After Lambda: Exactly-once processing in Google Cloud Dataflow, Part 1
Reuven Lax
Software Engineer
Google Cloud Dataflow, the fully-managed service for stream processing of data on Google Cloud Platform (GCP), provides exactly-once processing of every record. What does this mean, and why is it important for customers?
It almost goes without saying that for many customers, any risk of dropped records or data loss is unacceptable. Even so, many general-purpose streaming systems predating Cloud Dataflow make no guarantees about record processing — it’s “best effort” only. Other systems provide at-least-once guarantees, ensuring that records are always processed at least once (and thus which might be duplicated); in practice, many such at-least-once systems perform aggregations in memory, and thus even they can lose data.
As a result, one common strategy — sometimes called the Lambda architecture — is to run a streaming system with weak semantics, and then calculate the correct answer the next day using a batch system (and then only if the data source is replayable, which is often not the case for streaming sources). However, many customers experience the following with Lambda architecture:
- Inaccuracy: Users tend to underestimate the impact of failures. They often assume that a small percentage of records will be lost or duplicated (often based on experiments they ran), and are shocked on that one bad day when 10% of records are lost or duplicated. In a sense, such systems provide only “half” a guarantee — and without a full one, anything is possible.
- Inconsistency: The batch system used for the end-of-day calculation often has different data semantics than the streaming system. Engineers can struggle with tweaking the two pipelines to ensure they're calculating the same results.
- Complexity: By definition, Lambda requires you to write and maintain two different codebases. You also have to run and maintain two complex distributed systems, each with different failure modes. For anything but the simplest of pipelines, this quickly becomes overwhelming.
- Unpredictability: In many use cases, end-users will see streaming results that differ from the daily results by an uncertain amount, which can change randomly. In these cases, users will stop trusting the streaming data and wait for daily batch results instead, thus destroying the whole purpose of a streaming system.
- Latency: Some business use cases require low-latency correct results, which the Lambda architecture does not provide by design.
Accuracy vs. completeness
As described previously, if a record is processed by a pipeline in Cloud Dataflow, we ensure that it is never dropped or duplicated. However, the nature of streaming pipelines is such that records sometimes show up late, after aggregates for their time windows have already been processed. Apache Beam, the unified programming model for stream/batch processing to which Cloud Dataflow SDKs are transitioning in their 2.x releases, allows the user to configure how long the system should wait for late data to arrive — any (and only) records arriving later than this deadline are dropped. This feature contributes to completeness, not to accuracy: All records that showed up in time for processing are accurately processed exactly once, while these late records are explicitly dropped.While we usually worry about late records when discussing streaming systems, it’s worth noting that batch pipelines have similar completeness issues. For example, a common batch paradigm is to run a job at 2am over all the previous day’s data. However, if some of yesterday’s data wasn’t collected until after 2am, it won’t be processed by the batch job! Thus batch pipelines also provide accurate, but not always complete, results.
Side effects
One characteristic of Apache Beam and Cloud Dataflow is that users inject custom code that is executed as part of their pipeline graph. Cloud Dataflow does not guarantee that this code is run only once per record, whether by the streaming or batch runner. It might run a given record through a user transform multiple times, or it might even run the same record simultaneously on multiple workers; this is necessary to guarantee at-least once processing in the face of worker failures. Only one of these invocations can “win” and produce output further down the pipeline.However, side effects are not guaranteed; if you write code that has side effects external to the pipeline such as contacting an outside service, these effects might be executed more than once for a given record. This situation is usually unavoidable, as there is no way to atomically commit Cloud Dataflow’s processing with the side effect on the external service.
Consider a simple streaming Cloud Dataflow pipeline.
The purpose of this pipeline is to compute two different windowed aggregations. The first counts how many events came from each individual user over the course minute, and the second counts how many total events came in each minute. Both aggregations are written to unspecified streaming sinks. Remember that Cloud Dataflow executes pipelines on many different workers in parallel. After each GroupByKey (the Count operations use GroupByKey under the covers), all records with the same key are processed on the same machine in a process called a shuffle. The Cloud Dataflow workers shuffle data between themselves using RPCs, ensuring that records for a given key all end up on the same machine.
The following diagram shows the shuffles created by the above pipeline. The Count.perKey shuffles all the data for each user onto a given worker, while the Count.globally shuffles all these partial counts to a single worker to calculate the global sum.
