Google Cloud Dataflow を使用した GNN の異種グラフ サンプリングのスケーリング
Google Cloud Japan Team
※この投稿は米国時間 2022 年 7 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
このブログでは、Google Cloud Dataflow(Dataflow)を使用して異種グラフのサブサンプリングを大規模に行うオープンソースのソリューションをご紹介します。Dataflow は、大規模な Apache Beam コンピューティング パイプラインを実行するために Google が一般に公開しているフルマネージド環境です。Dataflow はすぐに使用できるモニタリングとオブザーバビリティの機能を備えており、厳しい要件のデータセットを簡単に処理できるよう本番環境システムをスケーリングするために日常的に使用されています。
この記事では、Tensorflow-GNN(TF-GNN)を使用してグラフ ニューラル ネットワーク(GNN)をトレーニングするための前処理のステップとして、グラフのサブサンプリングの問題を説明します。TF-GNN は、Google のオープンソース GNN ライブラリです。
次のセクションでは、問題を説明し、Docker、Apache Beam、Google Cloud Dataflow、TF-GNN Unigraph 形式、TF-GNN グラフ サンプラーなどの必要なツールの概要を紹介し、最後に GNN(ノード予測)ベンチマークで広く使用されている大規模異種引用ネットワーク(OGBN-MAG)を使ったエンドツーエンドのチュートリアルで締めくくります。TF-GNN を使用したモデリングやトレーニングは、ライブラリのドキュメントと論文で説明されているため、ここでは扱いません。
目的
ソーシャル グラフ、引用ネットワーク、オンライン コミュニティ、分子データから派生したデータを含むリレーショナル データセット(グラフ構造を含むデータセット)は増え続けており、モデルを最適化し、構造化データから分析情報を引き出すためにディープ ラーニングの手法を適用することは一般的になりつつあります。元は構造化されていないデータセットであっても、Grale(半教師ありグラフ学習)などのツールにより、ディープ ラーニングの手法を適用する前に構造を推測することで、ML タスクのパフォーマンス向上が見られることは珍しくありません。
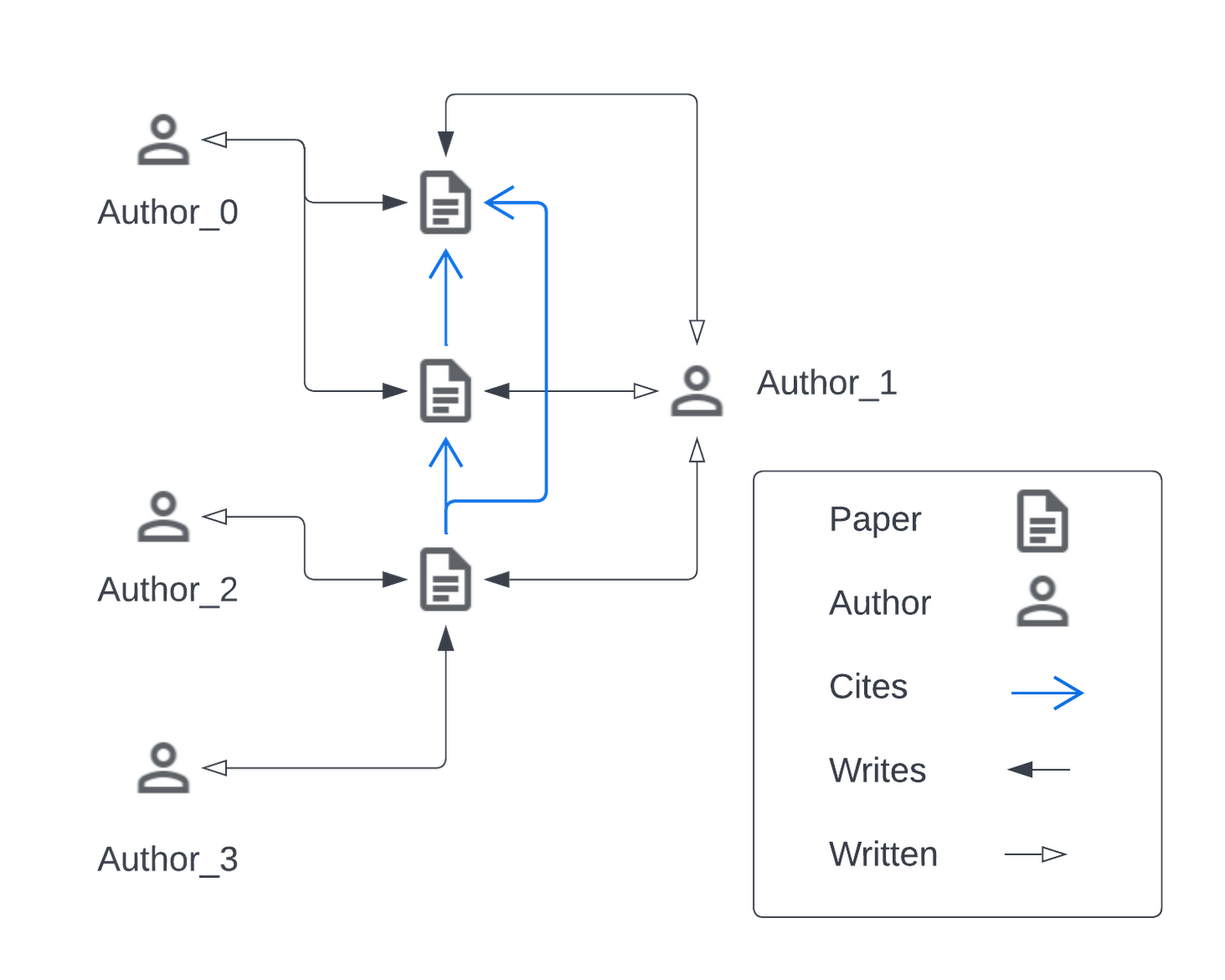
以下は、一般的に使用されている OGBN-MAG データセットと同じスタイルで引用ネットワークを可視化した総合的な例です。この図は異種グラフ、つまり複数のタイプのノード(エンティティ)とその間の関係(エッジ)を含むリレーショナル データセットを示しています。この図には、「Paper(論文)」と「Author(著者)」の 2 つのエンティティがあります。特定の著者が特定の論文を「Write(書く)」することで、「Author」エンティティと「Paper」エンティティ間のリレーションが定義されます。「Paper」は一般的に、他の「Paper」を「Cite(引用)」することで、「Papers」エンティティ間のリレーションを構築します。
