チューニングすべきか否か: LLM でデータを活用するためのガイド
Kamilla Kurta
Customer Engineer, AI/ML Specialist
Filipe Gracio PhD
Customer Engineer, AI/ML Specialist
※この投稿は米国時間 2024 年 5 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
カスタマー エクスペリエンスの向上、社内プロセスの自動化、情報へのアクセスと検索、新規コンテンツの作成など、生成 AI は多種多様なユースケースで使用されるようになっています。Google をご利用のお客様は、大規模言語モデル(LLM)とデータの活用によるこれらのユースケース実現に大きな期待を寄せておられます。LLM では、お客様が社内に保有している独自のデータをさまざまな方法で活用できます。そこでこのブログ投稿では、データ活用の主なアプローチと用途、そして開始する際に知っておくべき事項について説明します。
基盤モデルでデータを活用する方法
具体的な生成 AI アプリケーションの姿を思い描く前に、まず LLM やその他の基盤モデルでデータをどのように活用できるかについて理解する必要があります。
プロンプト エンジニアリング
指示(システム プロンプト)にデータを組み込み、モデルに送り込むのが、モデルでデータを活用するための最も簡単な方法です。プロンプト エンジニアリングでは、モデルを変更したり、データに適応させたりする必要はないため、非常に強力で使い勝手の良い方法と言えますが、逆にこのアプローチを有効に活用できないユースケースもあります。たとえば、静的な情報であればシステム プロンプトに簡単に追加し、その情報に基づき対話を進めることができますが、スポーツのスコアや航空券の価格など、頻繁に更新される情報は簡単に組み込むことができません。
検索拡張生成(RAG)
検索拡張生成(RAG)では、データに基づきモデルの出力を生成できます。AI アプリケーションを RAG 対応の設計とすることにより、モデルのトレーニングに使用された知識にのみ頼るのではなく、クエリに関連する情報をデータから引き出し、その情報をプロンプトに渡すことができます。プロンプト エンジニアリングと似ている面もありますが、RAG では、対話が行われるたびに、データを検索して新たなコンテキストを引き出すことができます。
RAG のアプローチは、常に更新される最新のデータ、接続するプライベート データ、大規模なマルチモーダル データなど、さまざまなタイプのデータをサポートします。RAG は、データベースとの単純な統合から、カスタマイズされたシステムにおけるエンベディング API やその他のコンポーネントに至るまで、多種多様なプロダクトによってますます強固になったエコシステムでサポートされるようになっています。
教師ありファインチューニング(SFT)
