Earth Engine からの衛星画像を BigQuery の表形式データに変換
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
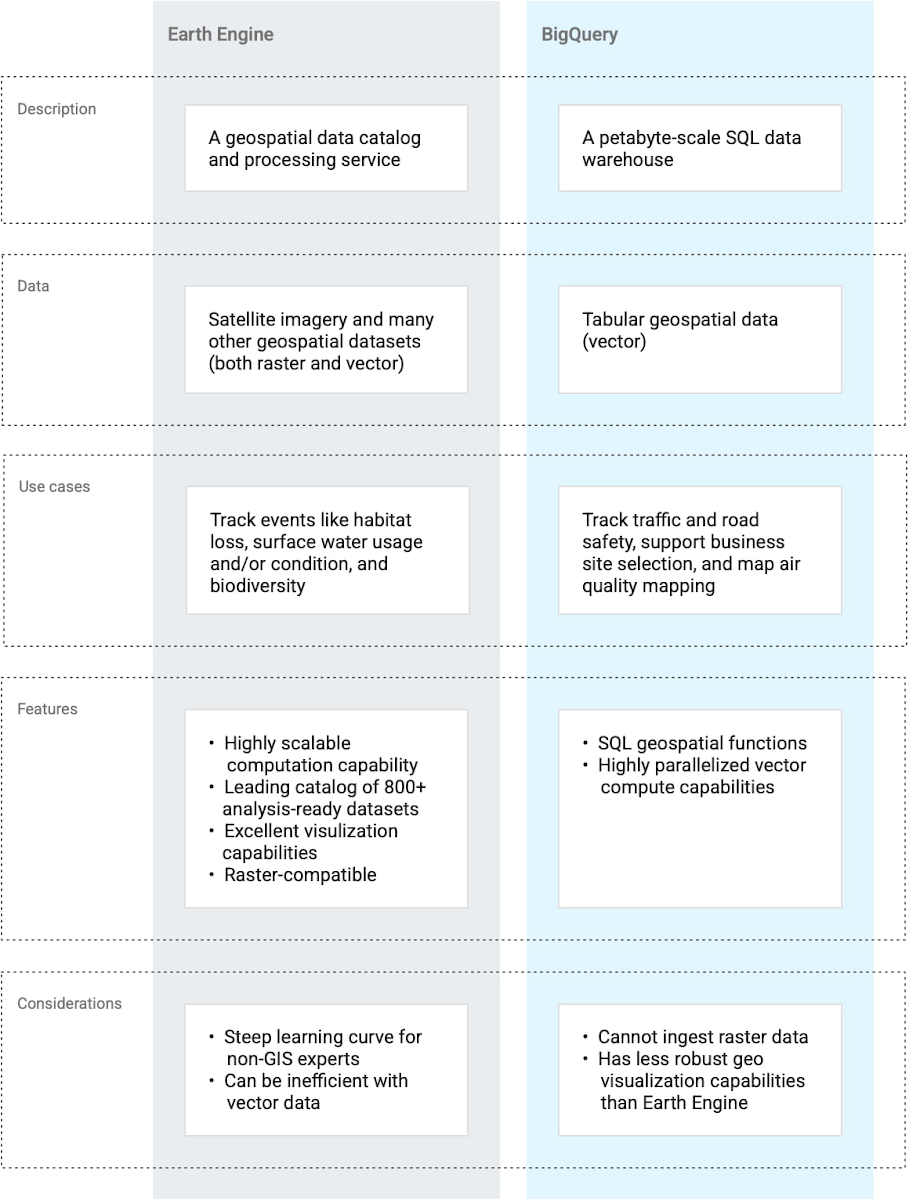
地理空間データには、従来のマッピング以外にも、場所の選定や土地インテリジェンスなどの多くの用途があります。そのため、多くの企業が地理空間データをデータ ウェアハウスや分析に組み込む方法を見出そうとしています。Google Earth Engine と BigQuery はどちらも、地理空間データの解釈、分析、可視化に使用できる Google Cloud Platform 上のツールです。たとえば、Google Earth Engine から取得した衛星データに基づく作物分類を BigQuery の天候データと組み合わせて作物の収穫量を予測できます。
これら 2 つのプロダクトの機能は一部重複していますが、両者は同じものではなく、次の表に示すように異なるユースケース向けに設計されています。このブログでは、地理空間データを Google Earth Engine から BigQuery に移動する方法と必要なデータ形式の変更について説明します。
Earth Engine は優れた可視化機能とデータカタログを備えているため、地理空間ソリューションの発見 / 開発段階などで重要な役割を果たします。BigQuery は完成されたデータ ウェアハウスと評価されており、非地理空間データセットが関与するソリューションに役立ちます。両方のツールを併用したいと思うユースケースは数多くあります。ここから、「Earth Engine のデータを BigQuery に移動するにはどうすればよいだろうか?」という疑問が浮かんできます。
Geobeam を使用して Earth Engine のデータを BigQuery に移動
地理空間データには多くの形態、ファイル形式、投影座標系があるため、ツール間でのデータの移動は簡単ではありません。ただし、Geobeam という比較的新しいオープンソース ライブラリは、Earth Engine と BigQuery のギャップを埋めるために役立ちます。
