BigQuery 特集: 結合データ、繰り返しおよびネストされたデータの処理
Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery 特集シリーズの前回の投稿では、SQL を使用した BigQuery のデータセットのクエリ、クエリの保存と共有の方法、標準ビューとマテリアライズド ビューの管理の概要について説明しました。本投稿では、結合、およびネストされたフィールドと繰り返しフィールドを使用したデータの非正規化に焦点を当てます。詳しく見ていきましょう。
結合
一般的に、データ ウェアハウス スキーマは、スタースキーマまたはスノーフレーク スキーマに従います。イベントを有する一元化された「ファクト」テーブルには、ファクト テーブルに関連する説明的属性を有する「ディメンション」と称されるサテライト テーブルが付属しています。ファクト テーブルは非正規化され、ディメンション テーブルは正規化されています。スタースキーマは、データ ウェアハウスで分析クエリをサポートしているため、結合数の限定によるシンプルなクエリの実行、より速い集約の実施、クエリのパフォーマンスの向上が可能です。
スキーマが高度に正規化され、結合を後半に実施して結果を得るオンライン トランザクション処理システム(OLTP)とは対照的です。データ ウェアハウスでのほとんどの分析クエリでは、ファクトデータをディメンション属性やその他のファクト テーブルと結合するために、依然として JOIN オペレーションを実施する必要があります。
BigQuery での結合の仕組みを見てみましょう。BigQuery は、ANSI SQL 結合タイプをサポートしています。JOIN オペレーションは、結合条件と結合タイプに基き、2 つのアイテムに対して実施されます。JOIN オペレーションのアイテムは、BigQuery テーブル、サブクエリ、WITH ステートメント、ARRAY(同じデータ型の 0 以上の値を有する順序付きリスト)のいずれかにすることができます。
BigQuery は、次の結合タイプをサポートします。
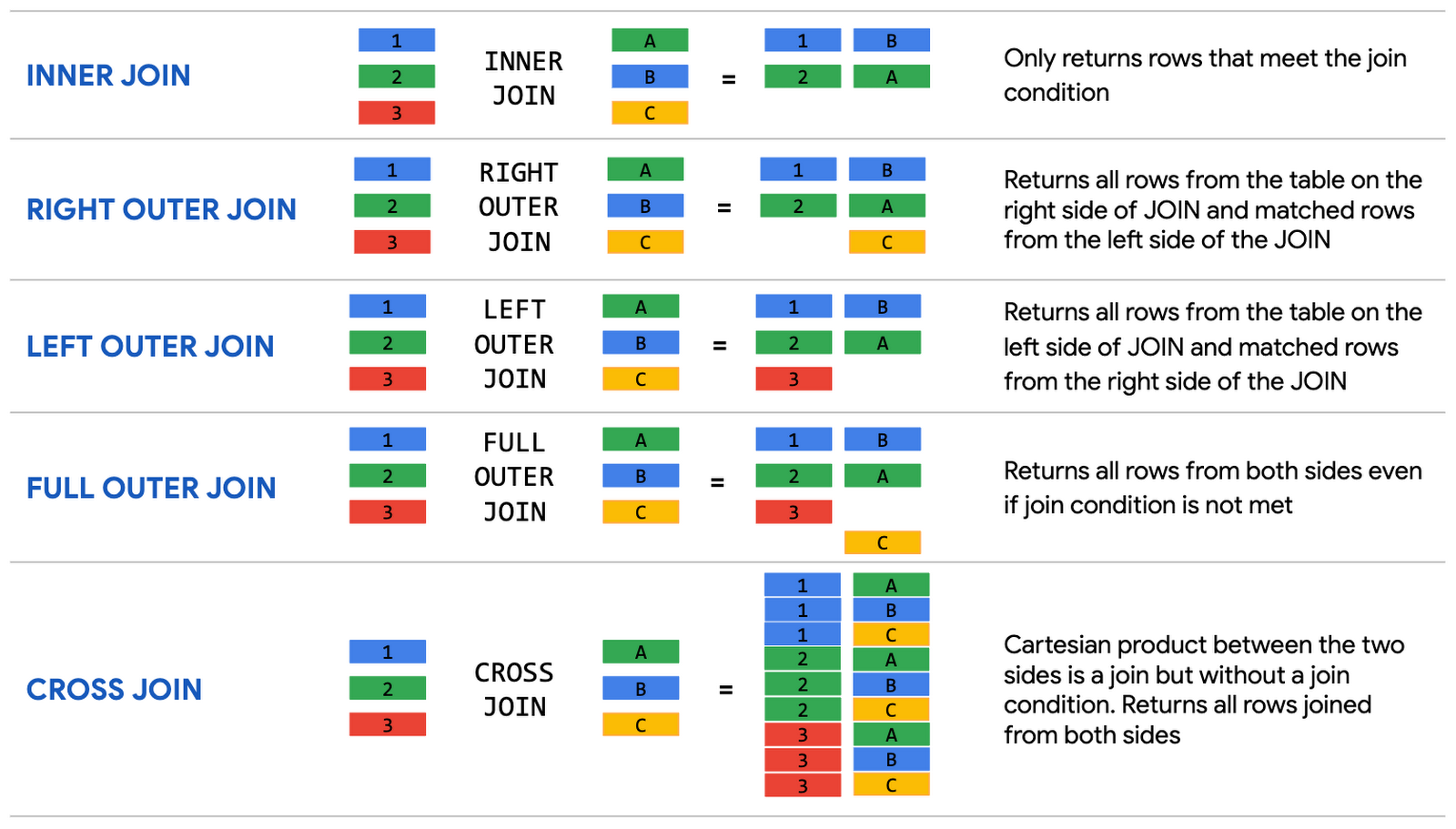
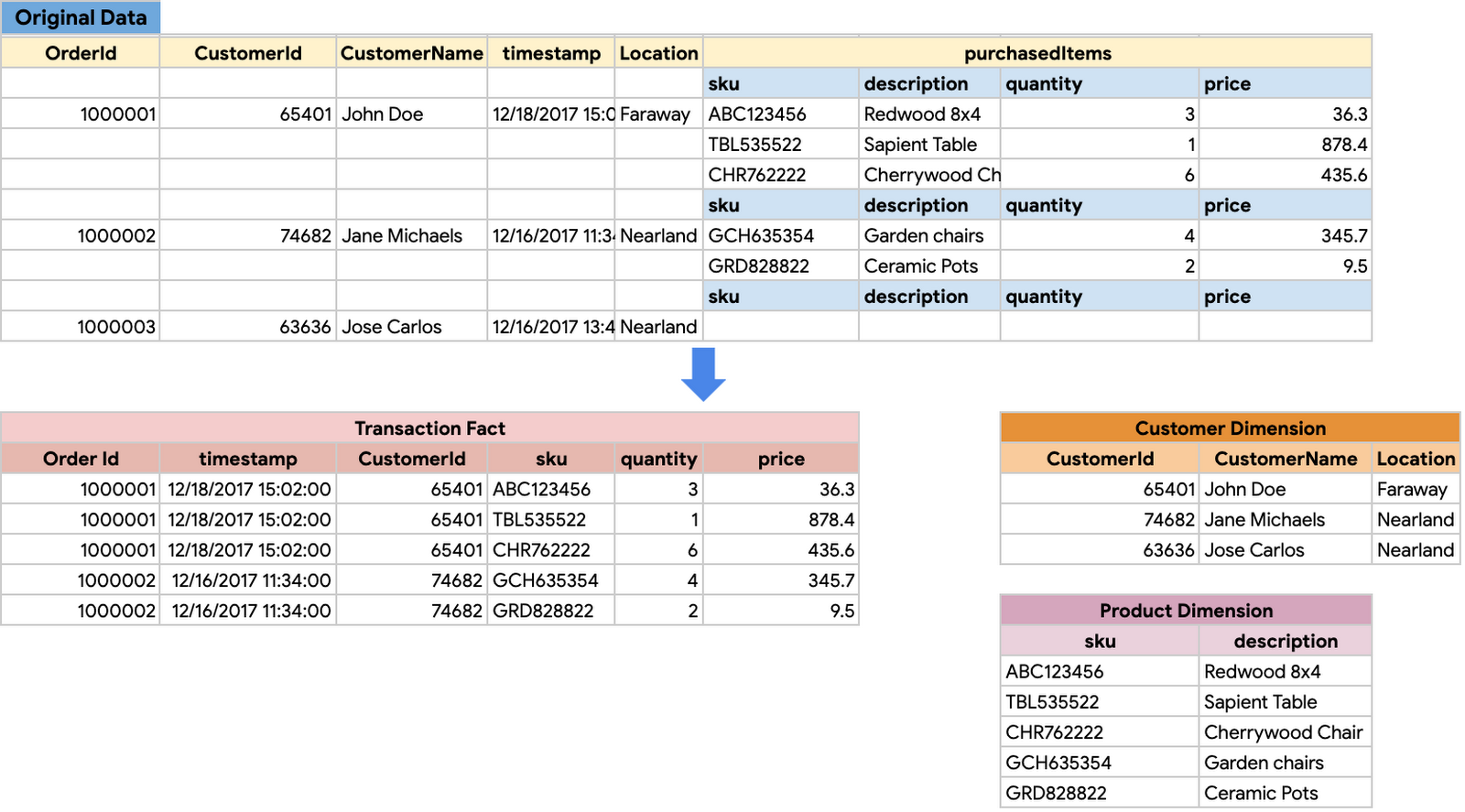
