Google のデータと AI の統合型プロダクトの紹介
Google Cloud Japan Team
※この投稿は米国時間 2022 年 4 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
AI がなければ、データを最大限に活用できません。
データがなければ、古くて時代遅れの、最適ではないモデルというリスクを負うことになります。
しかし、ほとんどの企業は、これらの高度に依存し合うテクノロジーの同期を保ち、AI を運用可能な状態にしてデータから有益なアクションを引き出すことに未だに苦慮しています。
AI 開発の長年の経験から、Google はデータと AI のワークフローを可能な限りまとまりのあるものにする方法を学びました。その結果、Google のデータクラウドは、市場で最も完成されたデータと AI の統合型ソリューション プロバイダとなりました。データと AI の橋渡しを行えば、データ アナリストはユーザー フレンドリーでアクセスが容易な ML ツールを活用できるようになり、データ サイエンティストは組織のデータを最大限利用できるようになります。これらすべてが組み込みの MLOps でひとまとめにされるため、チームをまたいで、すべての AI 関連の作業を本番環境での使用に適合させることができます。
このブログでは、Data Cloud Summit からのエキサイティングな発表に加え、これらのすべての作業の仕組みについて紹介します。
Vertex AI Workbench が一般提供となり、Google Cloud のデータシステムと ML システムが単一のインターフェースに一体化されました。チームは、データ分析、データ サイエンス、機械学習で 1 つの共通のツールセットを使用できるようになります。BigQuery、Spark、Dataproc、Dataplex とネイティブに統合されているため、データ サイエンティストは従来のノートブックの 5 倍の速さで ML モデルを構築、トレーニング、デプロイできます。
ML モデルのライフサイクルを管理するための一元型のリポジトリ、Vertex AI Model Registry の紹介。