BigQuery での LLM のファインチューニングと評価の概要
Google Cloud Japan Team
※この投稿は米国時間 2024 年 4 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery では、Gemini 1.0 Pro、Gemini 1.0 Pro Vision、text-bison など、Vertex AI でホストされているさまざまな大規模言語モデル(LLM)を使用してデータを分析できます。これらのモデルは、プロンプト エンジニアリングを使用するだけで、テキストの要約や感情分析など、複数のタスクで使用できます。ただし、モデルに想定される動作をプロンプトで簡潔に定義することが難しい場合や、プロンプトが想定される結果を十分に一貫して生成しない場合など、シナリオによってはモデルのファインチューニングによるその他のカスタマイズが必要です。また、ファインチューニングは、モデルが特定のレスポンスの種類(例: 簡潔か詳細か)や新しい動作(例: 特定のペルソナとして応答する)を学習したり、新しい情報でモデルそのものをアップデートしたりするのにも役立ちます。
Google は本日、BigQuery の LLM の教師ありファインチューニングによるカスタマイズをサポートすることを発表いたします。BigQuery による教師ありファインチューニングでは、入力テキスト(プロンプト)と想定される理想的な出力テキスト(ラベル)の例があるデータセットを使用し、これらの例から推測される動作やタスクを模倣するようにモデルをファインチューニングします。
機能の紹介
モデル ファインチューニングを説明するために、テキストデータを使用した分類問題を見ていきましょう。医学記録転写のデータセットを使用して、特定の記録を 17 のカテゴリ(例:「アレルギー / 免疫学」、「歯科」、「循環器 / 呼吸器」など)のいずれかに分類するようモデルに依頼します。
データセット
使用したデータセットは mtsamples.com からのもので、Kaggle で提供されています。モデルのファインチューニングと評価を行うために、まず Cloud Storage で利用可能なこのデータのサブセットを使用して、BigQuery で評価テーブルとトレーニング テーブルを以下のように作成します。
