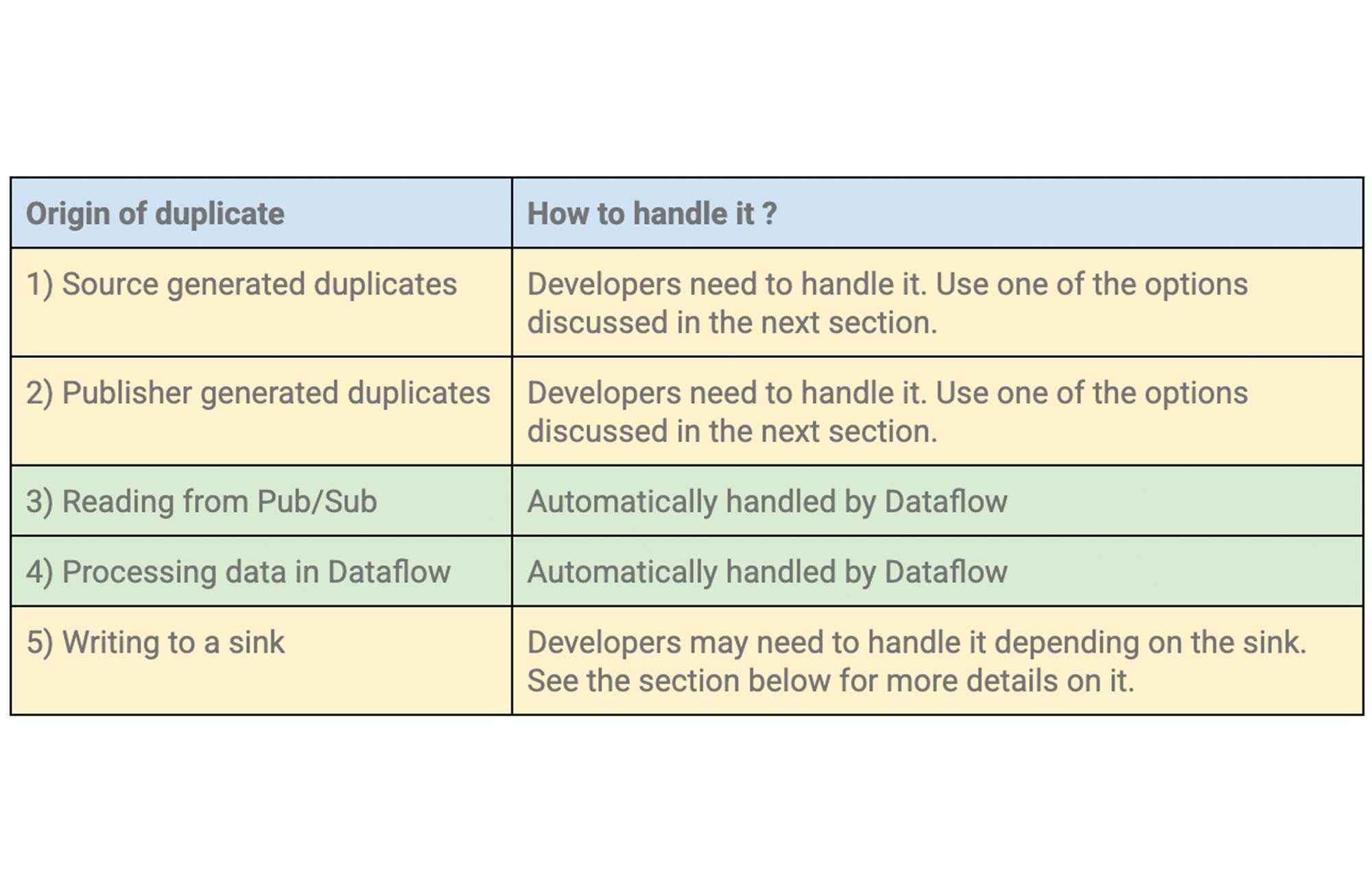
重複によっては、Dataflow で自動的に処理できるものもありますが、デベロッパーが何かしらの手法を用いて処理しなければならない場合もあります。以下の表は、これについてまとめたものです。
1. ソースで生成される重複
データソース システムそのものが重複データの発生源になる場合があります。ネットワーク障害やシステムエラーなど、重複データの原因となりうるものはさまざまです。このような重複は、「ソースで生成される重複」と呼ばれます。
たとえば、GCS バケットのオブジェクト変更に応じた Google Cloud Storage から Pub/Sub へのトリガー通知を設定している場合、ソースで生成される重複が発生する可能性があります。この機能は Pub/Sub への 少なくとも 1 回の配信を保証するものであり、重複する通知を生成する可能性があります。
2. パブリッシャーで生成される重複
少なくとも 1 回はパブリッシュが行われることを保証するために、パブリッシャーが Pub/Sub にメッセージをパブリッシュする際に重複が生成される場合があります。このような重複は、「パブリッシャーで生成される重複」と呼ばれます。
Pub/Sub は、トピックに正常にパブリッシュされたメッセージごとに、一意の message_id を自動的に割り当てます。Pub/Sub が確認応答をパブリッシャーに返すと、各メッセージがパブリッシャーにより正常にパブリッシュされたとみなされます。1 つのトピック内のすべてのメッセージに message_id が付与され、また複数のメッセージが同じ message_id を持つことはありません。何かしらの理由(ネットワーク遅延や中断など)でパブリッシュの成功が確認できない場合は、同じメッセージ ペイロードがパブリッシャーにより再試行される場合があります。再試行が発生した場合の結果として、異なる message_id を持つ重複メッセージが Pub/Sub に入る可能性があります。Pub/Sub では、これらのメッセージは異なる message_id を持つため、一意のメッセージとしてみなされます。
3. Pub/Sub からの読み取り