実世界のアプリケーションでは、エンティティやリレーションの数が非常に多く複雑な場合があり、ほとんどの場合、単一のマシンで完全なデータセットをメモリに読み込むことは不可能です。
グラフ ニューラル ネットワーク(GNN または GCN)は、ディープ ラーニングとメッセージ パッシング フレームワークを構造化データにスケーリングするための技術として急速に成長しているスイートであり、Tensorflow GNN(TF-GNN)は Tensorflow プラットフォーム上に構築された Google のグラフ ニューラル ネットワーク ライブラリです。TF-GNN は、tfgnn.GraphTensor を含むネイティブな Tensorflow オブジェクトを定義し、何百万ものノードと何兆ものエッジのあるグラフを含む学術的アプリケーションから実世界のアプリケーションまでスケーリングできる任意の異種グラフ、モデル、処理パイプラインを表現することが可能です。
GNN モデルを大規模なグラフにスケーリングすることは困難であり、通常、実世界の構造化データセットとしてアクティブな研究分野は単一のマシンで利用可能なメモリに収まらないため、GNN を使用したトレーニングや推論は単一のマシンでは不可能です。この場合に考えられる解決策としては、大規模なグラフを複数の断片にパーティショニングし、それぞれを 1 台のマシンに収まるようにして、トレーニングと推論に連携して使用する方法があります。GNN はメッセージ パッシング アルゴリズムに基づいているため、元のグラフがどのようにパーティショニングされているかは、モデルのパフォーマンスにとって非常に重要です。
従来の畳み込みニューラル ネットワーク(CNN)には、自然なパーティショニング スキームを定義するために利用できる規則性がありますが、GNN のトレーニングに使用されるカーネルは、グラフ全体の表面に重複する可能性があり、不規則な形状で、通常はスパースです。GCN のスケーリングには、補完タイプや事前計算による集約など他のアプローチもありますが、Google は主にサブグラフのサンプリングに取り組んでいます。サブグラフのサンプリングでは、ランダムな探索を使用してグラフを小さなサブグラフにパーティショニングし、元のグラフの構造を把握します。
このドキュメントでは、グラフ サンプラーはバッチの Apache Beam プログラムで(潜在的に)大規模な異種グラフとユーザ提供のサンプリング仕様を入力として受け取り、サブサンプリングを実行し、ダウンストリームの TF-GNN トレーニング用にエンコードしたストレージ システムに tfgnn.GraphTensors を書き込みます。
Docker、Beam、Google Cloud Dataflow の概要
Apache Beam(Beam)は、コンピューティング集約型の処理パイプラインを表現するためのオープンソース SDK で、複数のバックエンド実装に対応しています。Google Cloud Platform(GCP)は Google のクラウド コンピューティング サービスで、そのなかでも Dataflow は Beam パイプラインを大規模に実行するための GCP 実装です。Beam SDK で定義される 2 つの主要な抽象化は次のとおりです。
