お客様からのフィードバックを変革: BigQuery ML の音声文字変換によるカスタマー レビュー音声の分析
Google Cloud Japan Team
※この投稿は米国時間 2024 年 4 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery に統合されている音声文字変換機能は、音声データに隠された貴重な分析情報を引き出すための強力なツールになります。このサービスは、カスタマー レビューの通話のような音声ファイルをテキスト形式に文字変換して、BigQuery の堅牢なデータ プラットフォームで分析できるようにします。音声文字変換と BigQuery の分析機能を組み合わせることで、お客様の感情を掘り下げ、繰り返し発生する製品の問題を特定し、お客様の声を深く理解できるようになります。
BigQuery の音声文字変換は、音声データを実用的な分析情報に変換し、業界全体に潜在的なメリットをもたらすとともに、複数のチャネルにわたるお客様とのやり取りをより深く理解できるようにしてくれます。また、BigQuery ML を使用して Gemini 1.0 Pro を活用することで、BigQuery ML のネイティブな音声文字変換機能を通じて音声ファイルから抽出したテキストについて、さらにエンティティ抽出や感情分析などの分析情報やデータ形式を取得することもできます。以下に、特定の業界のユースケースとビジネス価値をいくつかご紹介します。
BigQuery ML などの高度な AI 機能を使用する場合も、BigQuery に組み込まれているすべてのガバナンス機能にアクセスできます。これにより、アクセス制御パススルーが利用できるため、BigQuery オブジェクト テーブルに設定した行レベルのセキュリティに基づいて、お客様の音声ファイルから得た分析情報を制限できます。
音声データを分析情報に変える準備はできましたか?それでは、BigQuery で音声文字変換を使用する方法についてご説明しましょう。
Google Cloud Storage バケットに、お客様からのフィードバックの通話記録が音声ファイルとして保存されているとします。BigQuery の ML.TRANSCRIBE 関数は、Google の Vertex AI プラットフォームでホストされている事前トレーニング済みの音声文字変換モデルに接続されており、これを使用すると、これらの音声ファイルを BigQuery 内で判読可能なテキストに自動的に変換できます。音声データに特化した変換機とお考えください。ML.TRANSCRIBE 関数に、音声ファイルの場所(オブジェクト テーブル内)と使用する音声文字変換モデルを指示します。次に、ML を活用して音声文字変換処理を行い、テキスト結果を BigQuery に直接配信します。これにより、お客様の会話を他のビジネスデータと合わせて簡単に分析できます。
このプロセスを BigQuery で見ていきましょう。
設定の手順:
-
開始する前に、Google Cloud プロジェクトを選択し、請求先アカウントをリンクして、必要な API を有効にします。詳細な手順はこちらからご確認ください。
-
認識ツールを作成します。認識ツールは音声認識の構成を保存するもので、作成は任意です。
-
クラウド リソース接続を作成し、接続のサービス アカウントを取得します。詳細なガイドはこちらをご覧ください。