下記の小売店向けのデータ ウェアハウス スキーマの例を見てみましょう。一番上の小売トランザクションに関する元のデータテーブルは、トランザクション ファクト テーブル、およびディメンション テーブルとしての商品と顧客情報に保存された注文の詳細を有するデータ ウェアハウス スキーマに変換されます。
特定の月の各顧客の支払い額を確認するには、トランザクション ファクト テーブルと顧客ディメンション テーブルに対して OUTER JOIN を実施し、結果を入手します。WITH 句を使用して、サンプルのトランザクションと顧客データを即座に生成し、JOIN の動作を確認します。次のクエリを実行します。
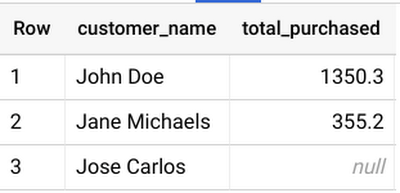
注: WITH 句は実体化されないため、主に可読性のために使用するようにします。1 つのクエリが複数の WITH 句に含まれている場合、そのクエリは各句でそれぞれ実行されます。

結合パターンの最適化
ブロードキャスト結合
大きいテーブルを小さいテーブルに結合する場合、BigQuery はブロードキャスト結合を作成します。小さいテーブルは大きいテーブルを処理する各スロットに送信されます。
SQL クエリ オプティマイザーを使用すれば結合のどちら側にどのテーブルを配置するかが自動的に判断されますが、結合後のテーブルは適切に並べ替えることをおすすめします。ベスト プラクティスは、最初に最大のテーブルを配置し、その後ろに最小のテーブルを配置することです。その後は、サイズの大きい順にテーブルを配置します。
ハッシュ結合
2 つの大きいテーブルを結合する場合、BigQuery は、ハッシュ オペレーションとシャッフル オペレーションを使用して左右のテーブルをシャッフルし、一致するキーを同じスロットに配置してから、ローカルで結合を行います。データの移動が必要なため、これは負荷の高いオペレーションです。
クラスタリングによってハッシュ結合が高速化される場合があります。以前の投稿で述べたように、特にクエリ実行プランの事前集約部分がある場合、クラスタリングでは同じカラム型のファイル内にデータが配置される傾向があり、データ シャッフルの全体的な効率が改善されます。
自己結合
自己結合において、テーブルはそれ自体と結合されます。これは一般的に SQL アンチパターンで、大きなテーブルには負荷の高いオペレーションとなり、1 つ以上のパスでデータを取得することが必要となる場合があります。
そこで、自己結合を回避して、分析(ウィンドウ)関数を使用して、クエリにより生成されるバイト数を削減することをおすすめします。