トレーニング データセットと評価データセットには、転写された記録を含む「input_text」列と、ラベルまたはグラウンド トゥルースのデータを含む「output_text」列があります。
モデルの推論向けに、まずモデルのタスクの説明と作成したテーブルの記録を連結して、プロンプトをコンストラクトします。次に、出力を取得するために ML.GENERATE_TEXT 関数を使用します。モデルはすぐに多くの分類を正しく行いますが、いくつかの記録を誤って分類してしまいます。誤って分類されたレスポンスの例を以下に示します。
上述のケースでは、正しい分類は「循環器 / 呼吸器」です。
ベースモデル向けの指標ベース評価 モデルのパフォーマンスをより確実に評価するには、BigQuery の ML.EVALUATE 関数を使用して、test/eval データセットからの理想的なレスポンスに対するモデル レスポンスの比較指標をコンピューティングできます。その方法は次のとおりです。
上述のコードでは、入力として評価テーブルを提供し、モデルを評価するタスクの種類として「classification」を選びました。他の推論パラメータはデフォルトのままにしましたが、評価のために変更できます。
返される評価指標は、クラス(ラベル)ごとにコンピューティングされます。結果は次のようになります。
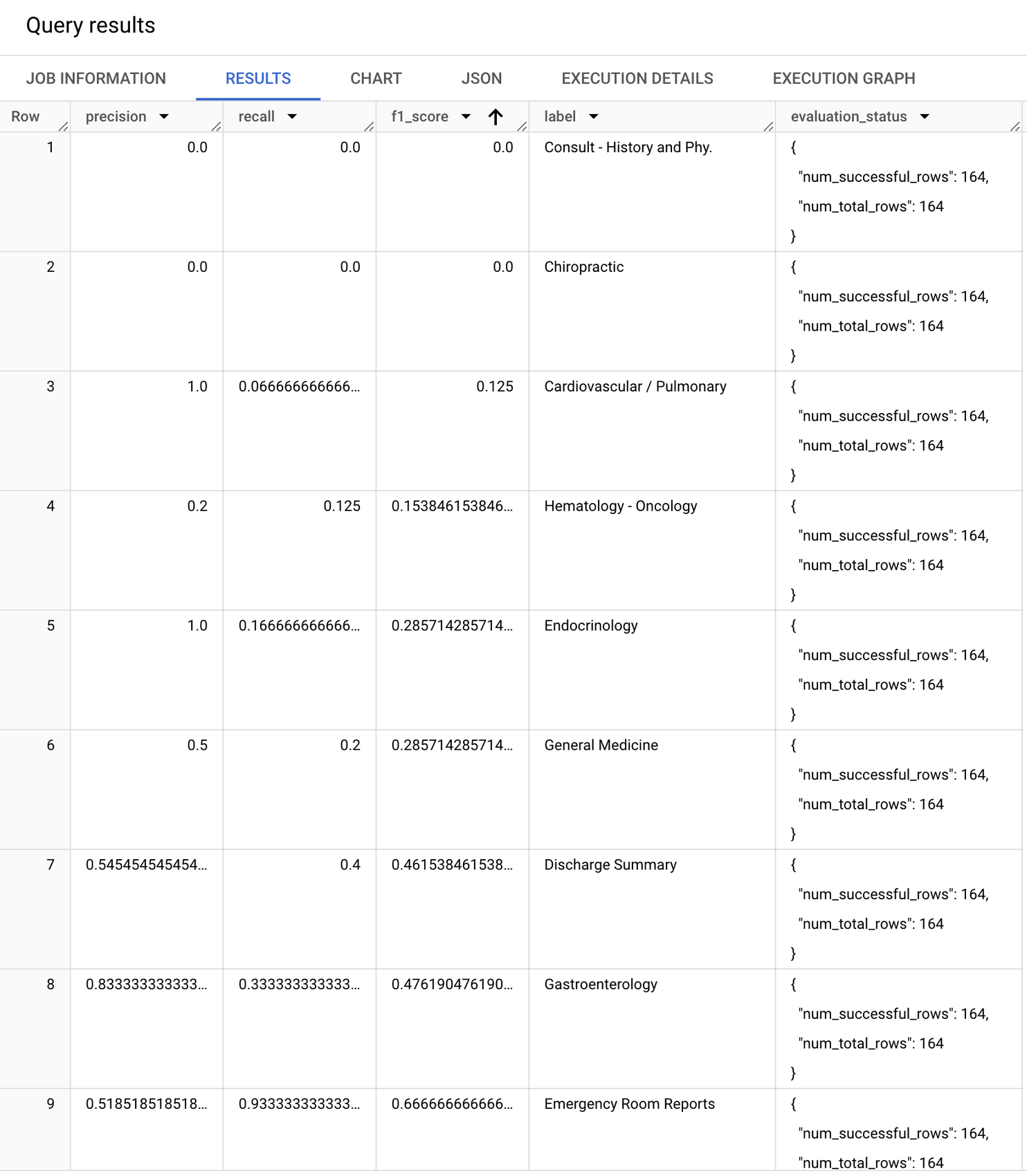
F1 スコア(適合率と再現率の調和平均)に注目すると、モデルのパフォーマンスがクラスによって異なることがわかります。たとえば、ベースライン モデルが「剖検」、「食事と栄養」、「歯科」で適切なパフォーマンスを発揮しているものの、「問診 - 病歴と病態」、「カイロプラクティック」、「循環器 / 呼吸器」クラスでのパフォーマンスは不十分です。
では、モデルをファインチューニングして、このベースライン パフォーマンスを改善できるかどうかを確認します。
ファインチューニングしたモデルを作成する
BigQuery でファインチューニングされたモデルを作成するのは簡単です。CREATE MODEL ステートメントで、「prompt」と「label」列のあるトレーニング データを指定することで、ファインチューニングできます。ファインチューニングには、先ほどの評価で使ったのと同じプロンプトを使用します。次のようにファインチューニングしたモデルを作成します。
