MLB、Google Cloud Smart Analytics プラットフォームでデータの分析情報をスケール

Google Cloud Japan Team
※この投稿は米国時間 2020 年 10 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
2020 年は異例の年となっていますが、アメリカの秋の伝統の一つ、ワールド シリーズが中止されることなく続いていることに多くのスポーツファンは安堵しているでしょう。ワールド シリーズは、何百万もの人々が観戦する、毎年恒例の野球のチャンピオンシップです。今年、ロサンゼルス ドジャースとタンパベイ レイズは、初回 2 戦を 1 勝 1 敗でタイとし、金曜日の夜から始まるエキサイティングな 3 日間の試合への機運を高める結果となりました。
COVID-19(新型コロナウイルス感染症)のパンデミックによりもたらされた数多くの課題に対処しなければならない状況はいまだ続いています。そんな中、野球を取り巻くイノベーションや野球ファンのエンゲージメントを促進するマルチシーズン パートナーシップの初シーズンとなる今回、Google Cloud とメジャーリーグ ベースボール(MLB)は共同で技術基盤を構築しました。データという点で考える場合、技術基盤として重要となる要素の一つに、大量の野球データの収集と分析を可能とするメジャーリーグ球場内のデータ キャプチャ システム、Statcast があります。この Statcast は、試合の観戦スタイルのみならず、決定を行う際の手法や根拠も変革しています。
この投稿では、MLB が Google Cloud をどのように活用して、Statcast から取得されるデータを、MLB のブロードキャスターやコンテンツ作成者が関連性の高いストーリーラインを特定し、豊富なコンテキストを試合に追加する際に活用できる分析情報に変換しているかに着目して解説します。ほとんどすべてのスポーツはデータドリブンになりつつあり、また、(数十年前からそうであるように)野球はその最前線にあります。このような分析情報を、選手、コーチ、フロントオフィスの意思決定者、メディア、ファンなど、誰でもアクセス可能なものにすることは、スポーツの未来にとって重要となります。
この記事で説明する技術ワークフローは、スポーツだけでなく、データを分析情報に変換するプロセスをスケールアップし、データドリブンの意思決定の改善を行おうとしているビジネスにも役立つ可能性があります。客観的な測定値を生成して、それらをタイムリーかつコンテクスチュアル、簡潔で貴重な情報源に変換し、自動化を活用して効率を大幅に向上させてこれを行えるようになれば、業界を問わず大きなメリットになります。

MLB ゲームノート
「ゲームノート」には、ある試合に関わった選手とチームに関する統計的な分析情報が記載されています。MLB によれば、放送局の 3 分の 2 以上が、テレビ放送の準備用としてゲームノートを時折、あるいは頻繁に作成しているといいます。また、球団、デジタル メディア、ライター、リサーチャーは、ゲームノートのような統計に基づいたノートを活用することで、シーズンを通してチームや選手が関与するさまざまなストーリーラインの特定やサポートができます。
以下は、MLB のコンテンツ チームがワールド シリーズの開催前に作成した、典型的なゲームノートとそれに付随する表です。レイズの Randy Arozarena とドジャースの選手 2 人が、打球速度、時速 95 マイル(約 152 km)以上を意味する「ハードヒット」の回数で、MLB ポストシーズンにおけるトップにどのようにランクインしたかが強調されています。