-
こちらの手順に沿って、サービス アカウントへのアクセスを許可します。
-
こちらの手順に沿って、モデルとオブジェクト テーブルを含むデータセットを作成します。
-
音声ファイルをダウンロードして Google Cloud Storage に保存します。
モデルの作成
REMOTE_SERVICE_TYPE で CLOUD_AI_SPEECH_TO_TEXT_V2 のリモートモデルを作成します。モデルにより、Speech-to-Text API が BigQuery 内で利用可能になります。
構文:
クエリの例:
音声ファイルを参照するオブジェクト テーブルの作成
構文:
サンプルコード:
'BUCKET_PATH' は、音声ファイルが保存されている Google Cloud Storage バケット / フォルダのパスに置き換えてください。
BigQuery ML を使用した音声ファイルの音声文字変換
構文:
クエリの例:
結果:
ML.TRANSCRIBE の結果には次の列が含まれます。
-
transcripts: 処理された音声ファイルの音声文字変換テキストが含まれます。
-
ml_transcribe_result: Speech-to-Text API からの結果を含む JSON 値
-
ml_transcribe_status: 各行の音声文字変換処理の成功 / 失敗を示す文字列値が含まれます。処理が成功した場合は空になります。
- オブジェクト テーブルの列
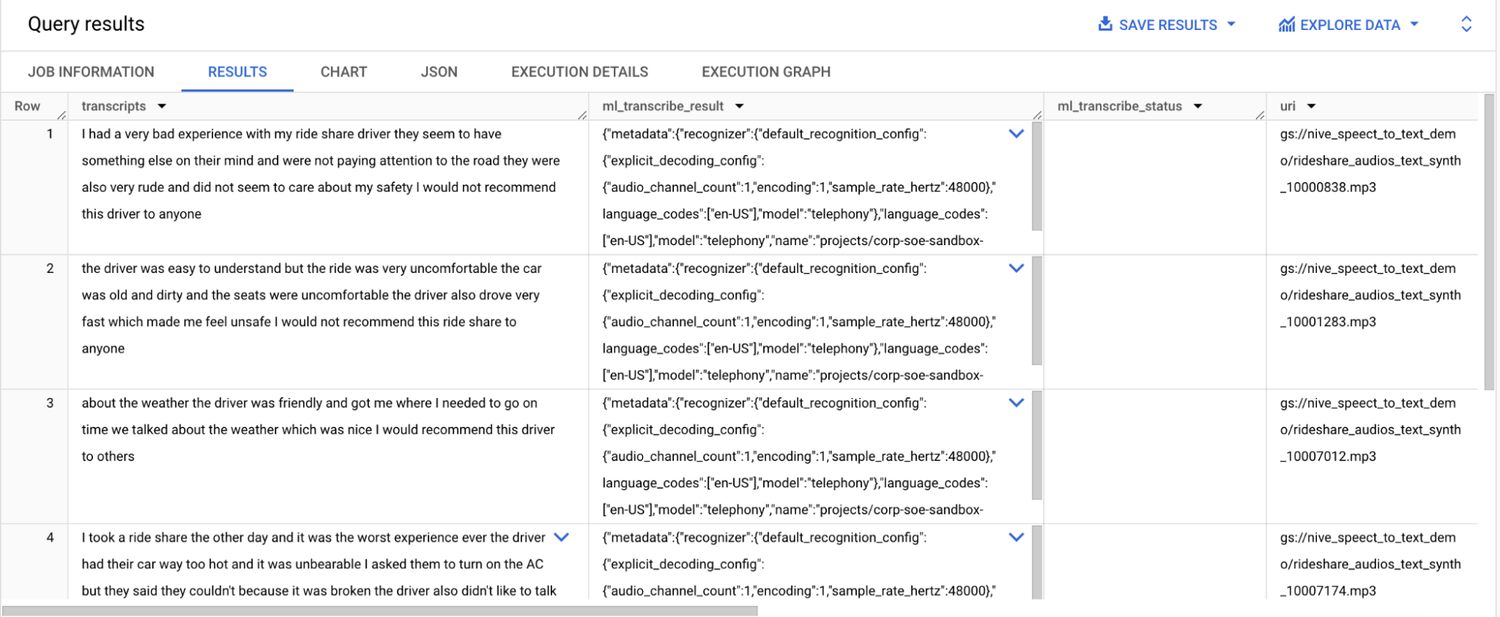
ML.TRANSCRIBE 関数を使用すると、手作業による音声文字変換の必要がなくなり、時間と労力を節約できます。音声文字変換されたテキストは BigQuery 内で簡単に検索および分析が可能になり、音声データから貴重な分析情報を抽出できるようになります。
追加のアイデア
-
音声ファイルから抽出されたテキストを取得し、Gemini 1.0 Pro と BigQuery ML の ML.generate_text 関数を使用して、製品名、株価などのエンティティや、対象となる他のタイプのエンティティ データを抽出した後、JSON で構造化する。
-
Gemini 1.0 Pro と BigQuery ML を使用して、抽出されたテキストの感情分析を行い、ポジティブ / ネガティブな感情を JSON で構造化する。
-
お客様からのフィードバックの逐語的な内容や感情スコアを顧客生涯価値の合計スコアやその他の関連する顧客データと結合して、定量的データと定性的データが相互にどのように関連しているかを確認する。
-
抽出されたテキスト上にエンべディングを生成し、ベクトル検索を使用して音声ファイルで特定のコンテンツを検索する。
詳細については、ML.TRANSCRIBE に関するGoogle Cloud の公式ドキュメントをご確認ください。また、BigQuery ML の Gemini 1.0 Pro サポートに関するブログでは、「追加のアイデア」で概説している他の生成 AI ユースケースについてもご覧いただけます。ぜひチェックしてみてください。
-データ分析カスタマー エンジニア、Nivedita Kumari
-データ分析 AI / ML 担当プロダクト責任者、Michael Kilberry
