野球ファンのための分析情報のスケーリングと自動化に BigQuery を活用

Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
ビジネスの意思決定者は、データを見るとき、「このデータから何が言えるか」という問いに悩まされることがよくあります。データ アナリストとデータ サイエンティストは、数値をまとめて結果を作成するだけでなく、この問いに対する答えを出すうえで重要な役割を果たします。
大きな組織も小さな組織も、データ アナリストやデータ サイエンティストに「言語を数値化し、数値を言語化してもらう」ことに依存していると、スポーツ分析のパイオニアである Dean Oliver 氏はかつて述べました。しかし、データ サイエンティストやアナリストは、クライアントに向けてテーブルや、グラフ、あるいはインタラクティブなダッシュボードを作成するだけでなく、コミュニケーションをさらに自動化し、ビジネスに迅速でより明確な分析情報を提供することができなければなりません。
BigQuery などのデータクラウド ソリューションは、データ分析に携わる方が分析情報をスケーリングや自動化する際に使用することで、分析情報を得るまでの時間を短縮できます。BigQuery のセルフチューニングやサーバーレス インフラストラクチャにより IT オペレーションが自動化されているため、データ アナリストはインフラストラクチャの管理について気を揉むことなく、分析に集中できます。このようにアナリストの時間を有効活用することで、自動化が容易ではない統計情報やトレンドの発掘、自動化された分析情報生成パイプラインを利用するための指標のさらなる構築などにリソースをシフトすることができます。
以前の投稿で、メジャーリーグ ベースボール(MLB)が Google Cloud と提携して、特定の試合に関わる選手やチームに関する統計的な分析情報を得ることができる「ゲームノート」の生成プロセスをどのようにスケールするかをご紹介しました。2021 年も MLB のシーズンが到来しました。今回は、Statcast のデータからゲームノートの作成が自動化されるプロセスにおいて、さまざまな BigQuery の機能がどのように組み合わされるかについてさらに詳しく見ていきます。BigQuery の元データから、元の投稿で紹介したような、文、画像、状況を反映したテーブルで構成される数百から数千もの分析情報へ変換する方法についてご説明します。
野球は多くの人にとって楽しみの場ですが、ここで説明するプロセスの一部は、自動化によって効率を大幅に向上させることで、ビッグデータをタイムリーで状況を反映した、貴重な情報の簡潔版に変換したいと考えているすべての業界で使用できます。それではさっそく第 1 打席に立ってみましょう。
特定のタイプの分析情報に対して繰り返し可能なパターンを構築する
技術的な側面に入る前に、与えられたデータからどのような形式の分析情報を自動化またはスケールできるか、そしてそれをどのように行うかについて考えることが重要です。MLB の場合、このような「統計リーダーボード」タイプのノートには、ほとんどの場合、以下の要素がいくつか組み合わされています。
関心のある統計(ハードヒットの回数や速球の平均速度など)
リーダーボードがカバーする期間(過去 2 度のレギュラー シーズン、今回のポストシーズンなど)
関心のある「エンティティ」(通常はチームか選手のいずれか)