Pub/Sub では、すべてのサブスクリプションで少なくとも 1 回の配信が保証されます。つまり、Pub/Sub が確認応答を期限までに受け取らなかった場合、同じサブスクリプションで 1 つのメッセージが複数回配信される可能性があります。サブスクライバーが期限後に確認応答を行うことも、一時的なネットワークの問題で確認応答が失われることもあります。このような場合、同じメッセージが再度配信され、サブスクライバー側でデータの重複が確認されることになります。Dataflow などのサブスクライブ システムは、このような重複を検出して適宜処理する機能を担っています。
Dataflow は Pub/Sub サブスクリプションからメッセージを受け取ると、最初の融合ステージでそのメッセージを正常に処理してから確認応答を返します。Dataflow は融合という最適化を行い、これにより複数のステージが単一の融合ステージにまとめられます。融合の中断は、GROUP BY、COMBINE、BigQueryIO などの I/O 変換を含む変換がありシャッフルが発生する場合に起こります。メッセージがその期限までに確認応答されない場合、Dataflow は Pub/Sub からのメッセージの再配信を防ぐために、確認応答の期限を繰り返し延期して、メッセージのリースを維持しようとします。ただし、この機能はベストエフォート型であるため、メッセージが再度配信される可能性はあります。また、こちらに記載されている指標を用いて、この機能をモニタリングできます。
ただ、Pub/Sub は各メッセージに一意の message_id を付与して配信するため、組み込みの Apache Beam PubsubIO を使用している場合、Dataflow はデフォルトでこの ID を使用してメッセージの重複除去を実行します。そのため、このような Pub/Sub からの同じメッセージの再配信に起因する重複は、Dataflow で除外できます。このトピックの詳細については、以前のブログの「ソースの例: Cloud Pub/Sub」セクションをご覧ください。
4. Dataflow でのデータ処理
