BigQuery now offers industry-leading uptime SLA of 99.99%
Brian Welcker
Director, Product Management
More than ever, businesses are making real-time, data-driven decisions based on information stored in their data warehouses. Today’s data warehouse requires continuous uptime as analytics demands grow and organizations require rapid access to mission-critical insights. Business disruptions from unplanned downtime can severely impact company sales, reputation, and customer relations. Our customers expect their data warehouses to be highly available, just like their online transaction processing databases.
With this in mind, the BigQuery service-level agreement (SLA) now provides an industry-leading 99.99% uptime per calendar month, increased from the previous uptime of 99.9%. This level of availability means that your applications on BigQuery can now rely on less than five minutes of unavailability per calendar month with no planned downtime—ensuring full business continuity for your organization. In comparison, products with a 99.9% uptime SLA can have up to 43 minutes of downtime per calendar month, which could impact business performance.
Our commitment to reliability ensures that we deliver highly available infrastructure for customers to run their most demanding workloads. Our improved SLA gives you peace of mind for essential workloads, such as customer-facing analytics applications or real-time predictive analytics.
How BigQuery ensures uptime
BigQuery, Google Cloud’s enterprise data warehouse, has a serverless architecture, which means that there are no virtual machines or storage servers to manage. The following diagram shows the components of the BigQuery architecture, highlighting the separation of compute and storage:
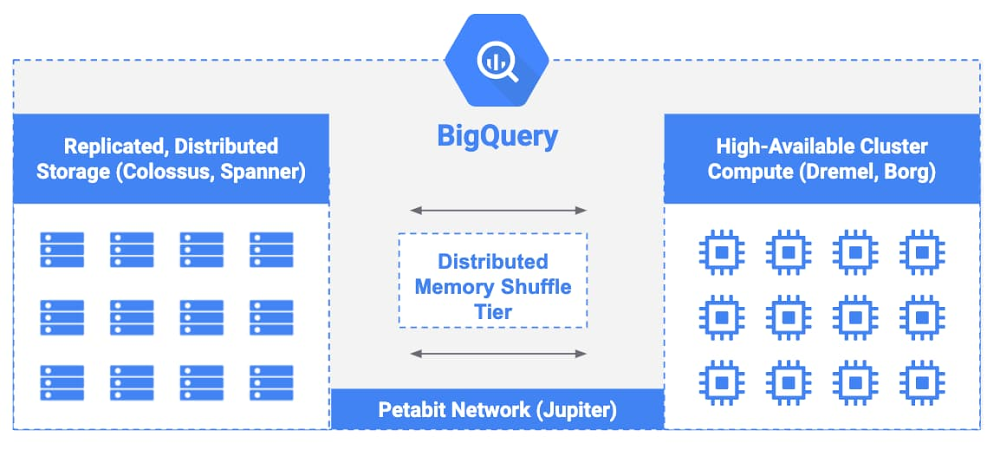
BigQuery relies on Google technologies like Borg, Colossus, Spanner, Jupiter, and Dremel. All customer data is managed in Colossus, Google’s highly durable distributed file system, and Spanner, Google’s strongly consistent database service. Colossus and Spanner handle replication of data, recovery for when disks crash, and distributed management, so there is no single point of failure. Find more technical details in this post.
Similarly, BigQuery compute relies on Borg, Google’s large-scale cluster management system. Borg clusters run on tens of thousands of machines with hundreds of thousands of cores and Borg automatically routes processing tasks in the case of machine failures. At Google scale, even if hundreds of servers fail every single day, Borg works to ensure that workloads don’t stop running.
Finally, Dremel, BigQuery’s query execution engine, is completely stateless. This means that if a Dremel node or even an entire cluster goes down, running queries will not be interrupted. Combined with Jupiter, Google’s high-performance networking infrastructure, these technologies enable BigQuery to offer automated failover when unexpected problems occur, such as a building fire, power outage, cut fiber-optic cable, or network partitions. All of this happens behind the scenes, so you only need to decide which region(s) to use.
The updates to BigQuery's SLA covers all users and all BigQuery regional and multi-region deployments at no additional cost. Learn more.