ファインチューニングしたモデルを作成するために使用する CONNECTION には、(a)Storage オブジェクト ユーザーと(b)Vertex AI サービス エージェントのロールがアタッチされている必要があります。さらに、Compute Engine(GCE)のデフォルトのサービス アカウントには、プロジェクトの編集者のアクセス権が必要です。BigQuery 接続の操作のガイダンスについては、ドキュメントをご覧ください。
BigQuery は、Low-Rank Adaptation(LoRA)と呼ばれる技術を使ってモデルをファインチューニングします。LoRA チューニングはパラメータ効率調整(PET)メソッドで、事前トレーニングされたモデルの重みを凍結し、トレーニング可能なランク分解行列を Transformer アーキテクチャの各レイヤに注入することで、トレーニング可能なパラメータの数を軽減します。モデルのファインチューニング自体は Vertex AI コンピューティング上で行われ、アクセラレータとして GPU または TPU を選択するオプションがあります。スキャンされたデータまたは使用されたスロットについては BigQuery から、消費された Vertex AI リソースについては Vertex AI から請求されます。ファインチューニング ジョブは、学習済みの重みを表す新しいモデル エンドポイントを作成します。ファインチューニングされたモデルのクエリを実行する際に発生する Vertex AI 推論料金は、ベースライン モデルの場合と同じです。
このファインチューニング ジョブは、「max_iterations」などのトレーニング オプションによって異なりますが、完了するのに 2 時間ほどかかる場合があります。完了すると、ファインチューニングしたモデルの詳細を BigQuery UI で確認でき、ファインチューニングしたモデルの別のリモート エンドポイントが表示されます。
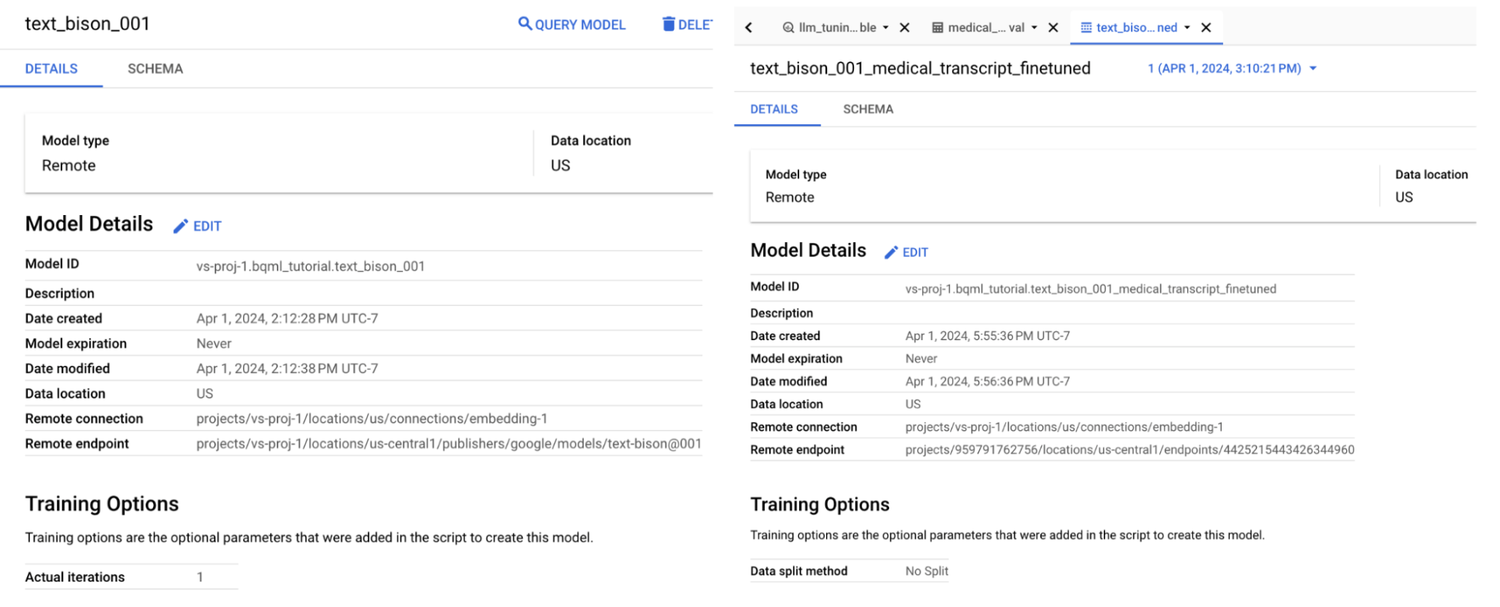
ベースライン モデルとファインチューニング モデルのエンドポイント。