Vertex AI Model Registry は、BigQuery ML を含むあらゆるモデルのタイプ、デプロイ ターゲットで動作するように設計されているため、モデルの管理、デプロイが容易になります。
ML で、形式を気にすることなくデータを最大限に活用
BigQuery で SQL を使用するなど、データ ウェアハウスの構造化データを分析することは、多くのデータ アナリストの本業と言えます。データベースにデータを用意すると、トレンドの確認やレポートの生成が行えるようになるとともに、ビジネスをより効果的に把握できるようになります。ただ残念なことに、有用なビジネスデータの多くは、行と列からなる整然とした表形式にはなっていません。「構造化されていないデータ」と称されることの多い画像、動画、音声の文字起こし、PDF などのデータは煩雑で取り扱いが難しく、多くの場合は複数の場所に散在し、形式が異なることもあります。
ここで、AI が役に立ちます。ML モデルは、音声や動画の文字起こし、言語の分析、画像からのテキスト抽出に利用できるため、構造化されていないデータの要素を、BigQuery などのデータベースに保存してクエリを実行できる形式に変換できます。たとえば、Google Cloud の Document AI プラットフォームでは、フォームや契約書などのドキュメントを把握するために ML が利用されています。以下は、このプラットフォームで構造化されていないドキュメント(履歴書など)から構造化されたテキストデータをインテリジェントに抽出する方法を示しています。抽出したデータは、BigQuery などのデータ ウェアハウスに保存できます。
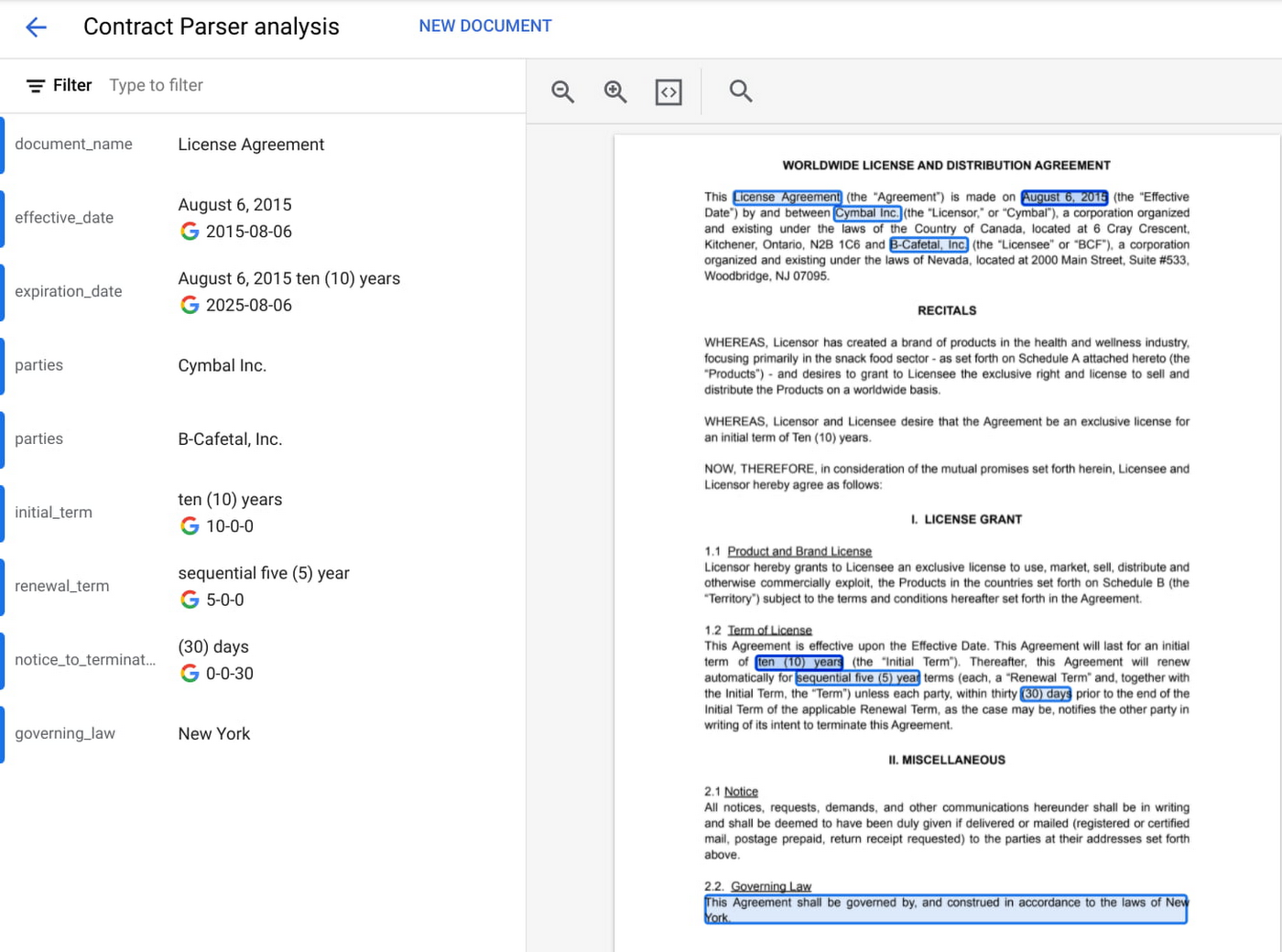
使い慣れたツールを通じて、機械学習をデータ アナリストの手元に届ける
今日における ML の最大の障壁の一つは、ML を行うために必要となるツールやフレームワークが新しく、不慣れな場合もあるということです。しかし、そうではない場合もあります。たとえば BigQuery ML では、BigQuery 内で SQL コードを直接使用して、洗練された ML モデルを大規模にトレーニングできます。データ ウェアハウスに ML を組み込むことで、追加のインフラストラクチャのセットアップやモデルコードの作成に伴う複雑さを低減できます。