Announcing BigQuery and BigQuery ML operators for Vertex AI Pipelines
Polong Lin
Developer Advocate
Ivan Nardini
Developer Relations Engineer
Developers (especially ML engineers) looking to orchestrate BigQuery and BigQuery ML (BQML) operations as part of a Vertex AI Pipeline have previously needed to write their own custom components. Today we are excited to announce the release of new BigQuery and BQML components for Vertex AI Pipelines, that help make it easier to operationalize BigQuery and BQML jobs in a Vertex AI Pipeline. As official components created by Google Cloud, using these components will allow you to more easily include BigQuery and BigQuery ML as part of your Vertex AI Pipelines. For example, with Vertex AI Pipelines, you can automate and monitor the entire model life cycle of your BQML models, from training to serving. In addition, using these components as part of a Vertex AI Pipelines provides extra data and model governance, as each time you run a pipeline, Vertex AI Pipelines tracks any artifacts produced automatically.
For BigQuery, the following components are now available:
Allows users to submit an arbitrary BQ query which will either write to a temporary or permanent table. Launch a BigQuery query job and wait for it to finish. |
For BigQuery ML (BQML), the following components are now available:
Allow users to submit a DDL statement to create a BigQuery ML model. | |
Allows users to evaluate a BigQuery ML model. | |
Allows users to make predictions using a BigQuery ML model. | |
Allows users to export a BigQuery ML model to a Google Cloud Storage bucket |
Learn how to create a simple Vertex AI Pipeline train a BQML model, and deploy the model to Vertex AI for online predictions:
In addition to the notebook above, check out the end-to-end example of using Dataflow, BigQuery and BigQuery ML components to predict the topic label of text documents using BQML and Dataflow.
End-to-end example using BigQuery and BQML components in a Vertex AI Pipeline
In this section, we'll show an end-to-end example of using BigQuery and BQML components in a Vertex AI Pipeline. The pipeline predicts the topic of raw text documents by first converting them into embeddings using the pre-trained Swivel TensorFlow model with BQML. Then, it trains a logistic regression model in BQML using the text embeddings to predict the label, which is the topic of the document. For simplification, the model will just predict if the topic is equal to "acq" (1) or not (0), where "acq'' means that document is related to the topic of "corporate acquisitions'' as defined in the dataset.
Below you can see a high level picture of the pipeline
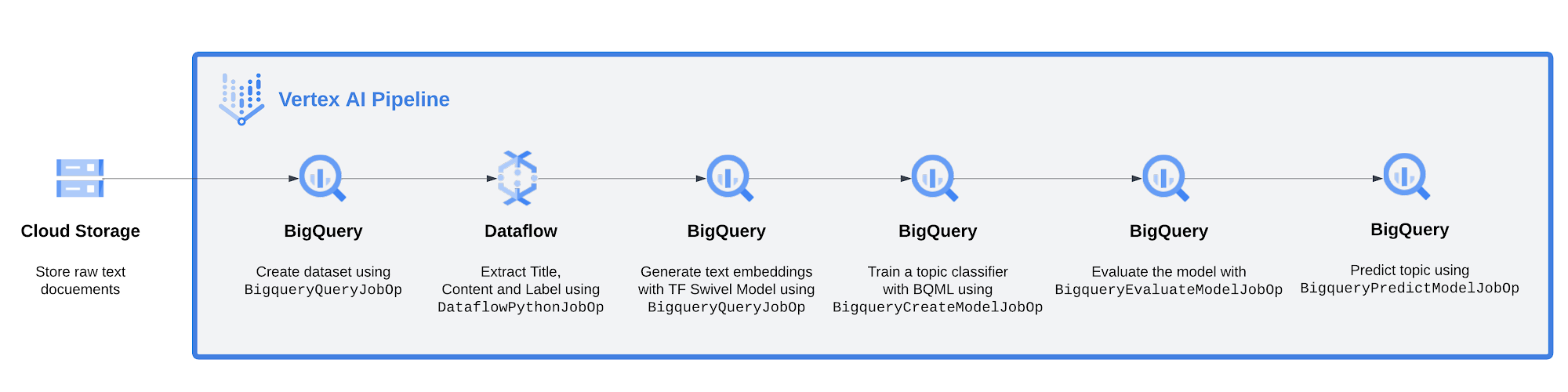
From left to right:
Start with news-related text documents stored in Google Cloud Storage
Create a dataset in BigQuery using
BigqueryQueryJobOpExtract title, content and topic of (HTML) documents using Dataflow and ingest into BigQuery
Using BigQuery ML, apply the Swivel TensorFlow model to generate embeddings for each document’s content
Train a logistic regression model to predict if a document's embedding is related to a pre-defined topic (1 if related, 0 if not)
Evaluate the model
Apply the model to a dataset to make predictions
Let’s dive into them.
