BigQuery で無制限のワークロードを構築: SQL 以外の言語を使用した新機能

Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud の使命は、データドリブンへの変革を推進するお客様を支援することです。その実現に向けたステップとして、BigQuery では SQL 専用のインターフェースという制限をなくし、SQL 以外の言語でのプログラミングが必要なワークロード用の新しいデベロッパー拡張機能を提供しています。これらの柔軟なプログラミングの拡張機能はすべて、稼働している仮想サーバーの制限を受けることなく提供されます。
先日開催された Next 22 カンファレンスの基調講演で Apache Spark 用ストアド プロシージャのプレビュー版を発表しました。これにより、BigQuery の完全なサーバーレス環境にスケーラブルな分散型の機械学習と ELT ジョブを直接組み込めます。また、Google のサーバーレス ノートブック サービスである Colab を BigQuery のコンソールに統合することで、SQL クエリ結果から Python 分析へのシームレスな移動が可能になったことも発表しました。さらに、リモート関数の一般提供が開始されたことで、Cloud Functions または Cloud Run で記述されたカスタム関数を使用して BigQuery の SQL ライブラリの拡張が可能になりました。

「多言語での記述に向けた BigQuery における取り組みに期待しています。これにより、SQL と Python のデータ モデリングを同じワークフローで行い、実務担当者が特定のタスクに適したツールを選択できるようになります。先日当社は、同様の理由で dbt に Python サポートを導入しました。こうした新機能により BigQuery における dbt のデータ変換ワークフローをシームレスにサポートできることを嬉しく思います。」 - dbt Labs プロダクト マネージャー Jeremy Cohen 氏
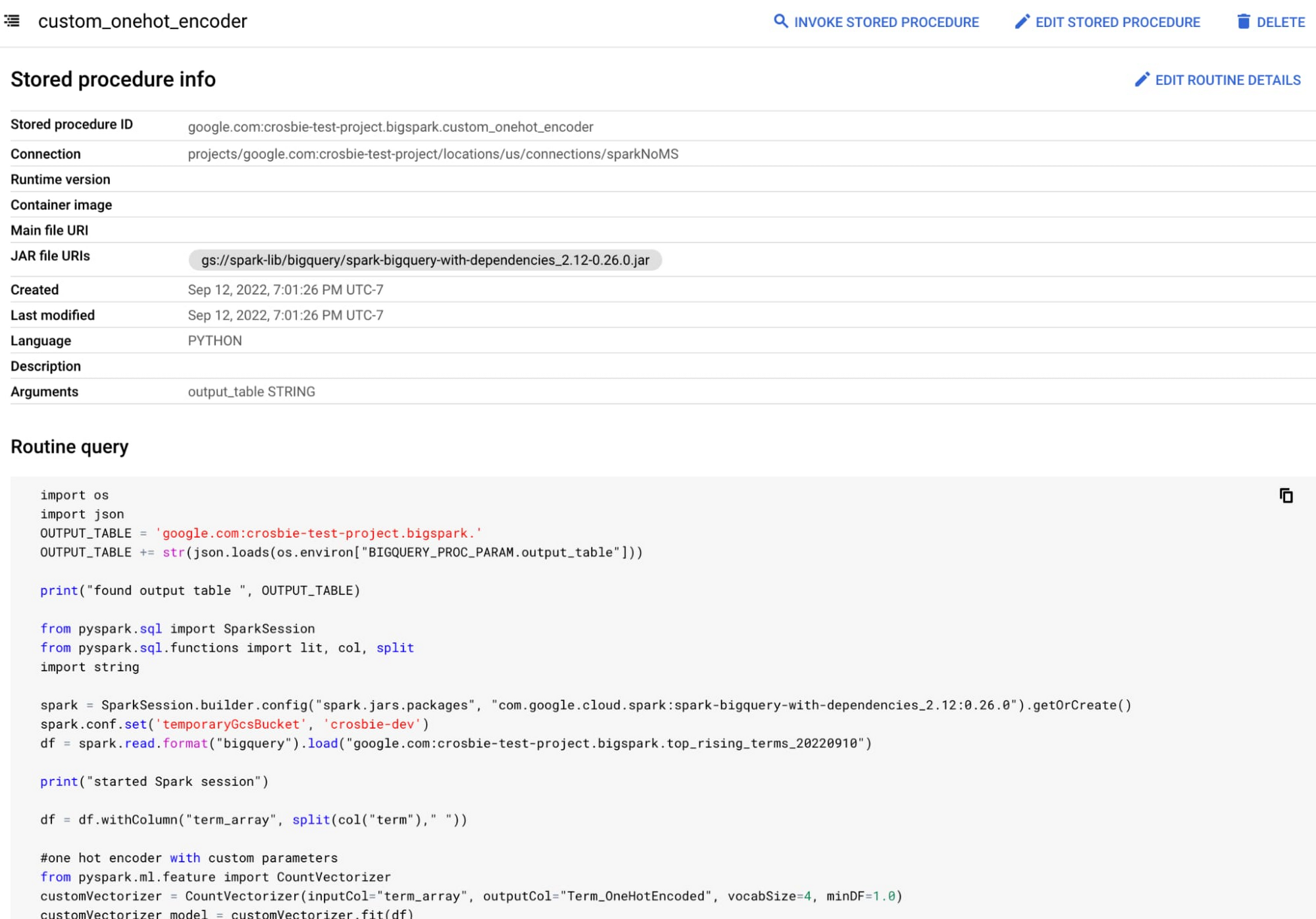
Apache Spark 用 BigQuery ストアド プロシージャのプレビュー版を提供