コンピューティングは Apache Beam SDK を使用してパイプラインで表され、ランナーがコンピューティング環境を定義します。具体的には、Google は DataflowRunner と呼ばれる Beam Runner 実装を提供し、(ユーザー提供の認証情報で)GCP プロジェクトに接続し、GCP 環境下で Beam パイプラインを実行します。
Beam パイプラインを分散環境で実行する場合、DAG 内の手順を実行するコンピューティング ユニットである「ワーカー」マシンの使用を必要とします。Beam SDK を使用して定義されたカスタム オペレーションがワーカーマシンにインストールされて利用可能であること、ワーカー間の伝達されるデータのシリアル化およびシリアル化解除が可能である必要があります。DataflowRunner のほかにも、ローカル ハードウェア上で Beam パイプラインを実行できる DirectRunner があり、通常、開発、検証、テストに使用されます。
クライアントが DirectRunner を使用して Beam パイプラインを起動すると、パイプラインのコンピューティング環境はローカルホストをミラーリングし、ユーザーのマシンで利用できるライブラリとデータが Beam ワークユニットで利用できるようになります。分散環境で実行する場合は、これに該当しません。ワーカーマシンのコンピューティング環境は、リモート Beam パイプラインをディスパッチするホストとは異なる可能性があります。Python の標準ライブラリのみに依存するパイプラインはこれで十分かもしれませんが、数学パッケージまたはカスタムの定義やバインディングに依存する可能性のある科学技術計算では、これは通常使用できません。
たとえば、TFGNN は、Beam パイプラインを開始するクライアントとサンプリング DAG の手順を実行するワーカーの両方にインストールする必要があるプロトコル バッファ(tensorflow / gnn / proto)を定義します。解決策の一つは、完全な TFGNN ランタイム環境を定義する Docker イメージを生成し、Beam パイプラインの実行前に Dataflow ワーカーにインストールすることです。
Docker コンテナは、共通のマシン上で他のアプリケーションから分離できるポータブルな仮想化ランタイム環境を定義するためにオープンソース コミュニティで広く使用され、サポートされています。Docker コンテナは、Docker イメージ(概念的には読み取り専用のバイナリ blob またはテンプレート)の実行中のインスタンスとして定義されます。イメージは、目的のコンピューティング環境の仕様を列挙した Dockerfile によって定義されます。Dockerfile のユーザーは Docker イメージを「ビルド」し、Docker をインストールした他のユーザーがこれを使用して共有し、分離されたコンピューティング環境をインスタンス化できます。Docker イメージは、Docker CLI などのツールでローカルにビルドすることも、Google Cloud Build(GCB)でリモートからビルドすることも可能です。Docker イメージは、Google Container Registry または Google Artifact Registry などの公開リポジトリまたは限定公開リポジトリで共有できます。
