今月の新情報: リアルタイム ストリーミングのリーダーシップから、インテリジェントなデータ ファブリックと分析エクスチェンジまで
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
データ分析のプロダクト イノベーションに関して、5 月は盛りだくさんの月でした。今回初開催となった Data Cloud Summit にご参加いただけなかった方も、すべてのセッションの動画リプレイが可能になっていますので、ご自分のペースでご視聴いただけます。
今回のブログでは、5 月にリリースしたイノベーションのバックグラウンドと、なぜこの方法で構築したのか、そしてこの機能が会社やチームにどのような価値をもたらすのかをご紹介します。
最初に、皆様に感謝の気持ちをお伝えします
今週、Google は The Forrester Wave™: Streaming Analytics, Q2 2021 レポートにてリーダーに選出されました。「Google Cloud Dataflow は、データ シーケンシング、高度な分析、パフォーマンス、高可用性の分野で優れている」として、Forrester は 12 の異なる基準において、Dataflow に 5 段階中で 5 の評価を付けました。
Google には、Google が独自に使用するためにリアルタイムかつインターネット規模のシステムを構築してきた 10 年以上の実績があります。信頼性、スケーラビリティ、パフォーマンスに優れたプラットフォームをお客様に提供してきた成果が実を結んでいることを嬉しく思います。
今回の発表は、Google Cloud も同じくリーダーとして選出された、The Forrester Wave™: Cloud Data Warehouse, Q1 2021 レポートのリリースを受けて行われました。
データを活用したイノベーションを推進するというお客様の目標をサポートすべく Google が行っている活動に対して、お客様からいただくフィードバックと信頼にこの上なく感謝しております。
イノベーションの数々
お客様からいただくフィードバックと情熱は、より多く、より良いサービスをお客様にお届けするための Google の原動力となっています。そのため、今年は Google Cloud Next まで待たずに、これまで Google が開発してきた素晴らしいプロダクトを紹介したいと考えました。5 月 26 日、Google のチームは、新しいプロダクト、サービス、プログラムを次々と発表しました。こちらからそのサマリーをご覧ください。

既存の環境を変えずに機能を拡張
Google が提供するすべてのサービスの背後にある重要な設計方針は、「既存の環境を変えずに機能を拡張」です。つまり、お客様が思うままにイノベーションを起こすために必要なツールやソフトウェアを提供することを目指しています。ここでは役立つ 3 つの新しいサービスをご紹介します。
Datastream
Datastream は、新しいサーバーレスのチェンジ データ キャプチャ(CDC)およびレプリケーション サービスで、異種のデータベース、ストレージ システム、アプリケーション間でデータを確実に、かつ最小限のレイテンシで同期し、リアルタイム解析、データベース レプリケーション、イベント ドリブン アーキテクチャをサポートできます。Datastream は、Oracle および MySQL データベースからBigQuery、Cloud SQL、Cloud Storage、Cloud Spanner などの Google Cloud サービスに変更ストリームを配信し、時間とリソースを節約しつつ、データを高精度かつ最新に保つことができます。
内部では、Datastream が CDC のイベント(挿入、更新、削除)をソース データベースから読み取り、それらのイベントを最小限のレイテンシでデータ移行先に書き込みます。これは、各データベース ソースが独自の CDC ログ(MySQL の場合は binlog、Oracle の場合は LogMiner)を備えていることを利用しており、独自の内部レプリケーションと整合性の目的で使用しています。
Datastream は、専用の拡張可能な Dataflow テンプレートと統合して、Cloud Storage に書き込まれた変更ストリームを pull し、分析用の最新の複製テーブルを BigQuery に作成します。また、Dataflow テンプレートを活用してデータベースを複製し、Cloud SQL や Cloud Spanner に同期して、データベースの移行とハイブリッド クラウド構成を実現します。
さらに、Datastream は、Cloud Data Fusion の新しいレプリケーション機能で Google ネイティブの Oracle コネクタを強化し、ETL / ELT パイプライン作成を容易にします。変更ストリームを Cloud Storage に直接配信することで、お客様は Datastream を活用して最新のイベント ドリブン アーキテクチャを実装できます。
Microsoft Azure で利用可能な Looker および BigQuery Omni