Randy Arozarena は、今回のポストシーズンにハードヒット数 26 を記録してトップに位置しており、Corey Seager や Mookie Betts もトップ 5 にランクインしています。
ハードヒット数ランキング(2020 年ポストシーズン)
1 位 Randy Arozarena(TB): 26
2 位タイ Corey Seager(LAD): 23
2 位タイ Freddie Freeman(ATL): 23
2 位タイ Michael Brantley(HOU): 23
5 位 Mookie Betts(LAD): 22
ハードヒット: 打球速度、時速 95 マイル(約 152 km)以上
ここ数週間で、Arozarena、Seager、Betts らが痛烈な打撃を放ち続けていることはベースボール ファンにとってはおなじみの話です。Statcast のデータを活用すれば、(すべての打球のスイング スピードを測定することにより)彼らの打球速度を定量化できます。また、上記のノートから、3 人の選手がプレーオフの段階で他のほとんどの選手よりも高い頻度でハードヒットを達成しているという情報が読み取れます。
メジャーリーグのコンテンツ リサーチャーは従来より、野球に関する知識や Baseball Savant などの柔軟なツールを使用してリーダーボードとトレンドを検索し、興味深いゲームノートを手作業で作成しています。この手作業のプロセスはその性質上時間やリソースを大量に消費するため、1 日で作成できるノートの数や具体性が制限されます。そのため、通常のレギュラー シーズン中のすべての試合、チームをカバーできない可能性があります(6 か月間で、30 チームにより 162 試合が行われます)。
一歩引いてこれらのノートの多くを見てみると、自動化にうってつけの、繰り返し可能なパターンがいくつかあることがわかります。たとえば、ゲームノートの多くでは、(上記の例のように)何かしらの関心のある統計における、MLB 全体でのトップ 5 やワースト 5 にランクインしているチームや選手が強調されています。自動化されたプロセスを使用すれば、さまざまな統計情報に関する同様のリーダーボードをより簡単に作成できます。また、過去のさまざまな期間(たとえば、直近のレギュラー シーズン、Statcast 導入後から現在までの期間など)を指定することもできます。これが、「自動化された」ゲームノートを生成し、1 日で作成されるノートの規模や速度を大幅に向上させるという私たちの動機づけになりました。
データの取り込み
Statcast は、選手がフィールドに現れた時点から試合に関連するデータを生成し始めます。Hawk-Eye Innovations が提供する光学式トラッキング センサーが、選手やボールの動きに関するデータを、各球場から Google Cloud でホストされる MLB PostgreSQL データベースに送信します。Statcast は 6 年間使用されており、MLB のテクノロジー チームは Statcast から取得されたデータを基とする数十個の指標を考案してきました。パートナーや球団は、Stats API アプリケーションを介して、イベントレベル(ピッチごと)のデータや関連する指標にアクセスできます(詳細については、こちらをご覧ください)。
複数の期間における、全チームおよび選手に関する多様な指標という大規模なデータ処理を実現するために、私たちは、MLB Stats API を介して送信されるイベントレベルの Statcast データを、リレーショナル データベース スタイルのテーブルに保存する取り込みプロセスを構築しました。過去 6 シーズンのすべてのゲームイベントの MLB データは、Google Cloud のフルマネージドでサーバーレスの、ストリーミング データ / バッチデータ処理サービスである Cloud Dataflow によって読み込まれて処理され、Google Cloud のサーバーレスでペタバイト規模のデータ ウェアハウスである BigQuery に保存されました。
