データ分析に関する今月の新情報: シンプル、高度、安全
Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
6 月は夏至の月であり、北半球では 1 年のうちで最も日照時間が長くなります。Google はこの 6 月にできる限り多くの時間を費やして、BigQuery、Dataflow、Data Fusion などにさまざまな新機能を導入しました。その一部をご紹介します。
シンプル、高度、安全
Google はデータ分析を開発するうえで使いやすさを重視しています。ユーザー フレンドリーの面で BigQuery に今月加えた新たな改善点は次のとおりです。
柔軟なデータ型のキャスティング
列の説明を変更するためのフォーマット
SQL を使用した GRANT / REVOKE アクセス制御コマンド
今回の改善をデータ アナリスト、データ サイエンティスト、DBA、SQL 愛好家の皆様に喜んでいただけることを願っています。詳しくは、こちらのブログをご参照ください。
Google は、コマンドをシンプルにすることと同様に、トランザクションの処理にもさらに高度な機能を組み込むことが重要だと認識しています。そこで、BigQuery におけるマルチステートメント トランザクションのサポートを発表しました。
ご存じのように、BigQuery は長年にわたり、トランザクションあたり 1 つのテーブルに適用される DML ステートメント(INSERT、UPDATE、DELETE、MERGE、TRUNCATE)による単一ステートメント トランザクションをサポートしてきました。マルチステートメント トランザクションでは、単一のトランザクションで複数のテーブルにまたがる複数の SQL ステートメント(DML を含む)を使用できます。
これは、あるトランザクション内のすべてのステートメントに関連付けられた複数のテーブルのデータに対する変更が、成功した場合はアトミックに(一度ですべてに)commit され、失敗した場合はすべてアトミックにロールバックされることを意味します。

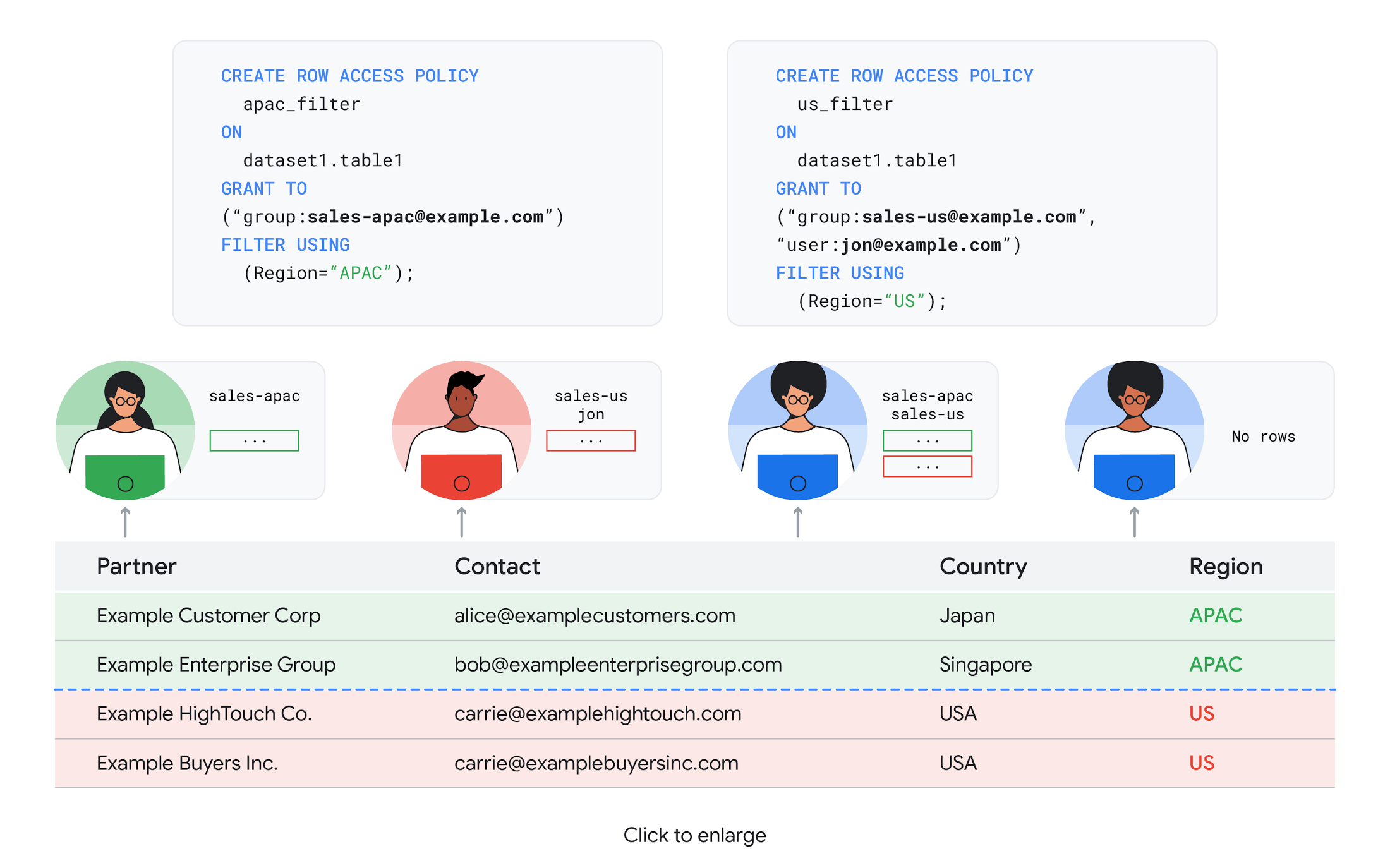
また、Google は組織がデータへのアクセス権を細分化して管理する必要があること、データ プラットフォームの複雑さが日々増すにつれて、機密データにアクセスできるユーザーを特定してモニタリングすることの重要性が高まっていることも認識しています。
こうしたニーズに対応するため、BigQuery の行レベルのセキュリティの一般提供を発表しました。これにより、同一テーブル内のデータのサブセットに対するアクセスを、ユーザー グループごとに制御できるようになります。BigQuery の行レベルのセキュリティを使用すると、同じテーブル内のデータのサブセットごとに異なるユーザー ペルソナのアクセスを許可でき、アクセス ポリシーは DDL ステートメントを使って簡単に作成、更新、削除できます。詳しくは、ドキュメントとベスト プラクティスをご覧ください。
シンプル、安全、スマート
Google のチームはお客様向けに、よりシンプルで高度かつ安全なデータ プラットフォームを構築するだけでなく、組み込みのインテリジェンスを活用したソリューションの提供にも注力してきました。Google では、機械学習が多くのユーザーに採用され、大規模に利用することができるように、使いやすく、デプロイしやすくすることを理念の一つに掲げています。
BigQuery ML は Google の組み込み機械学習機能で、世界中の Google の上位顧客の 80% が、データから価値を創出するための基礎として BigQuery ML を採用しています。
この取り組みの一環として、BigQuery ML での AutoML Tables の一般提供を発表しました。このノーコード ソリューションを導入すれば、構造化データに最先端の機械学習モデルを自動的に構築してデプロイできます。Vertex AI と簡単に統合できるため、BQML の AutoML はバックグラウンドで機械学習の能力を簡単に発揮できます。データの前処理から特徴量エンジニアリング、モデル チューニング、相互検証にいたるまで、AutoML はモデルを「自動的に」選択してアンサンブルするため、データ サイエンティストでなくても、誰でも利用できます。
