NLP タスク向け BigQuery テキスト エンベディングのご紹介
Google Cloud Japan Team
※この投稿は米国時間 2023 年 8 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
テキスト エンベディングは、セマンティック検索、推奨事項、テキスト クラスタリング、感情分析、固有表現抽出などのアプリケーションを実現する重要な要素であり、構成要素です。このたび、テキスト エンべディングを生成し、使い慣れた SQL コマンドを使用してダウンストリーム アプリケーション タスクに適用する BigQuery の新機能をリリースすることになりましたのでお知らせします。本日より、BigQuery SQL から次の 4 種類のテキスト エンべディング生成を直接使用できるようになります。
textembedding-gecko: 生成 AI を使用したエンべディング向け
BERT: コンテキストや多言語のサポートを必要とする自然言語処理タスク向け
NNLM: テキスト分類や感情分析などの単純な NLP タスク向け
SWIVEL: 単語間の複雑な関係を捉える必要がある大規模なデータ コーパス向け
新しくサポートされる array<numeric> 特徴タイプにより、こうした生成されたエンベディングが BigQuery でサポートされている ML モデルで使用できるようになります。これによって、ベクトル空間内の近接性と距離に基づいたデータ分析が可能になります。
BigQuery を使用して最初のエンべディングを生成する
以下で説明する BQML アプリケーションの準備を整えるために、まず新しく追加された関数を textembedding-gecko PaLM API を使用して確認し、エンべディングを生成します。具体的には、単純な 2 段階のプロセスを使用し、ML.GENERATE_TEXT_EMBEDDING という新しい BigQuery ML 関数を介して呼び出すことができます。
まず、textembedding-gecko モデルをリモートモデルとして登録します。
次に、ML.GENERATE_TEXT_EMBEDDING 関数を使用してエンべディングを生成します。以下の例では、imdb review データセットを入力として使用します。
詳細については、ドキュメント ページをご覧ください。BERT、NNLM、SWIVEL などのより小さなモデルを使用したテキスト エンべディングの生成も選択できます。生成されたエンべディングは、テキストのセマンティックな意味をエンコードする能力こそ低下しますが、非常に大規模なコーパスを処理する点においてはよりスケーラブルです。BigQuery ML での使用方法について詳しくは、こちらの公開チュートリアルをご覧ください。