私たちは Dataflow を活用し、必要な 6 シーズンのデータのバックフィルに加え、2020 年の MLB シーズンを通じた個々の試合からの新しいデータの取得を 1 つのジョブで行えるプラットフォームを実現しました(詳細は下の画像を参照)。バックフィルが必要になった際は、約 2.5 TB のデータを処理する数百台のマシンにスケールアップし、vCPU 処理時間で約 150 時間、実時間で 30 分で処理を完了しました。リーグ チャンピオンシップ シリーズの 2 試合のみからデータを取得する必要があったときは、1 台のマシンにより数分でこれを完了できました。
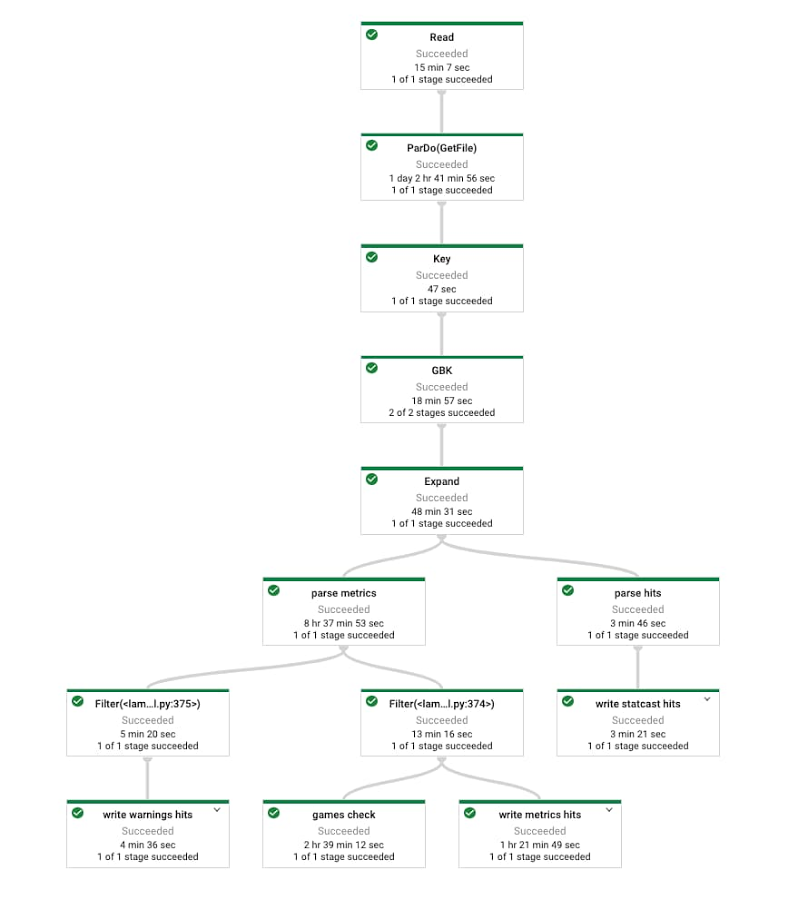
このプロセスの結果として、MLB シーズン中に毎日更新される Statcast の全履歴データを含む、多数のテーブルが BigQuery 内に作成されました。これは、各イベントの Statcast データを含む数百万の行と数十の列で構成される 1 つのテーブル、および、ゲームノートの生成に関係する、チームのスケジュール、名簿、スターター候補などが含まれる BigQuery テーブルからなります。
このデータ取り込みプロセスの毎日のオーケストレーションは、Apache Airflow 上に構築された Google のフルマネージド ワークフロー オーケストレーション サービスである Cloud Composer によって処理されました。Airflow は、個々のワークフローをプログラムで構築、スケジュール、モニタリングするために使用されるオープンソース プラットフォームです。DAG(実行するタスクのコレクション、Airflow のコアコンセプトの一つ)のスクリプトを作成することで、Cloud Composer でホストされる Airflow UI から、テスト、実行、パフォーマンスのモニタリング、デバッグのすべてを行うことができました。MLB データを毎日取り込むことに関して、私たちは、MLB API エンドポイントから生データを取得することから始まり、最終的に上記の例のようなノートを出力する 12 段階のプロセスを構築しました(詳細は下の画像を参照)。
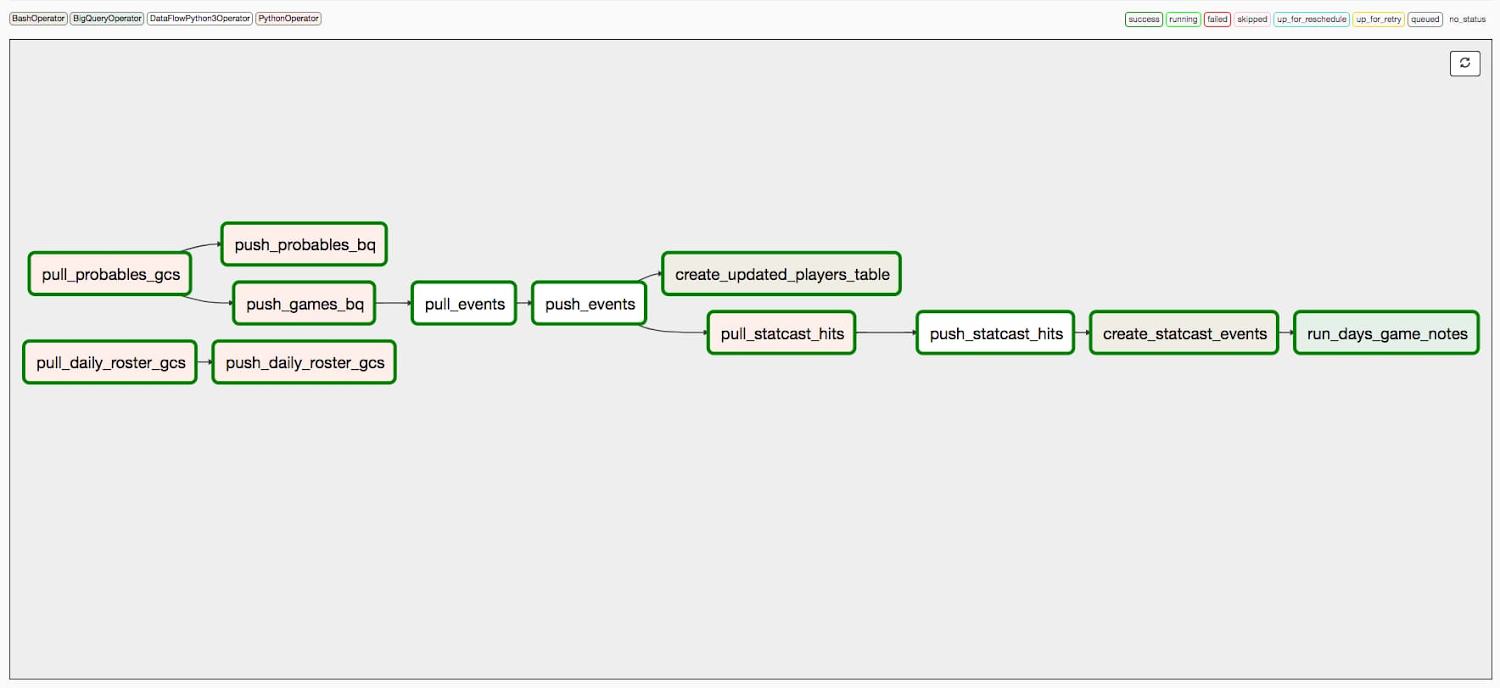
BigQuery を使用してデータを分析情報に変換する
データを BigQuery に保存して更新した後のステップは、ゲームノートとして活用できる、テキストベースの分析情報にそのデータを変換することでした。ゲームノートで使用できるさまざまな統計リーダーボードを生成する、数多くの一意の SQL クエリを作成することもできたでしょう。たとえば、今回のレギュラー シーズンで最もハードヒット数が多いチームに関する情報を生成するためのクエリや、ポストシーズンで速球の平均速度が最も速い投手に関する情報を生成するためのクエリなどを作成することが考えられます。このようにしても機能するでしょうが、私たちは、作成する「統計リーダーボード」タイプのノート数をある程度一般化し、より高度な BigQuery 機能を使用して、必要なコードの複雑さと冗長性を削減することで、より堅牢になるようにスケールアップを施しました。
ここで使用される統計リーダーボードには、ほとんどの場合、以下の要素がいくつか組み合わされています。
関心のある統計(ハードヒットの回数や速球の平均速度など)