マルチクラウドの導入に関する調査結果は明白で、2021 年には 92% の企業がマルチクラウド戦略を行っていると報告しています。お客様が戦略を実行するために必要な柔軟性を提供することで、Google は、お客様の選択をサポートし続けたいと考えています。
先月、Microsoft Azure 上でホストされている Looker をリリースしました。今回初めて、Looker のインスタンスに Azure、Google Cloud、AWS のいずれかを選択できるようになりました。また、Looker インスタンスをオンプレミスでセルフホストすることも可能です。
また、昨年リリースされた BigQuery Omni for AWS に続く、BigQuery Omni for Azure がリリースされ、Google Cloud、AWS、Azure のデータにアクセスし安全に分析できるようになりました。
クラウド プロバイダ間でデータを移動する費用は、多くの会社にとって持続可能なものではなく、クラウドをまたいでシームレスに作業するのは依然として困難です。BigQuery Omni は、複数のパブリック クラウドに保存されたデータを分析する新しい方法であり、BigQuery のコンピューティングとストレージの分離によって実現されています。この 2 つを切り離すことで、BigQuery は、Google Cloud やその他のパブリック クラウドに存在できるスケーラブルなストレージと、標準 SQL クエリを実行するステートレスで復元性に優れたコンピューティングを提供します。
他社製品とは異なり、BigQuery Omni では、データをパブリック クラウドから別のパブリック クラウドに移動またはコピーする必要がなく、下り(外向き)コストが発生することもありません。また、Google Cloud でも同じ BigQuery インターフェースを利用でき、クラウド間でデータの移動やコピーをすることなく、Google Cloud、AWS、Azure に保存されているデータに対してクエリを実行できます。
BigQuery Omni のクエリエンジンは、データが存在する同じリージョン内のクラスタで必要なコンピューティングを実行します。たとえば、Google Cloud に保存されている Google アナリティクス 360 の広告データに対してクエリを実行したり、AWS S3 や Microsoft Azure に保存されている e コマース プラットフォームやアプリケーションのログデータに対してクエリを実行したりできます。
そして Looker を活用し、広告費用とともにユーザーの行動や購入を可視化できるダッシュボードを作成できます。
Dataplex
ほとんどの組織は、複数のサイロにまたがって、組織内の多くの人やツールが分析のために高品質のデータを簡単に見つけ、アクセスできるようにすることに未だに苦労しています。
トレードオフを余儀なくされることも少なくありません。たとえば、多様な分析のユースケースを実現するために、サイロ間でデータを移動および重複させたり、データを分散したままにしつつ意思決定のアジリティを制限したりしています。
Dataplex は、インテリジェントなデータ ファブリックを提供しており、これによりデータレイク、データ ウェアハウス、データマートにまたがるデータを一元的に管理、モニタリング、統制できます。また、さまざまな分析ツールやデータ サイエンス ツールがデータに安全にアクセスできるようになります。
データの移動や重複を回避しつつ、ビジネスに有意義な方法でお客様がデータを整理および管理できるようにすることが、Dataplex の中心的な考え方の一つです。これを実現するため、Google ではレイク、データゾーン、アセットなどの論理構造を提供しています。これらの構成要素は基礎となるストレージ システムを抽象化して、データアクセス、セキュリティ、ライフサイクル管理などのポリシーを設定する基盤になります。
たとえば、組織内の部門(小売、販売、財務など)ごとにレイクを作成したり、データの即応性や使用状況(landing、raw、curated_data_analytics、curated_data_science など)に対応するデータゾーンを作成したりできます。
レイクとゾーンを一度設定すると、そのゾーンにはデータをアセットとしてアタッチできます。さまざまなタイプのストレージ(GCS バケットや BigQuery のデータセットなど)から取得したデータを同じゾーンに追加できます。同じゾーン内の複数のプロジェクトにデータをアタッチすることもできます。好きなツール(例: Dataflow、Data Fusion、Dataproc、Pub/Sub)を使用して、レイクとゾーンにデータを取り込めます。または、パートナー プロダクトから 1 つ選択することも可能です。Dataplex では、一般的なデータ管理タスクに使用する組み込みのワンクリック テンプレートも用意されています。
Dataplex の詳細については、cloud.google.com/dataplex をご覧いただくか、以下の動画をご覧ください。

毎日のイノベーションをサポート
