BigQuery にマルチモーダル エンべディングと構造化データのエンべディングをサポートを導入

Google Cloud Japan Team
※この投稿は米国時間 2024 年 4 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
エンべディングは、エンティティ、テキスト、画像、動画などの現実世界のオブジェクトを、ML モデルが容易に処理できる数値の配列(ベクトル)として表現します。また、セマンティック検索、推奨事項、クラスタリング、外れ値検出、名前付きエンティティ抽出など、多くの ML アプリケーションの構成要素でもあります。昨年、Google は BigQuery にテキスト エンベディングのサポートを導入し、ML モデルが現実世界のデータドメインをより効果的に理解できるようにしました。そして今年の初めには、ベクトル検索を導入して、何十億ものエンべディングをインデックス化して処理し、BigQuery で生成 AI アプリケーションを構築できるようにしました。
私たちは Next '24 で、BigQuery のエンべディング生成機能をさらに強化し、以下の機能をサポートすることを発表しました。
-
Vertex AI の multimodalembedding モデルによる BigQuery でのマルチモーダル エンベディング生成。これにより、同じセマンティック空間にテキストデータと画像データを埋め込むことができます。
-
BigQuery のデータでトレーニングされた PCA、オートエンコーダ、行列分解モデルを使用した構造化データのエンべディング生成。
マルチモーダル エンベディング
マルチモーダル エンベディングは、同じセマンティック空間にテキストデータと画像データのエンべディング ベクトルを生成し(意味が似ているアイテムのベクトルは互いに近い)、生成されたエンべディングは同じ次元を持ちます(テキストと画像のエンべディングは同じサイズ)。これにより、画像のエンべディングやインデックス登録、そしてテキストによる検索など、さまざまなユースケースが可能になります。
次の簡単なフローに従って、BigQuery でマルチモーダル エンべディングの使用を開始できます。必要に応じて、同様の例について説明している概要の動画もご覧ください。
ステップ 0: 非構造化データを参照するオブジェクト テーブルを作成するBigQuery では、オブジェクト テーブルを使用して非構造化データを扱うことができます。たとえば、エンべディングを生成したい画像が Google Cloud Storage バケットに保存されている場合、その画像データを参照する BigQuery オブジェクト テーブルを作成できます。画像データを移動する必要はありません。
このブログ投稿で紹介している手順を行うには、既存の BigQuery CONNECTION を再利用するか、こちらの手順に沿って新しい接続を作成する必要があります。使用する接続のプリンシパルに「Vertex AI ユーザー」ロールが割り当てられていて、プロジェクトで Vertex AI API が有効になっていることを確認します。接続が作成されたら、次の例のようにオブジェクト テーブルを作成できます。
この例では、メトロポリタン美術館(別名「The Met」)のパブリック ドメインのアート画像のデータを含む Cloud Storage の公開バケットを使用して、そのアート画像を含むオブジェクト テーブルを作成しています。作成されたオブジェクト テーブルには、次のスキーマがあります。