SQL コードを書ける人であれば、誰でも ML モデルを迅速かつ簡単にトレーニングできます。

統合されたノートブック インターフェースで、データに簡単にアクセス
今日の最も一般的な ML インターフェースとして、コードの作成、データの可視化と前処理、モデルのトレーニングなどが行えるインタラクティブ環境、ノートブックがあります。データ サイエンティストが、ノートブック環境でのモデル構築に 1 日の大半を費やすことはよくあることです。そのため、ノートブック環境から、組織で実行するすべてのデータだけでなく、そのデータを簡単に操作できるツールにアクセスできることが重要になります。
一般提供となった Vertex AI Workbench は、データ サイエンス ワークフロー全体のための単一の開発環境です。Google Cloud のデータ ポートフォリオにまたがるインテグレーションのおかげで、サービス間の切り替えを行うことなくデータをネイティブに分析できます。
Cloud Storage: 構造化されていないデータへのアクセス
BigQuery: SQL でのデータへのアクセス、BigQuery ML でトレーニングされたモデルを活用
Dataproc: 管理用の Dataproc クラスタを使用してノートブックを実行
Spark: 自動スケーリングのサーバーレス Spark でデータを変換、準備
以下は、Vertex AI Workbench で BigQuery データに対して SQL クエリを簡単に実行する方法を示しています。
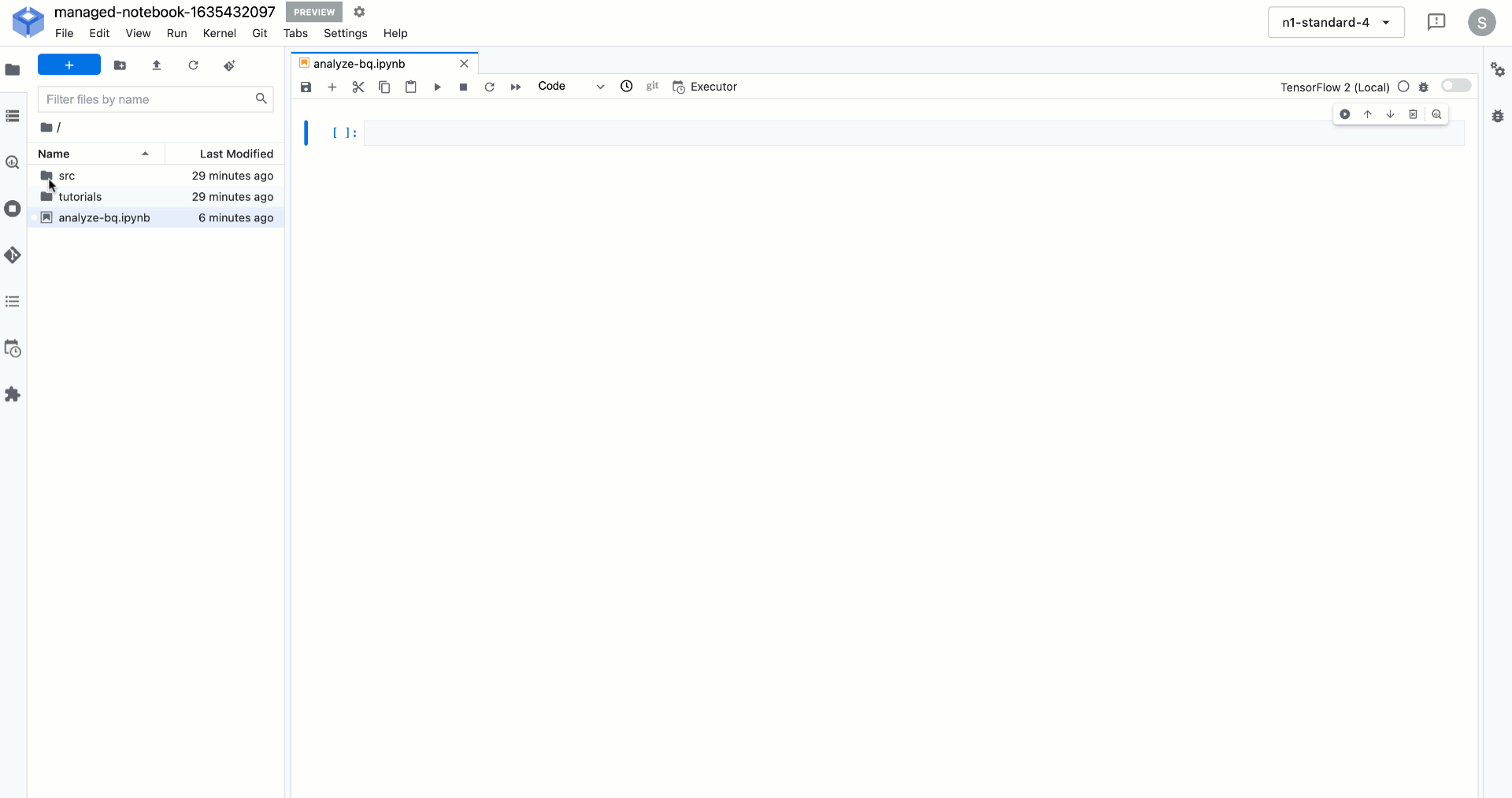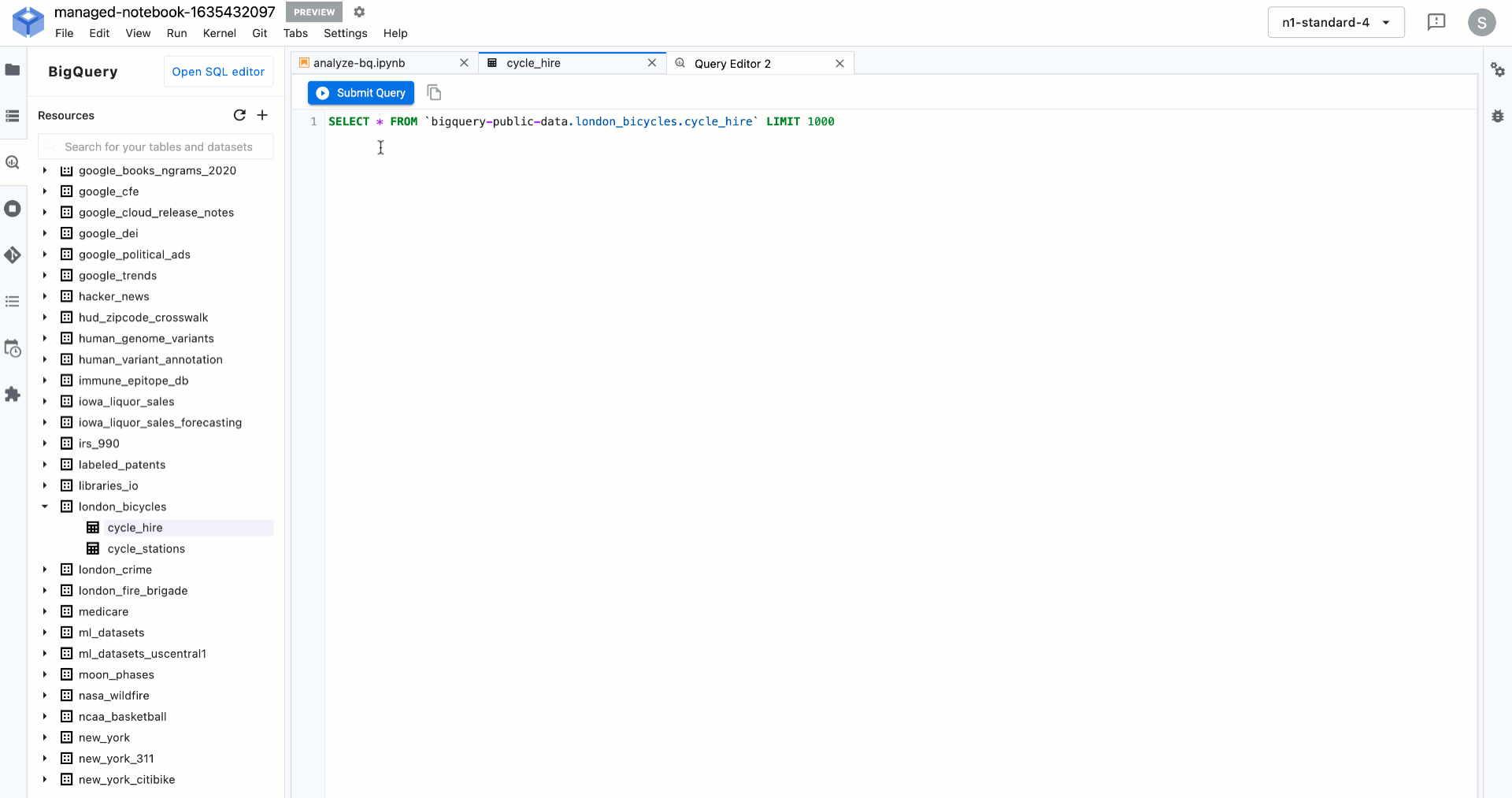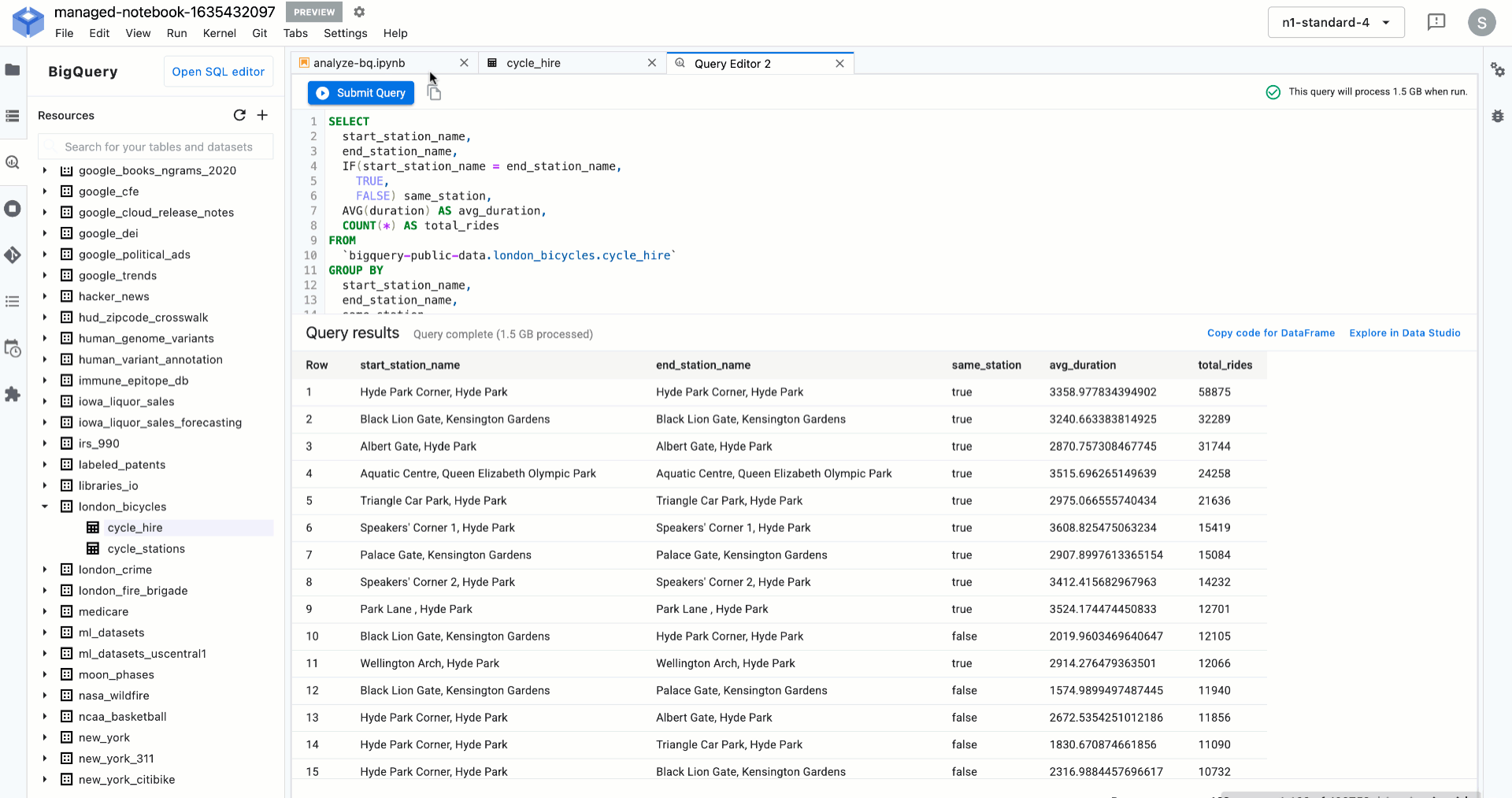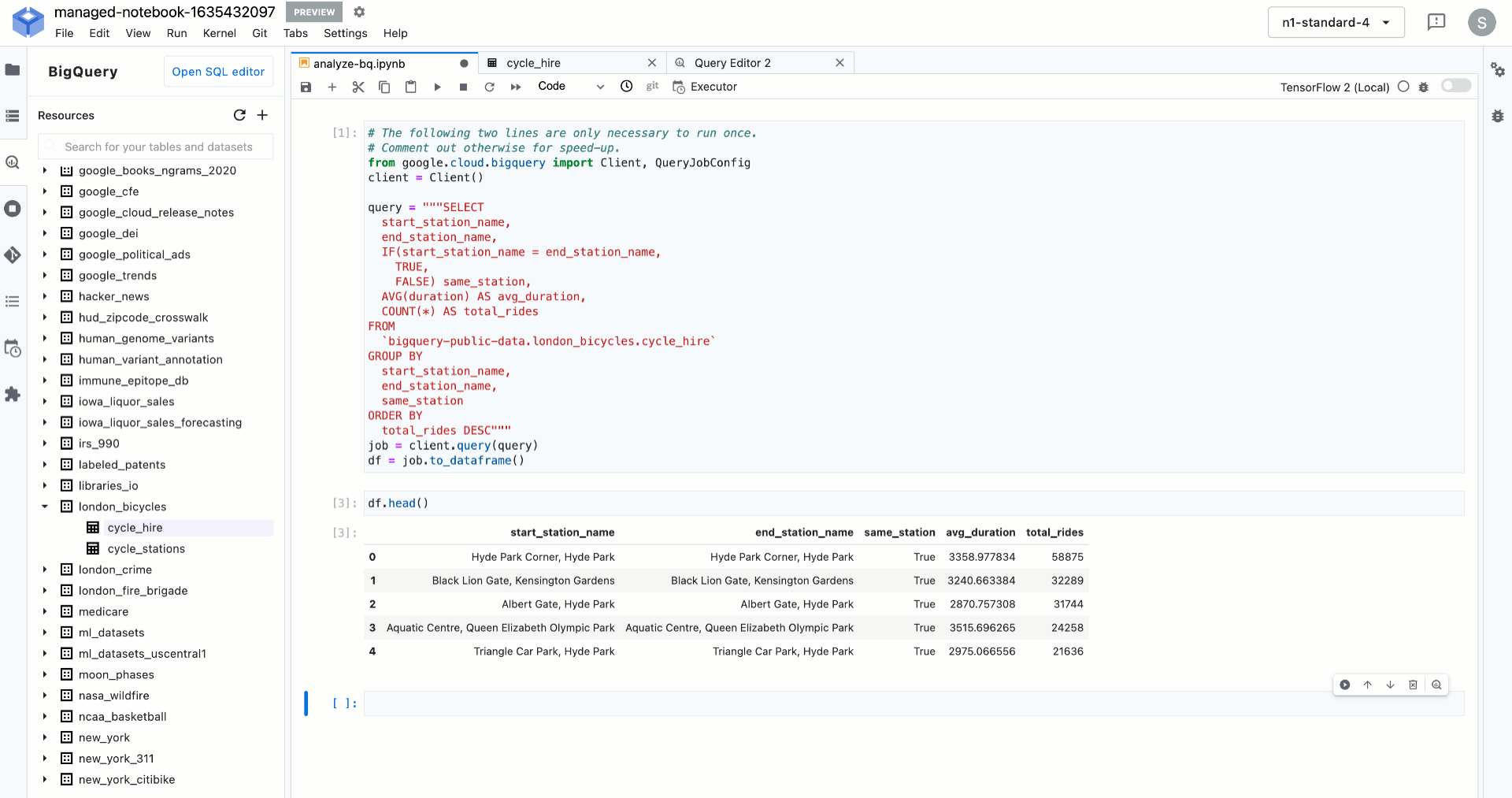
ところで、モデルをトレーニングした後はどうなるのでしょうか?データ アナリストやデータ サイエンティストは、アプリケーション デベロッパーがそのモデルを利用可能で、今後にわたり管理可能であることをどのようにして確認すればよいでしょうか?