クロス結合
クロス結合は SQL アンチパターンで、入力データよりも大きい出力データを生成し、クエリが終了しないこともあるため、重大なパフォーマンスの問題を引き起こす可能性があります。
クロス結合のパフォーマンスの問題を回避するには、集計関数を使用してデータを再集約するか、通常クロス結合よりパフォーマンスの高い分析関数を使用します。
スキュー結合
データスキューは、テーブル内のデータがさまざまなサイズのパーティションに分割されている場合に発生する可能性があります。データのシャッフルを必要とする大きなテーブルを結合する場合は、スキューにより、スロット間で送信されるデータ量に極端な不均衡が生じる場合があります。
スキュー結合(または不均衡な結合)に関連するパフォーマンスの問題を回避するには、事前にできるだけ早くテーブルからデータをフィルタし、クエリを 2 つ以上のクエリに分割します。
クエリ パフォーマンスの最適化案をさらに確認するには、BigQuery ベスト プラクティス ドキュメントを参照してください。
ネスト構造と繰り返し構造を使ったデータの非正規化
データ ウェアハウスでスタースキーマやスノーフレーク スキーマなどの部分的に正規化されたスキーマに分析オペレーションを実施する場合、複数のテーブルを結合して必要な集約を行う必要があります。ただし、通常 JOIN は非正規化された構造ほどパフォーマンスが高くありません。JOIN を使用したことで、クエリのパフォーマンスが急激に悪化しています。
データを非正規化する従来の方法では、ファクトをそのすべてのディメンションとともに、フラット化した構造に書き込みます。対照的に、データを非正規化する望ましい方法は、JSON または Avro 入力データのネスト構造と繰り返し構造に対する BigQuery のネイティブ サポートを利用することです。ネスト構造と繰り返し構造を使用してレコードを書き込むと、基盤データをより自然に表現できます。
小売店向けに同じデータ ウェアハウス スキーマを続行する際、留意すべき主な点は次のとおりです。
トランザクションの 1 つの注文は、1 人の顧客に属する。
トランザクションの 1 つの注文には、複数の商品(またはアイテム)が含まれる場合がある。
前述のとおり、このスキーマは複数のテーブルに編成されています。これを変更してネストされたフィールドと繰り返しフィールドを使用し、すべての情報を 1 つのテーブルにまとめます。
