単一のクラウド環境内で ML 研究の共同プロジェクトを実施
Andika Rachman
AVP, Head of AI, Bank Rakyat Indonesia
Yoga Yustiawan
AI Research Lead, Bank Rakyat Indonesia
※この投稿は米国時間 2024 年 5 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
インドネシアと東南アジアで最大規模の銀行である Bank Rakyat Indonesia(BRI)は、中小企業とマイクロファイナンスに重点を置いています。BRI は、デジタル バンキングとデジタル化を実現するために、デジタル バンキング開発および運用部門を設立しました。この部門内では Digital BRIBRAIN という部署が、顧客エンゲージメント、信用審査、不正対策とリスク分析、ビジネスチームと運用チーム向けのスマート サービスと運用に及ぶ幅広い AI ソリューションを開発しています。
Digital BRIBRAIN では、AI リサーチチームが BRIBRAIN Academy などのプロジェクトに取り組んでいます。BRIBRAIN Academy は高等教育機関との共同イニシアチブで、銀行や金融における AI と ML を育成し、BRI の AI 機能を拡張して、学術コミュニティに貢献することを目的としています。このプログラムにより、提携大学の学生は、不公平なバイアスと公平性、Explainable AI、グラフ ML、フェデレーション ラーニング、統合プロダクトのレコメンデーション、自然言語処理、コンピュータ ビジョンなどのトピックから選択して、金融業界における AI の応用を学ぶことができます。
BRI は Google Cloud と長年にわたり連携し、Vertex AI テクノロジーを他のユースケースに実装していたことから、提携大学との研究活動にサンドボックス環境を提供するために Google Cloud のプロダクトとサービスを選びました。この研究では、以下のような幅広いユースケースとコンセプトを対象としています。
1. 銀行におけるクレジット スコア調査の公平性に関する分析
銀行やその他の金融機関は、ローンを申請した個人または組織の信用リスクを判断するために業界全体でクレジット スコアを利用しています。かつて、これは統計的手法や過去のデータを使用した手動および紙ベースのプロセスでした。クレジット スコア プロセスに自動化を適用すると大きなメリットを得られる可能性がありますが、責任を持って適用できる場合に限られます。
クレジット スコアに対する AI の使用においては、アルゴリズムの不公平性に関する懸念事項が存在し、明確に文書化されています。プロバイダはクレジット スコア AI モデルで使用されている変数を把握し、主流ではないグループの間で異なるモデル出力が発生するリスクを軽減するために対策を講じる必要があります。不公平なバイアスが適切に軽減されるソリューションを業界で実現できるように、BRIBRAIN Academy の研究プロジェクトの一つとしてクレジット スコアの公平性に関する分析に取り組むことにしました。