MLOps でプロトタイピングから本番環境へ移行
正確なモデルをトレーニングすることも重要ですが、本番環境でそのモデルをスケーラブルで、復元力が高く、正確なものにする独自の手法(MLOps)も重要です。MLOps では次のことができます。
モデルのトレーニングで使用されたデータを把握する
本番環境のモデルをモニタリングする
トレーニング プロセスを繰り返し可能なものにする
モデル予測への対応とスケーリング
他にも数多くの可能性があります!(MLOps の詳しい概要の全文については、「Practitioners Guide to MLOps」のホワイトペーパーをご覧ください。)
Vertex AI の統合プラットフォーム内の組み込み MLOps ツールであれば、モデル管理の複雑さを解消できます。実践的なツールであれば、ML モデルのトレーニングとホスティング、モデル メタデータの管理、ガバナンス、モデルのモニタリング、パイプラインの実行など、ML を本番環境で大規模に実行するために重要となるあらゆる要素に役立てられます。
そして、Google はその機能を拡張し、組織で ML を使う誰もが MLOps にアクセスできるようにしています。
Vertex AI Model Registry で、MLOps への引き継ぎを簡単に
本日 Google は、トレーニング済みの ML モデルを登録、整理、追跡、バージョニングするための一元化されたリポジトリ、Vertex AI Model Registry を発表いたします。あらゆるモデルのタイプ、デプロイ ターゲットで動作するように設計されており、BigQuery、Vertex AI、AutoML、GCP のカスタム デプロイに加え、クラウド外でも動作します。
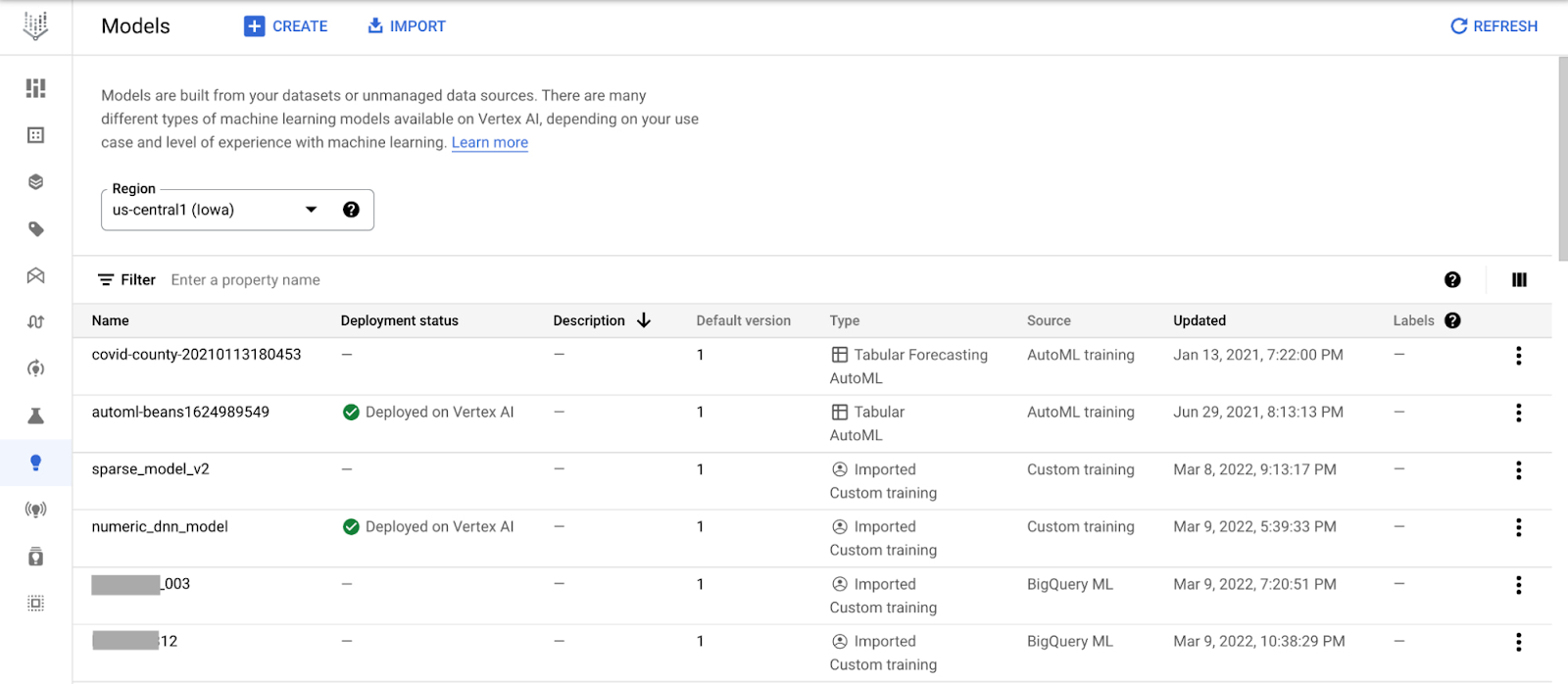
Vertex AI Model Registry は、BigQuery ML で特に役立ちます。BigQuery ML では、バッチ予測用の BigQuery の強力なスケーラビリティを利用できるものの、リアルタイム予測でデータ ウェアハウス エンジンを使用することは実用的ではありません。また、BigQuery をベースとした ML ワークフローをどのようにオーケストレーションするかについて、疑問に思っているかもしれません。しかし今では、BigQuery ML モデルを検出して管理し、それらのモデルを Vertex AI に簡単にデプロイすることで、リアルタイム予測と MLOps のツールとして利用できます。