TF-GNN は、オペレーティング システムを指定する Dockerfile と、一連のパッケージ、バージョン、インストール手順を提供し、TF-GNN の(Docker をインストールした)ユーザーなら誰でも使える共通の密閉型コンピューティング環境をセットアップできます。GCP では、TF-GNN ユーザーは TF-GNN の Docker イメージを構築し、そのイメージをイメージ リポジトリに push して、Dataflow ワーカーが Dataflow パイプラインの実行によってスケジュールされる前にインストールできるようにすることが可能です。
Unigraph データ形式
TF-GNN グラフ サンプラーは、Unigraph と呼ばれる形式のグラフを受け取ります。Unigraph は、ノードセットとエッジセット(タイプ)の変数で、非常に大きな同種、異種のグラフをサポートします。現在、グラフ サンプラーを使用するためには、グラフを Unigraph 形式に変換する必要があります。
Unigraph の形式は、完全な(サンプリングされていない)グラフトポロジを記述するテキスト形式の GraphSchema プロトコル バッファ(proto)メッセージ ファイルによって支えられています。GraphSchema は、主に次の 3 つのアーティファクトを定義します。
コンテキスト: グローバル グラフの機能
ノードセット: 異なるタイプおよび関連する機能(省略可)を含むノードのセット
エッジセット: ノードセット内のノードを関連づける有向エッジ
各コンテキスト、ノードセット、エッジセットには、ID と機能の「テーブル」があり、CSV ファイル、TFRecords コンテナ内の共有 tf.train.Example proto など、多くのサポート形式のうちの一つである可能性があります。各「テーブル」アーティファクトの場所は、スキーマに対して絶対的またはローカル規模である場合があります。通常、スキーマとすべての「テーブル」は、グラフのデータ専用の同じディレクトリに存在します。
Unigraph は、ユーザーが簡単にカスタム データソースを Unigraph 形式に変換できるように、意図的にシンプルになっています。Unigraph 形式は、グラフ サンプラーとそれに続いて TF-GNN が使用できます。
Unigraph が定義されると、グラフ サンプラーはさらに次の 2 つの構成アーティファクトを必要とします。
(省略可)シードノード ID
指定した場合、ランダムな探索は指定した「シード」ノード ID のみから開始します。
グラフ サンプラーは、「シードノード」のセットを起点として、グラフ構造をランダムに探索することでサブグラフを生成します。シードノードはユーザーが明示的に指定するか、省略する場合はグラフのすべてのノードがシードノードとして使用され、グラフのすべてのノードに対して 1 つのサブグラフが生成されます。Apache Beam のプログラミング モデルと Dataflow エンジンを利用することで、単一のマシンにグラフ全体を読み込むことなく、大規模な探索を行うことができます。