公平性は状況によって意味が異なります。金融機関とローン申請者にとって良くない結果を最小限に抑えるために、人口学的等価性の差と均等オッズの差という 2 つの公平性の制約を利用してモデルのバイアスを測定し、後処理アルゴリズムと削減アルゴリズムで不公平なバイアスを削減しました。その結果、公平性の人口学的等価性が 0.127 から 0.0004 に、均等オッズが 0.09 から 0.01 に改善されました。BRI がこれまで行ってきたすべての作業は、まだ研究と探索の段階にあり、公平性を向上させるために対処する必要がある制約を引き続き特定しています。
2. Explainable AI による、クレジット スコアを目的とした ML モデルの意思決定の解釈
過去のデータは、申請の信用度を評価するモデルをトレーニングするために使用されます。ただし、こうしたデータは透明性が欠如しているため、把握が困難になりやすく、他の人が AI モデルによる結果や予測を解釈できるようにする機能がより一層重要になってきています。
モデルの動作を正確に表現し、憂慮している関係者の信頼を得る説明が重要です。Explainable AI を使用すると、クレジット スコアが作成される仕組みについて理解を深めることができます。モデルに組み込んだ特徴を、さまざまなクレジット スコアの決定のためのフィルタとして使用することもできます。この共同研究を実施するには、データの保存と維持のための厳格なアクセス制御を備えた安全なプラットフォームを活用する必要がありました。
3. グラフ ML を使用した金融 chatbot の感情分析
chatbot は人間の会話をシミュレートするコンピュータ プログラムであり、ユーザーはチャット インターフェースを介してやり取りします。chatbot によっては、ユーザーの言葉やフレーズを解釈して処理し、事前に設定された回答を即座に返すことができますが、その際に感情を把握しません。
残念ながら、単語間の関係性が認識されないため、文脈を無視したレスポンスになることがあります。このため、グラフ特徴表現学習による前処理を通じて単語間の関係性を学習できる chatbot データを表現する必要がありました。こういった方法は、「Bag-of-Words(BOW)モデル」や「用語頻度 - 逆文書頻度(TF-IDF)表現」などの他の自然言語処理手法ではとらえられない言語特徴やセマンティック特徴、文法的特徴を説明するのに役立ちます。
グラフ ML を使用して金融 chatbot のレスポンスに対する感情分析モデルを構築し、どの会話が肯定的か、中立的か、否定的かを識別できるようになりました。これにより、chatbot がユーザーの回答を分類する際にミスが起きないようにできます。
データ ウェアハウジング、ML、アクセス管理ツールの導入
Google Cloud は、クラウド データ ウェアハウスの BigQuery や、ML ビルドを実施できるさまざまなフルマネージド ツールを提供する統合 ML 開発プラットフォームである Vertex AI といったインフラストラクチャとサービスを備えており、私たちのプロジェクトのニーズを満たしていました。
また、Jupyter ノートブック ベースの開発環境である Vertex AI Workbench も使用して、研究者のニーズに合わせて調整された仮想マシン インスタンスを作成、管理しました。これにより、データの準備、モデルのトレーニング、ユースケース モデルの評価を実施できるようになりました。
BigQuery に保存された構造化データを使用して、独自のトレーニング コードを記述し、任意の ML フレームワークを通じてカスタムモデルをトレーニングすることができました。さらに、Identity and Access Management(IAM)を利用して、リソースに対するアクセスのきめ細かい制御と管理を実現しました。