これまで、データ ウェアハウスとデータレイクの両方におけるデータ管理には困難が伴っていました。今年初めに Google は、Google Cloud Storage にオープン ファイル形式(Parquet など)でデータを保存し、GCP とオープンソース エンジンを安全で管理された、パフォーマンスに優れた方法で実行するストレージ エンジンである BigLake を発表しました。本日、BigQuery は、新たな章を迎えます。Apache Spark エンジンを BigQuery に直接組み込むことで、データ ウェアハウスとデータレイクの処理を統合します。
Apache Spark 用 BigQuery ストアド プロシージャを使用することで、BigQuery から Apache Spark プログラムを実行し、高度な変換と取り込みパイプラインを BigQuery の処理として統合します。ストアド プロシージャでは、Apache Spark を一連の SQL ステートメントのステップとしてスケジュール設定し、非構造化データレイク オブジェクトと構造化 SQL クエリを組み合わせてマッチングします。また、プロシージャを他のユーザーに引き継ぐことで、そのユーザーが SQL から直接 Apache Spark ジョブを実行することもできます。そのため、基盤となる Apache Spark コードの知識がなくても、モデルの再トレーニングや複雑なデータ構造の取り込みが可能です。
こうした Apache Spark ジョブの実行コストは、ジョブの所要時間と消費されたリソースに対してのみ発生します。実行コストは BigQuery で処理されたバイト数または BigQuery スロットのいずれかに変換され、データレイクとデータ ウェアハウスの両方のジョブに対して単一の課金単位が指定されます。
BigQuery コンソールと統合された Google Colab のプレビュー版を提供
Colab は、Python ベースの分析によって BigQuery SQL を拡張する、ノートブック ベースの快適なプログラミングを実現するものとして、長年にわたり BigQuery のお客様に利用されてきました。Google は、データ ワークフローを改善するために BigQuery SQL と Colab ノートブック間の移動を簡素化して欲しいというお客様からのご要望を受け、これを実現しました。プレビュー版では、以下の画像のように、SQL クエリの結果からノートブックにすぐに移動して、Python で詳細な分析を行うことができるようになりました。これにより、記述統計の実行、可視化の生成、予測分析の作成、さらには結果の共有に素早く移動できます。
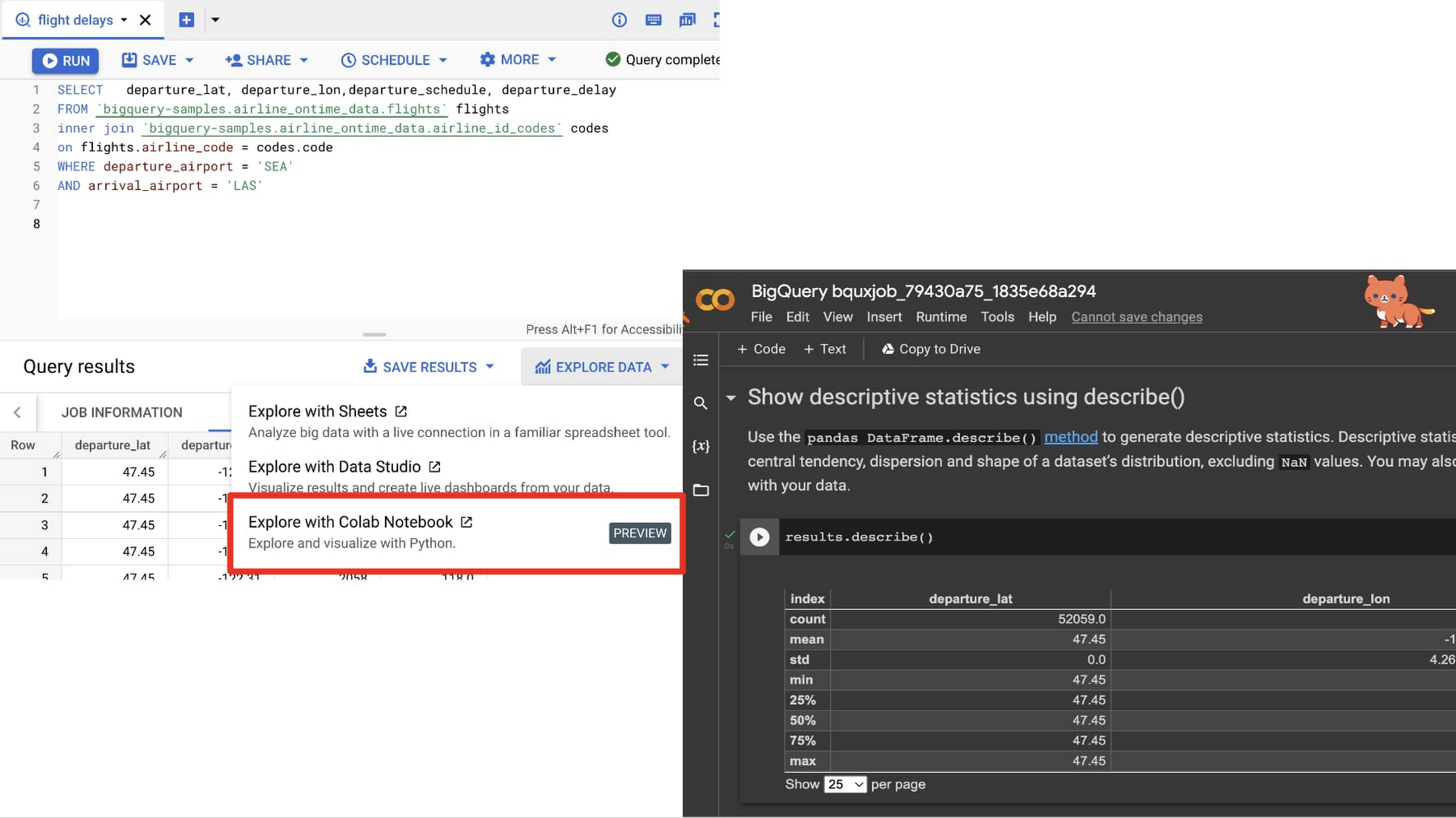