Geobeam は Apache Beam を拡張する Python ライブラリで、Dataflow を使用して大量の地理空間データを並列で取り込んで分析するのに使用できます。Geobeam は、地理空間データの読み取り、処理、書き込みを容易にする一連の FileBasedSource クラスと Apache Beam 変換を備えています。
このブログでは、Geobeam を使用して Earth Engine から取得した GeoTIFF 形式のラスター データセットを BigQuery にベクター データテーブルとして取り込むチュートリアルを見ていきます。
地理空間データの処理
コードの説明に入る前に、今回使用する各プロダクトが地理空間データをどのように処理するかを理解しておくことは重要です。Earth Engine は地図やアセットの大規模なデータカタログを備えており、これがユーザーに公開されています。また、Earth Engine では CSV ファイルと Shapefiles(ベクターデータ用)または GeoTIFF と TFrecords(ラスターデータ用)のインポートとエクスポートもできます。BigQuery も、Earth Engine より規模は小さいものの、同じように地理空間データセットを公開しています。BigQuery が対応しているデータ形式は、CSV 形式、WKT 形式、または適切にフォーマットされた GeoJSON 形式です。
ラスター ファイル(画像)は独特な種類のファイルであり、BigQuery でネイティブにはサポートされていません。したがって、ラスター ファイルは変換してから BigQuery に取り込む必要があります。次の図に示すように、この変換に Geobeam を使用できます。
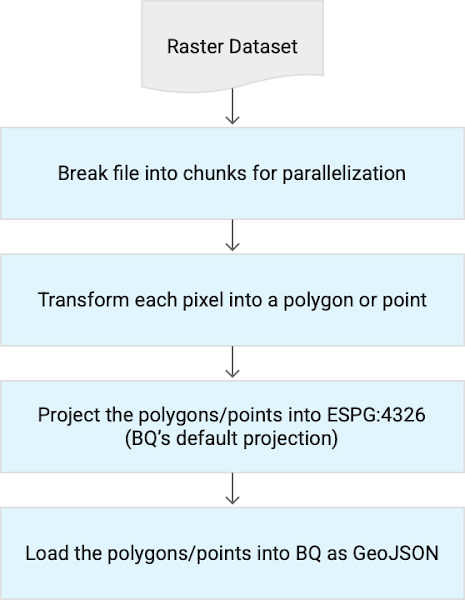
現在、Geobeam で BigQuery を送り先として使用することはまだテスト段階中です。ただし、これは MySQL などの他のシンクに拡張できます。Geobeam は、Python 用の rasterio、shapely、GDAL を主に使用して必要な変換を行います。Geobeam GitHub リポジトリをフォークすることで、Apache Beam で独自の変換を構築することも可能です。