ネストされたフィールドと繰り返しフィールドについて
BigQuery では、JSON ファイル、Avro ファイル、Firestore エクスポート ファイル、Datastore エクスポート ファイルなど、オブジェクトベースのスキーマをサポートするソース形式からネストされた繰り返しデータを読み込むことができます。ARRAY と STRUCT または RECORD は、ネストされたフィールドと繰り返しフィールドを表現する複雑なデータ型です。
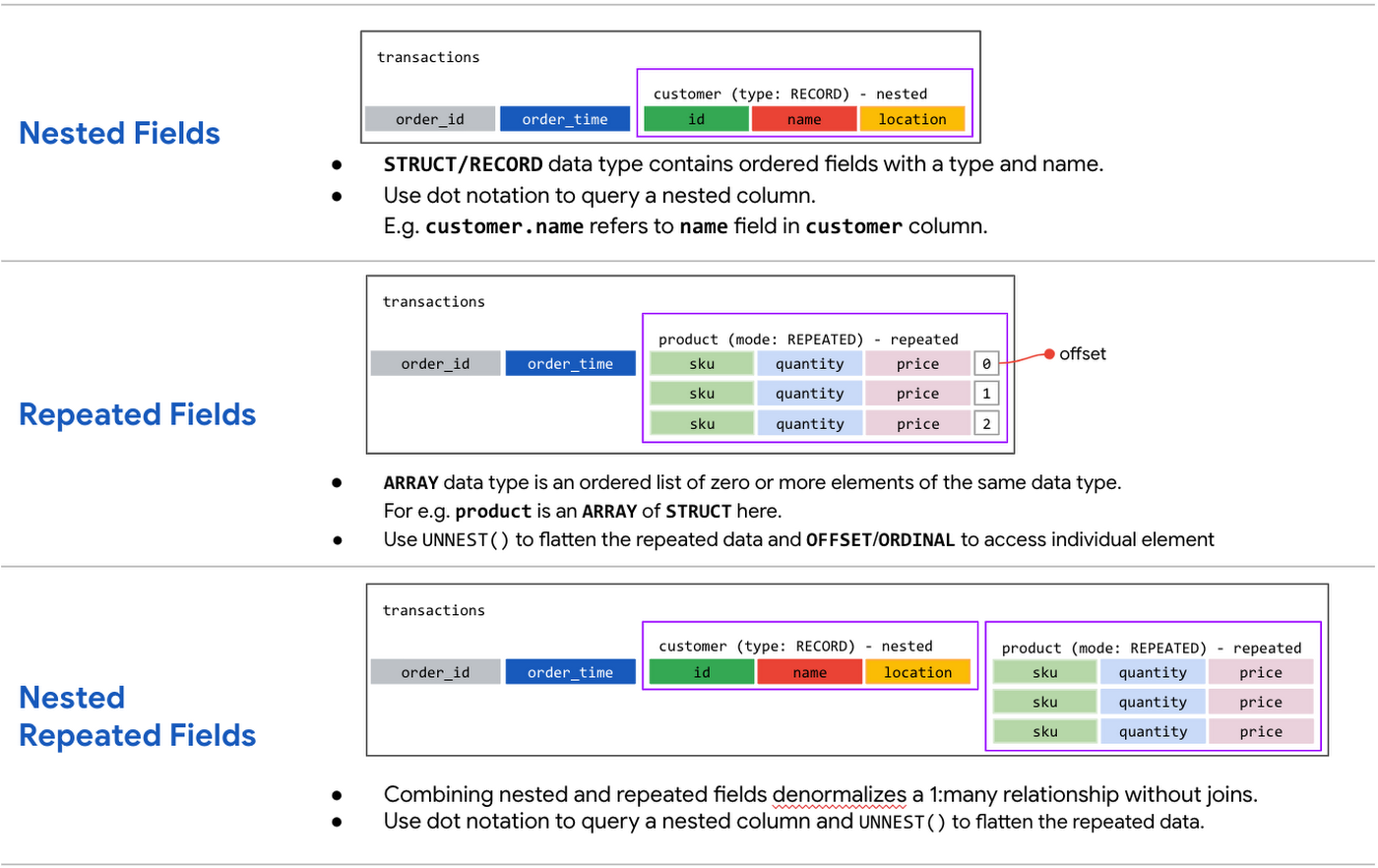
ネストされたフィールド
STRUCT または RECORD は、データ型とフィールド名が記載された順序付きフィールドを含みます。1 つ以上の子列を、ネストされた STRUCT(最大 15 レベルのネスト)と呼ばれる STRUCT 型として定義できます。
ネストされた構造に置かれたトランザクションと顧客データの例を見てみましょう。トランザクションの注文は、1 人の顧客に属することに注意してください。これは次のスキーマとして表現できます。
顧客列は、メインスキーマ内にネストされた順序付きフィールドとトランザクション フィールド(id と time)を有する RECORD 型です。
BigQuery は、クエリの実行時にネストされたフィールドを自動的にフラット化します。ネストされたデータを含む列にクエリを実行するには、各フィールドを、フィールドが含まれる列のコンテキスト内で識別する必要があります。たとえば、customer.id とは、customer 列の id フィールドを指します。

繰り返しフィールド
ARRAY は、同じデータ型の 0 以上の要素に順序を付けて並べたリストです。配列の配列はサポートされていません。繰り返しフィールドは、単一のフィールドまたは RECORD 内のデータの配列を追加します。
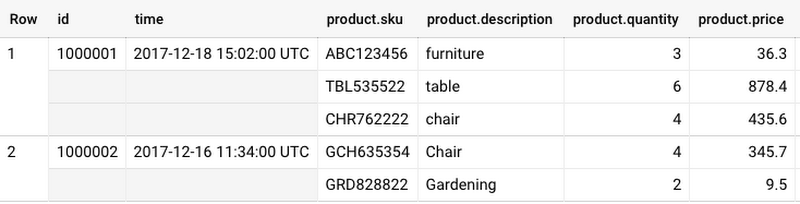
トランザクションと商品データを考えてみましょう。トランザクションの 1 つの注文には、複数の商品(またはアイテム)が含まれる場合があります。スキーマの繰り返しフィールドとして商品列を指定する場合、商品列のモードを REPEATED として定義します。繰り返しフィールドがあるスキーマを以下に示します。