ETL with DataflowPythonJobOp component
Imagine that you have raw text documents from Reuters stored in Google Cloud Storage (GCS). You want to preprocess them and import the text into BigQuery to train a classification model using BQML.
First, you will need to create a BQ dataset, which you can do by running the SQL queryCREATE SCHEMA IF NOT EXISTS mydataset. In a Vertex AI Pipeline you can execute this query within a BigqueryQueryJobOp.For the full code, please see this notebook.
Aftering creating the dataset, you will need to prepare the text documents for model training. Importantly, you would need to parse out the relevant sections ("Title", "Body", "Topics") of text from the raw documents. In our case we use a Beam pipeline on Dataflow which uses the Beautiful Soup (bs4) library in Python to extract the following:
Title, the title of the article
Body, the full text content of the article
Topics, one or more categories that the article belongs to
For the full code, please see this notebook.
To clarify what's happening in the component above, the requirements_file_path contains the GCS bucket URI to a requirements file, the python_module_path contains the bucket uri to the Apache Beam pipeline python script and args contains a list of arguments that are passed via the Beam Runner to your Apache Beam code. Also notice that WaitGcpResourcesOp is required, which allows the pipeline to wait for the component to finish execution before continuing to the next part of the pipeline.
Feature Engineering with BigqueryQueryJobOp and DataflowPythonJobOp
Once the documents have been pre-processed in Dataflow, the next step is to generate text embeddings from the pre-processed documents. The embeddings can then be used to as training data for the logistic regression model to predict the topic.
To generate embeddings from text, you can use the Swivel model, which is a pre-trained TensorFlow model publicly available on TensorFlow Hub. How do you use a pre-trained TensorFlow SavedModel on text in BigQuery? You can import it using BQML and apply it to the text of our documents to generate the embeddings. Then you split the dataset to get the training sample you will consume into the text classifier.
The following shows what the component looks like in the pipeline:
For the full code, please see this notebook.
Where bq_preprocess_query contains the preprocessing query, project and location where the BigQuery job runs.
bq_preprocess_query, the first step will be to import the Swivel model using BigQuery ML. And a step thereafter is to retrieve the embeddings, which serves as the training data for the document classifier model in the next section.For the full code, please see this notebook.
Training a document classifier with BigqueryCreateModelJobOp
Now that you have the training data (as a table), you are ready to build a document classifier, using logistic regression to determine if the label of the document is 'acq' or not, where 'acq' means that the document is related to the topic of "corporate acquisitions". You can automate this BQML model creation operation within a Vertex AI Pipeline using theBigqueryCreateModelJobOp. This component allows you to pass the BQML training query and, in case you need, parameterize it and the job associated in order to schedule a model training on BigQuery. The component returns a google.BQMLModel which also tracks the BQML model automatically using Vertex ML Metadata which provides extra insight into model and data lineage.For the full code, please see this notebook.