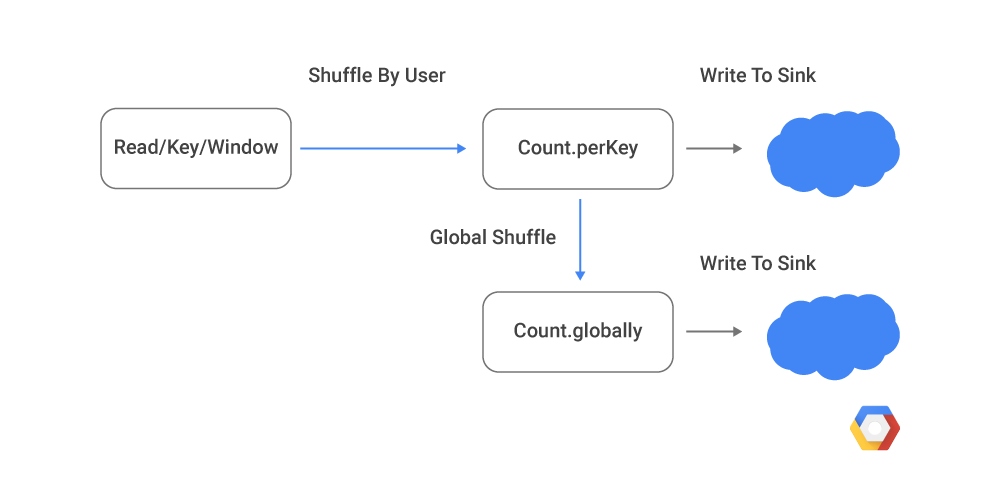
For Cloud Dataflow to accurately process data, this shuffle process must ensure that every record is shuffled exactly once. As you'll see below, the distributed nature of shuffle makes this a challenging problem. This pipeline also both reads and writes data to the outside world, so Cloud Dataflow must ensure that this interaction does not introduce any inaccuracies. Cloud Dataflow has always supported this task — what Apache Spark and Apache Flink call end-to-end exactly once—for Sources and Sinks whenever technically feasible.
Ensuring exactly-once in shuffle
As explained above, Cloud Dataflow’s streaming shuffle uses RPCs. Now, any time you have two machines communicating via RPC, you should think long and hard about data integrity. First of all, RPCs can fail for many reasons. The network might be interrupted, the RPC might time out before completing, or the receiving server might decide to fail the call. To guarantee that records are not lost in shuffle, Cloud Dataflows employs upstream backup. This simply means that the sender will retry RPCs until it receives positive acknowledgement of receipt. Cloud Dataflow also ensures that it will continue retrying these RPCs even if the sender crashes. This guarantees that every record is delivered at least once.Now, the problem is that these retries might themselves create duplicates. Most RPC frameworks, including the one Cloud Dataflow uses, provide the sender with a status indicating success or failure. In a distributed system, you need to be aware that RPCs can sometimes succeed even when they've appeared to fail. There are many reasons for this: race conditions with the RPC timeout, the positive acknowledgement from the server might fail to transfer even though the RPC has succeeded, and so on. The only status that a sender can really trust is a successful one.
An RPC returning a failure status generally indicates that the call may or may not have succeeded. Although specific error codes can communicate unambiguous failure, many common RPC failures, such as Deadline Exceeded, are ambiguous. In the case of streaming shuffle, retrying an RPC that really succeeded means delivering a record twice! Thus, Cloud Dataflow needs some way of detecting and removing these duplicates.
At a high level, the algorithm for this task is quite simple: Every message sent is tagged with a unique identifier. Each receiver stores a catalog of all identifiers that have already been seen and processed. Every time a record is received, its identifier is looked up in this catalog. If it's found, then the record is dropped as a duplicate. As Cloud Dataflow is built on top of a key-value store (Google Cloud Bigtable), this store is used to hold the deduplication catalog.

Addressing determinism
Making this strategy work in the real world requires a lot of care, however. One immediate wrinkle is that the Apache Beam model allows for user code to produce non-deterministic output. That means that a ParDo can execute twice on the same input record (due to a retry), yet produce different output on each retry. The desired behavior is that only one of those outputs will commit into the pipeline; however, the non-determinism involved makes it difficult to guarantee that both outputs have the same deterministic id. Even trickier, a ParDo can output multiple records, so each of these retries might produce a different number of outputs!So, why we don’t simply require that all user processing be deterministic? Our experience is that in practice, many pipelines require non-deterministic transform (and all too often, pipeline authors do not realize that the code they wrote is non-deterministic). For example, consider a transform that lookups supplemental data in Cloud Bigtable in order to enrich its input data. This is a non-deterministic task, as the external value might change in between retries of the transform. Any code that relies on current time is likewise not deterministic, and we've also seen transforms that need to rely on random inputs. Even if the user code is purely deterministic, any event-time aggregation that allows for late data might have non-deterministic inputs.
Cloud Dataflow addresses this issue by using checkpointing to make non-deterministic processing effectively deterministic. Each output from a transform is checkpointed, together with its unique id, to stable storage before they're delivered to the next stage (and a lot of care is taken to make sure it’s done efficiently). Any retries in the shuffle delivery simply replay the output that has been checkpointed—the user’s non-deterministic code is not run again on retry. To put it another way, the user’s code may be run multiple times but only one of those runs can “win.” Furthermore, Cloud Dataflow uses a consistent store that allows it to prevent duplicates from being written to stable storage.