試合の「ファセット」、その統計情報の計算でどちらの「サイド」を使用するかを表す(打者と投手のどちらかなど)
ランキング資格基準、その統計情報がランキングで使用するに妥当であるとみなせる最小の試行回数(選手の「割合」に関する統計で分母が小さく、外れ値が発生する可能性がある場合に主に使用。たとえば、10 打席で打率 0.700 となる場合)
これらの要素を組み合わせると、そこに秘められた多くのノートを得ることができます。そして、いくつかの「印象性」基準(その選手がトップ 5 または 10 にランクインしているかどうかなど)と関連性基準(その選手のチームが次の試合に関与しているかどうかなど)を使用して、興味を引くノートを試合情報に貼り付けることができます。自動化されていない場合、MLB コンテンツの専門家は Baseball Savant などのツールを使用することで同様のゲームノートを生成できますが、特定の選手やチームを探すために何十回も手動で検索しなければ、そのエンティティがトップ 5 または 10 にあるのを見つけることができず、ノートのテキストや付随するテーブルも手動で入力しなければなりません。各ノートの生成に数分しかかからないとしても、30 のすべてのチームにおいて複数の選手をカバーしようとすると、簡単に数時間かかってしまう可能性があります。
テーブルに指標メタデータを設定する
分析情報の元となる実際のデータを保持するテーブルに加えて、分析情報を形成するいくつかの構成可能な要素に関する「メタデータ」を含んだ BigQuery テーブルを設定すると便利です。MLB ゲームノートの場合、このテーブルの 1 つには、表示名、定義、昇順または降順ランキングが統計上「良好」かどうかなど、ゲームノートで考慮される各統計(「ハードヒット率」など)に関する情報が含まれます。
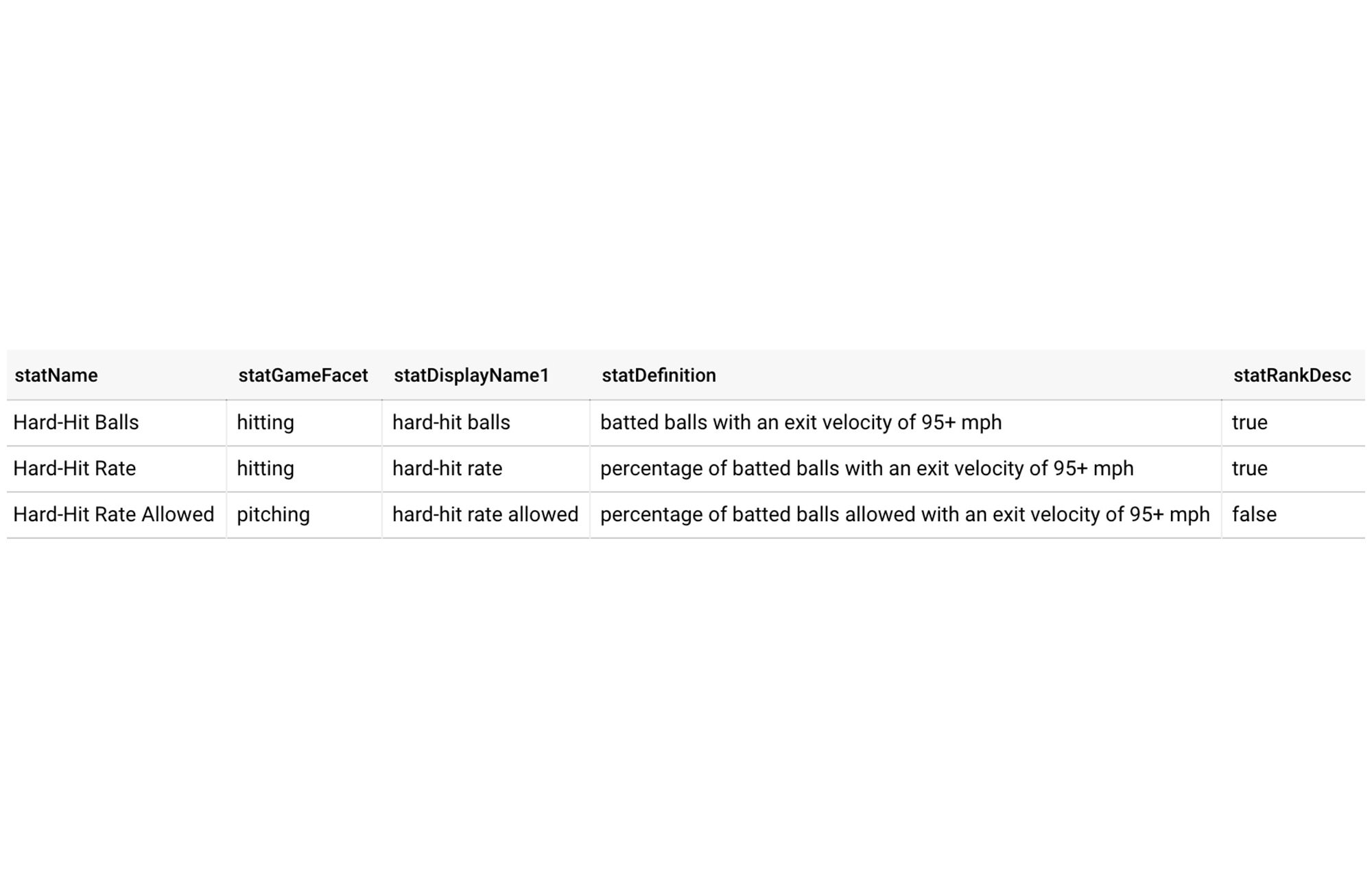
他のメタデータ テーブルには、関連する日付や試合タイプなど、ノートが作成される各期間(「2020 年ポストシーズン」など)に関する情報が含まれています。
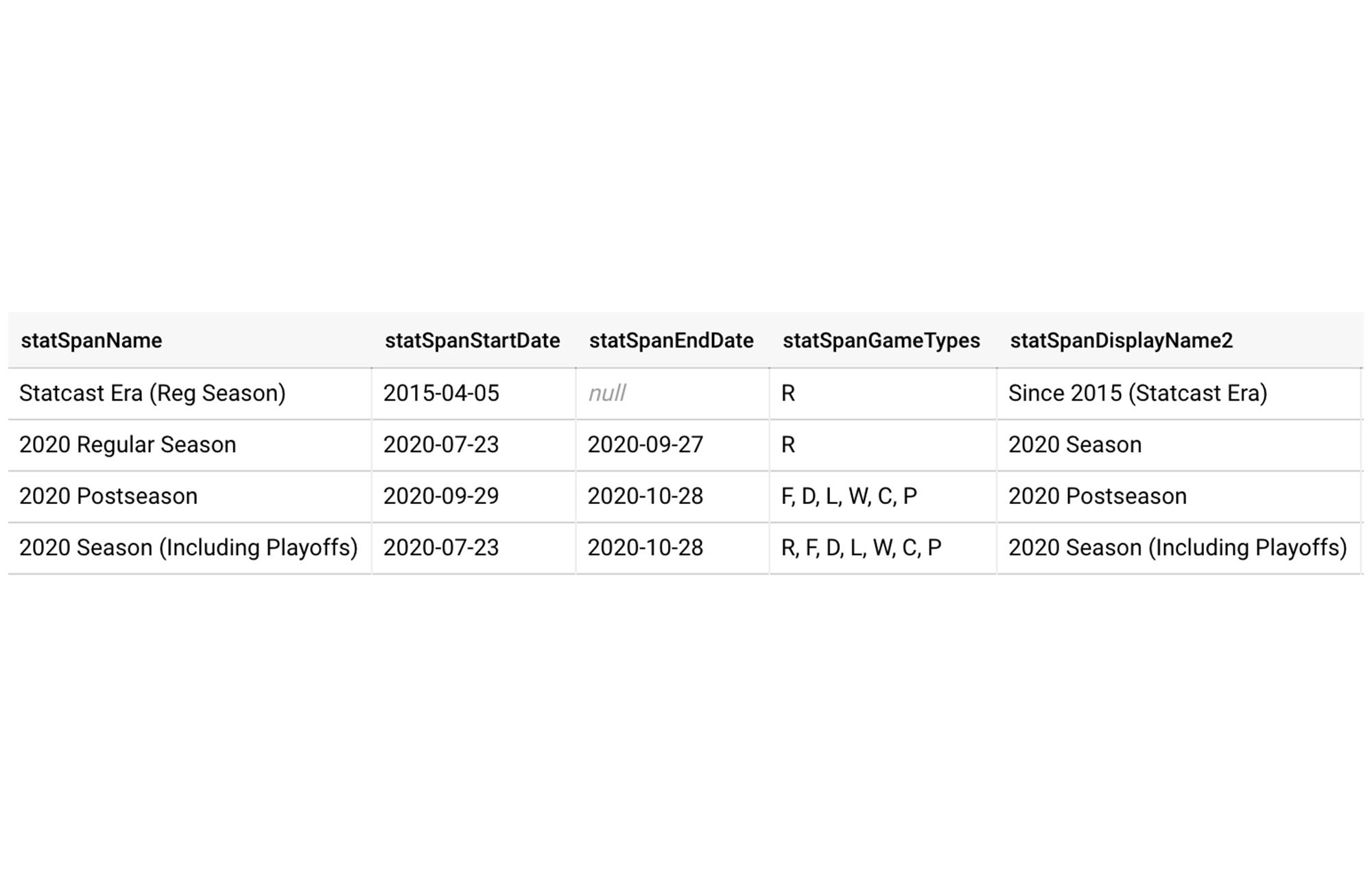
これらのテーブルは、期間ごとにデータを正しい日付にフィルタリングする際、各統計で選手またはチームを正しい方法でランク付けする際、最終的なノートを構成する文章とテーブルの両方で使用する一貫したテキストを用意する際など、ノート生成プロセスのさまざまな部分で使用されます。
ビューを作成し、特定のデータをフィルタリングして繰り返し使用できるようにする
別の方法として、BigQuery ビューを使用して分析情報生成プロセスの複数の側面をモジュール化することもできます。一部の分析ワークフローでは、ビューを使用して、他の複数のステップの仲介となる特定のクエリの結果を保存できます。ビューは仮想であり、テーブル(または他のビュー)の「上」にあるため、基になるテーブルの最新データを用いて常に最新の状態となっています。バッチ指向の ETL システム(MapReduce で応答するシステムなど)と比較して、BigQuery テーブルとビューを一緒に使用すると、このような中間データ処理ステップを効率的にモジュール化できます。
MLB ゲームノートのコードには、以下の 2020 年のポストシーズンについて示したビューのように、ピッチレベルのイベントデータを特定の期間にフィルタリングするビューがあります。