チュートリアル
チュートリアルを実行するには、Earth Engine アカウント(こちらから無料で登録できます)と Google Cloud アカウント(こちらから無料トライアルに登録できます)が必要です。このチュートリアルのすべてのコードは、関連する GitHub リポジトリで見ることができます。このブログを読み進める前提として、読者は Google Cloud Platform についてある程度の知識を持っていると想定しています。
このチュートリアルは次のステップからなります。
Earth Engine で USDA Cropland データを可視化する。
このデータセットを GeoTIFF としてエクスポートする。
Dataflow ジョブを実行し、Geobeam を使用して以下を行う。
ラスター GeoTIFF をベクター形式に変換する。
そのデータを BigQuery に取り込む。
データが正しく BigQuery に読み込まれたことを確認する。
データセットの可視化
ここで使用するデータセットは、USDA Cropland データレイヤーです。これは、Earth Engine カタログに登録されている、米国本土の作物種別データを含む画像コレクションです。次の図は、このデータセット全体が Earth Engine コンソールでどのように可視化されるかを示します。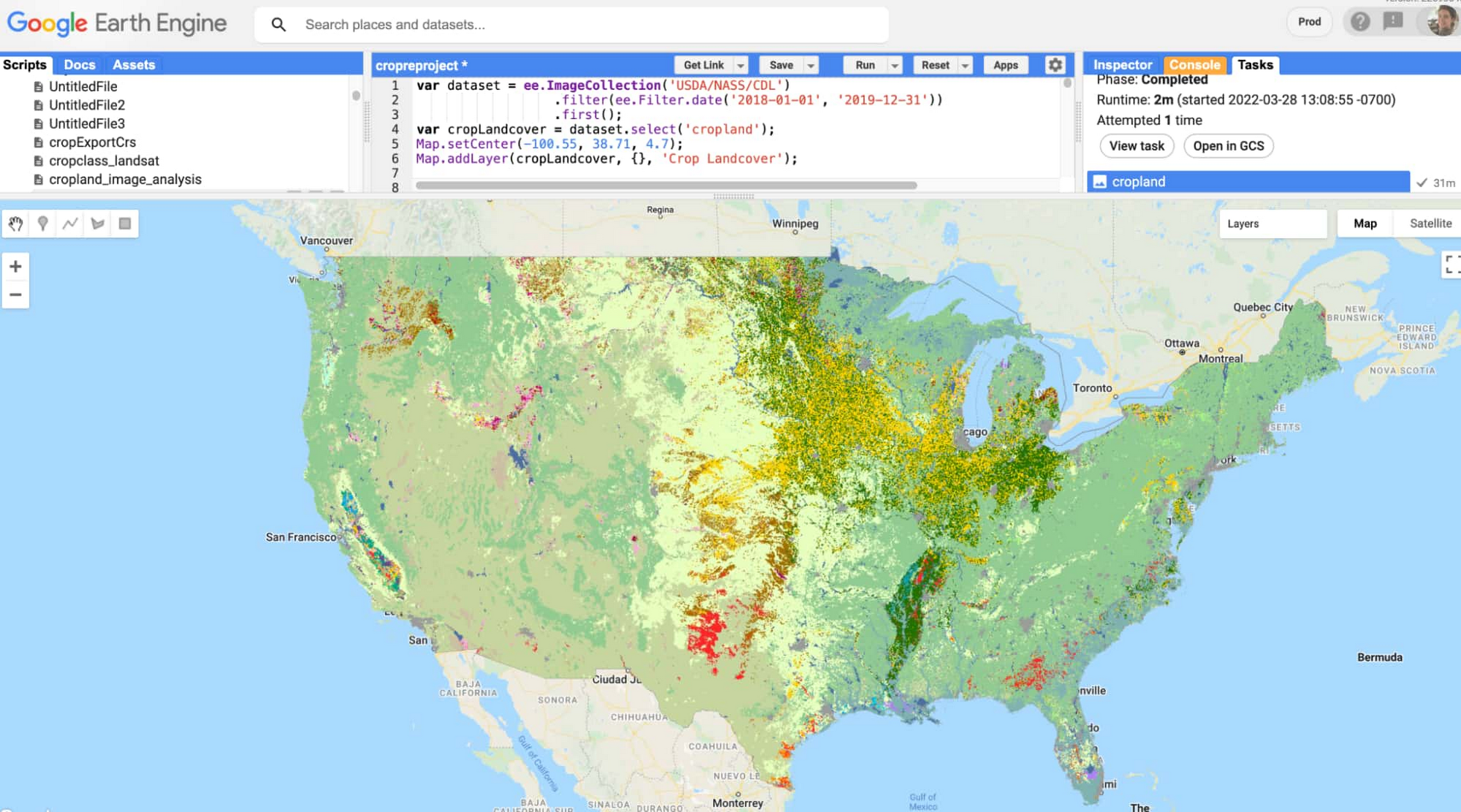
Earth Engine からのデータのエクスポート
Earth Engine からのデータのエクスポートには、Earth Engine コンソールを使用できます。これには JavaScript を利用します。この例では、Earth Engine Python API を使用して Earth Engine にコマンドを送信しました(このチュートリアルの作成時には、Vertex AI Workbench 環境で Jupyter ノートブックを使用しました)。
データセットの Cloud Storage バケットへのエクスポートには、次のスクリプトを使用しました。
