BigQuery、業界トップクラスとなる 99.99% の稼働時間の SLA を提供
Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
ビジネスではこれまで以上に、データ ウェアハウスに保存された情報に基づいてデータドリブンな意思決定をリアルタイムで行うようになっています。今日のデータ ウェアハウスには分析の需要が増えても稼働時間を維持することが求められ、組織はミッション クリティカルな分析情報へのすばやいアクセスを必要としています。計画外のダウンタイムで業務が中断されると、企業の売り上げ、評判、顧客関係に深刻な影響をおよぼす可能性があります。Google Cloud をご利用のお客様は、自社のオンライン トランザクション処理データベースと同じような高可用性をデータ ウェアハウスにも期待しています。
以上を踏まえて、このたび BigQuery のサービスレベル契約(SLA)で 1 か月あたり 99.99% の稼働時間を保証するようにしました。これは、以前の 99.9% から改善された、業界トップクラスの稼働時間となります。このレベルの可用性では、BigQuery 上のアプリケーションの非稼働時間が 1 か月あたり 5 分未満となり、計画的ダウンタイムはなくなるため、お客様の組織で完全なビジネスの継続性を確保できるようになります。一方、稼働時間の SLA が 99.9% のプロダクトの場合は、1 か月あたり最大 43 分の非稼働時間が発生しうるため、業務のパフォーマンスに影響をおよぼす可能性があります。
信頼性の確保に取り組んでいる Google Cloud では、高可用性インフラストラクチャをお客様に提供して、特に需要の高いワークロードを実行可能にしています。この改善された SLA により、顧客向けの分析アプリケーションやリアルタイムの予測分析などの重要なワークロードを安心して実行していただけます。
BigQuery が稼働時間を保証する仕組み
Google Cloud のエンタープライズ データ ウェアハウスである BigQuery はサーバーレス アーキテクチャを採用しているため、管理対象の仮想マシンやストレージ サーバーが必要ありません。次の図は、BigQuery アーキテクチャのコンポーネントにおける、コンピューティングとストレージの分離の様子を表しています。
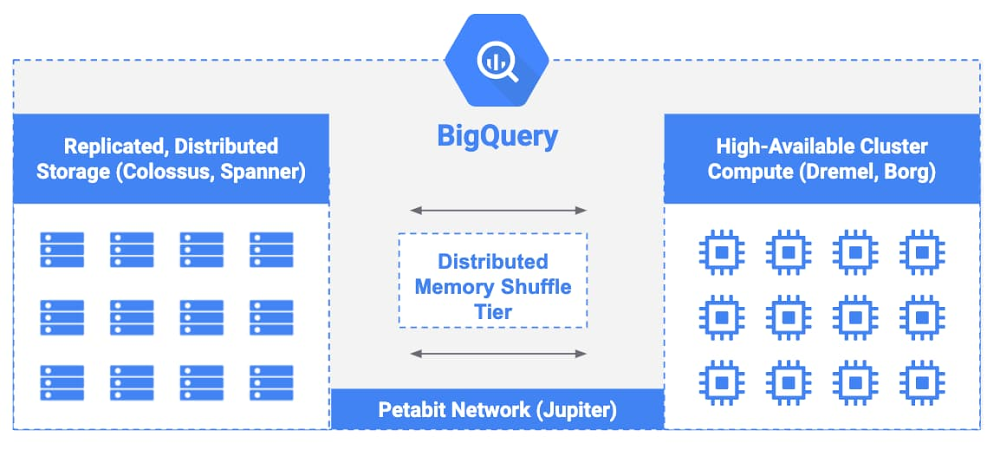
BigQuery は、Borg、Colossus、Spanner、Jupiter、Dremel などの Google テクノロジーを利用しています。お客様のすべてのデータは Colossus(Google の耐久性に優れた分散ファイル システム)と Spanner(Google の強整合性を備えたデータベース サービス)で管理されます。Colossus と Spanner はデータのレプリケーション、ディスク クラッシュ時の復元、分散型管理を行うため、単一障害点が存在しません。こちらのブログ投稿で技術的な詳細をご覧ください。
同様に、BigQuery のコンピューティングは、Google の大規模クラスタ管理システムである Borg を利用しています。Borg クラスタは数万台のマシンと数十万のコアで実行されます。マシンに障害が発生した場合は、Borg が処理タスクを自動的にルーティングします。Google 全体では、たとえ毎日数百台のサーバーに障害が発生したとしても、ワークロードの実行が停止しないように Borg が処理します。
最後に、BigQuery のクエリ実行エンジンである Dremel は完全にステートレスなサービスです。そのため、単体の Dremel ノードまたはクラスタ全体が停止してしまった場合でも、実行中のクエリは中断されません。これらのテクノロジーを Jupiter(Google の高性能ネットワーキング インフラストラクチャ)と組み合わせることで、BigQuery は、ビル火災、停電、光ファイバ ケーブル切断、ネットワーク分割などの予期せぬ問題の発生時に自動フェイルオーバーを提供できるようにしています。すべての処理はバックグラウンドで行われるため、お客様は使用するリージョンを指定するだけで済みます。
今回改善された BigQuery の SLA は、全ユーザーと BigQuery リージョンとマルチリージョンのすべてのデプロイメントが対象で、追加費用なしでご利用いただけます。詳細はこちら。
Brian Welcker, Group Product Manager, BigQuery