また、各チームの次の試合のスケジュール(ノートをどの試合に「貼り付け」ればよいかがわかる)、各チームの最新の名簿(どの選手がどのチームにいるかがわかる)、そして以下でご説明するノート作成プロセスの中間ステップとして、より複雑なビューを採用しています。全体として、ビューは分析情報生成プロセスのさまざまな部分において、用途の広い構成要素の機能を果たします。
中間出力に一時テーブルと動的 SQL を使用する
ついに、分析情報生成プロセスを一連の SQL クエリで実行するステップに進みます。反復的なものもありますが、1 つの大きなクエリにまとめられないほど差異のあるものもあれば、同様のロジックに依存していても並列テーブルに適用されるものもあります。一時テーブルや動的 SQL などの BigQuery 機能は、保存される不要なデータや管理する重複コードの量を減らしながら、これらの手順を実行するのに便利です。いくつかの統計情報から、数十から 100 以上のノートを自動化するにあたって、最小限のコード変更で新しい統計情報や期間を追加できること、つまり、統計情報ごとに 1 つの新しい SQL クエリを必要としないことは非常に価値があります。
MLB ゲームノート生成プロセスの両方のコンセプトを組み込んだ例の一つとして、以下の動的 SQL ステートメントが挙げられます。これにより、変数 SPAN_SITUATION_EVENTS_TABLE から一時テーブル SpanSituationEvents が作成されます。これは、ピッチレベルのデータを含む特定のテーブル(またはビュー)の名前を表す文字列です。
このコードは、イベントの特定のテーブルのセットでデータを変換するのに使用されます(前述の 2020 年ポストシーズンのビューを参照)。そして、そのデータをスクリプト内で複数回参照できるテーブルとしてインスタンス化しますが、コードがスクリプト外部にある必要はありません(したがって、一時的です)。
動的 SQL を使うことでテーブル名を変数として使用することができ、これを許可しない BigQuery パラメータの制限を回避できます。異なるテーブル(この場合、MLB イベントの異なるセット)を参照する同じ形式の複数の SQL クエリは、単一のパターンで表すことができます。「コードを使用して SQL を生成する」このプロセスは、多くのデータ サイエンス プロジェクトにおいて重要な手法であり、Python または R でよく行われます。BigQuery で動的 SQL を使用すること、つまり SQL を使用して SQL を作成することの利点の一つは、他の言語、環境、クライアント ライブラリなどに依存することなく、すべてを「1 か所」で記述できるということです。
スクリプトとストアド プロシージャを使用して、より複雑なビジネス ロジックを実装する
コードを深く掘り下げて分析情報を生成すると、ビジネス ロジックがより複雑になり、さまざまなタイプの指標(比率、合計、より複雑な計算)や、さまざまなレベルの集約を一般化できるようになります。検討中の指標と集約のレベルごとに個別のクエリを作成する代わりに BigQuery スクリプトとストアド プロシージャを使用すれば、変数と制御フローを使って同じ基本構造を持つクエリのさまざまなユースケースに対応しながら、可能な限り同じ状態を維持する SQL「テンプレート」を作成できます。ストアド プロシージャは、このように使用することで関数型プログラミングを使ってより大きなアルゴリズムの一部をモジュール化し、まとめることができる SQL ベースの手法です。