パイプラインによるエンドツーエンドの MLOps
MLOps で一般的な手法の一つに、ML パイプラインの考え方があります。この手法では、データ準備から、モデルのトレーニング、デプロイまでの ML ワークフローのそれぞれのステップが自動化され、共有と確実な再現が可能となります。
Vertex AI Pipelines は、事前構築済みのコンポーネントか独自のカスタムコードを使用して ML タスクをオーケストレーションするためのサーバーレス ツールです。今では、パイプライン内で直接、BigQuery、BigQuery ML、Dataproc でデータ処理とモデルのトレーニングを行えます。この機能と、馴染みのある ML 開発を、BigQuery および Dataproc 内で組み合わせて、再現可能な復元力の高いパイプラインを構築し、これまでにない速さで ML ワークフローをオーケストレーションできます。
これが、新しい BigQuery および BigQuery ML コンポーネントとどのように連携するかを示す例をご覧ください。
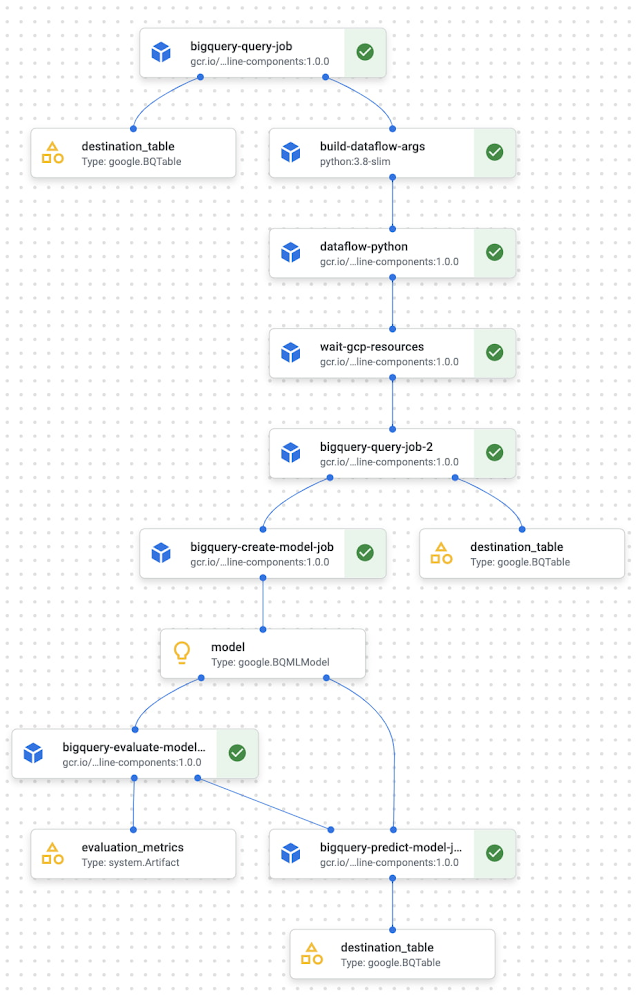
BigQuery および BigQuery ML コンポーネントを Vertex AI Pipelines と一緒に使用する方法の詳細をご覧ください。
詳細をご確認の上ご利用ください
Google のデータと AI の統合型プロダクトの詳細については、Data Cloud Summit で本日発表いたします。「AI / ML の戦略とプロダクト ロードマップ」のスポットライト セッション、あるいは、AI / ML ノートブックの「ハウツー」セッションにぜひご参加ください。
Vertex AI を実際に使う準備ができている場合は、以下のリソースをご確認ください。
Codelab: Vertex AI での AutoML モデルのトレーニング(英語)
Codelab: Vertex AI Workbench の概要(英語)
動画シリーズ: AI の基礎: Vertex AI
GitHub: サンプル ノートブック
トレーニング: Vertex AI: Qwik Start
- デベロッパー アドボケイト Polong Lin



