Cloud Functions で、BigQuery から Earth Engine への自動データパイプラインを構築する
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
これまで長年にわたり、粒度の高い膨大な量の衛星データが毎日収集されてきました。最近まで、これらのデータは商業目的では手つかずの資産でした。これは、この種のデータの大規模な分析に必要なツールや、衛星画像そのものが簡単に手に入らなかったことが主な原因です。しかし、地球科学のデータと分析のための地球規模のプラットフォームである Earth Engine のおかげで、もはやそのようなことはなくなりました。
先日、Google Cloud Platform (GCP) 製品として発表され、一般提供が開始されたこのプラットフォームにより、さまざまな業界の商用ユーザーが、センサーデータの運用をリモートで行えるようになりました。Earth Engine のユースケースとしては、サステナブルな調達、気候変動リスクの検出、サステナブルな農業、天然資源管理などがすでに検討されています。このようなユースケースに対し、Earth Engine で空間にフォーカスしたソリューションを開発したことで、業務改善のための明確な分析情報を取得できるようになっています。これらのソリューションを自動化することで、今まで以上に迅速に分析情報を得られるようになるため、手間のかかる作業が減り、エラーの発生を抑制できるようになります。
この投稿で取り上げる自動データ パイプラインでは、日用消費財を取り扱う架空の Cymbal 社のサステナブルな調達のユースケースを想定し、BigQuery から Earth Engine にデータを取り込みます。このユースケースには、2 種類のデータが必要です。1 つ目は Cymbal がすでに持っているデータ、2 つ目は Earth Engine と Data Catalog から提供されるデータです。この例では、Cymbal が所有するデータが BigQuery から、データ パイプラインを経由して自動処理で Earth Engine に流れ込んでいます。
これらのデータを組み合わせは、ケーキを作るときのようにレイヤを重ねると考えるとわかりやすくなります。ここでは、レイヤについて詳しく説明します。ベースレイヤは、Earth Engine が提供する衛星画像(ラスターデータ)です。2 番目のレイヤは、Cymbal が提供したパーム農園の位置で、下の画像では黒く囲まれています。最後の 3 番目のレイヤは、データカタログに掲載されている樹木被覆データで、下のピンク色の部分になります。ケーキの層のように、これらのデータレイヤが集まって最終的な製品ができあがります。このアーキテクチャの目的は、データレイヤの集約を自動化することです。
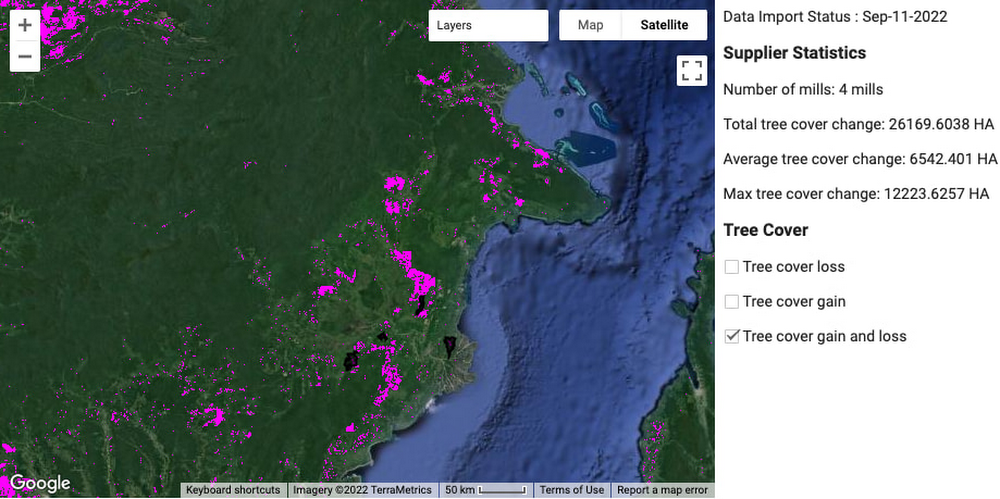
