新たに一般提供される Dataproc の機能がデータ サイエンスと ML の機能を拡張
Google Cloud Japan Team
※この投稿は米国時間 2020 年 1 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
データ サイエンティストの仕事は容易ではありません。その仕事は、データの背景にある毎日のビジネスを把握することから、機械学習に関する最新の学術研究の内容を把握することまで多岐にわたります。そのため、データ サイエンティストは効率的に職務をこなす必要があり、データ環境の移行や、元データの作業に関連する処理上の制限への対処などを心配している暇はありません。
Google Cloud の Dataproc を使用すれば、クラウド ネイティブの Apache Spark クラスタと Hadoop クラスタを簡単に実行できます。これは、データの増加に対処するために、個人のサーバーやノートパソコンではなく、Apache Spark などの分散されたクラスタ環境を使用する必要があるサイエンティストや機械学習研究者にとって特に役立ちます。Apache Spark を使用すれば、あらゆるサイズのデータ用の Python インターフェースや R インターフェースを利用できます。Dataproc を使用すれば、Google Cloud でオープンソースのデータ処理を実行できるようになるため、既存のデータ分析をクラウドサイズのデータセットへとすぐに拡張できます。
このたび、Dataproc の一部の新機能が一般提供となります。これらの機能により、現在お使いのオープンソース ツールやアルゴリズム、プログラミング言語を大規模なデータセットに適用できるようになります。クラスタやコンピュータの管理は必要ありません。一般提供となるこれらの新機能によって、データ サイエンティストとアナリストは、カスタマイズした開発環境をベースにして本番環境システムを構築できるようになります。
本質ではない IT インフラストラクチャの課題にわずらわされることなく、データを業務の中心に据えることができます。
ここでは、これらの機能の詳細をご紹介します。
自動スケーリングとノートブックによる環境の効率化
Dataproc の自動スケーリングとノートブックを使用すると、データ サイエンティストは使い慣れたノートブック環境で作業できるので、基盤となるリソースを変更したり、クラスタ処理を行うコンピュータを他のアナリストと取り合ったりする必要がなくなります。これは、Dataproc のノートブック用コンポーネント ゲートウェイと自動スケーリング(一般提供)を組み合わせることで可能になります。
Dataproc の自動スケーリングを使用すると、データ サイエンティストは分離された自身の小さいカスタム クラスタで作業しながら、記述統計の実行、機能の作成、カスタム パッケージの開発、各種モデルのテストを行うことができます。データセット全体に対して分析を行う準備ができたら、自動スケーリングを有効にして、同じクラスタとノートブックの環境内で完全な分析を行うことができます。このクラスタはデータセット全体を処理するのに必要なサイズに拡大され、処理が完了すると自動的に元のサイズにスケールダウンします。大規模なサーバー環境に移動しようとしたり、作業を移行する方法を見つけ出そうとしたりして、無駄な時間を費やさなくて済みます。
Jupyter Notebook for Spark で大規模なデータセットを処理する際に、デフォルトで作成される Spark コンテキストを停止し、代わりにメモリ上限がより大きい構成を使用することもできます。
たとえば、次のコードを使用します。
#In Jupyter you have to stop the current context first
sc.stop()
#in this example, the driver program that runs is given access to all memory on the master
conf = (SparkConf().set(\"spark.driver.maxResultSize\", 0))
#restart the Spark context with your new configuration
sc = SparkContext(conf=conf)
自動スケーリングとノートブックによって、適切なサイズに変更されるクラスタ リソースを使用して共同作業環境で作業できる、優れた開発環境が実現します。開発環境から本番環境ジョブ用の自動プロセスに移行する準備ができたら、Dataproc Jobs API を使用してこの移行を簡単に行うことができます。
SparkR ジョブタイプのロギングとモニタリング