これらの画像のサンプルを見てみましょう。こちらのチュートリアルの手順に沿って、BigQuery Studio で Colab ノートブックを使用してこれを行うことができます。ご覧のとおり、さまざまなオブジェやアート作品の画像が表示されています。
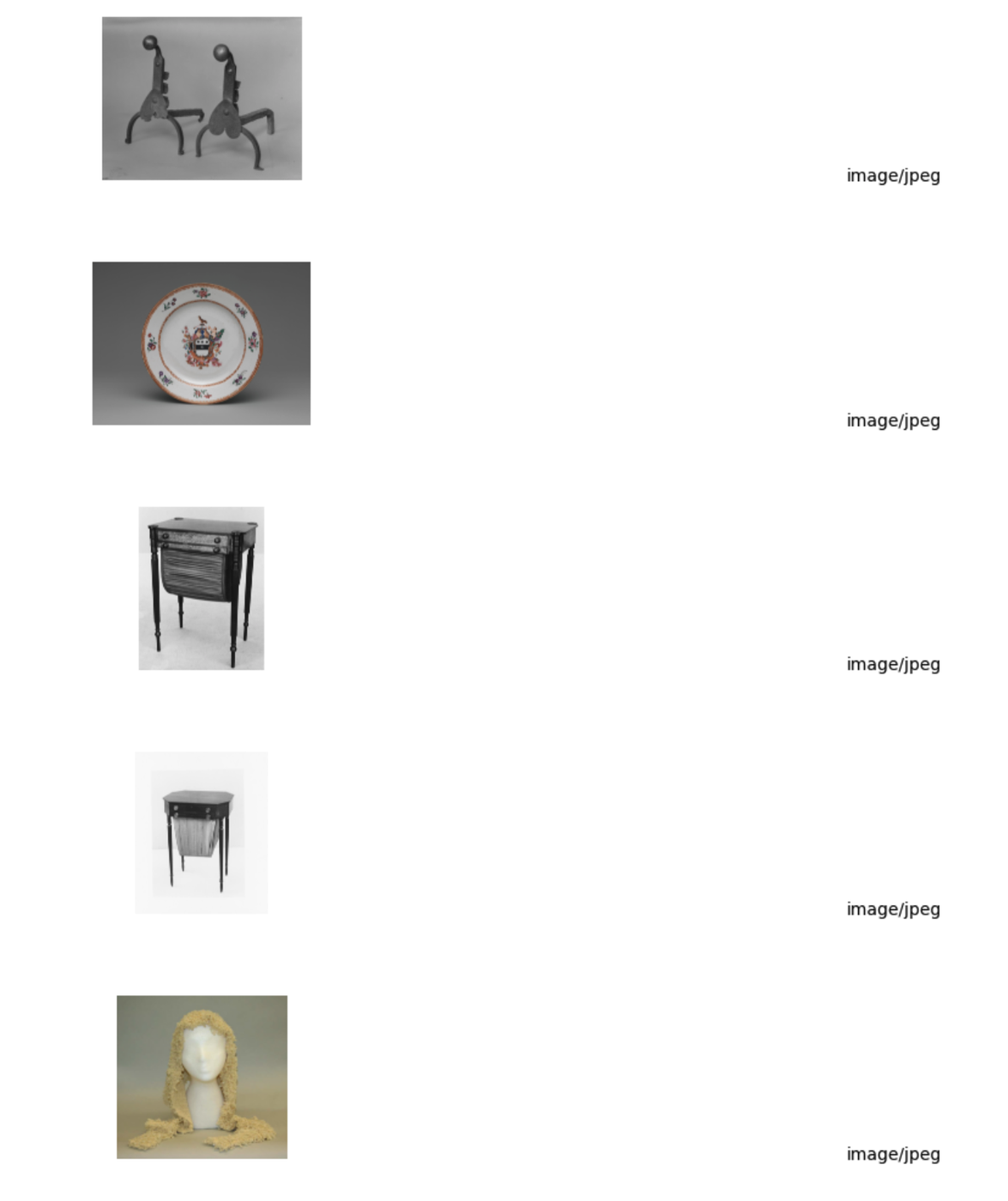
画像の出典: メトロポリタン美術館
画像を含むオブジェクト テーブルが作成できたので、それらのエンべディングを生成してみましょう。
ステップ 1: モデルを作成するエンべディングを生成するには、まず Vertex AI がホストする ’multimodalembedding@001’ エンドポイントを使用する BigQuery モデルを作成します。
multimodalembedding モデルはテキストのエンべディング生成をサポートしていますが、クロスモーダルなセマンティック検索のシナリオ(たとえば、テキストから画像を検索するなど)向けに特別に設計されている点に注意してください。テキストのみのユースケースの場合は、代わりに textembedding-gecko@ モデルを使用することをおすすめします。
ステップ 2: エンべディングを生成するBigQuery では、ML.GENERATE_EMBEDDING 関数を使用してマルチモーダル エンベディングを生成できます。この関数は、テキスト エンべディング(textembedding-gecko モデルを使用)や、構造化データ エンべディング(PCA、オートエンコーダ、行列分解モデルを使用)の生成にも使えます。エンべディングを生成するには、前のステップで作成したエンべディング モデルとオブジェクト テーブルを ML.GENERATE_EMBEDDING 関数に渡すだけです。
チュートリアルの実行時間を短縮するために、エンべディング生成を 10,000 個の画像に制限しています。このクエリの実行には 30 分から 2 時間かかります。このステップが完了すると、BigQuery Studio で出力をプレビューできます。生成されたエンベディングの次元は 1,408 になります。
ステップ 3(オプション): 生成されたエンべディングにベクトル インデックスを作成する前のステップで生成されたエンべディングを永続化して、下流のモデルやアプリケーションで直接使用できますが、エンべディング検索のパフォーマンスを向上させ、最近傍クエリパターンを有効にするためにベクトル インデックスを作成することをおすすめします。BigQuery でのベクトル検索の詳細については、こちらをご覧ください。
ステップ 4: テキストから画像(クロスモダリティ)検索にエンべディングを使用するこれらのエンべディングをアプリケーションで使用できます。たとえば、「pictures of white or cream colored dress from victorian era(ビクトリア時代の白色またはクリーム色のドレスの写真)」を検索するには、まず次のような検索文字列を埋め込みます。
埋め込まれた検索文字列を使用して、以下のように類似した(最も近い)画像のエンべディングを検索できるようになりました。