この機能を試してみませんか?NYC Taxi の一般公開データセットで BigQuery をぜひお試しください。手順はこちらのブログに記載されています。
一般公開のデータセットといえば、Google は BigQuery での Google トレンドデータの一般提供を発表しました。これにより、お客様は Google 検索全体でトピックや検索キーワードに対するユーザーの関心度を測定できるようになります。この新しいデータセットは、まもなく Analytics Hub でも利用できるようになり、データは匿名化やインデックス登録、正規化、集計が行われてから公開されます。
エンドキャップの表示内容が地域のオーディエンスに適しているかを確認したいですか?マーケット エリア内でユーザーが探しているものからシグナルを取得し、表示すべきものを判断できます。ユーザーの検索内容に基づいて、既存の製品に組み込むべき新機能を把握したいですか?こうしたデータセットに含まれるキーワードは、何に注意を向けるべきかを示している可能性があります。
これらのデータとテクノロジーはすべて、ビジネスを成長させ保護するための重要なソリューションのデプロイに活用できます。たとえば、検出の際に異常を定義する方法を把握することが難しいケースもあります。既知の異常でラベル付けされたデータがある場合は、BigQuery ML ですでにサポートされているさまざまな教師あり機械学習モデルタイプから選択できます。
しかし、どのような異常が起こるかを予想できず、ラベル付けされたデータもない場合にはどうすればよいでしょうか?教師あり学習を利用する一般的な予測の手法とは違って、ラベル付けされたデータがない場合でも、組織が異常を検出できるようにする必要があります。
そのため、Google は BigQuery ML の新しい異常検出機能の公開プレビューを発表しました。この機能を使えば、教師なし機械学習を利用してラベル付けされたデータがなくても異常を検出できます。
Google のチームは、異常検出の改善に機械学習を活用している多数の企業と連携しています。たとえば金融サービス業のお客様は Google のテクノロジーを使用して、機械学習によりリアルタイムの外国為替データの異常値を検出しています。
こうした企業のベスト プラクティスを簡単に活用できるように、Google は Kasna と協力してサンプルコード、アーキテクチャ ガイダンス、データを生成するデータ シンセサイザーを開発し、イノベーションをすぐにテストできるようにしました。
シンプル、スケーラブル、スピーディ
移動中のデータをキャプチャ、処理、分析できる機能は、お客様がアーキテクチャを選択する際の重要な検討項目になっています。バッチ処理に加えて、多くの場合、レコードが書き込まれるとすぐにクエリで使用できるように、BigQuery にレコードをストリーミングできる柔軟性が求められます。
新しい BigQuery Storage Write API は、ストリーミング取り込みとバッチ読み込みを 1 つの API に組み合わせたものです。これを使用すると、レコードを BigQuery にストリーミングできるだけでなく、任意の数のレコードをバッチ処理して、単一のアトミック オペレーションで commit することもできます。
Google の本質は、同じ環境でバッチとリアルタイムを実行できる柔軟なシステムの提供です。ストリーミング データとバッチデータをサーバーレスで処理する Google の Dataflow サービスは、柔軟性を念頭に構築されました。
この原則は、Dataflow の機能だけでなく、それを活用する方法にも当てはまります。ストリーミング パイプラインの開発に、BigQuery のウェブ UI から直接 Dataflow SQL を使用する場合でも、Dataflow インターフェースから Vertex AI Notebooks を使用する場合でも、膨大な数の構築済みテンプレートを使用する場合でも同じです。