Dataproc Jobs API を使用すると、HTTP 経由で jobs.submit を呼び出して、既存の Cloud Dataproc クラスタにジョブを送信できるようになります。この操作は、gcloud コマンドライン ツールを使用するか、Google Cloud Platform Console で行います。SparkR ジョブタイプが一般提供となったことで、SparkR ジョブのロギングとモニタリングが可能になり、R コード関連の自動化ツールを簡単に作成できます。また、Jobs API を使用することで、クラスタ上でジョブを送信できる権限を持つユーザーと、クラスタ自体にアクセスできる権限を持つユーザーを分離できます。Jobs API によって、データ サイエンティストとアナリストはゲートウェイ ノードやネットワーク構成を設定しなくても、本番環境ジョブをスケジュール設定できます。
下の画像に示すように、Dataproc Jobs API と Cloud Scheduler の HTTP ターゲットを組み合わせて、運用パイプラインの再実行ジョブや ML モデルの再トレーニングなどのタスクを所定の間隔で自動的に行うことができます。その際には、Cloud Scheduler ジョブで使用される範囲とサービス アカウントが、必要なすべての Dataproc リソースに対して適切なアクセス権限を持っている必要があります。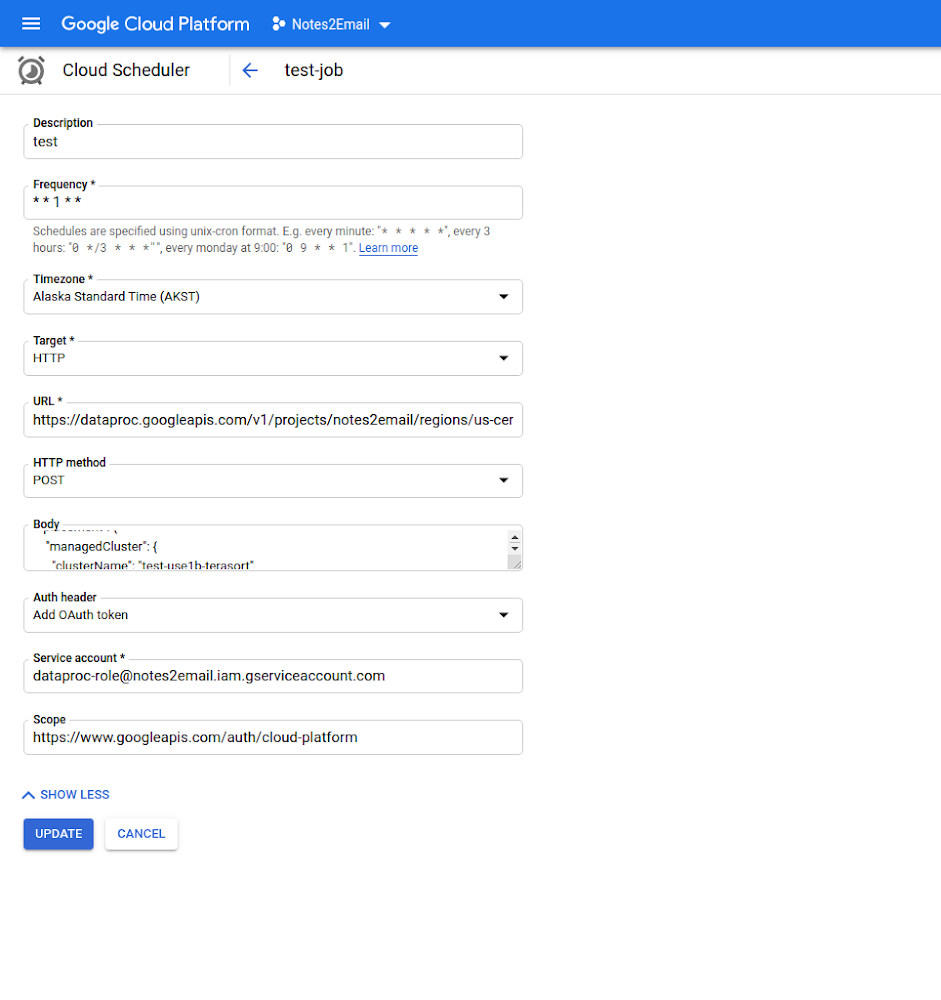
複数のステップでジョブを実行するタスクや、ジョブと同時にクラスタを作成するタスクなど、より高度なタスクについては、スケジューラから使用可能な別の HTTP ターゲットがワークフロー テンプレートによって提供されます。ワークフロー テンプレートと Dataproc ジョブに関しては、時間に基づいたスケジュール設定ツールとして Cloud Scheduler が最適です。Cloud Storage の新しいファイルや Pub/Sub のイベントに応答して Dataproc ジョブを実行する場合は、Cloud Functions が最適です。Dataproc 以外でデータ パイプラインをオーケストレートする必要があるジョブの場合は、スケジュール設定ツールとして Cloud Composer が適しています。
クラウドへの R の移行と、SparkR 向け Dataproc Jobs API の導入事例について詳しくは、SparkR に関するブログ投稿と Google Cloud Next ‘19 の Data Science at Scale with R on GCP の動画をご覧ください。
GPU のアクセラレータ サポート
多くの場合、Spark や他の Hadoop フレームワークは、GPU を使用するディープ ラーニング モデルに適したデータセットを作成するための前処理のステップです。これを考慮して、Dataproc は GPU をクラスタに追加する操作に対応するようになりました。これは、データ サイエンティストのために処理環境を統合する更なる機能で、アナリストは基盤となるクラスタ リソースを再構成する時間と労力を節約できます。単一のワークフロー テンプレートにおいて、Spark ML と GPU ベースのディープ ラーニング アルゴリズムを組み合わせて一致させる一連のジョブを自動化できます。
単一の GPU のメモリを超えてスケールする必要のあるデータセットについては、RAPIDS on Dataproc がフレームワークとなります。このフレームワークでは、GPU と Dataproc の両方の機能を使用して、API 呼び出しによって VM のクラスタの起動と制御を行います。RAPIDS on Dataproc の使用を開始するには、RAPIDS の初期化アクションと、それに関連するニューヨークのタクシーデータに基づいたサンプル ノートブックをご覧ください。
クラスタのスケジュール設定された削除
膨大なデータセットから必要な情報を取得するモデルを作成したり、その SQL クエリを微調整したりする作業に丸一日かかってしまうことがよくあります。そして金曜日に退社する前に [実行] をクリックして長期実行ジョブを開始し、月曜日に出社して結果を確認するような場合があります。オートスケーラーを使用してより多くのコンピューティング リソースを活用するのも、答えをすばやく得る方法の一つですが、クエリとジョブが無人で長時間実行されることも必然的にあります。
このような無人のジョブに余分な課金が発生しないようにするには、クラスタのスケジュール設定された削除機能を使用して、Dataproc Jobs API でジョブを送信する際は指定したアイドル時間の経過後にクラスタが自動削除されるようにします。これにより、金曜日に退社した後、実行している Dataproc クラスタの課金を停止するためにいつクラスタを削除できるかを確認し続けなくて済みます。クラスタのスケジュール設定された削除機能では、時間ベースの削除でさらに 2 つのオプションを使用できます。これらのオプションを使用すると、一日不在にするときにクラスタを削除し忘れてしまった場合や、うっかりクラスタを実行したままにした場合に、Dataproc クラスタの課金を停止できます。
- By Chris Crosbie