繰り返しフィールドの各エントリは、ARRAY です。たとえば、1 つの注文の商品列の各アイテムは STRUCT 型または RECORD 型で、SKU、説明、数量、価格というフィールドがあります。
BigQuery は、1 つ以上の繰り返しフィールドにクエリを実行する際、自動的に「行」でデータをグループ化します。
ARRAY と STRUCT の処理方法について詳しくはこちらをご覧ください。
ネストされた繰り返しフィールドを使って非正規化されたスキーマ
ここまでのすべてをまとめて、顧客情報と商品情報を 1 つのテーブルにし、ネストされた要素と繰り返し要素を組み合わせたトランザクション スキーマの代替表現を確認しておきましょう。スキーマは次のように表現されます。

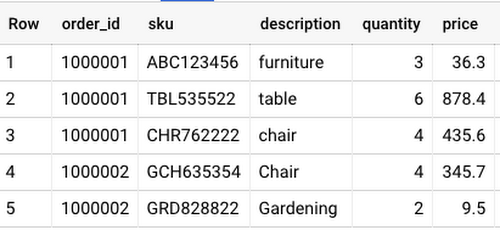
トランザクション テーブルでは、ネストされた要素と繰り返し要素として、外側に注文情報と顧客情報、内側に注文という項目が含まれています。ネストされたフィールドと繰り返しフィールドを使用してレコードを表現すると、JSON ファイルまたは Avro ファイルを使用したデータ読み込みが簡素化されます。このようなスキーマを作成した後、Order.sku などのドット表記を使用して、個別のフィールドで SELECT、INSERT、UPDATE、DELETE の処理を実行できます。
トランザクション データを再度即座に生成し、ネストされた繰り返しフィールドを使ってトランザクション スキーマにクエリを実行して、注文の総数と顧客名を検索します。
このクエリを展開して、データの非正規化方法を理解しましょう。
非正規化データ表現
トランザクション データは、WITH ステートメントを使用して生成され、それぞれの行は、注文情報、顧客情報、SKU、、価格を表す STRUCT の ARRAY として表現される個別のアイテムを含むネストされたフィールドから構成されます。
STRUCT の ARRAY を使用して、JOIN テーブルを回避することで、パフォーマンスをかなり向上できます。STRUCT の ARRAY は、データの構造を保持する事前結合されたテーブルとして扱うことができます。ネストされたレコード内の個別の要素は、必要な場合にのみ取得できます。JOIN キーと関連するテーブルを管理するのではなく、1 つのテーブルにすべてのビジネスの状況を保持できるという利点もあります。
分析のためのデータの正規化