リーダーボードがカバーする期間(過去 2 度のレギュラー シーズン、今回のポストシーズンなど)
関心のある「エンティティ」(通常はチームか選手のいずれか)
試合の「ファセット」、その統計情報の計算でどちらの「サイド」を使用するかを表す(打者と投手のどちらかなど)
ランキング資格基準、その統計情報がランキングで使用するに妥当であるとみなせる最小の試行回数(選手の「割合」に関する統計で分母が小さく、外れ値が発生する可能性がある場合に主に使用。たとえば、10 打席で打率 0.700 となる場合)
構成可能なこれらの要素は、それぞれ異なる「成分」として分離し、さまざまな形で組み合わせることでリーダーボードを作成できます。私たちは、それぞれの期間を対象に単一の BigQuery ビューを作成し、日付と試合の種類で Statcast イベント テーブルをフィルタリングしました。各統計情報には、計算式(分子と分母)と表示する値(名前や略語、小数値など)に関する情報が含まれ、これらは複数の「サポート」テーブルに保存されます。別の重要なテーブルには、各リーダーボードを構成する要素が示されています。これには、1 統計情報、1 期間、集計単位(チームまたは選手ごと)、観点(打者または投手側)、使用する適切な統計情報の名前などが含まれます。
これらの要素のさまざまな組み合わせを繰り返し処理するのは BigQuery のスクリプティング機能です。これにより、変数と制御ステートメントを使用して、1 つのリクエストで複数の SQL ステートメントをつなげることができます。ストアド プロシージャを使用すれば、関数型プログラミングでよく行われるように、スクリプト内の BigQuery ステートメントを個別の要素としてモジュール化できます。SQL コードを使用して SQL テキストを記述し、後で BigQuery で実行できるようにする、BigQuery の動的 SQL 機能により、これらのストアド プロシージャ内で実行できる内容の範囲を広げることができます。
これらの BigQuery 機能が使えないとしたら、SQL テキストを作成し、Python や R などの言語で BigQuery の外部から呼び出すことになっていたでしょう。BigQuery 環境自体でこれを行えば、データやビジネス ロジックをウェアハウスの外に移動する必要性がなくなり、SQL の使用に慣れているユーザーにとってのコードの単純さと一貫性を向上させることができます。
BigQuery に大量のビジネス ロジックを実装することにより、数百の SQL ステートメントを実行して 100 以上の「並列」統計リーダーボードを作成する、ランキング(生データおよびパーセンタイル)を追加する、さらに各統計のノートに追加するに足りる選手やチーム(通常はランキングのトップまたはワーストに位置する選手やチーム)を判断することが可能になりました。別の一連の SQL 操作では、個々のリーダーボード フィールドを実際のゲームノートに近いテキストに変換できます。たとえば、名前「Randy Arozarena」、ランク「1」、統計情報の名前「ハードヒット」、期間「2020 年ポストシーズン」、エンティティの種類「選手」、値「26」という統計情報が、「Randy Arozarena は、2020 年ポストシーズンにハードヒット(打球速度、時速 95 マイル以上)数 26 を記録して 1 位になりました」というテキストにまとめられます。
次に、現在のチームおよび選手に関するコンテキストをそれぞれのノートに追加します。特定のノートに付随する表では、サブクエリで BigQuery の配列を使用します。これにより、基になる各リーダーボードのフィルタリング、選手への現在のチームのタグ付け、テーブル テキスト内でノートが関係している特定選手の強調表示が可能です。アクティブな選手やチームに関するノートは、各チームの次に予定されている試合に添付されます。以下は、自動生成されたゲームノートの一例です。