Evaluate the model using BigqueryEvaluateModelJobOp
Once you train the model, you would probably evaluate it before deploying into production for generating predictions. With theBigqueryEvaluateModelJobOp, you just need to pass the google.BQMLModel output you received from the previous training BigqueryCreateModelJobOp and it will generate various evaluation metrics, based on the type of the model. In our case we get precision, recall, f1_score, log_loss and roc_auc which are available in the lineage of pipeline in the Vertex ML Metadata.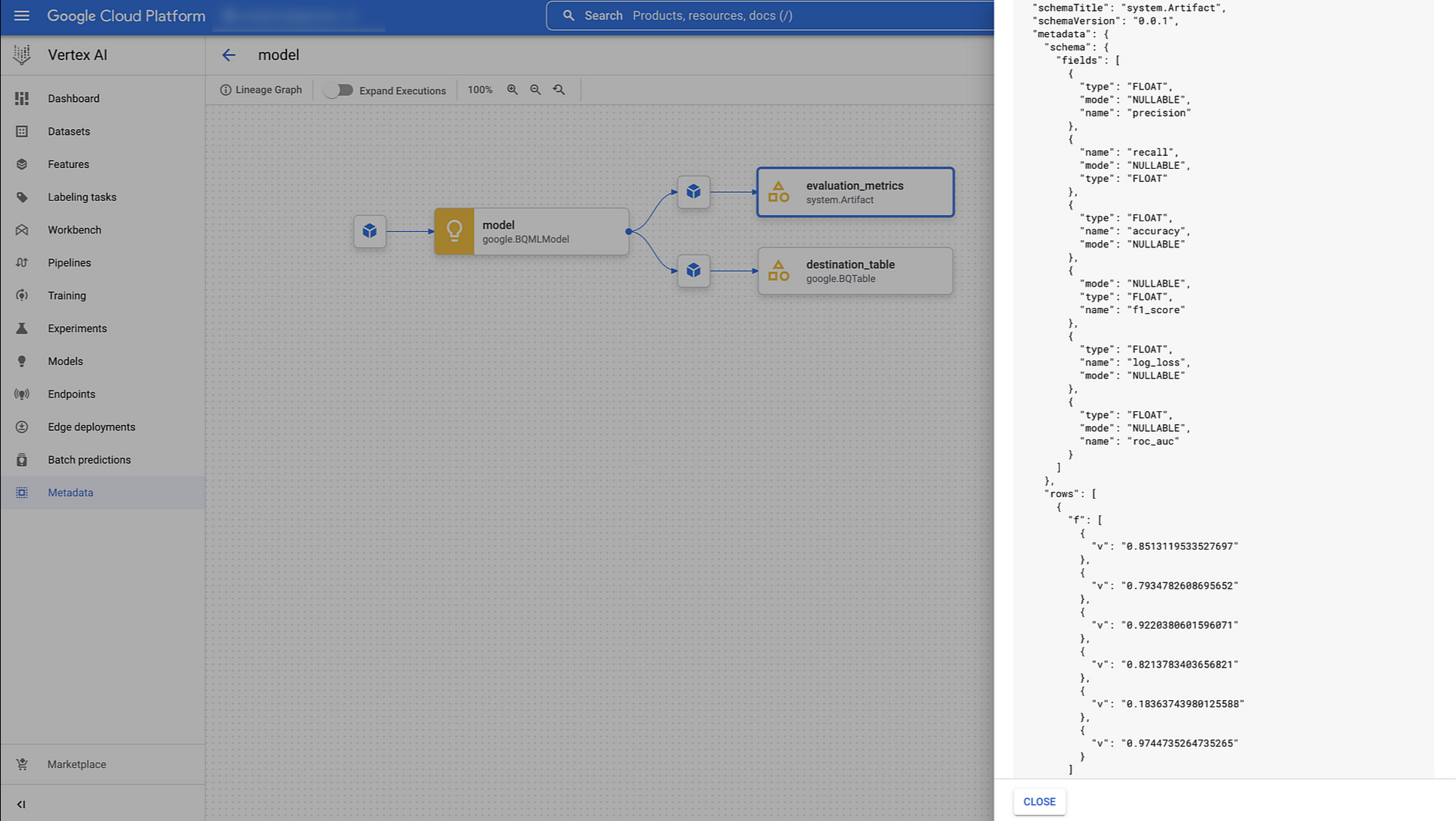
Notice that, thanks to these components, you can implement conditional logic in order to decide what you want to do with the model downstream. For example, if the performance is above a certain threshold, you can have the pipeline proceed to make predictions directly with BigQuery ML, or register your model into a model registry service, or deploy the model to a staging endpoint. This will really depend on the logic you want to implement with your ML pipeline.