また、このアーキテクチャを適用できるユースケースの例としては、メタン排出の検出があります。この場合、1 番目のレイヤは変わりません。2 番目のレイヤは、企業などの組織が提供した施設の位置情報(施設の名称や種類など)になります。3 番目のレイヤは、データカタログのメタン排出量データになります。メタンガスの検出やサステナブルなサプライチェーンと同様に、ほとんどのユースケースには、企業などの組織が収集したなんらかの表形式データが含まれます。データは表形式なので、BigQuery が起点となります。表形式データとラスターデータ、BigQuery と Earth Engine の使い分けや使うタイミングについては、この投稿をご覧ください。
Earth Engine と BigQuery を自動パイプラインで併用することの潜在的な価値をご理解いただけたら、ここからはアーキテクチャそのものについて見ていきましょう。次のセクションでは Cloud Functions を使い、分析を実行する目的で、BigQuery などの GCP 製品から Earth Engine にデータを流す処理を自動化する方法について説明します。Earth Engine から BigQuery にデータを移行する方法については、こちらの投稿で紹介しています。
アーキテクチャ内の各ステップ
Cymbal は、主にインドネシアにあるパーム油のサプライ チェーンをより明確に把握することを目標としています。具体的な目標は、森林破壊の可能性がある地域を特定することです。このセクションでは、Cymbal 社がすでに持っているパーム農園の位置情報を Earth Engine に取り込み、その地域を衛星画像上にマッピングすることで、現地の情報を Cymbal に提供する方法を説明しています。ここでは、そのアーキテクチャについて順を追って説明します。すべてのピースがどのように組み合わされているかを理解しましょう。このアーキテクチャのコードを確認したい場合は、こちらをご覧ください。
アーキテクチャ
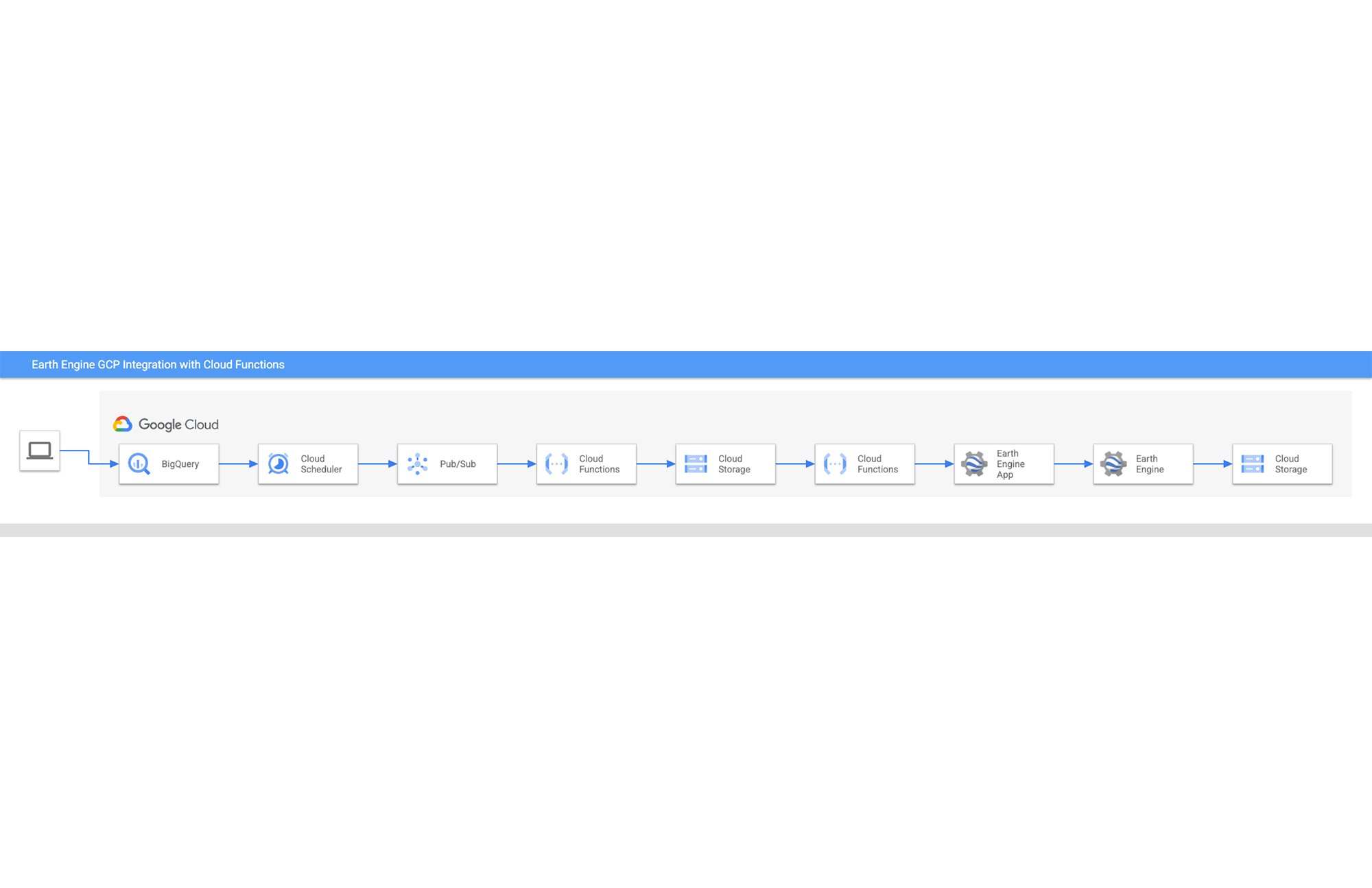
段階的なチュートリアル
1. 地理空間データを BigQuery にインポートする
Cymbal の地理空間データ サイエンティストは、パーム農園の位置データを管理し、それがどのように BigQuery に到着するかを把握します。
2. Cloud Scheduler のタスクが Pub/Sub トピックにメッセージを送信する
Cloud Scheduler のタスクは、パイプラインの動作を開始します。Cloud Scheduler のタスクは cron タスクであり、ワークフローに合った頻度でスケジュールできます。タスクが実行されると、Pub/Sub トピックにメッセージが送信されます。
3. Pub/Sub トピックがメッセージを受信し、Cloud Functions の関数をトリガーする
4. 最初の Cloud Functions の関数が BigQuery から Cloud Storage にデータを転送する
データを Cloud Storage に移動して、Earth Engine のアセットを作成できるようにする必要があります。