SELECT クエリにおいて、UNNEST() 関数とドット表記を使用するネストされたレコードから価格などのフィールドを読み込みます。例: orders.price
UNNEST() で、配列の要素を行に戻すことができます
UNNEST() は常に、FROM 句内のテーブル名に従います(事前に結合されたテーブルと似たコンセプト)
上記のクエリを実行すると、注文、顧客、合計注文金額の結果が返されます。

非正規化スキーマの設計のガイドライン
BigQuery で非正規化スキーマを設計する際の一般的ガイドラインを次に示します。
UPDATE や DELETE オペレーションなどのデータ操作のコストがクエリ最適化のメリットを上回っているという確かな根拠がある場合を除き、10 GB を超えるディメンション テーブルは非正規化する。
テーブルで UPDATE オペレーションと DELETE オペレーションがほとんど行われない場合を除き、10 GB 未満のディメンション テーブルは正規化されたままにする。
非正規化されたテーブルでは、ネストされたフィールドや繰り返しフィールドを活用する。
データ ウェアハウスにおけるスキーマの非正規化と設計について詳しくは、こちらの記事をご覧ください。
次のステップ
この投稿では、結合を使用した結合パターンの最適化について説明し、ネストされたフィールドと繰り返しフィールドでデータを非正規化しました。
BigQuery での JOIN を使用した作業
BigQuery での分析(ウィンドウ)関数を使用した作業
結合など、BigQuery のクエリ パフォーマンスのためのベスト プラクティス
BigQuery サンドボックスで、ネストされたフィールドと繰り返しフィールドを使用した BigQuery での一般公開データセットのクエリ - デモを行った Evan Jones に感謝します(Codelab は近日提供予定)
次回の投稿では、BigQuery におけるデータ操作や、スクリプト、ストアド プロシージャなどについて解説します。
今後の情報にご注目ください。ご精読ありがとうございました。質問がある場合やチャットをご希望の場合は、Twitter または LinkedIn でアクセスしてください。
本投稿に協力してくれた Alicia Williams に感謝します。
-Cloud カスタマー エンジニア、機械学習スペシャリスト Rajesh Thallam