ステップ 5: 結果を可視化するでは、計算された距離とともに結果を視覚化し、検索クエリ「pictures of white or cream colored dress from victorian era(ビクトリア時代の白またはクリーム色のドレスの写真)」の結果を確認してみましょう。BigQuery ノートブックを使用してこの出力をレンダリングする方法については、付属のチュートリアルを参照してください。

画像の出典: メトロポリタン美術館
かなり良い結果が出ています。
まとめ
このブログ投稿では、一般的なベクトル検索の使用パターンについて説明しましたが、エンべディングには他にも数多くのユースケースがあります。たとえば、マルチモーダル エンべディングを使用すると、画像のテーブルと、文のようなラベルが含まれた別のテーブルをエンべディングに変換することで、画像のゼロショット分類を行うことができます。そして、画像と各説明ラベルのエンべディングの間の距離を計算することで、画像の分類が可能になります。また、これらのエンベディングを他の ML モデル(BigQuery のクラスタリング モデルなど)をトレーニングするための入力として使用して、データ内の隠れたグループを検出することもできます。エンべディングは、フリー テキスト入力がある場合にも特徴量として役立ちます。たとえば、ユーザー レビューや通話の文字起こしのエンべディングをチャーン予測モデルで使用したり、家の画像のエンべディングを価格予測モデルの入力特徴として使用したりできます。さらに、ディープ ラーニング レコメンデーション モデルにおける商品カテゴリなど、そのカテゴリがセマンティックな意味を持つ場合には、カテゴリのテキストデータの代わりにエンべディングを使用できます。
BigQuery では、マルチモーダル エンベディングやテキスト エンベディングに加え、BigQuery のデータでトレーニングされた PCA、オートエンコーダ、行列分解モデルを使用して構造化データにエンベディングを生成することもできます。これらのエンべディングには、幅広いユースケースがあります。たとえば、PCA モデルやオートエンコーダ モデルによるエンべディングは、異常検出(他のエンベディングから遠く離れたエンベディングは異常とみなされる)に使用したり、他のモデル(オートエンコーダによるエンベディングでトレーニングされた感情分類モデルなど)への入力特徴として使用したりできます。行列分解モデルは、従来、レコメンデーションの問題に使用され、ユーザーとアイテムのエンべディングを生成するために使用できます。ユーザーのエンべディングを使用して、最も近いアイテムのエンべディングを見つけてそれらのアイテムをおすすめしたり、ユーザーをクラスタ化して特定のプロモーションのターゲットにしたりできます。
このようなエンべディングを生成するには、まず CREATE MODEL 関数を使用して PCA、オートエンコーダ、行列分解モデルを作成し、データを入力として渡します。次に、モデルを提供する ML.GENERATE_EMBEDDING 関数とテーブル入力を使用して、このデータにエンべディングを生成します。
使ってみる
BigQuery で、マルチモーダル エンベディングのサポートと、構造化データのエンベディングのサポートが利用可能になりました(プレビュー版)。利用を開始するには、ドキュメントやチュートリアルをご覧ください。フィードバックがございましたら、bqml-feedback@google.com までご連絡ください。


