Palo Alto Networks、高額請求防止用に AI による費用の異常検出をカスタマイズしてデプロイ
Kuntal Patel
Manager, Cloud FinOps, Palo Alto Networks
Pathik Sharma
Cloud FinOps Lead, delta, Google Cloud Consulting
※この投稿は米国時間 2024 年 12 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
めまぐるしく進化する現在のデジタル環境で競争優位性を得るために、各企業は常に最新テクノロジーの革新的な活用方法を模索しています。AI は変革の推進力として急成長しており、組織での複雑な処理の自動化、データからの重要な分析情報の取得、差別化したカスタマー エクスペリエンスの提供を可能にしています。
しかし、AI の導入が急速に進むことで重大な課題が生じています。関連するクラウドの費用の管理です。AI が成長し(実際にはクラウド ワークロード全般が増大して)ますます高度に洗練されるにつれて、関連する費用と、組織が注意深く消費計画を立てなかった場合に発生しかねない超過費用も増加しています。
この想定外の費用は、次のようなさまざまな要因によって発生します。
-
人的エラーと管理ミス: 誤って上位ティアのサービスを有効化する、スケーリングの設定を変更してしまうなど、クラウド サービスの構成を誤り、意図せず費用の増加を招くことがあります。
-
想定していないワークロード変更: マーケティング キャンペーンやユーザー アクションの急な変更などにより、トラフィックや使用量が急激に上昇する、またはアプリケーションの動作が突然変更されることで、予期しないサービス変更が発生する場合があります。
-
ガバナンスと費用の透明性に前もって対処していない: 堅牢な Cloud FinOps フレームワークのない環境では、クラウドの費用がコントロール不能に陥り、あっという間に膨大な支出を引き起こすことがあります。
組織には、前もってクラウドの費用を管理し、予算超過を回避するチャンスがあります。リアルタイムでの費用のモニタリングと分析を実装することで、異常の可能性を特定し、想定外の支出を引き起こす前に対処することが可能です。このアプローチにより、企業は予算をコントロールしたまま、成長目標を追求できます。
Palo Alto Networks は、150 か国の 70,000 を超える組織を顧客としています。世界有数のサイバーセキュリティ企業として、そのデジタル事業には、ある程度のレベルの警戒と認識が必要です。同社は新しい技術やツールを試験運用することも多く、また脅威アクターに攻撃された場合にはアクティビティの急増にも対処します。異常な支出が発生する可能性は、このような場合に特に高くなります。
顧客全体に効果的なクラウド支出管理のニーズがあることに気付き、Google Cloud は費用の異常検出を費用管理ツールキットの一部としてリリースしました。必要なセットアップは何もありません。ユーザーの Google Cloud プロジェクトでの異常を自動的に検出し、チームに詳細情報を添えてアラートを送り、根本原因分析も提供します。Palo Alto Networks はこの機能を使用するうちに有用さに気付き、さらにカスタマイズしたソリューションへのニーズを認識するようになりました。カスタム要件が厳しいため、同社は Google Cloud プロジェクト全体のアプリケーションやプロダクトといったラベルに基づいて異常を特定できる、そして検出されてチームにアラート通知された異常変数へのコントロールを強化できるサービスを必要としていました。また、同社のマルチクラウド環境全体で一貫性のあるエクスペリエンスにすることも重視していました。
Palo Alto Networks の専用ソリューションは、クラウドの管理と AI の費用に正面から対処するもので、同社が大きな規模で先を見越した行動を起こすための後押しとなっています。リアルタイムのアラートをプロダクト所有者に通知することで費用の透明性を向上できるように設計されており、情報に基づいた意思決定と迅速な行動を可能にします。このソリューションは、大規模な自動インサイトも可能にするため、チームの時間が節約でき、イノベーションに力を入れることができます。
想定外の費用を心配する必要がなくなったため、Palo Alto Networks は現在、新しいクラウドと AI ワークロードを活用し、デジタル トランスフォーメーションをさらに推し進めています。
異常のライフサイクル
Palo Alto Networks にとって異常とは、想定外のイベントや通常とは異なるパターンを指します。同社のクラウド環境では、単純な構成ミスから本格的なセキュリティ侵害まで、あらゆることが異常になり得ます。そのため、大きな被害が生じる前にその異常を検出、分析、軽減できるシステムを配備しておくことが重要となります。