MLB ゲームノートで使用されるさまざまな統計を計算する場合、単一のフィールド(例: ハードヒット数)で合計される累積的な「カウント」統計と、分子と分母の合計(例: ハードヒット率)や、資格基準(例: 最低 75 打数)によるその他のフィルタリングを含む「レート」統計があります。投手の統計は、「pitcherId」フィールドに集約する必要があります。そして打者の統計(場合によって逆の視点から見た同じ統計)は、「hitterId」フィールドに集約する必要があります。この計算形式の一般化は、大規模なストアド プロシージャを使用して実現されました。その最初の部分を以下に示します。
以下のスニペットは、ENTITY_TYPE フィールドと STAT_GAME_FACET フィールドをマルチレベルのケース ステートメントで使用して、投手側や打者側からだけでなく、チームレベルや選手レベルのいずれかに統計を集約できるようにする方法を示しています。
実際の手順は数百行のコードを必要とし、前述のとおり動的 SQL と一時テーブルを利用します。これは、数十の「並列」統計リーダーボードの計算を一般化するように構築されているため、「ワイド」形式ではなく「ロング」形式でさまざまな統計リーダーボードの計算と保存ができます。(「従来の」スポーツ統計表示のように)特定の選手やチームの複数の統計情報を同じ行に保存するのではなく、各選手やチームの統計情報をそれぞれの行に保存することで、ランキングやノートの生成などその後のステップを BigQuery 内でよりスムーズに進めることができます(基本的に、「stat leaderboard」は他の「GROUP BY」変数になります)。
他の言語の関数と同様に、BigQuery ストアド プロシージャはネスト化とチェーン化できるため、データ ウェアハウス内から直接複雑なデータ パイプラインを実行できます。MLB ゲームノートの場合、「run_stat_combo_calcs」と呼ばれるプロシージャは、統計リーダーボードのセットを使用して計算し、前述で参照した「calc_stat_span_situation」プロシージャを 100 回以上(リーダーボードごとに 1 回)実行します。そして、すべてのランキングを加え、追加の処理のために結果のテーブルを BigQuery にアップロードする関数に、結果の「長い」テーブルを渡します。
配列と構造体を使用して、状況に沿ったランキング情報を作成する
エンティティ(チームや選手)、統計、ランキングを含む長いテーブルを統計や期間の情報、チーム名簿ビュー(前述を参照)を含むメタデータ テーブルと結合して、ゲームノートの「文」の部分を作成できます。役立ちそうな追加のコンテキスト(スポーツでよくありますが、スポーツに限定されません)は、ランキング内の関心のあるエンティティとその周りの他のエンティティを示すテーブルです。たとえば MLB において、選手がある統計で 2 番目にランク付けされているとしたら、誰が 1 番目、3 番目、あるいはトップ 5 や 10 にランク付けされているかがわかるテーブルを見るのは興味深いです。
BigQuery の観点から、この部分を生成するには、長いリーダーボード テーブルに戻って、1 つのチームまたは 1 人の選手の単一の行にある情報以上のもの、つまりその情報の「周り」の他のエンティティを取得する必要があります。「周り」の行からの情報は、構造体の配列を含む BigQuery の配列機能を使用することで取得できます。次のように、ゲームノートの生成プロセスから「疑似コード」を取り除いてデモンストレーションします。