このデータセットの更新頻度は年 1 回なので、単一の日付に絞り込んでおけば、その年全体の作物種別が得られます。上記のコードでは、first() メソッドを使用してコレクションから最初の画像を選択しています。もっとも、この例ではその日付範囲に画像は 1 つしかありません。first() メソッドを使用することで、出力は ImageCollection 型ではなく Image 型(エクスポートに使用したい型)として扱われます。
エクスポート文では、画像を EPSG:4326 として再投影しました。この投影は、BigQuery が地理空間データに使用するものです。Geobeam は入力データを EPSG:4326 に再投影するよう設計されており、in_epsg パラメータを使用して入力データのオリジナルの投影を提供できます。Cropland データセットでデフォルトで使用されている投影(Albers Conical Equal Area Map)は特殊なので、それをそのまま Geobeam に渡してデータを再投影するのではなく、エクスポート時により一般的な投影を指定しました。Earth Engine で再投影する場合は、scale 値と crs(座標参照系)値を指定することが重要です。
例として、エクスポートと取り込みの時間を短縮するために小さい地域(コロラド州の一部)をエクスポートしました。米国全体をエクスポートした場合は、エクスポートに約 30 分、Geobeam への取り込みジョブに約 30 分はかかるでしょう。
Google Earth Engine から広大な地域の高解像度ラスターデータを BigQuery にエクスポートすることは推奨されず、一般的に効率的な方法ではありませんが、必要であればそうすることもできます。このチュートリアルでは、単一のバンドを 2.4 MB の GeoTIFF ファイルとしてエクスポートしました。これを変換すると 200 万行の BigQuery データになります。もっとサイズが大きくて複雑なデータセットでは、エクスポートに長時間かかります(メモリ制限を超える可能性もあります)。さらに、BigQuery は衛星画像を可視化するのに適したツールではありません。その代わりに、Earth Engine で画像コレクションの分析を行うことをおすすめします。関連するデータのサブセットがある場合は、そのデータを BigQuery に移動することを検討してください。