データを共有するのは大変です。従来のデータ共有の手法ではバッチ データ パイプラインを使用しますが、これは運用コストが高く、処理に遅れて到着するデータが発生し、ソースデータに変更があると実行が失敗することがあります。また、こうした手法ではデータの複数のコピーが作成されるため、不要なコストが生じ、データ ガバナンス プロセスをすり抜ける可能性があります。さらに、サブスクリプションやアクセス権の管理といったデータの収益化に関する機能も備えていません。つまり、組織はこのような課題により、共有データを活用してビジネスを変革する可能性を最大限に発揮できていません。
Analytics Hub
このような従来の手法の限界に対処するために、Google は Analytics Hub をリリースしています。新しいフルマネージド サービスによって、組織はデータ共有の価値を活かせるようになり、新たな分析情報の獲得やビジネス価値の向上につなげることができます。
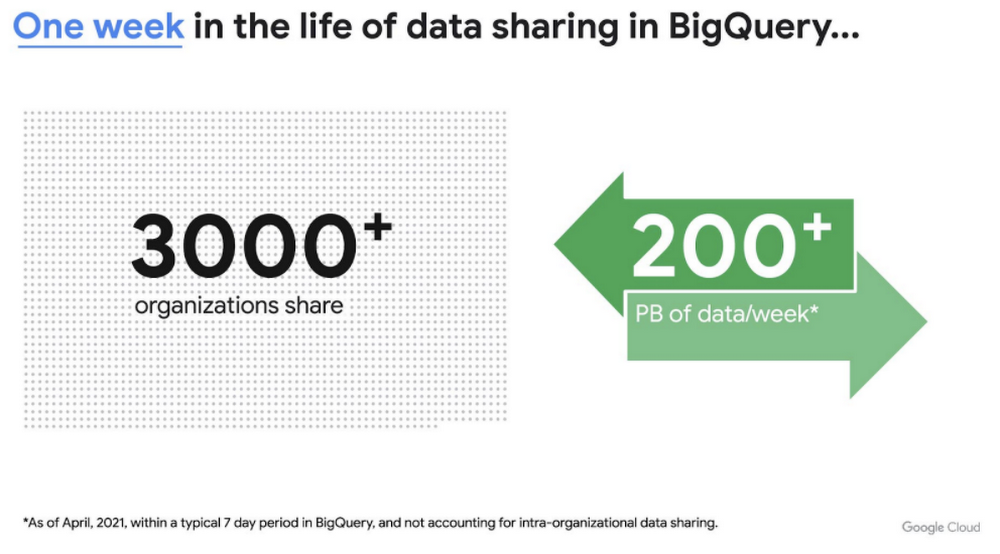
この新しいサービスは、これまでの多くの経験とお客様からいただいたフィードバックをもとに構築されています。たとえば、2010 年のリリース以来、BigQuery には組織を超えたインプレースのデータ共有機能が備わっており、この機能は特に好評です。4 月の 7 日間で 3,000 以上の組織が 200 ペタバイトを超えるデータを共有しました。この数値には、同じ組織内の部門間のデータ共有は含まれていません。
Analytics Hub によって、さらに上のレベルの共有が可能となります。貴重なデータセットの公開、発見、サブスクライブが容易になり、自社のデータと組み合わせて独自の分析情報を導き出すことができます。
以下に例を示します。
共有データセット: データ パブリッシャーとして、サブスクライバーに配信するデータのビューを含む共有データセットを作成します。データ サブスクライバーは、アクセス権を付与されているすべてのエクスチェンジで公開されているデータセットを検索して、関連するデータセットをサブスクライブできます。また、パブリッシャーは共有データに関して、サブスクライバーの追跡、サブスクリプションの無効化、使用状況の集計データの確認ができます。
キュレートされたセルフサービスのデータ エクスチェンジ: エクスチェンジとは、共有データセットを整理し、保護するためのコレクションです。デフォルトでは、エクスチェンジは完全にプライベートなものですが、きめ細かいロールと権限を設定することで、社内や社外を問わず、適切な対象者にデータを提供することが容易になります。
ここまでは Analytics Hub の第一歩にすぎません。2021 年第 3 四半期にリリース予定のプレビューにぜひお申し込みください。
Dataflow Prime
Google は Google Cloud にて、世界で特に革新的な組織と一緒に仕事ができるという素晴らしい特権を持っています。また、これにより、ビッグデータ処理の未来を占うユニークな視点を得ることができます。Dataflow Prime は、サーバーレス、NoOps、自動チューニング アーキテクチャに基づいた新しいプラットフォームで、ビッグデータ処理に優れたリソース使用率と操作の抜本的な簡素化をもたらします。この新しいサービスには、エキサイティングな機能が数多く導入されていますが、今回はプロダクトの 3 つのキーアスペクトについてご紹介します。
垂直自動スケーリング: Dataflow Prime は、使用率に基づいて各ワーカーに割り振られたコンピューティング容量を動的に調整し、ワーカー リソースでジョブが制限されていることを検出すると、自動的にリソースを追加します。垂直自動スケーリングは水平自動スケーリングと連携し、パイプラインのニーズに最適なワーカーをシームレスにスケールします。その結果、完璧なワーカーの構成を決定し使用率を最大化する作業に数時間から数日もかかることがなくなりました。
Right Fitting: パイプラインの各ステージには通常、他のステージとは異なるリソース要件があります。これまでは、パイプライン内のすべてのワーカーが大容量のメモリと GPU を使用していたか、いずれも使用していませんでした。パイプラインがリソースを浪費するか、ワークロードの遅延がパイプラインの負担になっていました。Right Fitting は、この問題を解決するために、ステージごとに最適化されたステージ固有のリソースプールを作成します。
スマート推奨事項: パイプラインの問題を自動的に検出して修正案を表示します。たとえば、パイプラインで権限の問題が発生している場合、スマート推奨事項はジョブのブロックを解除するために有効にする必要がある IAM 権限を検出します。非効率的なコーダーをジョブで使用している場合、スマート推奨事項により、パフォーマンスの高いコーダー実装が表示され、コストを節約できます。
次のステップ
これらの魅力的な新しいサービスに関して、皆様のご意見やご感想をお待ちしております。また、コミュニティのメンバーと交流し、メンバーの体験談をお聞きになることも強くおすすめいたします。たとえば、初開催となった Data Cloud Summit にて、Keybank と Rackspace の最高データ責任者とともに Data To Value の顧客パネルを作成しました。以下より無料でご覧いただけます。

-プロダクト管理担当シニア ディレクター Sudhir Hasbe