現在、BigQuery は text-bison-001 と text-bison-002 モデルのファインチューニングをサポートしています。
ファインチューニング モデルのパフォーマンスを評価する
次のようなコードを使って、ファインチューニングされたモデルから予測を生成できます。
先ほど評価したプロンプトのサンプルに対するレスポンスを見てみましょう。同じプロンプトを使用することで、このモデルは転写された記録を「循環器 / 呼吸器」という正しいレスポンスに分類するようになりました。
ファインチューニングされたモデルの指標ベースの評価
次に、ベースモデルの評価で使用したのと同じ評価データと同じプロンプトを使用して、ファインチューニングされたモデルの指標をコンピューティングします。
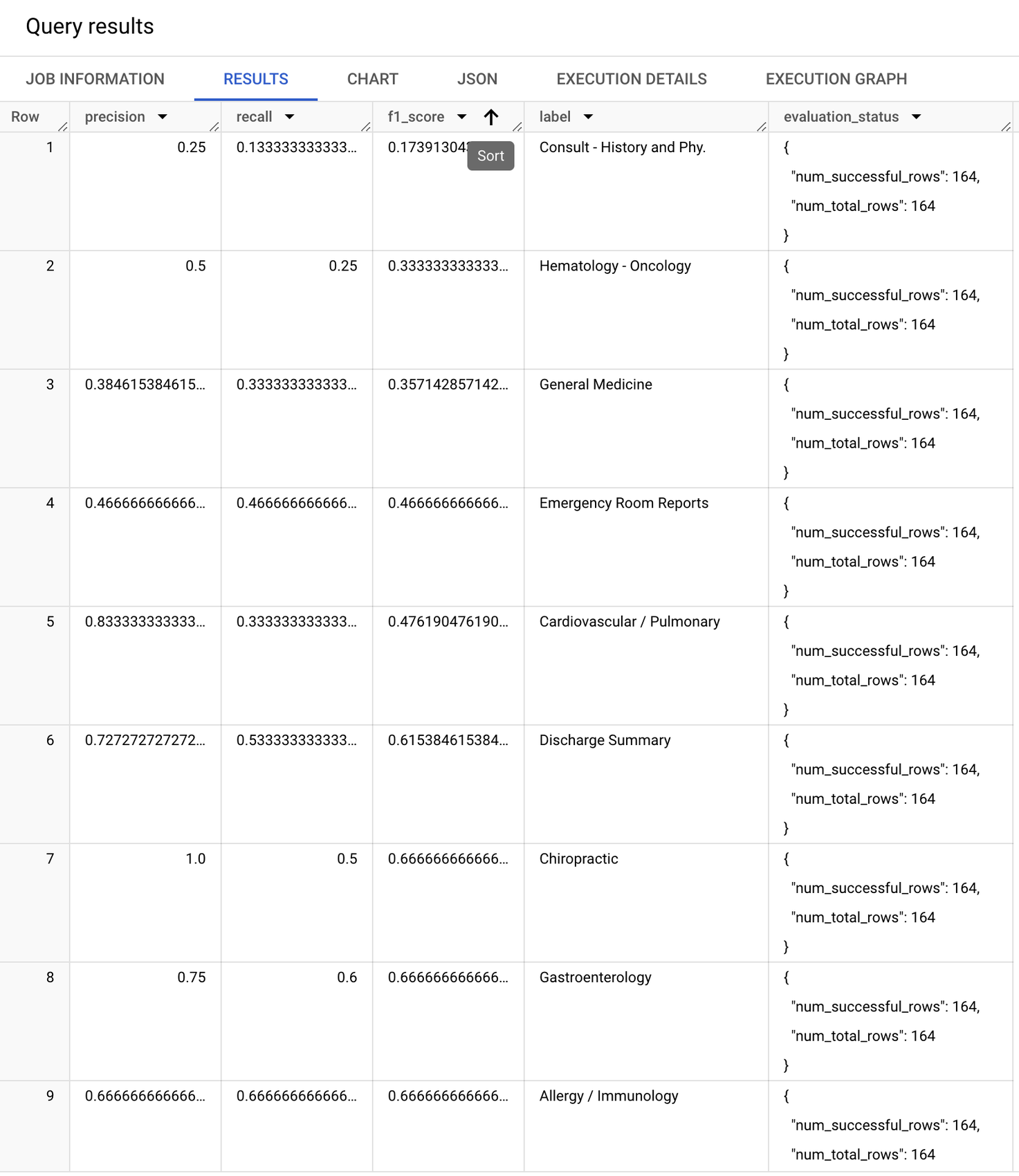
ファインチューニングされたモデルの指標は以下のとおりです。このブログで使用したファインチューニング(トレーニング)データセットには 519 例しか含まれていなかったにもかかわらず、すでにパフォーマンスが著しく向上しているのがわかります。以前はモデルのパフォーマンスが低かったラベルの F1 スコアが改善され、「マクロ」F1 スコア(全ラベルの F1 スコアの単純平均)は 0.54 から 0.66 に跳ね上がりました。
推論に対応
ファインチューニングされたモデルは、前のステップでサンプルのレスポンスを取得するために使用した ML.GENERATE_TEXT 関数を使用した推論に使用できるようになりました。ファインチューニングされたモデルのために追加のインフラストラクチャを管理する必要はなく、ベースモデルで発生するのと同じ推論の価格が請求されます。
BigQuery の text-bison モデルのファインチューニングをお試しになるには、ドキュメントをご覧ください。フィードバックの提供やその他のモデルのファインチューニングのサポートが必要な場合は、bqml-feedback@google.com までご連絡ください。
このブログ投稿を執筆するにあたって、Tianxiang Gao の協力を得ました。この場を借りて感謝を申し上げます。
ー BigQuery ML、プロダクト リーダー Vaibhav Sethi
ー Google Cloud、ソフトウェア エンジニア Eric Hao