明確に定義されたタスクにおいて、具体性の高い指示をモデルに与える場合、SFT を使用できます。SFT はパラメータ エフィシエント ファインチューニング(PEFT)とも呼ばれます。このアプローチは、分類タスクや、自由に入力されたテキストから構造化された出力を作成するタスクなどに適しています。
教師ありファインチューニングを実施するためには、モデルに入出力のペアを指定し、そのペアに基づきモデルを学習させる必要があります。たとえば、会議の文字起こしの内容を「マーケティング」「法務」「カスタマー サポート」などのさまざまなカテゴリに分類する場合、教師ありファインチューニングのプロセスに対して、会議の文字起こしとカテゴリのペアを複数指定する必要があります。チューニングのプロセスは、会議の正しい分類を示すこのデータに基づいて学習します。
人間からのフィードバックを用いた強化学習(RLHF)
では、目標とするものを明確にカテゴリとして分類できず、定量化することが難しい場合はどうでしょう。たとえば、ブランドに適したトーンや、状況に合わせた礼儀正しいトーンが必要な場合など、モデルの回答を特定のトーンにしたい場合があります。人間からのフィードバックを用いた強化学習(RLHF)は、このような人間の好みを反映させる形で強化学習を行い、特定のニーズに合わせてチューニングされたモデルを作成する手法です。
簡単に説明すると、RLHF のアルゴリズムでは入力プロンプトと出力の回答という形式でデータを指定しますが、出力の回答には、好みを反映した回答と好みを反映していない回答の 2 つの考えられる回答のペアを含めます。たとえば、一方を内容は正しいが汎用的な回答とし、他方を内容が正しくかつ出力に求める言語スタイルに沿った回答とします。
蒸留
蒸留とは、データを迅速かつ速やかに処理できる、より小さいモデルを作成するとともに、実行するタスクに特化したモデルとするという 2 つの目的を巧みに組み合わせた手法です。大きな基盤モデルを使用して小さなモデルを学習させ、データやタスクに特化した内容に学習を絞り込むのが蒸留の特徴です。たとえば、すべてのメールを再確認して、改まった文体に書き換えたいとします。これを、より小さなモデルを使用して行います。そのためには、まず大きなモデルに入力(元のメールのテキストと、「このメールを改まった文体にして」という指示)を指定します。すると、大きなモデルから出力(書き換えられたメール)が得られます。次に、この入力と大きなモデルからの出力を使用して、メールの書き換えに特化した小さなモデルのトレーニングを行い、この特定のタスクを再現できるように学習させます。基盤モデルの入出力のペアに加えて、独自のペアを指定することもできます。
どの方法を選ぶべきか
まず、モデルが基盤となるデータソースから引用して回答を生成する必要があるかを考えます。その必要があれば、RAG をおすすめします。RAG には、基盤となるデータのうちどのデータに誰がアクセスできるかを制御できるメリットもあります(モデルを呼び出したユーザーごとにアクセスを制御できます)。RAG により、ハルシネーションを防止し、解釈しやすい結果を生成できます。