SamplingSpec メッセージは、ユーザーがエッジセットによるグラフの探索方法とノードセット(シードノードから始まる)のサンプリングの実行方法を制御できるグラフ サンプラーの構成です。SamplingSpec はさらにもう一つのテキスト形式のプロトコル バッファ メッセージで、単一の「seed_op」オペレーションから始まるサンプリング オペレーションを列挙します。
例: OGBN-MAG Unigraph 形式
たとえば、次のノードとエッジを含む一般的な大規模異種引用ネットワークである OGBN-MAG データセットについて考えます。
OGBN-MAG ノードセット
「paper」には、736,389 件の学術論文が含まれており、それぞれに、各論文のタイトルと要約に含まれる単語のエンベディングを平均化することで計算された 128 項目の word2vec 特徴ベクトルがあります。
「field_of_study」には、59,965 件の研究分野が含まれ、関連する特徴表現はありません。
「author」には、1,134,649 名の論文の異なる著者が含まれ、関連する特徴表現はありません。
「institution」には、著者の所属機関として記載された 8,740 の機関が含まれ、関連する特徴表現はありません。
OGBN-MAG エッジセット
「cites」には、論文からその論文が引用した論文までのエッジが 5,416,217 個含まれています。
「has_topic」には、論文からその論文のゼロ個以上の研究分野までのエッジが 7,505,078 個含まれています。
「writes」には、著者から、その著者名を掲載している論文までのエッジが 7,145,660 個含まれています。
「affiliated_with」には、著者から、いずれかの論文にその著者の所属機関として記載されているゼロ個以上の機関までのエッジが 1,043,998 個含まれています。
このデータセットは、以下のスケルトン GraphSchema メッセージで Unigraph に記述できます。
このスキームはいくつかの詳細を省略していますが(完全なサンプルは TFGNN リポジトリに含まれています)、GraphSchema メッセージは単に node_sets のコレクションとしてノードタイプを列挙し、ノードセット間の関係は edge_sets メッセージによって定義されることを示すには十分な概要となっています。
注: 追加の「written」エッジセットもあります。この関係は、元のデータセットでは定義されておらず、永続メディアでも顕在化されていません。しかし、「written」テーブルの仕様では、「writes」エッジセットの転置として、論文から著者へ戻る有向エッジを作成する逆関係を定義しています。tfgnn-sampler は、metadata.extra タプルを解析し、edge_type/reverse Key-Value ペアが存在する場合は、ソースとターゲットを交換するエッジ(関係)の追加の PCollection を生成し、永続メディア上に表現された関係を相対化します。
サンプリングの仕様
TF-GNN モデラーは、特定のタスクとモデルに対して SamplingSpec 構成を作成します。OGBN-MAG での特定のタスクの一つは、テストセットから論文が発表された場所(ジャーナルや学会)を予測することです。そのタスクの有効なサンプリング仕様を次に示します。
この特定の SamplingSpec は、サンプリング仕様のノードセットとリレーションの関係を示すプレート表記で、次のように可視化できます。