このクエリは、統計リーダーボードごとに 1 行に集約され(たとえば、特定の日付のハードヒット リーダーなど)、配列内の特定のリーダーボードの上位または下位 5 位あるいは 10 位内にランク付けされた選手やチームをネストします。配列は構造体で構成されています。これは、複数のフィールドを一緒に保存できるレコード形式となっており、ここでは各エンティティのランキング、ID、名前、現在のチーム、およびフォーマット化された統計値が配列内の 1 つのレコードを構成しています。このようにネストすることで、この先の作業がしづらくなってしまう厳密なテキスト形式への集約なしで、最終的なノートの生成に役立ちそうな各統計リーダーボードの要素を保持します。
統計リーダーボード テーブルを配列と結合して、個々の統計ごとに 1 行のテーブルに戻すと、配列の要素をネスト解除して動的に使用できます。具体的には、リーダーボード テーブルをそれぞれ異なる見た目となるように修正します。ゲームノートの例の 1 つにテーブル内にある実際の選手の行のハイライト(「**」がついています)があり、これはこの選手のノートとなっています。同じ動的な「結合とネスト解除」により、ノート内の選手のランクに応じて、リーダーボード テーブルを異なる行数に制限できます。
配列と構造体を組み合わせると、同じデータのネストされた形式とネストされていない形式の両方を使用して、この追加のコンテキストをスケーラブルな方法でゲームノートに追加できます。全体として見ると、BigQuery の配列と構造体の機能を理解するために時間を費やすことで、比較的コンパクトなコードで成果を上げ、真にユニークなアウトプットを作成できます。
さまざまな基準を使った分析情報のスコアリングとランク付け
データを分析情報へ変換する自動化が始まると、新しい問題が発生する可能性があります。それは、分析情報が多すぎて、どれがより興味深いものか、どれがより関連性があるものかを見分けることができないということです。ビジュアルを使用しつつ、データをいくつかの重要なメッセージに凝縮する場合、「重要な」メッセージが多すぎると、重要なポイントを抽出するという本来の目的に反することになりかねません。
MLB ゲームノートには、データ内に重要度のランク付けに役立つ明確なヒントがいくつかあります。たとえば、30 個の修飾子を持つ統計で 7 番目にランク付けされているものよりも、500 個の修飾子を持つ統計で 2 番目にランク付けされているものの方が興味深いと言えるでしょう。BigQuery のランク関数とパーセンタイル ランク関数は、メモの主要コンポーネントとして使用される「統計的関心」スコアを作成する際に役立ちます。
多くの場合、特定の分析情報の価値に影響を与え得る外因性の要因があります。MLB ゲームノートの品質をスコアリングする際には、たとえば、選手やチームの人気の指標もいくつか組み込みました(詳細については、元の投稿をご覧ください)。従来のビジネス コンテキストには、他のセグメントよりも重要なセグメントや、フォーカスする価値のある特定のトップレベルの KPI があるかもしれません。したがって、スコアリングとランキングの分析情報の改善はビジネス固有となり、ユーザーのフィードバックに大きく依存する可能性があります。