Dataflow は最近多くの注目を集めています。先日の Dataflow Prime の発表を耳にされた方もおられるでしょう。これは、リソースの使用量を最適化し、ビッグデータ処理をさらに簡素化する新しい NoOps の自動チューニング機能です。また、Google Dataflow が 2021 年の The Forrester Wave™: Streaming Analytics でリーダーに選出され、12 の異なる基準において 5 段階中で 5 の評価を獲得したという投稿を目にされた方もいらっしゃるでしょう。
このプラットフォームに対するサポートをコミュニティから得られたことは、この上ない喜びです。Dataflow のスケーラビリティは比類のないものであり、スケーラビリティ、スピード、ストリーミングの向上を目指す企業には、すでにその目標を達成している Sky、RVU、Palo Alto Networks のリーダーの経験談を参考にされることをおすすめします。
Dataflow を初めて使用する場合は、先月、Priyanka Vergadia(別名 CloudGirl)が優れたリソースセットをリリースしましたので、参考にしてください。こちらのブログをお読みになり、次の紹介動画をご覧ください。

連携が可能なシンプルな構造
Google は、データの出所やデータスタックの統合方法に関係なく、お客様が変革を進めるうえで最適なパートナーになることを目指しています。
Google のパートナーである Tata Consultancy Services(TCS)が最近発表した調査では、デジタル ファブリックを統合することの重要性を取り上げています。また、Google Cloud Data Fusion などのデータ統合サービスによってクライアントがこのビジョンを実現する方法も説明しています。
Google はまた、SAP Business Suite、SAP ERP、S4/HANA からデータをシームレスに移動するために、Google Cloud のネイティブ データ統合プラットフォームである Cloud Data Fusion と SAP の統合を発表しました。SAP データの迅速な取り込みについては、現在までに Cloud Data Fusion で 50 を超えるパイプラインを提供しています。
先月、Google は SAP Order to Cash アクセラレータをリリースしました。このアクセラレータは、Cloud Data Fusion の SAP テーブル バッチ ソース機能の実装例で、エンドツーエンドの Order to Cash プロセスと分析を初めて作成する際に役立ちます。
このアクセラレータには、SAP データソースへの接続、データ変換、BigQuery へのデータの保存、Looker での分析の設定を構成できるサンプルの Cloud Data Fusion パイプラインが含まれます。また、これに含まれる LookML ダッシュボードを使えば、GitHub でアクセスできます。
数え切れないほどの一流企業が、SAP データのために Google との連携を選択しています。6 月に執筆した ATB Financial の変革に関する投稿では、BigQuery を中心に構築されたデータ露出プラットフォーム「D.E.E.P」を通じて、同社がデータの活用によって 80 万人を超える顧客により良いサービスを提供し、さらに生産性において 224 万カナダドル以上を節約して、400 万カナダドル以上の営業収益を実現した方法を紹介しています。
最後に、Firebase Crashlytics、Google Analytics、Cloud Firestore、サードパーティのデータセットから得たデータをまとめる統合プラットフォームを探しているアプリケーション開発者の方に朗報です。
Google は先月、Firebase、BigQuery、Google Looker、FiveTran を組み合わせた統合分析プラットフォームをリリースしました。これにより、異なるデータソースを簡単に統合し、データを運用ワークフローに注入して、製品開発における洞察を深め、カスタマー エクスペリエンスを向上させることができます。このリソースにはサンプルコード、リファレンス ガイド、わかりやすいブログが含まれています。ぜひご活用ください。来月の投稿もお楽しみに。

-プロダクト管理担当シニア ディレクター Sudhir Hasbe