各研究トピックに対応するために使用した一般的なアーキテクチャは次のとおりです。
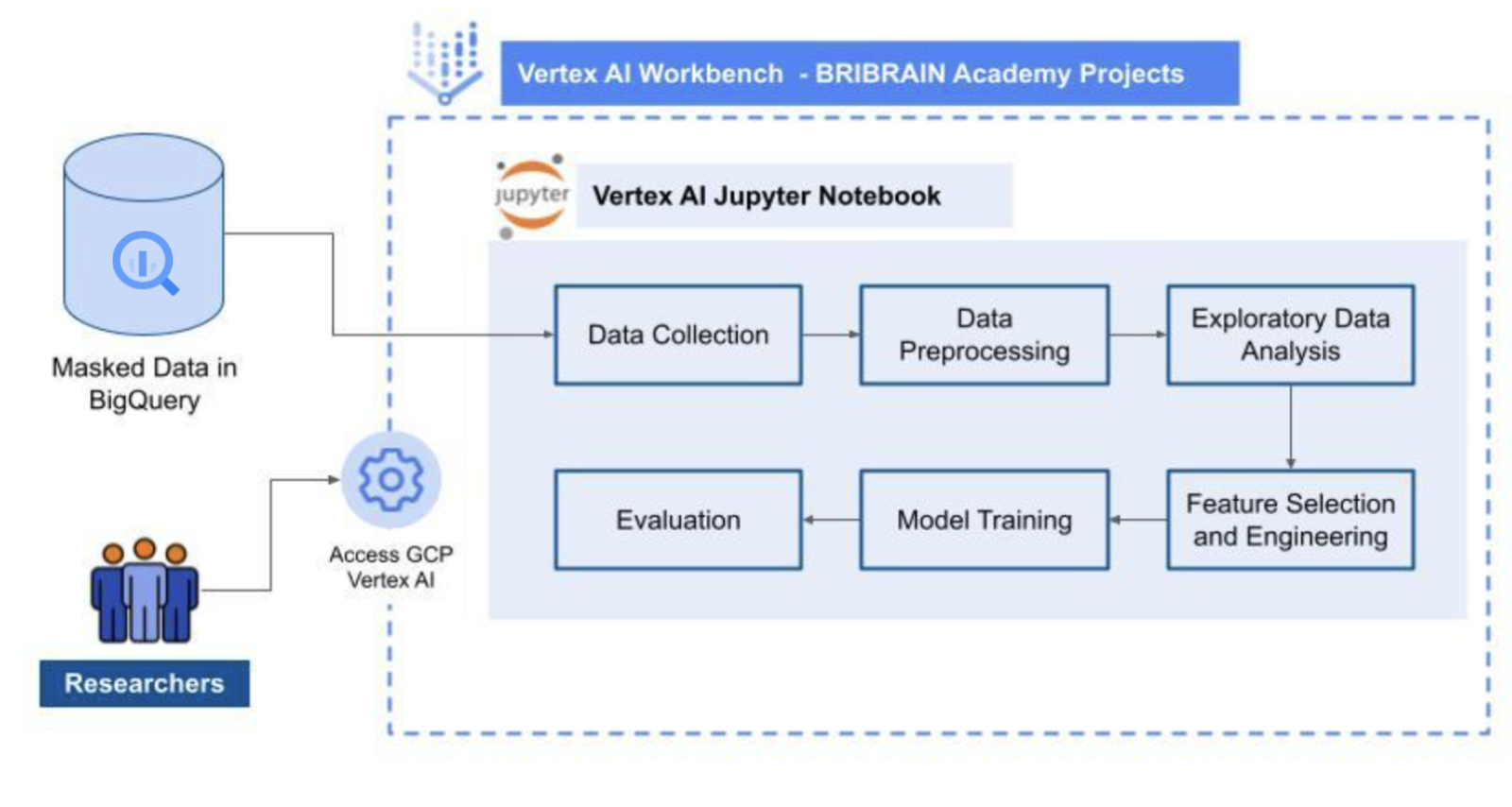
マスクされた研究を BigQuery に読み込み、特定の BRIBRAIN Academy プロジェクトの Vertex AI に研究者がアクセスできるようにし、研究を行う仮想マシンを割り当てました。その後、研究者は Vertex AI Workbench を使用して、上図のパイプラインのステップを Vertex AI Workbench で実行し、BigQuery を介して BRIBRAIN Academy プロジェクトの必要なデータにアクセスできました。
ML ソリューションを効率的かつ費用対効果の高い方法で構築して実行するために、各ユーザーが利用できるリソースを制限しました。ただし、Vertex AI を使用することで、モデルの作成に大量のデータが必要な場合に合わせてインスタンス リソースを変更できるようになりました。
同時に、Google Cloud データ セキュリティ サービスにより、プロジェクト データとリソースへの特定アクセスを作成、管理しながら、保存データと転送中のデータを不正アクセスから保護できるようになりました。BigQuery とノートブックのカスタムロールを通じて、研究者には特化したアクセス権を提供し、開発者には管理者ロールを割り当てました。
単一のプラットフォーム内で研究プロジェクトを実施
Google Cloud を使用することで、Digital BRIBRAIN は BRIBRAIN Academy のユースケースを確認し、実際のビジネス プロジェクトで得た教訓を応用できるようになりました。
たとえば、BRI はすでに AI の説明可能性に関する研究を利用して、BRILink エージェントと呼ばれるブランチレス バンキング サービスのレコメンデーション システム向けにエンドツーエンドの ML ソリューションを開発できるようにしています。また、AI Explanations の推奨事項を含むモバイル アプリケーションも構築しました。多くのユーザーが ML とその複雑さに慣れていない環境では、AI の説明可能性は ML ソリューションの透明性を高めるのに役立ち、ユーザーは推奨事項や決定の論理的根拠を理解できるようになります。
これまでの成果を踏まえ、ML およびデータ マネジメント機能を進化させる予定です。現在は BigQuery を使用して、モデルのトレーニングと構築のために主に表形式データを保存しています。これらの機能を拡張し、テキスト、ファイル、画像などの非構造化データを Cloud Storage で保存、処理、管理できるようにしています。また、ウェブベースのアプリケーションで利用できる ML ソリューションの一部を使用して、Firebase 向け Google アナリティクスを通じて生成されたレポートにより、アプリの使用状況をモニタリングする予定です。
Google Cloud のおかげで、データの保存、ML モデル ワークフローの構築とトレーニング、アクセス制御のモニタリング、データ セキュリティの維持をすべて単一のプラットフォーム内で行うことができます。これまで実現した有望な成果を受け、BRI は Vertex AI の機能をさらに活用することで、BRIBRAIN Academy で進行中の開発をサポートできるようにしたいと考えています。



