New This Month: From leadership in real-time streaming to intelligent data fabric and analytics exchanges
Sudhir Hasbe
Sr. Director, Product Management
May was a very busy month for data analytics product innovation. If you didn’t have the chance to attend our inaugural Data Cloud Summit, video replays of all our sessions are now available so feel free to watch them at your own pace.
In this blog, I’d like to share some background behind the innovations we released in May, why we built them the way we did, and the type of value they can bring your company and your team.
But first, a huge thank you!
This week, we had the honor to announce that Google has been named a Leader in The Forrester Wave™: Streaming Analytics, Q2 2021 report. Forrester gave Dataflow a score of 5 out of 5 across 12 different criteria, stating: “Google Cloud Dataflow has strengths in data sequencing, advanced analytics, performance, and high-availability”.
Google has more than a decade of experience in building real-time and internet-scale systems for its own needs, and we are excited to see that our ability to provide customers with a reliable, scalable, and performant platform is bearing fruit.
This announcement comes on the back of the release of The Forrester Wave™: Cloud Data Warehouse, Q1 2021 report, which also named Google Cloud as a Leader.
We couldn’t be more excited about the recognition and appreciate all your feedback and trust in the work that we do to support your goal in accelerating data-powered innovation.
Innovation galore
Your feedback and your passion is the fuel that drives our ambition to deliver more and better services to you. That’s why, this year, we didn’t want to wait until Google Cloud Next to share some great products we have been working on. On May 26, our team announced a slew of new products, services and programs. Watch a quick summary below:

Meeting you where you are
An important design principle behind all of our services is “meeting you where you are”. This means we aim to provide you with the tools and software you need to innovate on your own terms. Here are three new services that will help you do just that:
Datastream
Datastream, our new serverless change data capture (CDC) and replication service, allows your company to synchronize data across heterogeneous databases, storage systems, and applications reliably and with minimal latency to support real-time analytics, database replication, and event-driven architectures. Datastream delivers change streams from Oracle and MySQL databases into Google Cloud services such as BigQuery, Cloud SQL, Cloud Storage, and Cloud Spanner, saving time and resources while ensuring your data is accurate and up-to-date.
- Under the hood, Datastream reads CDC events (inserts, updates, and deletes) from source databases, and writes those events with minimal latency to a data destination. It leverages the fact that each database source has its own CDC log—binlog for MySQL and LogMiner for Oracle—which it uses for its own internal replication and consistency purposes.
- Datastream integrates with purpose-built and extensible Dataflow templates to pull the change streams written to Cloud Storage, and create up-to-date replicated tables in BigQuery for analytics. It also leverages Dataflow templates to replicate and synchronize databases into Cloud SQL or Cloud Spanner for database migrations and hybrid cloud configurations.
- Datastream also powers a Google-native Oracle connector in Cloud Data Fusion’s new replication feature for easy ETL/ELT pipelining. By delivering change streams directly into Cloud Storage, customers can leverage Datastream to implement modern, event-driven architectures.
Looker and BigQuery Omni on Microsoft Azure
Research on multi cloud adoption is unequivocal — 92% of businesses in 2021 report having a multi cloud strategy. We want to continue supporting your choice by providing the flexibility you need to see your strategy through.
- This past month, we introduced Looker, hosted on Microsoft Azure. For the first time, you can now choose Azure, Google Cloud, or AWS for your Looker instance. You can also self-host your Looker instance on-premises.
- We also introduced BigQuery Omni for Azure, which along with last year’s introduction of BigQuery Omni for AWS, will help you access and securely analyze data across Google Cloud, AWS, and Azure.
The cost of moving data between cloud providers isn’t sustainable for many, and it’s still difficult to seamlessly work across clouds. BigQuery Omni represents a new way of analyzing data stored in multiple public clouds, which is made possible by BigQuery's separation of compute and storage. By decoupling these two, BigQuery provides scalable storage that can reside in Google Cloud or other public clouds, and stateless resilient compute that executes standard SQL queries.
- Unlike competitors, BigQuery Omni doesn’t require you to move or copy your data from one public cloud to another, where you might incur egress costs. You also benefit from the same BigQuery interface on Google Cloud, enabling you to query data stored in Google Cloud, AWS, and Azure without any cross-cloud movement or copies of data.
- BigQuery Omni’s query engine runs the necessary compute on clusters in the same region where your data resides. For example, you can query Google Analytics 360 Ads data stored in Google Cloud and query logs data from your ecommerce platform and applications that are stored in AWS S3 and/or Microsoft Azure.
Then, using Looker, you can build a dashboard that allows you to visualize your audience behavior and purchases alongside your advertising spend.
Dataplex
We understand that most organizations still struggle to make high-quality data easily discoverable and accessible for analytics, across multiple silos, to a growing number of people and tools within their organization.
They are often forced to make tradeoffs. For instance, moving and duplicating data across silos to enable diverse analytics use cases or leaving their data distributed but limiting the agility of decisions.
- Dataplex provides an intelligent data fabric that enables you to centrally manage, monitor, and govern your data across data lakes, data warehouses, and data marts, while also ensuring data is securely accessible to a variety of analytics and data science tools.
- One of the core tenets of Dataplex is letting you organize and manage your data in a way that makes sense for your business, without data movement or duplication. For that, we provide logical constructs like lakes, data zones, and assets. These constructs enable you to abstract away the underlying storage systems and become the foundation for setting policies around data access, security, lifecycle management, and so on.
- For example, you can create a lake per department within your organization (e.g. Retail, Sales, Finance, etc.) and create data zones that map to data readiness and usage (e.g. landing, raw, curated_data_analytics, curated_data_science, etc.).