オリジナルに非常に近いものになりました。
このパラダイムに適合するノートに関して、ノート生成機能をスケールアップすることは比較的簡単です。2020 年のポストシーズンの統計情報の追加後、リーグ チャンピオンシップ シリーズ中に 1 試合あたり 150 のノートを作成できました。これは、手作業で達成できるものと比較すれば大幅な増加であり、多くの時間が節約されました。
私たちは、すべてのゲームノートが、チーム、選手、試合などに関する「メタデータ」フィールドを含む別の BigQuery テーブルに保存されるようにして、アップストリーム プロセスでノートのさらなるフィルタリングや操作ができるようにしました。また、MLB のコンテンツ担当者や制作担当者にゲームノートを積極的に利用してもらうために、視覚的に魅力のあるユーザー フレンドリーなデータポータル ダッシュボードにゲームノートが表示されるようにしました。
最適なゲームノートを特定する
自動生成されるノートの数が一定量に達したとき、当初の課題とはまったく逆の課題が発生しました。すなわち、考慮すべきゲームノートの数が増えすぎたのです。これでは、放送局や制作チームが、テレビ放送でコンテキストを追加するために使用する主要な分析情報をいくつか探すような場面であっても、圧倒的な量の情報が表示されてしまう可能性があります。
上記で説明したフィールドでノートをフィルタリングできると便利ですが、私たちが追加したもう一つの機能はその機能ではなく、各ノートの「良さ」を表す「ノートスコア」でした。このスコアはその性質上主観的なものであるため、私たちはまず、特定のゲームノートがどれほど面白くて役立つかに関するさまざまなコンセプトを考案したうえで、それらを測定するデータドリブンの手法を特定することから始めました。現在、ノートスコア指標を構成する 8 つのコンポーネント スコアは次のとおりです:
統計の関心、極端さ(印象の強さ)とランキングの方向性(トップかワーストか)に関する情報を含む
選手と試合の関連性、現在、チームの先発投手候補に関するノートのスコアを上げるために使用
選手の関連性、選手が受賞したさまざまな MLB の栄誉賞(権威性の相対的高さと最新性に基づき評価)を使用して、選手の関連性に優劣を付ける
選手の人気、2020 年 8 月時点の YouGov のリスト「アメリカで最も有名な現代野球選手」に基づく
チームの関連性、レギュラー シーズン中の FiveThrtyEight のポストシーズン予測(プレーオフを行い、ワールド シリーズで勝つ可能性)に基づく。ポストシーズンに進出し勝ち残っているすべてのチームでは同じ
チームの人気、2020 年 8 月時点でのチームの公式アカウントの Facebook ファン数および Twitter フォロワー数に基づく(いずれも Statista から取得)
統計の種類、統計が幅広く興味深い / 適切であるかに関する優劣を表す
統計の期間、最近の情報を含む統計が、それ以前のシーズンの統計よりもどの程度興味深い / 適切であるかを表す
ゲームノートのスコアの「最終版」は、これらのコンポーネント スコアの加重平均です。現在のところ、「統計の関心」で最も高い重み付けがなされ、次に「選手と試合の関連性」、「選手の関連性」、「統計の期間」で比較的高い重み付けがなされます。MLB 用のゲームノート ダッシュボードでは、データポータル パラメータを利用して、ユーザーが独自の重みを入力して「カスタム」ノートスコアを作成できるようにし、独自のノートのランキングを作成できるようにしました。