このような要件がない場合は、プロンプト エンジニアリングで十分か、あるいはモデルのチューニングが必要かを判断する必要があります。データ量が少ない場合は、プロンプト エンジニアリングで十分な可能性があります。100 万トークンのコンテキスト ウィンドウを備える Gemini 1.5 のように、コンテキスト ウィンドウは拡大し続けており、大量のデータを扱う場合でもプロンプト エンジニアリングが有効な手法となりつつあります。
チューニングを行う場合、目的とするモデルの動作の特殊性、そして定量化の難しさによって選択すべきチューニングが異なります。明確に表すことが難しい回答をモデルから出力したい場合は、おそらく人間の関与が必要なため、RLHF が適しています。それ以外の場合は、モデルのカスタマイズの必要性、予算、必要なサービング スピードに応じてチューニング方法を選びます。
以下に、ここで説明した方法の選び方について、簡単にディシジョン ツリーとしてまとめました。
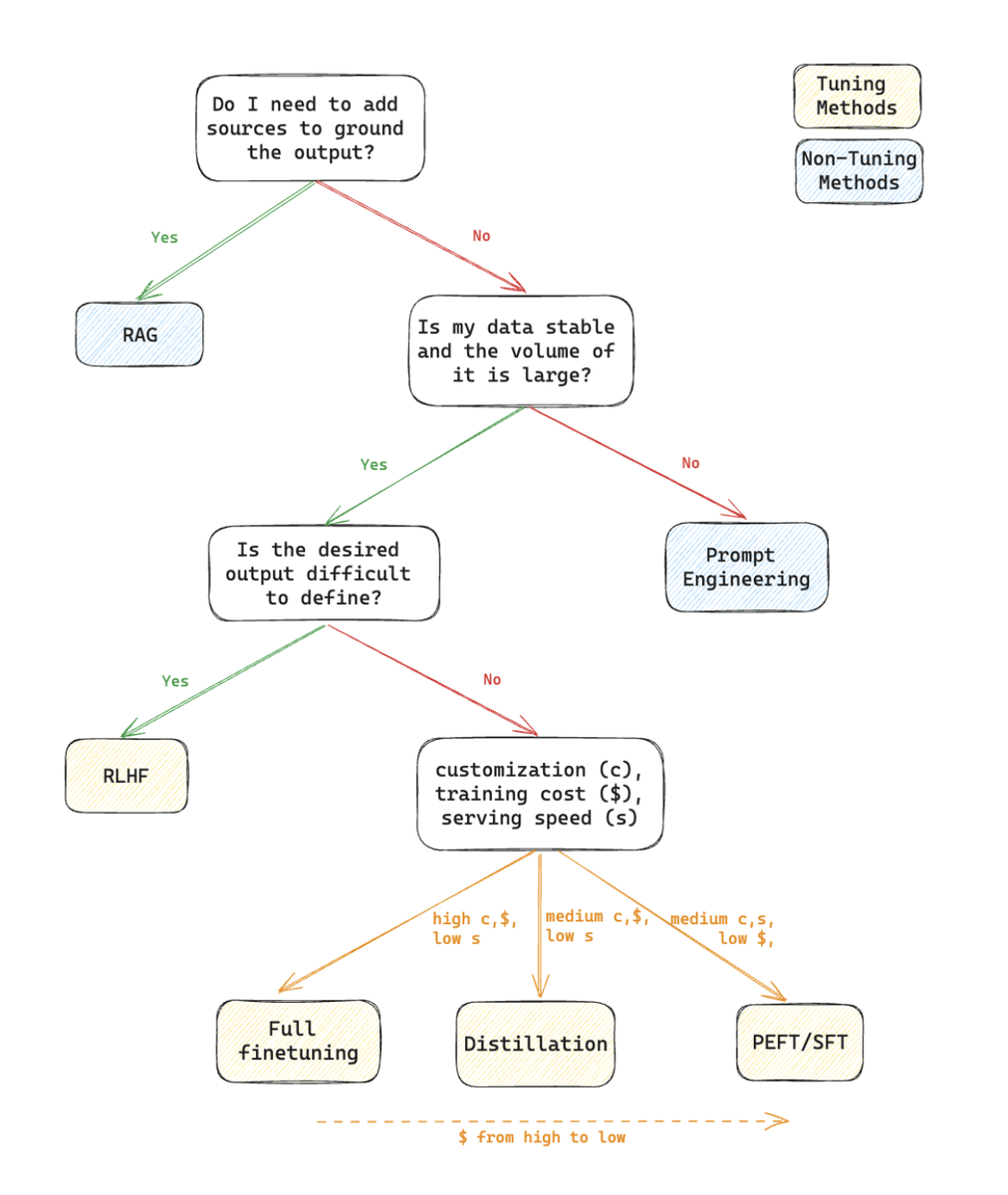
これらを組み合わせる方法も
これらの方法を組み合わせて使用したいというニーズもあるかもしれません。たとえば、ブランドのトーンに合わせてモデルをファインチューニングするとともに、自社のデータのみを使用して回答を生成したい(RAG を使用したい)場合もあるでしょう。このように組み合わせて使用することは可能です。むしろ、必要に応じて組み合わせて使用することをおすすめします。たとえば、チューニングしたモデルを、別のタスクの実行に使用できます。あるいは、LLM をチューニングしたうえで、コンテキストに沿ったプロンプト エンジニアリングを行うことにより、求めるモデルの動作を実現することもできます。要するに、ここで紹介した方法は、ニーズに応じて自由に組み合わせることが可能です。
使ってみる
まずはシンプルなものから手を付けてみましょう。それにより、短時間で成果を上げることができるだけでなく、実験やテストを通してアプリケーションに最適な方法を見極めるためのたたき台として利用できます。
これらすべての機能は Google Cloud で試すことができます。プロンプト エンジニアリングや Vertex AI Agent Builder による RAG の実装を使用できるほか、独自に RAG を実装したい場合は、エンベディングを使用するか、または Multimodal Embeddings API を使用してエンベディングを作成し、ベクトル検索に保存できます。その他にも、教師ありファインチューニング、RLHF によるチューニング、蒸留もお試しいただけます。便利なコードサンプルもご活用ください。
-カスタマー エンジニア兼 AI / ML スペシャリスト Kamilla Kurta
-カスタマー エンジニア兼 AI / ML スペシャリスト Filipe Gracio 博士