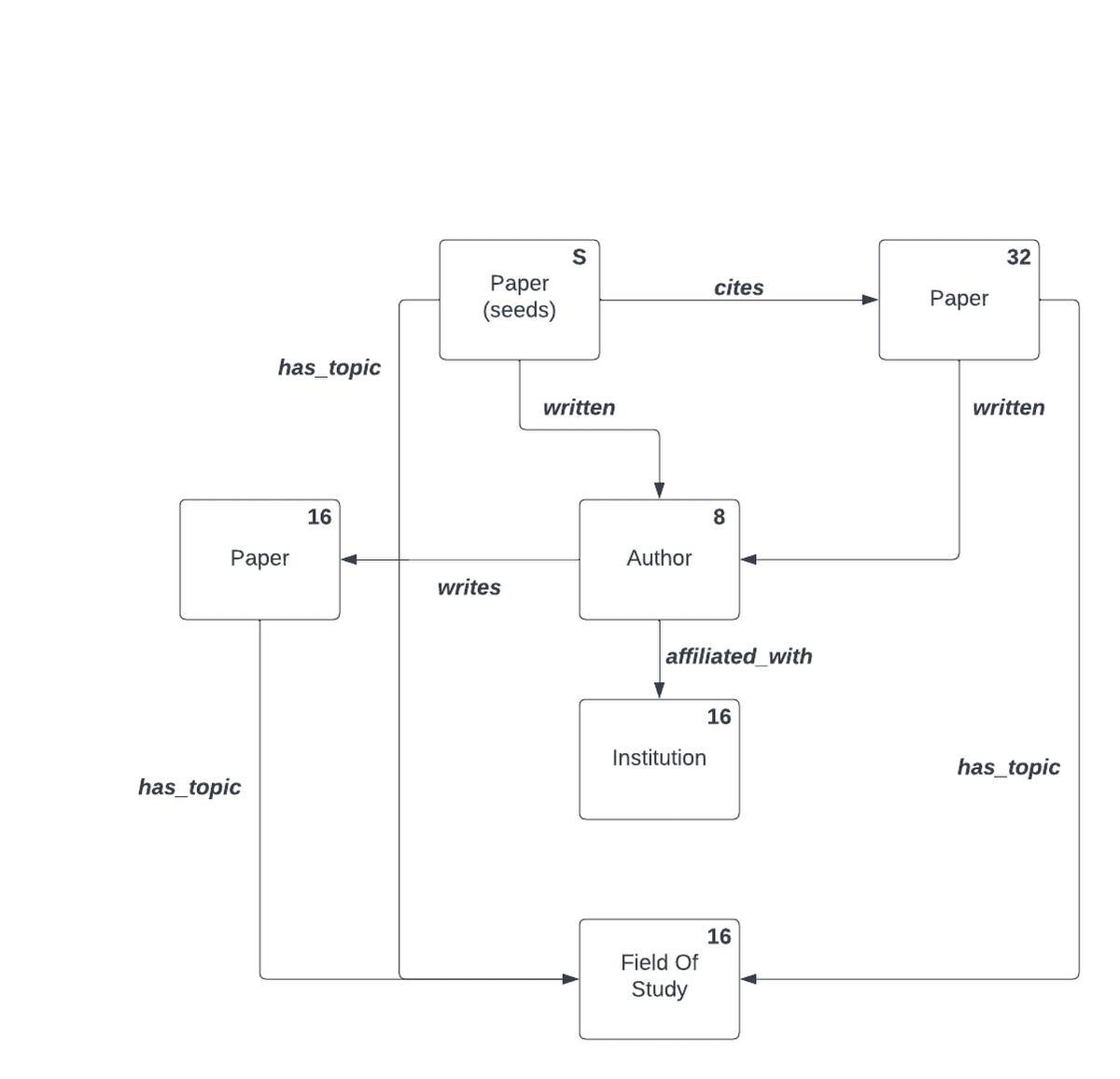
このサンプリング仕様は、人が読める形式では次のような一連の手順で記述できます。
「paper」ノードセットのすべてのエントリを「seed」ノード(サンプリングされたサブグラフのルート)として使用します。
引用エッジセットにより、「seed」ノードからさらに 16 の論文をランダムにサンプリングします。このサンプリングされたセットを「seed->paper」と呼びます。
「seed」セットと「seed->paper」セットの両方で、「written」エッジセットを使用して 8 人の著者をサンプリングします。取得したサンプリングされた著者のセットに「paper->author」と名付けます。
「paper->author」セットのそれぞれの著者で、「affiliated_with」エッジセットを介して 16 の機関をサンプリングします。
「seed」の各論文で、「seed->paper」と「author->paper」が、「has_topic」リレーションを介して 16 の研究分野をサンプリングします。
ノードとエッジの集計
現在、グラフ サンプラー プログラムはオプションの入力フラグ edge_aggregation_method を取得し、node または edge(デフォルトは edge です)に設定できます。エッジ集計方法は、グラフ サンプラーがランダムな探索後にサブグラフ単位で収集するエッジを定義します。
edge 集計方法を使用すると、最終的なサブグラフにはランダム探索時に走査されたエッジのみが含まれます。node 集計方法を使用すると、最終的なサブグラフにはランダム探索時に訪れたノードのセット内のソースノードとターゲット ノードが存在するすべてのエッジが含まれます。
わかりやすい例として、次のような 3 つのノード {A, B, C} を有向辺とするグラフを考えてみます。
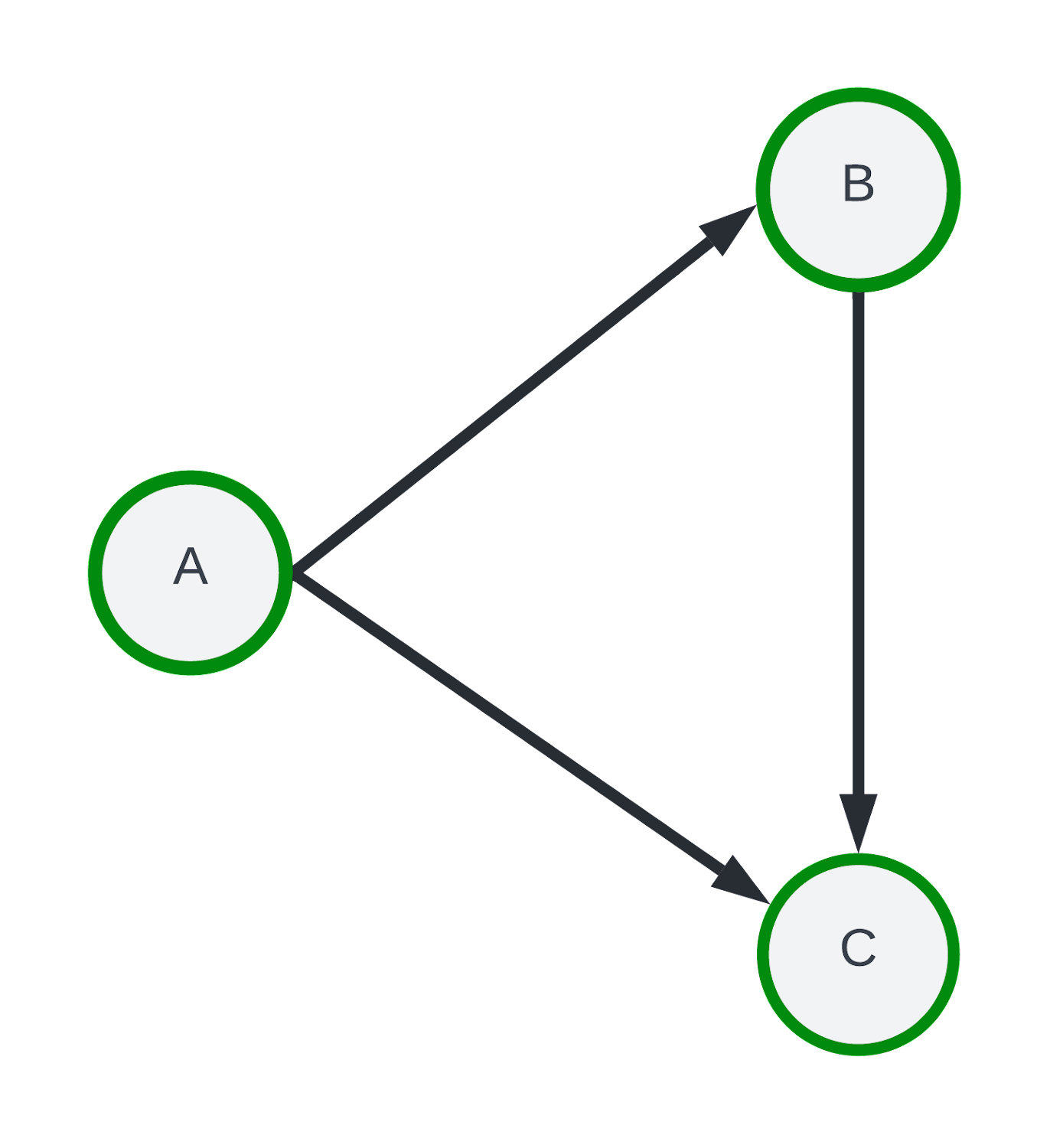
グラフの例。
ランダム探索の代わりに、シードノード「A」を起点として、エッジ A → B、A → C を走査する 1 つのホップの範囲の最初の探索を実行するとします。edge 集計方法を使用すると、最終的なサブグラフには A → B と A → C のみが保持される一方、node 集計には A → B、A → C、B → C エッジが含まれます。サンプリング パスの例と、エッジとノードの集計結果を以下に可視化します。
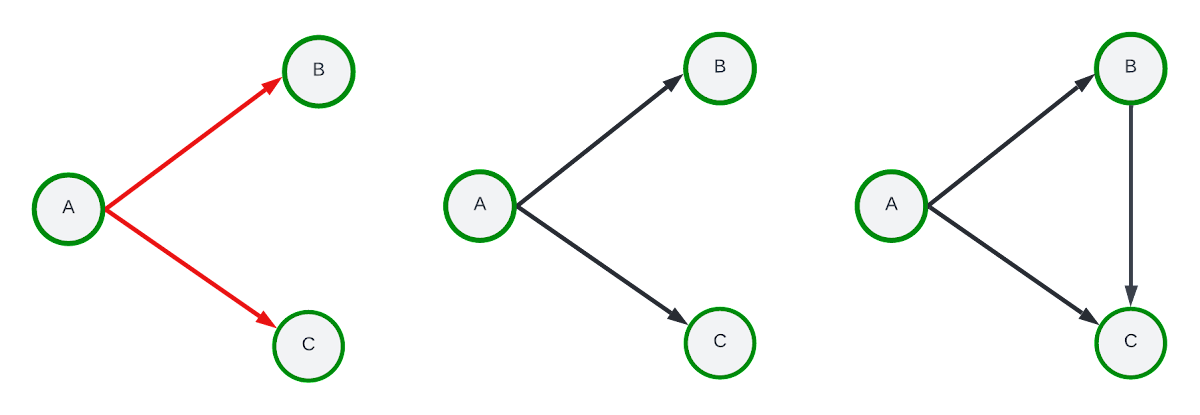
左: サンプリング パスの例。中央: エッジ集計のサンプリング結果。
右: ノード集計のサンプリング結果。
edge 集計方法は、node 集計方法よりも時間とスペースが節約されますが、node 集計方法では一般的にエッジ密度の高いサブグラフが生成されます。ノードベースの集計は、いくつかのデータセットにおいてトレーニングや推論の際により最適なモデルを生成できることが実際にわかっています。
Google Cloud Dataflow OBGN-MAG による TF-GNN グラフ サンプリング: エンドツーエンドの例