BigQuery ML でエンべディング アプリケーションを構築する
テキスト エンべディング テーブルの作成を通じて、「分類」と「基本バージョンの類似性検索」という 2 つの一般的なアプリケーションをご紹介します。
分類による感情分析
NNLM モデルから生成された embeddings を使用し、元のデータ列 reviewer_rating を組み合わせて、imdb review の感情(肯定的または否定的)を予測するロジスティック回帰モデルを構築する方法を見てみましょう。
モデルが作成されたら、ML.PREDICT を呼び出してレビューのセンチメントを取得し、ML.EVALUATE を呼び出してモデル全体のパフォーマンスを確認できます。強調すべき点の一つは、モデルにフィードする前に、テキスト入力をエンべディングに変換する必要があるということです。以下は ML.PREDICT クエリの一例です。
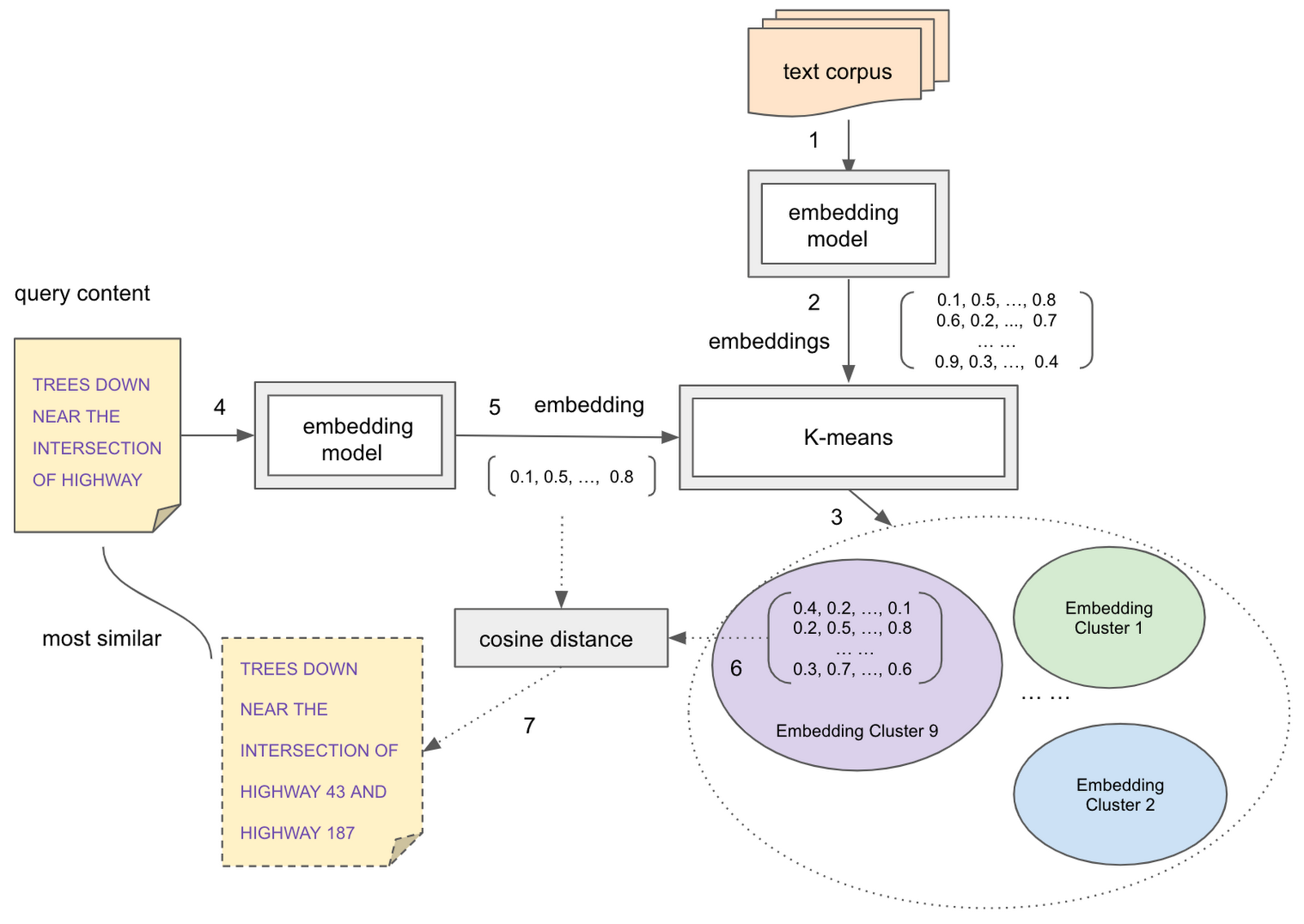
2020 年、私たちはオープンソースのエンべディング モデルを活用してドキュメントの類似性検索とクラスタリングを行うアプローチと、モデルのトレーニングにエンべディングを使用する回避策を紹介するブログ記事を書きました。今では、より合理化された簡潔な SQL 構文を使用して検索タスクを実行できるようになっています。
わかりやすく説明するために、同じ wind_reports 一般公開データセットを使用します。上記の textembedding-gecko モデルを使用して「reports」テキスト列のエンべディングを生成したと仮定すると、エンべディングと元のデータを含む semantic_search_tutorial.wind_reports_embedding という名前の新しいテーブルが得られます。
次に、K 平均法モデルをトレーニングして、検索空間を分割します。
次のステップでは、ML.PREDICT 関数と、上記のトレーニング済み K 平均法モデルおよびクエリ エンベディングを使用して、検索候補が存在する K 平均法クラスタを見つけます。クエリ エンベディングと予測されたクラスタ内の検索候補のエンベディングとの間のコサイン距離を計算することで、クエリアイテムに最も類似したアイテムのセットを取得できます。クエリの一例を以下に示します。