Dataflow の処理の分散性のために、異なる Dataflow ワーカーで各メッセージが複数回試行されることがあります。ただし、Dataflow では、このような試行のうちの 1 つのみが採用され、それ以外の処理は以降の融合ステージに影響しないことが保証されます。Dataflow は各ステージでチェックポイントを活用して、このような重複が再処理されて状態や出力に影響しないようにすることで、正確に 1 回の処理を保証します。これを達成する方法についての詳細は、こちらのブログをご覧ください。
5. シンクへの書き込み
各要素が Dataflow ワーカーにより複数回試行されて、重複する書き込みが発生する場合があります。シンクは、このような重複を検出して適宜処理する機能を担っています。シンクによりますが、重複がある場合、除外、上書き、重複として表示のいずれかの処理がなされます。
シンクとしてのファイル システム
ファイルを書き込む場合、失敗時の Dataflow ワーカーによる再試行はファイルを上書きするため、正確に 1 回の処理が保証されます。Beam には、ファイルを書き込むためのいくつかの I/O コネクタが用意されており、これらすべてが正確に 1 回の処理を保証します。
シンクとしての BigQuery
組み込みの Apache Beam BigQueryIO を使用して、ストリーミング挿入でメッセージを BigQuery に書き込む場合、Dataflow は再試行に対し一貫した insert_id(Pub/Sub の message_id とは異なる)を発行し、これが BigQuery での重複除去に使用されます。ただ、この重複除去はベストエフォート型であるため、重複する書き込みが発生する可能性はあります。BigQuery では、以下に示すその他の挿入メソッドも利用できます。なお、重複除去の保証はそれぞれ異なります。
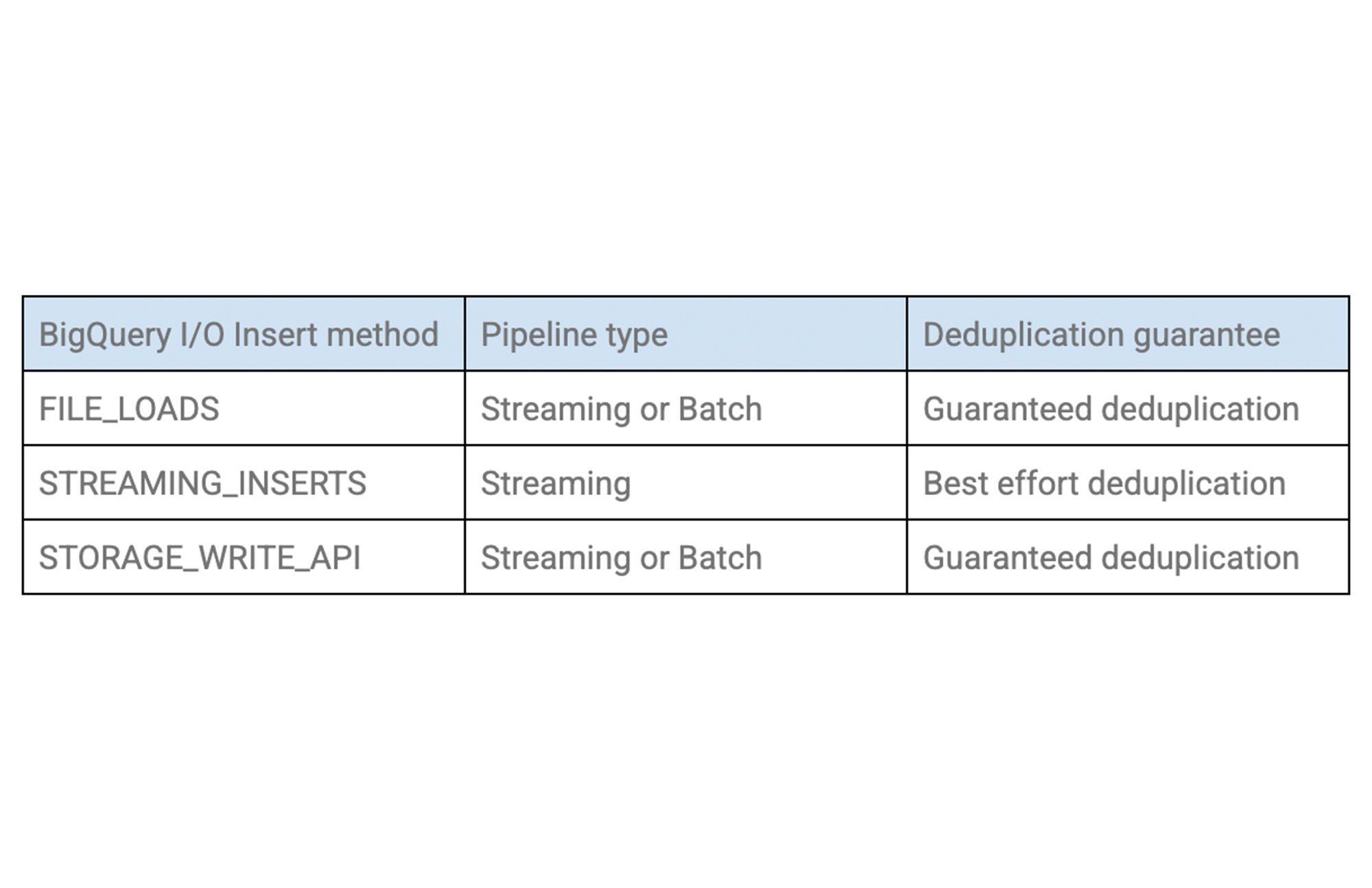
BigQuery の挿入メソッドに関する詳細については、BigQueryIO Javadoc をご覧ください。また、シンクとしての BigQuery に関する詳細については、以前のブログの「シンクの例: Google BigQuery」のセクションをご覧ください。