In this example pipeline with document classification, you'll just be generating batch predictions directly without conditional logic.
Predict using BigqueryPredictModelJobOp
In order to operationalize BQML model prediction, the bigquery module of google_cloud_pipeline_components library provides you the BigqueryPredictModelJobOp which allows you to launch a BigQuery predict model job by consuming the google.BQMLModel of the training component.
For the full code, please see this notebook.
In this component, you also pass in a job_config in order to define the destination table (project ID, dataset ID and table ID) beyond the query statement to format the columns you want to have in the prediction table.
Below you can see the visualization of the overall pipeline you get in the Vertex AI Pipelines UI.
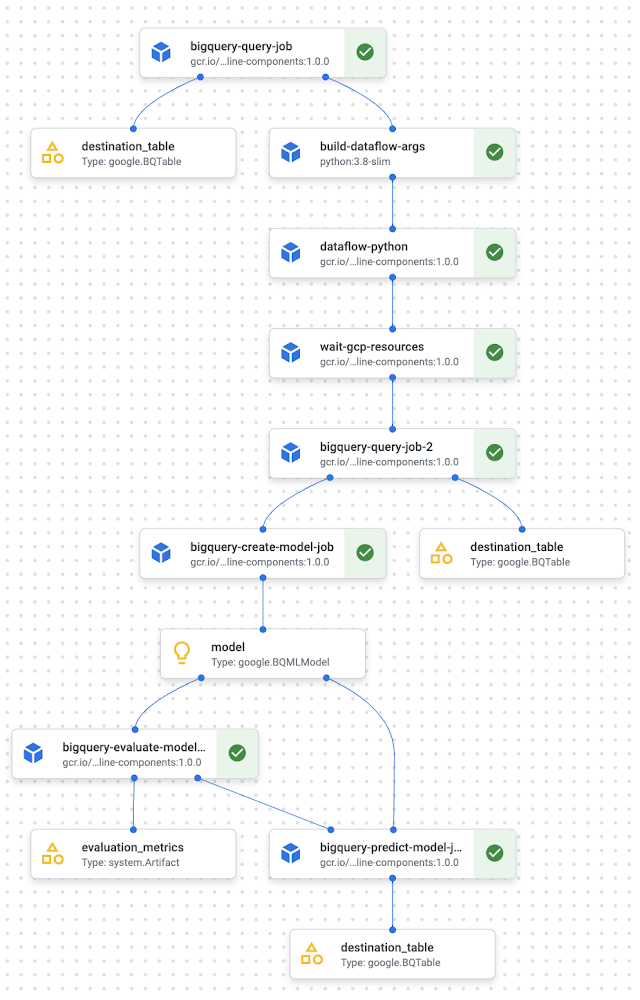
Conclusion
In this blogpost, we described the new BigQuery and BQML components now available for Vertex AI Pipelines. We also showed an end-to-end example of using the components for document classification involving BigQuery ML and Vertex AI Pipelines.
What’s Next
Are you ready for running your BQML pipeline with Vertex AI Pipelines? Check out the following resources and let give it a try:
Documentation
Code Labs
Video Series: AI Simplified: Vertex AI
Quick Lab: Build and Deploy Machine Learning Solutions on Vertex AI
References
Special thanks to Bo Yang, Andrew Ferlitsch, Abhinav Khushraj, Ivan Cheung, and Gus Martins for their contributions to this blogpost.