ゲームノートのスコア コンポーネントの測定方法やそれらの重み付け方法には多くの主観が介在していることは間違いありません。ですが、ノートの品質を客観的に測定する方法がないため、システムのプロトタイプを作成する目的で、プレースホルダとしてこのような手法を使うことは合理的と考えることもできます。将来的には、ノートの利用者が実際に感じた品質の評価や、ノートが放送で使用されたかどうかに関する追跡を行うことも可能です。この「ラベリング」を行えば、教師あり機械学習問題に関するデータを取得できます。これにより、過去のノートのデータを活用して、新しいノートに対して実際に感じる品質や、新しいノートが使用される可能性を予測し、実際の結果に基づいてノートをスコアリングできるようになります。
とは言うものの、重要な点はノートスコアを計算することです。現在の手法であっても、良いゲームノートと悪いゲームノートを区別する手がかりとすることは通常であれば可能です。これにより、MLB の制作チームとコンテンツ チームは、限られた時間と注意を、大きなインパクトを生み出す可能性の高いノートに向けられるようになります。
すべてをまとめ、今後のために構築する
リーダーボードの作成、ノートの生成、ノートのスコアリング、試合への添付、ダッシュボードの準備で必要となる BigQuery の要素を一連のビューとストアド プロシージャにカプセル化することで、毎日のノート生成プロセスをいくつかの短い SQL ステートメントで実行できるようになりました。すでに解説したように、このコードは上記の Cloud Composer パイプラインの最後で実行されます。シーズン中には毎朝、BigQuery 内の Statcast データが更新された直後にゲームノートが生成されます。
MLB が、Google Cloud のデータ分析ツールスイートを使用して、大幅に改善された規模と速度でゲームノートを自動的に作成しているということが、今回の記事の概要です。MLB は、Dataflow を使用して過去 6 シーズンと今後の Statcast イベントデータをキャプチャします。また、BigQuery を使用して統計情報を計算して、適切なコンテキストを追加してテキスト形式のノートに変換します。その後、Cloud Composer を使用して毎日のデータ取り込みとノート作成パイプラインのオーケストレーションを行います。豊富な分析情報が記載された数百のゲームノートが、MLB のコンテンツ チームやイベント作成チームの参考情報として毎日生成され役立っているのです。
統計リーダーボードをベースとするゲームノートは、特に簡単にスケールできる部類のノートかもしれません。もちろん、特定の選手やチームに関する最高値や最低値、単一の外れ値イベント、2 つのチームの選手が対戦する特定の試合に関するノートなど、自動的に作成できるであろうゲームノートは他にも数多くあります。また、今後力を入れようとしていることの一つに、リアルタイムのゲームノートを試合中に作成することがあります。これにより、フィールド上で発生したイベントに対して、その数秒後にコンテキストを提供できるようになります。
これからも、MLB と Google Cloud のパートナーシップによるエキサイティングなコラボレーションにご期待ください。他にも数多くご用意しています。ですが、とりあえず今は 2020 年のワールド シリーズを楽しみましょう。
メジャーリーグ ベースボールの商標および著作権は、メジャーリーグ ベースボールの許可を得て使用されています。MLB.com をご覧ください。
-データ サイエンス デベロッパー アドボケイト Alok Pattani




{kind=link}
{kind=link}