ポイント 3、4、5 で発生する重複については、すでに説明したように、(BigQuery がシンクである場合に限り)このような重複を除去する組み込みのメカニズムがあります。以下のセクションでは、「ソースで生成される重複」と「パブリッシャーで生成される重複」の重複除去オプションについて説明します。どちらの場合も、message_id が異なる重複メッセージが生成され、これらは Pub/Sub とそのダウンストリーム システム(Dataflow など)では 2 つの一意のメッセージとみなされます。
ソースで生成される重複とパブリッシャーで生成される重複向けの重複除去オプション
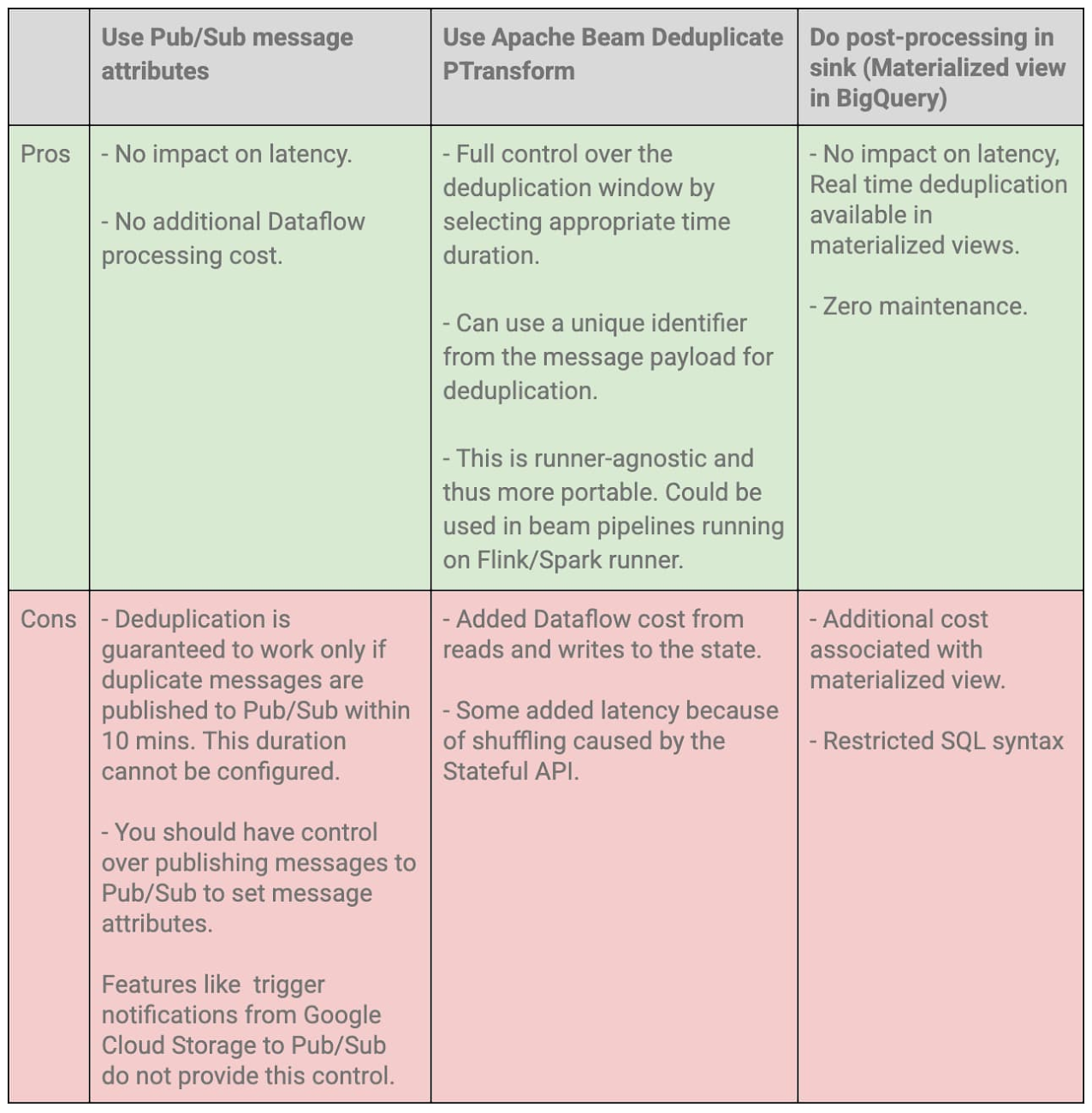
1. Pub/Sub メッセージ属性を使用する
Pub/Sub トピックにパブリッシュされる各メッセージの PubsubMessage の「属性」フィールドには、メタデータとして文字列の Key-Value ペアを付与できます。これらの属性は、Pub/Sub へのパブリッシュ時に設定されます。たとえば、Python Pub/Sub クライアント ライブラリ を使用している場合、publish メソッドの「attrs」パラメータをメッセージのパブリッシュ時に設定できます。メッセージの独自のフィールド(event_id など)を属性値として設定し、フィールド名を属性キーとして設定できます。
Dataflow では、Pub/Sub message_id を使用するデフォルトの重複除去オプションではなく、これらのフィールドを使用したメッセージの重複除去を行うように構成できます。これを行うには、組み込みの PubsubIO を使用して Pub/Sub からの読み取り時に属性キーを指定します。
Java SDK の場合は、PubsubIO.Read() の withIdAttribute メソッドでこの属性キーを以下のように指定します。
Python SDK の場合、ReadFromPubSub PTransform の id_label パラメータで、以下のようにこれを指定します。
Pub/Sub メッセージ属性を使用するこの重複除去オプションは、互いに 10 分以内に Pub/Sub にパブリッシュされた重複メッセージに対してのみ機能することが保証されます。
2. Apache Beam の重複除去用 PTransform を使用する