Colaboratory(略称 Colab)は、Google Research が提供するプロダクトです。Colab を活用することで、任意の Python コードを記述、実行できます。特に機械学習、データ分析、教育などの分野に適しています。具体的には、Colab はホスト型の Jupyter Notebook サービスで、GPU などの限られた量のコンピューティング リソースへのアクセスを無料で提供しています。このサービスを利用するための設定は必要ありません。
現在、この統合機能はコンソールから利用可能です。
リモート関数の一般提供を開始
Google は、既存のセキュリティ プラットフォームで BigQuery を活用したい医療機関、リアルタイムの株価情報を投入して BigQuery のデータを強化したい金融機関、BQML と Vertex AI を併用したいデータ サイエンティストからのご要望をいただいていました。このようなお客様が BigQuery を他のコンポーネントに拡張できるように、BigQuery リモート関数の一般提供を開始しました。
Protegrity と CyberRes は、BigQuery を自社のセキュリティ プラットフォームに統合する仕組みとして、こうしたリモート関数との統合機能をすでに開発していて、共通のお客様が厳格なコンプライアンス管理に対応できるよう支援しています。
リモート関数は、カスタムコードで BigQuery SQL を拡張できるユーザー定義関数(UDF)で、Cloud Functions または Cloud Run のいずれかで記述、管理されます。リモート UDF は、BigQuery の列を入力として受け付け、カスタムコードを使用してその入力に対するアクションを実行し、アクションの結果をクエリ結果の値として返します。Cloud Run に基づくリモート関数を使用して作成できる SQL 関数は、まさに無限です。SQL を記述するユーザーなら誰でも使用できる BigQuery SQL 関数を完全に制御し、柔軟に記述できます。さらに、Google Cloud がサポートするサーバーレスの従量課金制のインフラストラクチャにより、任意の言語、ライブラリ、バイナリを呼び出すことができます。
BigQuery Utils の GitHub リポジトリ(リモート関数のサンプルで拡張された便利な BigQuery ユーティリティの公開リスト)の関数を使用して新機能をぜひご利用ください。
- データ分析担当プロダクト マネージャー Christopher Crosbie
- データ分析担当プロダクト マネージャー Joe Malone