Geobeam を使用した BigQuery へのデータの取り込み
ラスター GeoTIFF を Cloud Storage バケットにエクスポートしたら、GeoTIFF をベクター(表形式)データとして BigQuery に取り込む Dataflow ジョブを実行する準備は完了です。パイプライン コード(これは Geobeam GitHub の例にあります)では、Geobeam の GeotiffSource クラスと format_record メソッドを使用して、入力ファイルを BigQuery が取り込める形式に変換しています。
Dataflow で Apache Beam を使用すれば、考えられるほとんどどのような種類のデータ変換でも記述できます。この例で行ったのは、バンドの値(作物種別)を整数として直接読み取り、ピクセルをポイントとして読み取ったことだけです。
Dataflow でのジョブの実行には次のコマンドを使用しました。
centroid_only パラメータを true に設定することで、ピクセル全体(複数のピクセルが同じバンド値を持つ場合はそれら複数のピクセル全体)を含むポリゴンを生成するのではなく、各ピクセルの中心を計算してポイントを生成しました。
merge_blocks パラメータは、読み取り中にピクセルをどのように結合するかを制御します。このパラメータを使用して取り込み時間を調整できます。一般に、merge_blocks の値を増やすと取り込み時間が長くなります。
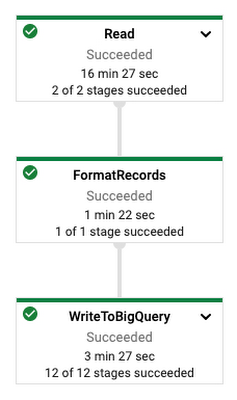
Dataflow ジョブは Cloud コンソールでモニタリングできます。この例では、ジョブの実行に約 11 分かかり、次のように表示されました。
BigQuery でのテーブルの表示
ジョブが完了したら、BigQuery のエクスプローラ パネルでプロジェクト > データセット > 取り込まれたテーブルの順に移動して結果のテーブルを確認できます。テーブルのプレビューは次のようになります。
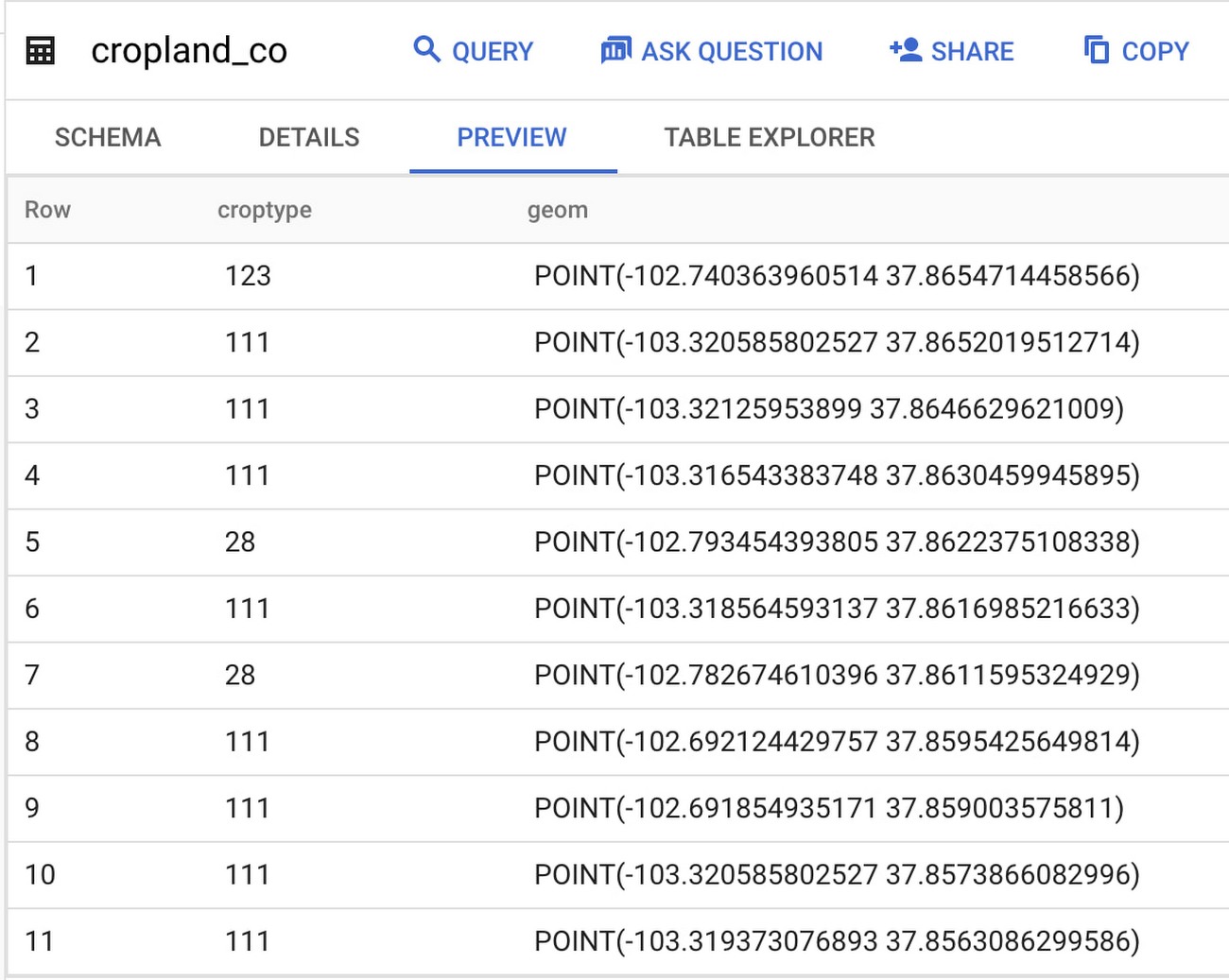
ご覧のように、Earth Engine ではピクセルであったデータが BigQuery ではポイントになっています。つまり、データがラスターからベクターに変換されました。これらのポイントは、BigQuery Geo Viz ツールを使用して地図上に可視化できます。
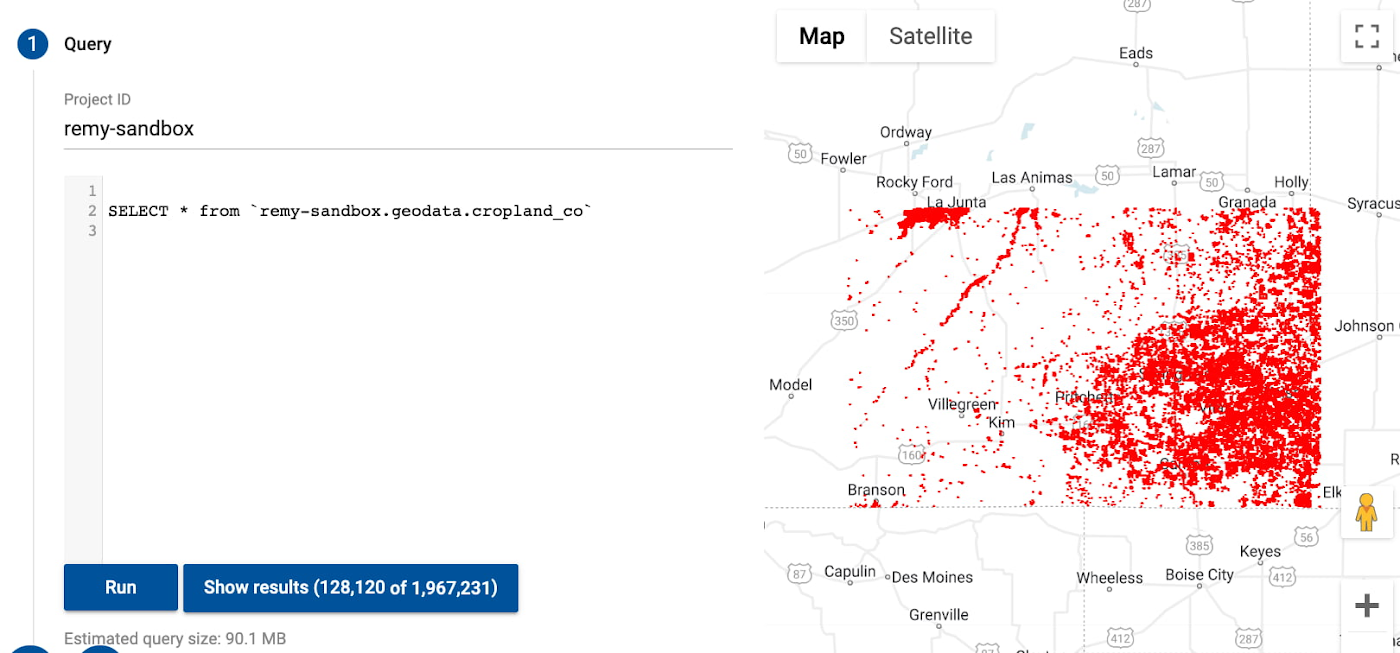
データの分析
このブログでは、Earth Engine から取得したラスターデータを Geobeam で変換して BigQuery にベクターデータとして取り込みました。これは、Geobeam を使用して衛星画像データセット全体を BigQuery で再現できる、またはそうすべきであることを意味するものではありません。BigQuery は画像を処理するようには作られていないため、Sentinel-2 データセット全体を BigQuery に取り込んで分析しようとしても、なかなか思い通りにはいかないでしょう。おすすめの方法は、地理空間データセット内の関心のある特定のバンド、特性、地域を特定し、Geobeam を使用してそれらを BigQuery に取り込むことです。このようにして BigQuery に取り込んだデータを他の表形式データと簡単に組み合わせたり、モデルの構築やその他の分析に使用したりすることができます。
これで作物分類データの BigQuery への取り込みは完了したので、これらのデータを天候情報を含む別のデータセットと空間的に結合し、それらを BQML 予測モデルで特徴として使用できます。たとえば、大豆畑の間の平均距離を計算し、大豆系食品を販売している会社の店舗を探すことができます。
最初は理解しにくいかもしれませんが、地理空間データはデータの世界にまったく新しい次元を開きます。Earth Engine、BigQuery、Geobeam の組み合わせは、地図上での分析に効果的です。
謝辞: この投稿に協力してくれた Travis Webb、Rajesh Thallam、Donna Schut、Mike Pope に感謝します
- カスタマー エンジニア Remy Welch
- データ エンジニア Kannappan Sirchabesan