Apache Beam では重複除去用に PTransform が用意されており、これを使用して一定期間中の受信メッセージの重複除去ができます。重複除去は、メッセージまたは Key-Value ペアのキーに基づいて行えます。キーは、メッセージ フィールドから取得できます。重複除去ウィンドウは、withDuration メソッドを使用して構成できます。このメソッドでは、処理時間やイベントタイム(withTimeDomain メソッドを使用して指定)を基にできます。この値のデフォルト値は 10 分です。
PTransform の詳しい仕組みについては、Java のドキュメントかPython のドキュメントをご覧ください。
この PTransform は、内部で Stateful API を使用して、監視される各キーの状態を維持します。重複除去ウィンドウに収まる同じキーを持つ重複メッセージは、この PTransform により破棄されます。
3. シンクで後処理を行う
重複除去はシンクで行うこともできます。これは、一意の識別子を使用して行を定期的に重複除去するスケジュールされたジョブを実行することで行えます。
シンクとしての BigQuery
BigQuery がパイプラインのシンクの場合、重複除去されたデータを他のテーブルに書き込む、既存のテーブルを更新するなどの操作を行うスケジュールされたクエリを定期的に実行できます。スケジューリングの複雑さによっては、クエリのスケジュールで Cloud Composer や Dataform などのオーケストレーション ツールが必要になる場合があります。
重複除去は、DISTINCT ステートメントや MERGE などの DML を使用して行えます。このメソッドのサンプルクエリについては、こちらのブログ(ブログ 1、ブログ 2)をご覧ください。
多くの場合、ストリーミング パイプラインでは、重複除去されたデータが BigQuery でリアルタイムで必要になる場合があります。これは、DISTINCT ステートメントを使用して、基になるテーブルの上にマテリアライズド ビューを作成することで達成できます。
基になるテーブルが新たに更新されると、マテリアライズド ビューもメンテナンスやオーケストレーションなしでリアルタイムで更新されます。
さまざまな重複除去オプションの技術的トレードオフ
-クラウドデータ エンジニア Zeeshan Khan