5. データが Cloud Storage バケットに到着し、Cloud Functions の 2 つ目の関数をトリガーする
6. Cloud Functions の 2 つ目の関数が、Earth Engine API を呼び出して Earth Engine にアセットを作成する
Cloud Functions の関数は、Earth Engine の認証から開始します。次に、Cloud Storage にある地理空間データから Earth Engine のアセットを作成する API 呼び出しを実施します。
7. Earth Engine アプリ(EE アプリ)は、Earth Engine でアセットが作成されると更新される
この EE アプリは、主に影響が大きい指標に関心のある Cymbal の意思決定者向けです。このアプリケーションは、ユーザーがコードに煩わされることなく指標や映像を確認できるダッシュボードです。
8. 高度な分析のためのスクリプトが EE アプリからアクセス可能になる
Earth Engine のコードエディタで高度に分析できる環境が構築され、Cymbal の技術ユーザー向けに EE アプリで提供されます。この環境は、森林破壊の可能性がある地域について意思決定者が感じた疑問を深く掘り下げる場を、技術ユーザーに提供するものです。
9. Earth Engine での分析結果を Cloud Storage にエクスポートする
テクニカル ユーザーは、高度な分析環境でのさらなる分析が終了すると、タスクを実行し、その結果を Cloud Storage にエクスポートできます。そこから先は、適宜様子を見ながらワークフローを進めることができます。
この 9 つの手順により、自動化されたワークフローが実現し、パーム油のサプライ チェーンを可視化するソリューションが Cymbal に提供されます。このソリューションは、企業全体の目標に対応しつつ、Cymbal のさまざまなタイプのユーザーのニーズを満たすものです。
まとめ
Cloud Functions を利用した、BigQuery から Earth Engine への自動データ パイプラインのアーキテクチャについて説明しました。このアーキテクチャと、すべてのピースがどのように組み合わされているかについての理解を深めるには、ご自分の環境でアーキテクチャを構築してみることをおすすめします。Terraform のスクリプトは GitHub で公開されているため、アーキテクチャを簡単に構築できます。アーキテクチャを構築したら、パイプラインのさまざまな要素を入れ替えて、ご自分の業務にとって適切なものにしましょう。興味のある方や他の事例をご覧になりたい方はこの投稿を読んで、Earth Engine から BigQuery へのデータの取り込み方法をご確認ください。この投稿では、GEE カタログ内の Landsat 衛星画像から気温と樹木のデータを BigQuery の SQL で取得する、Cloud Functions の関数の作成方法について説明しています。最後までお読みいただきありがとうございました。
- クラウド ジオグラファー Grace Coleman
