音声の高速処理: AI パイプラインによる音声コンテンツの高速分類
Google Cloud Japan Team
※この投稿は米国時間 2020 年 5 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
コンテンツ作りはかつてないほど容易になっています。世界中で創作やコラボレーションを楽しめるアプリが数多く世に出回り、その形態もオンラインでの動画アップロードやストリーミング、ポッドキャスト、ブログ、コメント フォーラムなどさまざまです。こうした多様なプラットフォームにより、自分のアプリやウェブサイトをホストする方法を知らなくても、オリジナルのコンテンツを自由に投稿できます。
しかし、新しいアプリは、ほんの数日で急激に人気になることもあり、スケーリングをどのように管理するかが大きな課題です。アプリ クリエイターは、新しいユーザーとコンテンツをできるだけ増やすことを望む一方で、作成したコンテンツを常に把握することが難しくなっています。独自のコンテンツを自由に投稿できることは、クリエイターにとっては励みになりますが、プラットフォームにとっては管理の課題も生まれます。このため、プラットフォームを提供している組織は、クリエイターの保護とオーディエンスの保護について板挟み状態になっています。クリエイターが自由に望むものを投稿できるようにしながら、オーディエンスにとって適切なコンテンツを維持するにはどうすればよいでしょうか。
これは白黒つけられる問題でもありません。コンテンツが同じであっても、オーディエンス セグメントが異なれば反応が異なる可能性もあります。音楽を例に挙げると、一部の大人は露骨な言葉を使うアーティストの自由を楽しむかもしれませんが、その同じ言葉は子どものオーディエンスには不適切かもしれません。ポッドキャストの場合、その問題はさらに微妙になります。アプリは、リスナーに安心感を与えながら、不適切なコンテンツを管理するという両方の問題に配慮して設計する必要があります。ある曲が適切かどうかを判断するには 3 分かけてその曲を聞けばよいだけかもしれませんが、ポッドキャストの内容を判断するには 30 分から 1 時間、場合によってはもっと長く聴かなければなりません。大人と子どもの両方に向けたコンテンツを提供することは、重要な作業であり、慎重な管理が求められます。このブログでは、スケーリングにより発生する課題と、効率的にスケールして責務を果たそうとするプロバイダのための Google Cloud 活用法を詳しく解説します。
スケーラビリティの課題
多くのプラットフォームには、サイトにアップロードされたコンテンツに対する評価やトリアージを行うスケーラブルなモデルが備わっていません。特に 1 秒間に複数の新しい投稿を受け付けられるものはほとんどありません。一部のプラットフォームでは、オーディエンスや従業員が不適切なコンテンツに手動でフラグを付けています。また、定期的にコンテンツの一部をサンプリング評価しているプラットフォームもあります。ただ、どちらも人的エラーは避けられず、有害なコンテンツがオーディエンスに公開される恐れがあります。コンテンツへの対処に有効なソリューションがないために、やむを得ずサイトへのコメント機能を無効にしたり、古い投稿の評価が終わるまでユーザーによる新規アップロードを無効にしたりしている組織もあります。
評価する入力情報のフォーマットが異なる場合には、さらに問題が複雑になります。文字テキストの場合は、スクリーニングしてから機械学習(ML)モデルに移し、既知の不適切な言葉を抽出できます。ところが音声の場合は、まず前処理段階で文字起こしを行ってから、さまざまな機械学習アルゴリズムを適用してテキストに変換する必要があります。このアルゴリズムでは、文法、言語、話の内容の全体的なコンテキストを考慮して、ディープ ラーニングを活用して文字テキストを予測します。このため、一般的な音声文字変換モデルは、日常的な話し言葉による音声により適しています。一方、乱暴な言葉遣いの音声を扱うことはあまり多くないため、音声文字変換モデルがうまく機能しないことがあります。そのため、音声コンテンツの管理の複雑さについても問題が残ります。
ソリューション
プラットフォーム プロバイダが大量のコンテンツを容易に管理できるようにするために、Google は Natural Language API や Jigsaw の Perspective API も含めたさまざまな Google Cloud プロダクトを組み合わせて、音声コンテンツを分析する処理パイプラインと処理結果を表示するインターフェースを作成しました。これによりコンテンツ利用者に安心な環境が整い、クリエイターはコンテンツが誤って削除されることを恐れずにアップロードや
コラボレーションができるようになります。
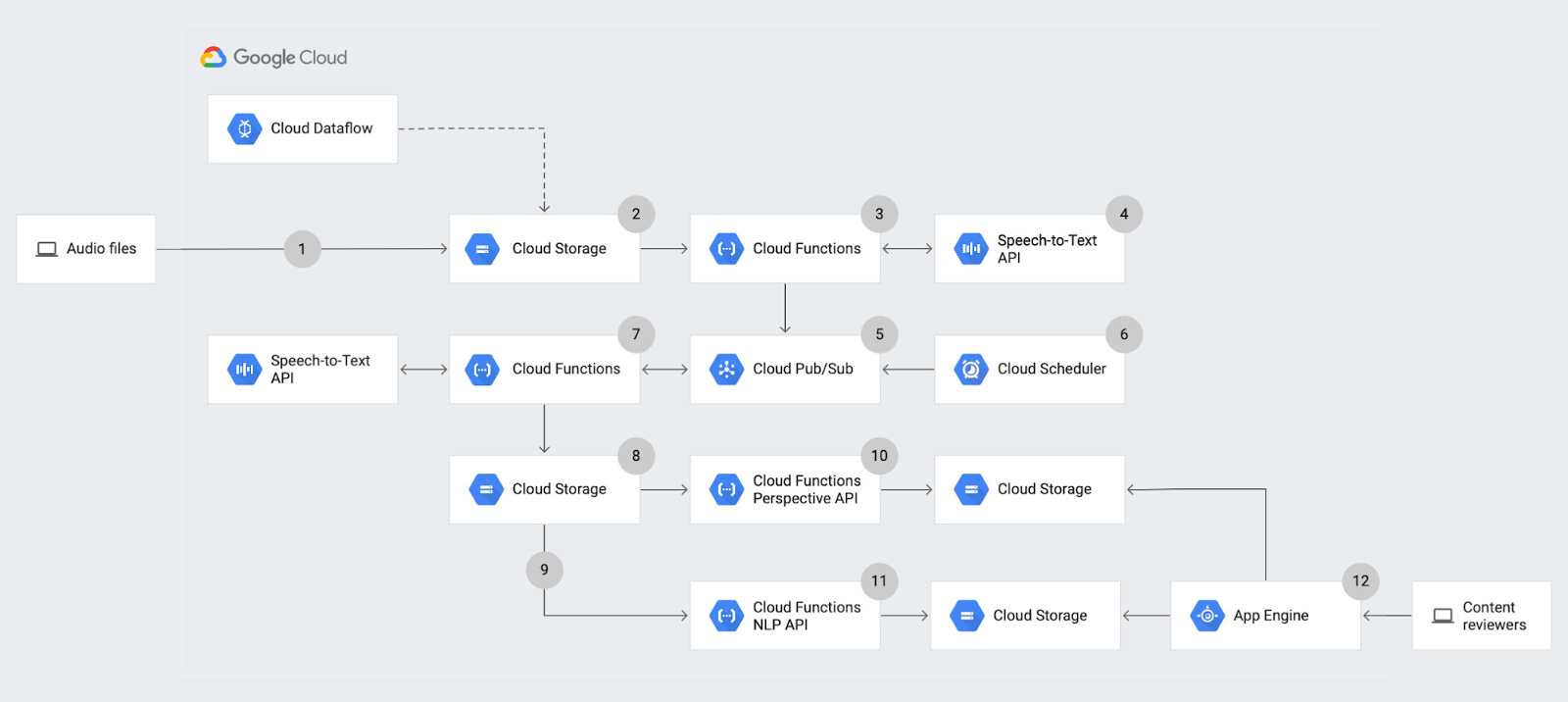
ステップ 1: 音声コンテンツのアップロード
このソリューションでは、まず音声ファイルを Cloud Storage(Google のオブジェクト ストレージ プロダクト)にアップロードします。このアップロードは、Cloud Storage でコマンドライン インターフェース(CLI)またはウェブ インターフェースから、あるいは Dataflow のバッチ アップロード ジョブなどの処理パイプラインから直接実行できます。このアップロードは個々で扱うパイプラインとは無関係です。
このアーキテクチャでは、新しいファイルがアップロードされるたびに分析を開始します。そのため、新しいアップロードがあるたびに通知がトリガーされるように構成します。具体的には、特定の Cloud Storage バケットに新しいオブジェクトが追加されるたびにオブジェクトのファイナライズ通知が送信されるようにします。このオブジェクトのファイナライズ イベントにより、該当する Cloud Functions の関数 がトリガーされ、簡単なサーバーレス処理を実行できるようになります。つまり、実行に必要なリソースに合わせて関数がスケールアップまたはスケールダウンするということです。ここで Cloud Functions を使用する理由は、フルマネージドであるため、インフラストラクチャを独自にプロビジョニングする必要が一切なく、指定したイベントタイプに基づいてトリガーされることです。この関数で、イベントは Cloud Storage へのアップロードです。ただし、Cloud Functions の関数をトリガーする方法は多数あるため、このアーキテクチャではこれらを複数回使用して、さまざまなタイプの分析をそれぞれ個別に実行していきます。
ステップ 2: 音声文字変換分析
最初の Cloud Functions の関数は、音声文字変換処理を開始します。この関数は Speech-to-Text API にリクエストを送信し、このリクエストのジョブ ID を即座に返します。次に、ジョブ ID と音声ファイルの名前をその Cloud Functions の関数から Cloud PubSub にパブリッシュします。これにより、音声文字変換処理が完了するまで念のため情報を保存しておくことができ、複数の音声文字変換ジョブを並列でキューに入れることもできます。
ステップ 3: 音声文字変換結果のポーリング
複数のアップロードを並列処理できるようにするために、音声文字変換ジョブが完了しているかどうかをチェックする 2 つ目の Cloud Functions の関数を作成します。この Cloud Functions の関数のトリガーは 1 つ目の関数とは異なります。このケースではアップロードしたオブジェクトを通知として使用しないため、関数を呼び出すためのサービスとして Cloud Scheduler を使用して関数を開始します。Cloud Scheduler を使用すると、指定した間隔でジョブを繰り返し実行できます。このマネージド cron ジョブ スケジューラを使うことで、必要に応じて毎週、毎日、毎時、または毎分という同じタイミングで Cloud Functions の関数を実行するようにリクエストできます。
今回の例では、10 分おきに Cloud Functions の関数が実行されるようにします。この関数は、未読メッセージを PubSub から pull した後、それらを反復処理してそれぞれのジョブ ID を抽出します。その後、特定のジョブ ID で Speech-to-Text API を呼び出して、音声文字変換ジョブのステータスをリクエストします。音声文字変換ジョブが完了していない場合は、その Cloud Functions の関数から PubSub にジョブ ID と音声ファイルをパブリッシュし直し、次にトリガーされたときにステータスを再度チェックできるようにします。音声文字変換ジョブが完了していた場合は、音声文字変換の結果である JSON 出力をその Cloud Functions の関数が受け取り、詳しく分析するために Cloud Storage バケットに格納します。
次の 2 つのステップでは、音声文字変換の結果に対して 2 種類の機械学習分析を行います。音声文字変換の結果を Cloud Storage にアップロードすると生成されるオブジェクトのファイナライズ通知が、それぞれのステップで異なる Cloud Functions の関数を作成します。
ステップ 4: エンティティと感情分析
1 つ目の処理では Natural Language API を呼び出し、文字変換されたコンテンツに対してエンティティ分析と感情分析を実施します。エンティティ分析では、テキストのさまざまなセグメントをこの API で調べ、音声クリップの中で述べられる可能性のあるさまざまな主題を抽出し、既知のカテゴリ(「人物」、「場所」、「出来事」など多数)にグループ化します。感情分析では、コンテンツを -1 から 1 の範囲で評価し、特定の主題が肯定的に話されているか否定的に話されているかを判断します。
たとえば、「ケイトリンはパイが大好きです」というフレーズを API で分析するとします。最初に行われるのは、テキスト内で述べられている内容の把握です。つまり、「パイ」と「ケイトリン」の両方がエンティティとして抽出されます。次に、「ケイトリン」は「人物」、「パイ」は「その他」と特定の名詞として分類され、それぞれのラベルが生成されます。
次の処理では、このテキストから伝わる全体的な態度や意見を把握します。このフレーズでは、「パイ」に高い感情スコア(おそらく 0.9~1)が付けられます。これは「大好き」という動詞が伝える肯定的な態度によるものです。このフレーズの分析結果からわかるのは、ある人物がある名詞について好意的に話をしているということです。
パイプラインに話を戻します。このステップでは、音声ファイルの全体的な内容を把握しやすくするために、Cloud Functions の関数で Natural Language API を呼び出しています。アップロードされたすべてのファイルをすべて聴くのは時間がかかる作業であるため、Natural Language API の力を借りて簡単な初期チェックを行い、各コンテンツの全体的な印象を把握し、どのような内容についてどのように話されているのかを理解できるようにします。たとえば、「ケイトリンはパイが大好きです」の分析結果を見たユーザーは、話されている内容が肯定的であるため、プラットフォームで公開しても問題ないとすぐに判断できます。
このステップでは、音声文字変換ファイルが Cloud Storage にアップロードされると Cloud Functions の関数が起動します。その後この関数は音声文字変換ファイルを読み取り、それを Natural Language API に送信して感情分析とエンティティ分析をリクエストします。API は、ファイルで表現されている全体的な態度とエンティティを、テキストの論理的なかたまりに分割して戻します。そして、Cloud Functions の関数がこの出力を Cloud Storage に新しいオブジェクトで格納し、後から読み取れるようにします。
ステップ 5: 有害度分析
もう 1 つの Cloud Functions の関数も Cloud Storage に音声文字変換ファイルをアップロードするとトリガーされますが、この関数は Perspective API を起動します。つまり、前のステップと並行して実行されるということです。この API では、テキストのかたまりと個々の単語の両方を分析し、それぞれの有害度を評価します。有害度は露骨さ、不快さ、不適切さなどさまざまなものを指す場合があります。
有害度は従来、公開フォーラムでの会話を可能にする短いコメントに使用されていますが、他のフォーマットでも使用できます。たとえば、多少のブラック ユーモアが含まれる 1 時間のポッドキャストの内容を従業員が管理してみるケースを見てみましょう。このような長尺のコンテンツを簡易的に理解するのは困難です。そのため、オーディエンスがポッドキャストのユーモアを不適切と報告しても、プラットフォームのモデレーターがファイル全体を聴いて、コンテンツ内での表現方法が本当に不適切なのか、ふざけているだけなのか、誤って報告されてしまったのかなどを判断することが必要になります。ポッドキャストやサイズの大きい音声ファイルの量を考えると、報告されたコンテンツを 1 つひとつ聴く作業には膨大な時間がかかります。つまり、不適切ファイルはすみやかに削除されず、オーディエンスに不快な思いをさせ続けることになります。同様に、侮辱しているように見えても害のない悪ふざけが含まれるコンテンツもあるでしょう。
こうした課題に対処しやすくするために、この Cloud Functions の関数はテキストを分析してコンテンツに関する予測を生成します。この関数は、Cloud Storage から音声文字変換ファイルを読み取り、Perspective API を呼び出して読み取ったテキストを入力として供給します。次に、テキストのかたまりごとに有害度に関する予測を受け取り、Cloud Storage の新しいファイルに格納します。
これで分析は完了です。コンテキスト全体を把握するため、最後にこのソリューションのユーザー インターフェース(UI)について説明します。
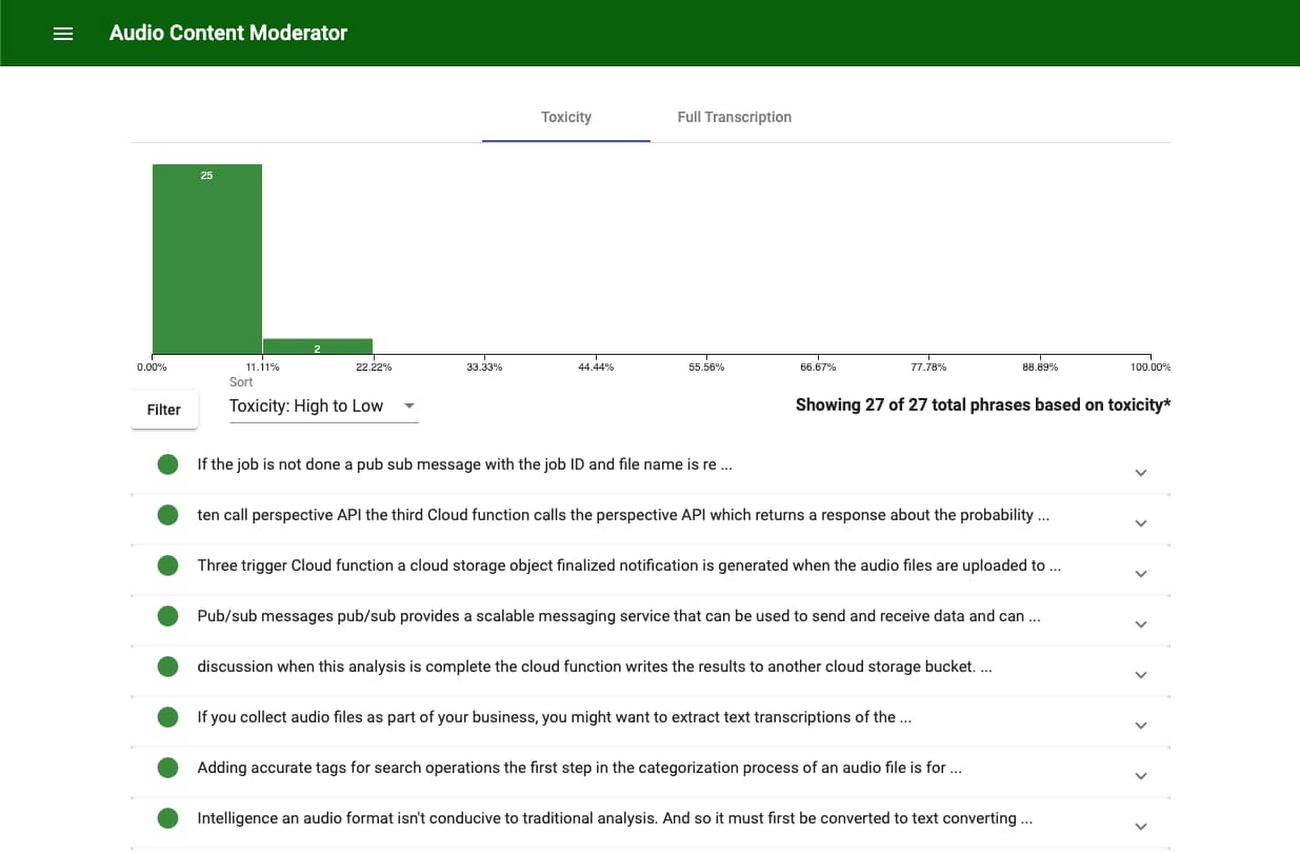
ユーザー インターフェース
このソリューションの UI は App Engine を基盤に構築されているため、サーバーを独自に管理しなくてもフルマネージドのアプリケーションをデプロイできます。生成された出力を Cloud Storage から読み取り、理解しやすいユーザー フレンドリーな方法でそれを表示します。
ユーザーはこの UI を使って Cloud Storage にある各音声文字変換ファイルの名前を一覧表示できます。ファイルを選択したら、モデレーターは、論理的かつ理解しやすく分割された音声文字変換を確認できます。テキスト ブロックは、有害性のレベルや Perspective API による生成順、またはファイルに登場する順に並べ替えられます。
テキストの横にあるのは、有害な内容が含まれる確率を示すパーセンテージです。結果は生成された有害性のレベルに基づいてフィルタできます。素早く処理するには、一定のしきい値を設定して、しきい値を上回ったファイルのみを手動で審査します。たとえば、スコアが 50% 未満のテキストばかりが含まれるファイルには初期審査は必要ないかもしれませんが、いつも評価が 90% を超えるセクションを含むファイルは審査したほうがよいでしょう。これにより、モデレーターはより積極的かつ強い目的意識を持って音声コンテンツを調査できるようになり、ユーザーから有害コンテンツの報告を待つことや、音声ファイル全体を聴く必要がなくなります。
各テキスト ブロックには、Natural Language API による分析結果を示すポップアップも含まれています。これはコンテンツの各ブロックのさまざまな態度と主題を示します。これを見ることで、コンテンツの概要をすぐに把握できます。
結果
このアーキテクチャでは Google Cloud の事前トレーニング済みの Speech-to-Text API と Natural Language API を使用していますが、さらに高度なモデルを使ってカスタマイズできます。たとえば Speech-to-Text API は、音声コンテキスト構成オプションに含めることで精度を高められます。音声コンテキストを使用すると、音声に含まれている可能性のあるヒント(予測される単語)を組み込むことができます。既知の暴言などの不適切な言葉を組み込むことで、ヒントを使ったクライアント API リクエストのカスタマイズが可能になり、モデルが音声を文字に変換する際のコンテキストを提供できるようになります。
他に、利用しているプラットフォームが特定のタイプのコンテンツにフラグを付けたり、特定の主題を特定の方法で分類しようしたりすることなども考えられます。たとえば、音声セグメントに含まれる政治的なコメントを把握する必要がある場合です。AutoML Natural Language を使用すると、指定した既知のエンティティに対してカスタムモデルをトレーニングすることや、ドメイン固有の用語を使用することが可能です。ここでのメリットは Natural Language API と同様です。機械学習の専門知識がなくても構いません。この API の場合も Google Cloud がモデルを構築し、ユーザー独自のデータを使用して行います。
独自のモデルを使って独自性を高めた分析を行うには、TensorFlow または転移学習を使用します。この場合のメリットは、固有のユースケースに合わせたモデルと分析ができることですが、Google Cloud のマネージド機能は活用されず、独自のモデルをメンテナンスし続ける必要があります。
このブログで紹介したパイプラインを使えば、よりプロアクティブにコンテンツを管理できるようになります。また、音声ファイルの全体像を把握して、会話のトピックとそのトピックに対する全体的な態度や、不適切なコンテンツが含まれている可能性を知ることができます。そして、モデレーターの審査工程が劇的にスピードアップします。音声全体の文字変換テキストを提供し、重要フレーズを強調表示して、テキストを有害度の高い順に並べることで、ファイル全体を聴いて判断を下す必要がなくなります。このパイプラインは、プラットフォーム、クリエイター、ユーザーが形成するコンテンツ チェーンのあらゆるフェーズに影響するものであり、誰もが快適なユーザー エクスペリエンスを享受し、あらゆる創造的な作品を手軽に楽しむことができます。
音声コンテンツの分類に関する詳細については、こちらのチュートリアル、概要ドキュメント、ソースコードをご覧ください。
- By 戦略的クラウド エンジニア Kaitlin Ardiff、応用 AI 担当テクニカル ディレクター Ashwin Ram



{kind=link}
{kind=link}