グラフ サンプラーである、異種グラフ サンプリングを実装する Apache Beam プログラムは、TF-GNN オープンソース リポジトリにあります。
他のワークフローも可能ですが、このチュートリアルでは、ユーザーがインターネットにアクセスできるローカルマシンから Docker イメージをビルドし、Dataflow ジョブを開始することを想定しています。
まず、ローカル ホストマシンに Docker をインストールしてから、tensorflow_gnn リポジトリを確認します。
ユーザーは、GCP プロジェクトの名前(ここでは、GCP_PROJECT と呼びます)と、なんらかの GCP 認証情報が必要です。デフォルトのアプリケーション認証情報は、分離されたプロジェクト内で開発およびテストを行う場合に一般的ですが、本番環境システムでは、カスタムのサービス アカウント認証情報を維持することを検討してください。デフォルトのアプリケーション認証情報は、以下の方法で取得できます。
ほとんどのシステムで、このコマンドはアクセス認証情報を次の場所にダウンロードします: ~/.config/gcloud/application_default.json
クローンされた TF-GNN リポジトリの場所を ~/gnn とすると、TF-GNN Docker イメージは次のように構築し、GCP Container Registry に push できます。
イメージのビルドと push には時間がかかる場合があります。ローカルでのビルドや push を避けるには、Google Cloud Build を使用してローカルの Dockerfile からリモートで直接イメージをビルドできます。
OGBN-MAG データを取得する
TFGNN リポジトリには、~/gnn/examples ディレクトリがあり、OGBN ウェブサイトから一般的なグラフ データセットを自動的にダウンロードして Unigraph としてフォーマットするプログラムが含まれています。シェル スクリプト ./gnn/examples/mag/download_and_format.sh は Docker コンテナ内でプログラムを実行し、ローカルマシンの /tmp/data/ogbn-mag/graph に ogbn-mag データセットをダウンロードして Unigraph に変換し、必要な GraphSchema とノードセットとエッジセットを表すシャーディング済みの TFRecord ファイルに変換します。
GCP の Dataflow でサンプリングを大規模に実行するには、このデータを Google Cloud Storage(GCS)のバケットにコピーして、Dataflow ワーカーがグラフデータにアクセスできるようにする必要があります。
Google Cloud Dataflow での TF-GNN サンプリングの起動
大まかに言うと、カスタム Docker コンテナを使用して Dataflow にジョブを push するプロセスは次のように可視化できます。
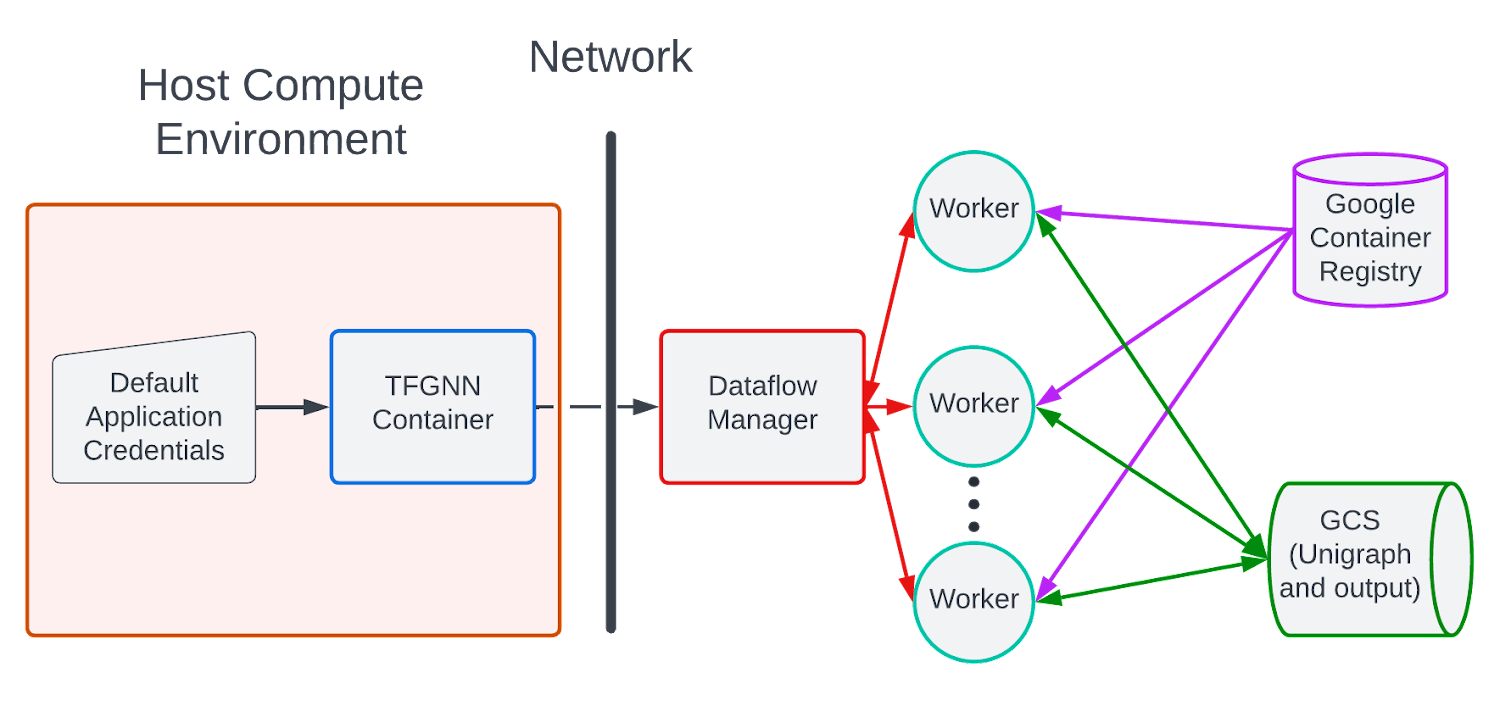