Once you have your lakes and zones setup, you can attach data to these zones as assets. You can add data from different types of storage (e.g. GCS Bucket and BigQuery dataset) under the same zone. You can also attach data across multiple projects under the same zone. You can ingest data into your lakes and zones using the tools of your choice, including services such as Dataflow, Data Fusion, Dataproc, Pub/Sub, or choose from one of our partner products. Dataplex comes with built-in 1-click templates for common data management tasks.
To find out more about Dataplex, head to cloud.google.com/dataplex or watch the video below:

Helping you innovate everyday
Sharing data is hard. Traditional data sharing techniques use batch data pipelines that are expensive to run, create late arriving data, and can break with any changes to the source data. These techniques also create multiple copies of data, which brings unnecessary costs and can bypass data governance processes. They also fail to offer features for data monetization, such as managing subscriptions and entitlements. Altogether, these challenges mean that organizations are unable to realize the full potential of transforming their business with shared data.
Analytics Hub
To address these limitations, we are introducing Analytics Hub, a new fully managed service that helps organizations unlock the value of data sharing, leading to new insights and increased business value.
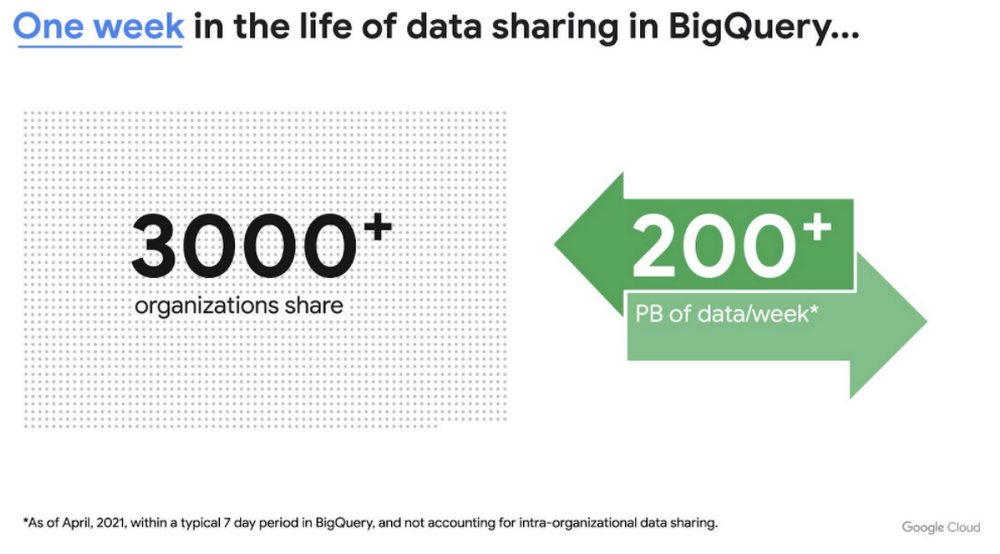
This new service is built on the tremendous experience and feedback we have received over the years. For example, BigQuery has had cross-organizational, in-place data sharing capabilities since its inception in 2010—and the functionality is very popular. Over a 7-day period in April, we had over 3,000 different organizations sharing over 200 petabytes of data. These numbers don’t include data sharing between departments within the same organization.
Analytics Hub takes sharing to the next level, making it easy for you to publish, discover, and subscribe to valuable datasets that you can combine with your own data to derive unique insights.
This includes:
Shared datasets: As a data publisher, you create shared datasets that contain the views of data that you want to deliver to your subscribers. Data subscribers can search through the datasets that are available across all exchanges for which they have access and subscribe to relevant datasets. In addition, the publisher can track subscribers, disable subscriptions, and see aggregated usage information for the shared data.
Curated, self-service data exchanges: Exchanges are collections used to organize and secure shared datasets. By default, exchanges are completely private, but granular roles and permissions make it easy to deliver data to the right audience—whether internal or public.
This is just the beginning for Analytics Hub. Please sign up for the preview, which is scheduled to be available in the third quarter of 2021.
Dataflow Prime
At Google Cloud, we have the great privilege of working with some of the most innovative organizations in the world. And this work provides us with a unique perspective into the future of big data processing. Dataflow Prime is a new platform based on a serverless, no-ops, and auto-tuning architecture that brings unparalleled resource utilization and radical operational simplicity to big data processing. This new service introduces a large number of exciting capabilities but I’d like to highlight three key aspects of the product:
Vertical Autoscaling: Dataflow Prime dynamically adjusts the compute capacity allocated to each worker based on utilization, detecting when jobs are limited by worker resources and automatically adding more resources. Vertical Autoscaling works hand in hand with Horizontal Autoscaling to seamlessly scale workers to best fit the needs of the pipeline. As a result, it no longer takes hours or days to determine the perfect worker configuration to maximize utilization.
Right Fitting: Each stage of a pipeline typically has a different resource requirement than the others. Until now, either all workers in the pipeline would have had the higher memory and GPU, or none of them would. Pipelines either had to waste resources or suffer slower workloads. Right Fitting solves this problem by creating stage-specific pools of resources, optimized for each stage.
Smart Recommendations: Smart Recommendations automatically detects problems in your pipeline and shows potential fixes. For example, if your pipeline is running into permissions issues, a Smart Recommendation will detect which IAM permissions you need to enable to unblock your job. If you are using an inefficient coder in your job, Smart Recommendations will surface more performant coder implementations that can help you save on costs.
What’s next
We’re excited to hear your thoughts and feedback about all these exciting new services. I would also highly recommend that you connect with members of the community to learn more about their story and journey. A good example to start with is the Data To Value customer panel we produced at our inaugural Data Cloud Summit with the Chief Data Officers of Keybank and Rackspace. You can watch it for free below:


