Dataproc で AI/ML 対応の Apache Spark を実現
Vaibhav Sethi
Senior Product Manager
Jayadeep Jayaraman
Senior Staff Software Engineer, Google
【Next Tokyo ’26】
【Next Tokyo 】 7 月 30 日、31 日 東京ビッグサイトにて開催!エンジニアもビジネス リーダーも。新しいアイデアを、AI とクラウドで実現しよう。
今すぐ登録※この投稿は米国時間 2025 年 7 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Spark は、AI/ML ワークロードの大規模なデータ処理、モデルのトレーニング、推論の基盤です。しかし、環境構成、依存関係管理、MLOps 統合の複雑さによって、作業が遅くなる可能性があります。AI/ML の取り組みを加速させるために、Dataproc は Spark 向けの ML 対応の強力な機能を提供します。Compute Engine クラスタ上の Dataproc と Apache Spark 向け Google Cloud Serverless の両方で利用できるこれらの機能強化は、開発と運用の合理化、セットアップのオーバーヘッドの削減、ワークフローの簡素化を目的として設計されています。これにより、データ サイエンティストとエンジニアは、インフラストラクチャの管理に時間を取られることなく、影響力の大きいモデルの構築とデプロイに時間を費やすことができます。
新機能と、これらのイノベーションを今すぐ使い始める方法について見ていきましょう。
AI/ML 対応ランタイム
ML 用の Spark 環境、特に GPU アクセラレーションを使用した環境を準備するには、カスタム スクリプトと手動構成が必要でした。Dataproc では、ML ランタイムによってこのプロセスが合理化されます。ML ランタイムは、ML ワークロードを高速化するために設計された、Ubuntu ベースのイメージの 2.3 以降を対象とする、Compute Engine イメージ バージョン上の Dataproc の特殊なものです。GPU ドライバ(NVIDIA ドライバ、CUDA、cuDNN、NCCL)と、PyTorch、XGBoost、トークナイザー、トランスフォーマーなどの一般的な ML ライブラリが事前にパッケージ化されているため、クラスタのプロビジョニングとセットアップの時間を大幅に短縮できます。
Apache Spark 向け Google Cloud Serverless は、ML ライブラリがプリインストールされたランタイムのメリットも享受し、サーバーレス環境でも同じ使いやすさを実現します。これらには、XGBoost、PyTorch、トークナイザー、トランスフォーマーなどのライブラリも含まれます。
「Snap では、GPU アクセラレーテッド Spark Rapids の実行、PyTorch を使用したモデルのトレーニングと推論など、さまざまな分析と ML ワークロードに Dataproc 上の Spark を使用しています。新しい Dataproc 2.3 ML ランタイムは非常に役立っています。クラスタの起動レイテンシが 75% 削減され、ML プラットフォーム デベロッパーが環境を構築、管理する際のトイルがなくなりました」- Snap Inc.、シニア マネージャー、Prudhvi Vatala 氏
ML イメージのバージョンと、ワーカーに必要な GPU アクセラレータを指定するだけで、簡単に Compute Engine クラスタで Dataproc を作成できます。
さらに、サーバーレス Spark セッション(一般提供)も GPU をサポートしており、GPU ドライバと一般的な ML ライブラリが同様にパッケージ化されています。
Colab またはお気に入りの IDE で Spark アプリケーションを開発
BigQuery Studio の Colab Enterprise ノートブックを使用するか、VSCode や Jupyter などの統合開発環境(IDE)を介して、Spark アプリケーションを開発および実行できます。
BigQuery Colab Enterprise ノートブックは、Spark アプリケーション開発のネイティブ サポートを備えた BigQuery Studio 内で利用できます。Colab Enterprise ノートブックでは、Spark Connect を使用してサーバーレス Spark セッションを作成し、BigLake Metastore でテーブルを操作できます。
Colab ノートブックは、生成 AI によるコード支援やエラーの説明などの高度な機能を提供しており、エラー修正機能も近日中に提供される予定です。また、Spark ジョブのオブザーバビリティと Spark セッションの管理もサポートします。さらに、Colab ノートブックでは、1 つのノートブックで BigQuery SQL と Spark コードを混在させ、結果のテーブルを相互運用できます。コードの準備ができたら、組み込みのスケジューリング機能を使用してノートブックをスケジュール設定するか、より複雑な DAG には BigQuery パイプラインを使用できます。
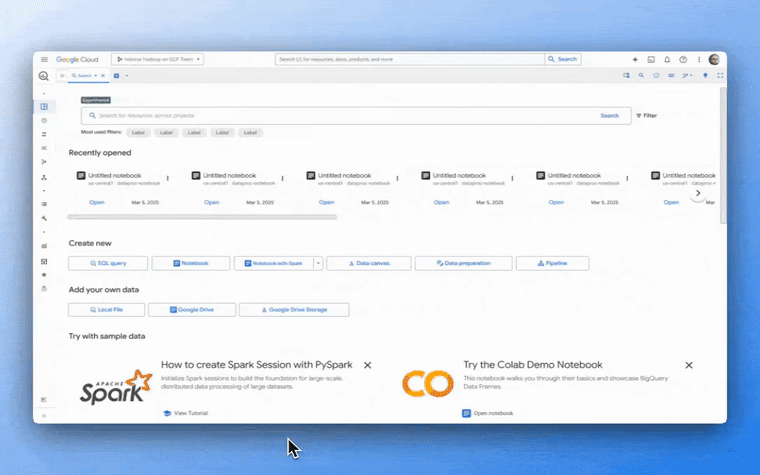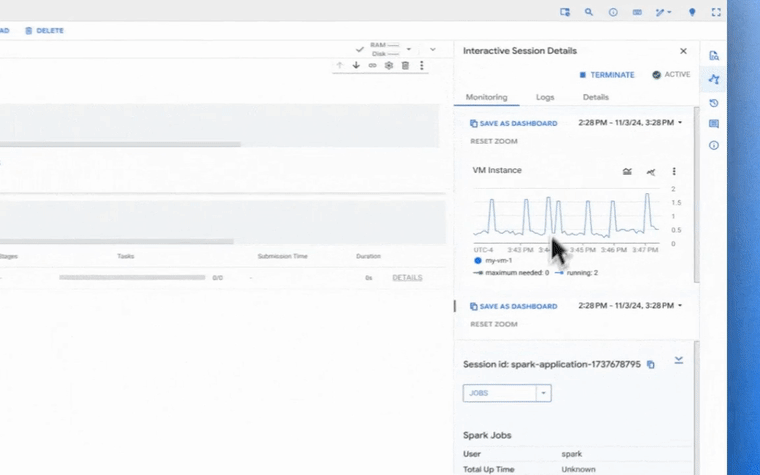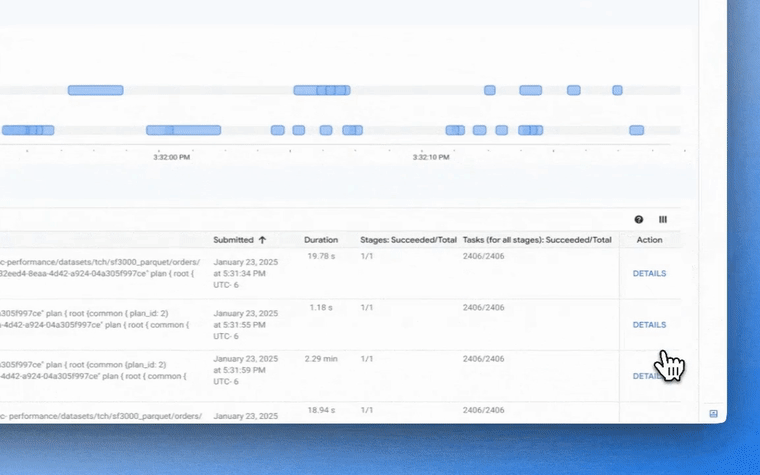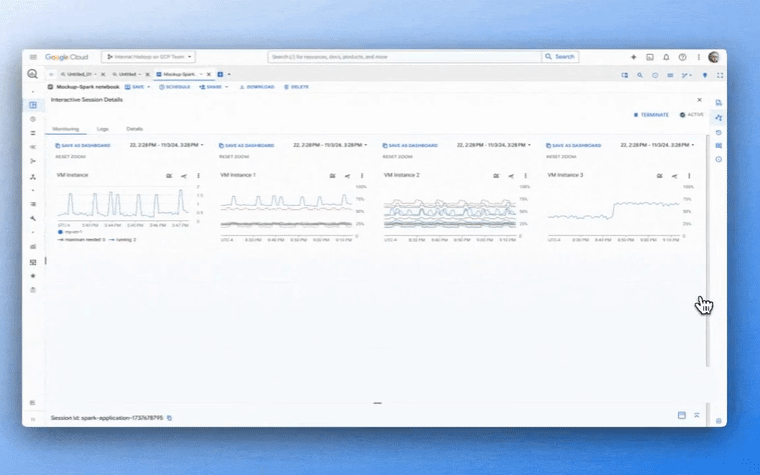
Spark アプリケーション開発には、Visual Studio Code や JupyterLab などの IDE を使用することもできます。JupyterLab ユーザーは、Dataproc JupyterLab プラグインを使用して、Spark サーバーレス セッションでのインタラクティブな開発を簡素化し、サーバーレス バッチジョブを介したバッチジョブの作成と送信を簡素化できます。このプラグインは Vertex Workbench にプリインストールされているため、すぐに生産性を高めることができます。

VS Code では、Cloud Code 拡張機能を使用できます。この拡張機能は、さまざまな Google Cloud サービスに対する開発をサポートしています。Cloud Code 拡張機能を構成すると、BigQuery データセットとテーブルの参照、Dataproc コンピューティング リソース(クラスタ、サーバーレスのインタラクティブ セッションとバッチ)の参照と管理、利用可能なテンプレートからの Spark ノートブックの作成、独自の開発の開始、ワークロードのスケジュール設定をすべて VS Code から行うことができます。開発ツールを自由に選択できるため、Dataproc Spark の機能を利用しながら、ワークフローに最適なツールを選択できます。
GPU サポートによる分散トレーニングと推論
Dataproc の ML ランタイムは、XGBoost、TensorFlow、PyTorch などのフレームワークを活用して分散トレーニングと推論を実行するように構築されており、すべて GPU 利用向けに事前構成されています。たとえば、Spark 上の XGBoost を使用した分散トレーニングでは、事前インストールされた xgboost.spark ライブラリを活用できます。num_workers などのパラメータを設定してタスクを Spark エグゼキュータに分散し、device=”cuda” を設定することで、複数の GPU でモデルを効果的にトレーニングし、大規模なデータセットのトレーニング プロセスを大幅に高速化できます。Spark クラスタで分散 GPU トレーニングを行うように XGBoost 分類器を構成する例を次に示します。
Spark Connect のインタラクティブな環境のカスタマイズ
Spark Connect を使用する Colab ノートブックなど、Spark をインタラクティブに使用する場合、クライアントと Spark クラスタ間で Python ライブラリの整合性を確保することが重要です。Dataproc は、addArtifacts メソッドを拡張することで、PyPI パッケージを Spark セッションに動的に追加する処理を簡素化します。version-scheme でインストール/アップグレード/ダウングレードするパッケージのリストを指定できるようになりました(pip install と同じ)。これにより、Spark Connect サーバーにパッケージとその依存関係をインストールするよう指示し、UDF やその他のコードのワーカーで使用できるようにします。