ユーザーは、ローカルマシンで TF-GNN の Docker イメージを構築し、その Docker イメージを GCR リポジトリに push して、GCP Dataflow サービスにパイプラインの仕様を送信します。パイプラインの仕様を GCP Dataflow サービスが受け取るとパイプラインが最適化され、Dataflow ワーカー(GCP VM)がインスタンス化され、ユーザーが GCR に push した TF-GNN イメージを pull して実行できます。
ワーカーの数は、デフォルトでパイプライン ステージのスループットをモニタリングする Dataflow 自動スケーリング アルゴリズムに従って自動的にスケールアップまたはスケールダウンされます。入力グラフは GCP でホストされ、サンプリング結果(GraphTensor 出力)は、Google Cloud Storage の *.tfrecord ファイルに書き込まれます。
このプロセスは、いくつかの変数を入力し、スクリプト(./gnn/tensorflow_gnn/examples/mag/sample_dataflow.sh)を実行することでインスタンス化できます。
これらの環境変数は、GCP プロジェクトのリソースと、Beam サンプラーが必要とする入力の場所を指定します。
TEMP_LOCATION 変数は、Dataflow ワーカーが共有スクラッチ スペースのために必要とするパスで、サンプルは最終的に $OUTPUT_SAMPLES(GCS の場所)でシャーディング済みの TFRecord ファイルへ書き込まれます。REMOTE_WORKER_CONTAINER は、カスタム TF-GNN イメージを指す適切な GCR URI に変更する必要があります。
GCP_VPN_NAME は、GCP ネットワーク名を保持する変数です。デフォルトの VPC は機能しますが、デフォルトのネットワークは公共のインターネットにアクセスできる IP を持つ Dataflow ワーカーマシンを割り当てます。これらのタイプの IP は、GCP の「使用中」の IP 割り当て範囲の対象としてカウントされます。Dataflow ワーカーの依存関係は Docker コンテナに付属しているため、ワーカーには外部インターネット アクセスのある IP は必要なく、外部インターネット アクセスのない VPC を設定することが推奨されます。詳しくはこちらをご覧ください。デフォルトのネットワークを利用する場合は、GCP_VPN_NAME=default を設定し、以下のコマンドから --no_use_public_ips を削除してください。
Dataflow tfgnn-sampler ジョブを起動する主要なコマンドは以下のとおりです。
このコマンドは、ユーザーのデフォルトのアプリケーション認証情報をマウントし、コンテナ ランタイムの $GOOGLE_CLOUD_PROJECT と $GOOGLE_APPLICATION_CREDENTIALS を設定し、tfgnn_graph_sampler バイナリを起動して、サンプラー DAG を Dataflow サービスに送信します。Dataflow ワーカーは GCR に保存されている tfgnn:latest イメージからランタイム環境を取得し、出力は GCS 上の $OUTPUT_SAMPLES の場所に配置され、TF-GNN モデルをトレーニングできるようになります。
- ソフトウェア エンジニア Brandon Mayer
- リサーチ サイエンティスト Bryan Perozzi