BigQuery の分析情報生成コードとデータに組み込むことができる部分があり、より良い分析情報につながるものをより手軽に調整し、把握できます。MLB では、前述のメタデータ テーブルの数値として、統計がより重要であると考えられる情報を保存しました(たとえば、「ハードヒット率」は「ホームランの平均角度」よりも関心スコアが高く、2020 年のポストシーズンは 2019 年のシーズンよりも関連性スコアが高くなっています)。BigQuery パラメータを使用することで、ハードコードされた SQL を手動で修正して変更しなくても、同様のスコアリングの柔軟性を実現することもできます。
すべてをまとめて提供する
ここまで、自動化された手法で分析情報を作成できるようにするための重要な情報と BigQuery 機能について見てきました。2020 年の MLB シーズンが終わるまでに、各チームの数十におよぶ興味深いゲームノートを生成することができました。つまり、複数の試合がプレーされる通常の日に、数百ものノートを生成できました。また、システムを導入することで、さらなるスケーリングが可能になります。ノートを検討するために統計や期間を追加する場合は、メタデータ テーブルとコードにほんの少し加えるだけで追加できます。同じパターンに従って、システムを使用してさらにゲームノートを作成します。
最後のステップは、作成した分析情報をエンドユーザーに役立つ形式で「提供」することです。MLB ゲームノートでは、ゲームノート、対応するメタデータ、スコア情報を含んだ、最終的な BigQuery テーブルの上に配置されるデータポータル ダッシュボードを作成しました。ダッシュボードには、付随するテーブルと 1 つのノートのノートスコアとともにランク付けされたノートのリストがテキスト形式で表示されます(詳細については、以前の投稿をご覧ください)。
少々遠回りではありますが(ダッシュボードから分析情報を得てはどうなのかと思いませんでしたか?)、主な違いは、このダッシュボードにはテキストベースの分析情報が含まれており、ユーザー自身がデータから結論を見つけなければならない大きなテーブルではないことです。フィルタを使用することで、ユーザーは特定の試合や選手、あるいは特定の種類の統計にのみにフォーカスできます。カスタムノート スコアリングは、データポータル パラメータを使用して有効化されます。そのため、ユーザーはさまざまなコンポーネントの重みを増減して、よりカスタマイズされた分析情報のランキングを取得できます。
もちろん、他の Google Cloud ツールを使用した、ゲームノート(PDF、グラフィック、メール)などの他のプレゼンテーションや分析情報のパッケージ化も可能です。分析情報スコアリングと同様に、この多くはビジネス固有であり、ユーザー固有です。おそらく、「ノート」は定期的なレポートによってビジネス セグメントごとに配信されるか、特定のしきい値に達した分析情報のみが定期的に配信されます(異常検出と同様)。
ここでのビジョンは、BigQuery を使用した MLB ゲームノートの作成によって、業界全体のデータの専門家が、データから分析情報を生成する独自のプロセスのスケーリングについてどのように考えるかを見ていくことでした。うまくいけば、フィールド上の野球選手に関する興味深い分析情報の生成プロセスを自動化した方法によって、自身のフィールドでもより大きな影響力を持つことができるかもしれません。
メジャーリーグ ベースボールの商標および著作権は、メジャーリーグ ベースボールの許可を得て使用されています。MLB.com をご覧ください。
-データ サイエンス デベロッパー アドボケイト Alok Pattani

{kind=link}
{kind=link}