さらに、初期化スクリプトとカスタム イメージを使用して、Dataproc 上の Spark 環境をカスタマイズすることもできます。
Vertex AI による MLOps
Dataproc は、AI と ML のための Google Cloud の統合プラットフォームである Vertex AI と連携して、Spark を使用した AI/ML ワークフローの MLOps を改善します。Dataproc Spark コード内で Vertex AI SDK を直接使用すると、テストのトラッキングとモデルの管理が可能になり、次のことが実現します。
-
テストの追跡: Dataproc Spark トレーニング ジョブから Vertex AI Experiments に、ログパラメータ、指標、アーティファクトを追跡します。これにより、実行の比較、結果の可視化、実験の確実な再現が可能になります。
- モデルの登録: トレーニングが完了したら、トレーニング済みモデルを Vertex AI Model Registry に登録します。これにより、モデルのバージョン管理、ステージング、ガバナンスのための一元化されたリポジトリが提供され、デプロイまでのパスが簡素化されます。
この統合により、組織のより広範な MLOps 戦略に従って、Spark 上の AI/ML ワークロードをより管理しやすく、再現可能で、デプロイ可能にできます。
本番環境にデプロイ
インタラクティブな開発から本番環境への移行が簡単。
開発に BigQuery Colab ノートブックを使用すると、Git サポートによりコードのバージョン管理と CI/CD フローの実行が可能になります。また、BigQuery の組み込みのパイプライン機能を使用して Spark ノートブックをスケジュールすることもできます。この機能を使用すると、単一のスケジュールされたノートブックや、複数のノートブックやクエリをチェーンするより複雑な DAG を作成できます。これらのパイプラインは、ユーザー アカウントまたは本番環境パイプライン用のサービス アカウントを使用して実行できます。
BigQuery パイプラインでは、フローを個別のタスクに構成できるため、Dataproc 上の Apache Spark と BigQuery の実行を組み合わせることができます。次の BigQuery パイプラインでは、最初のタスクで BigQuery クエリを介して未加工データを取り込み、ノートブック タスクを介して Apache Spark でデータを変換します。このノートブックには、関連する Spark 変換ステップが含まれています。最後に、グラフは 2 つの並列タスクに分割されます。1 つは前のタスクの出力に基づいてレポートを生成するノートブック、もう 1 つは最初に取り込んだデータをクリーンアップする最終的なクエリです。

IDE を使用する場合は、これらの IDE の Git クライアントを使用して Spark コードをバージョン管理することで、同様のフローを実現できます。Google Cloud のマネージド サーバーレス Apache Airflow サービスである Cloud Composer を使用して、パイプラインを作成してデプロイすることもできます。ジョブは、既存の Dataproc クラスタ、エフェメラル ジョブクラスタ、または Serverless Batch で実行できます。
AI/ML 対応の Apache Spark
Dataproc を使用すると、Apache Spark で AI/ML ワークロードをより簡単に構築できます。Dataproc は、GPU をサポートする事前構成済みの ML ランタイムの提供、Spark Connect によるインタラクティブ セッションの Python 依存関係管理の簡素化、好みの IDE からの開発の実現、MLOps 向けの Vertex AI とのシームレスな統合により、ML ライフサイクル全体を加速します。探索とトレーニングから、本番環境に対応した堅牢な Spark ML パイプラインに移行できます。Dataproc のドキュメントで詳細を確認し、これらの機能を活用しましょう。
-Google、プロダクト マネージャー Vaibhav Sethi
-Google、シニア スタッフ ソフトウェア エンジニア Jayadeep Jayaraman