次のフローチャートは、異常の典型的なライフサイクルを、大きく 3 つのステージに分けて示しています。

図 1 - 異常のライフサイクル
次のセクションでは、これらの異常の各ステージに対処するために、Palo Alto Networks が Google Cloud をどのように活用して AI ベースのカスタム異常検出ソリューションを開発したかについて詳しく確認します。
1. 検出
最初のステップは異常の可能性の特定です。Palo Alto Networks は Google Cloud コンサルティングと協力し、同社のアプリケーションから取得した請求データと BigQuery ML(BQML)を使用して、ARIMA+ モデルをトレーニングしました。同社のチームがこのモデルを選んだのは、時系列的な請求データで優れた結果があり、ハイパーパラメータをカスタマイズできること、そして大規模な運用でのコスト効率が良いことが理由です。
ARIMA+ モデルによって、Palo Alto Networks は同社の費用異常検出ソリューション用に、上限と下限のあるベースライン支出を生成することができました。また、チームは同社の過去の請求データを使用してモデルをチューニングし、季節性の変化や一般的な急上昇と急下降、移行パターンなどの要素を最初から把握できるようにしました。モデルによって作成された上限を支出が上回ると、チームはその費用のビジネスへの影響を(割合と金額の両方で)数値化し、アラートの重大度を判定して調査を続けるかを決めます。

図 2 - AI による Google Cloud の費用の異常検出ソリューションのアーキテクチャ
Looker は Google Cloud のビジネス インテリジェンス プラットフォームです。データ モデリングのカスタマイズと可視化の基盤となっており、Palo Alto Networks の既存の請求データ インフラストラクチャ(毎日複数回、BigQuery にストリーミング)とシームレスに統合されています。このプラットフォームにより、分析用に最新の情報を確保でき、データ パイプラインをさらに追加する必要がなくなりました。
BigQuery ML によって、Palo Alto Networks は ML モデルのトレーニングと推論の機能を強化できます。BQML を活用することで、チームは高度なモデルを BigQuery 内で直接ビルドしてデプロイでき、ML 環境を別に管理するわずらわしさもなくなりました。この合理的なアプローチが、費用の異常をリアルタイムに検出して分析する機能をさらに加速します。この例では、Palo Alto Networks は ARIMA+ モデルを、特定のアプリケーションに対する最新 13 か月分の請求データの純支出フィールドでトレーニングし、カスタム カレンダーに基づく移行パターンと既知の急上昇に加えて、季節による影響や急上昇と急下降を取り入れました。
アラート通知と異常管理のプロセスを強化するため、Google Cloud Pub/Sub および Cloud Run functions も利用しました。Pub/Sub は、ステークホルダーへの異常の通知を、高い信頼性でスケーラブルに実施するために役立ちます。Cloud Run functions は、これらの通知をカスタム ロジックで処理できるようにします。たとえば、アラート疲れを最小限に抑えて調査を合理化するために、類似する異常をインテリジェントにグループ化できます。Pub/Sub と Cloud Run functions を活用することで、Palo Alto Networks は潜在的な費用の問題に迅速に、また効果的に対処できます。
2. 通知と分析
異常が確認されると、ソリューションによってこの費用のビジネスへの影響が算出され、その後の調査のため適切なアプリケーション チームに Slack 経由でアラートが通知されます。根本原因分析を短時間で行うために、このソリューションでは重要な情報がテキストと画像でまとめられており、異常についての詳細をすべて得られます。その異常が起きた時点と関連する SKU およびリソースも正確にわかります。アプリケーション チームはこの情報をさらに分析し、アプリケーションのコンテキストとも合わせて、迅速に判断を下すことができます。
以下の図は、BigQuery で 7 月 30 日に始まった費用の上昇を捉えたスナップショットの例です。
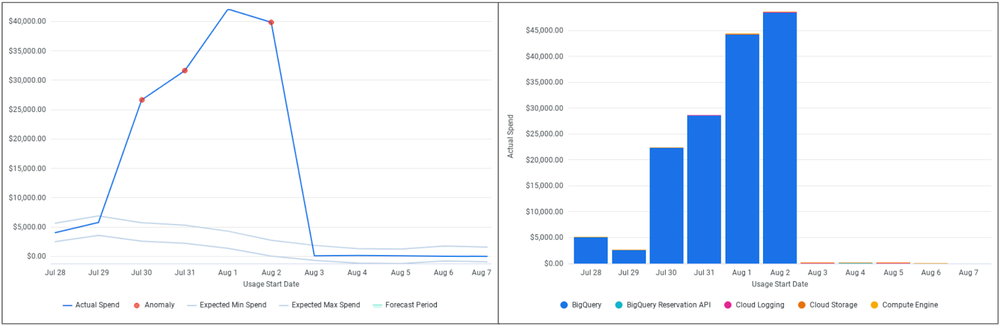
図 3 - 検出された費用の異常とリソースの詳細
費用の異常検出ソリューションによって、フラグ済みの異常に関連する情報(費用の影響に加えて、Google Cloud プロジェクト ID やデータ、環境、サービス名、SKU など)が、すべて自動的に生成されました。このデータにより、アプリケーション チームがすばやく行動するために必要なコンテキストのほとんどを取得できました。Slack アラートの例を以下に示します。
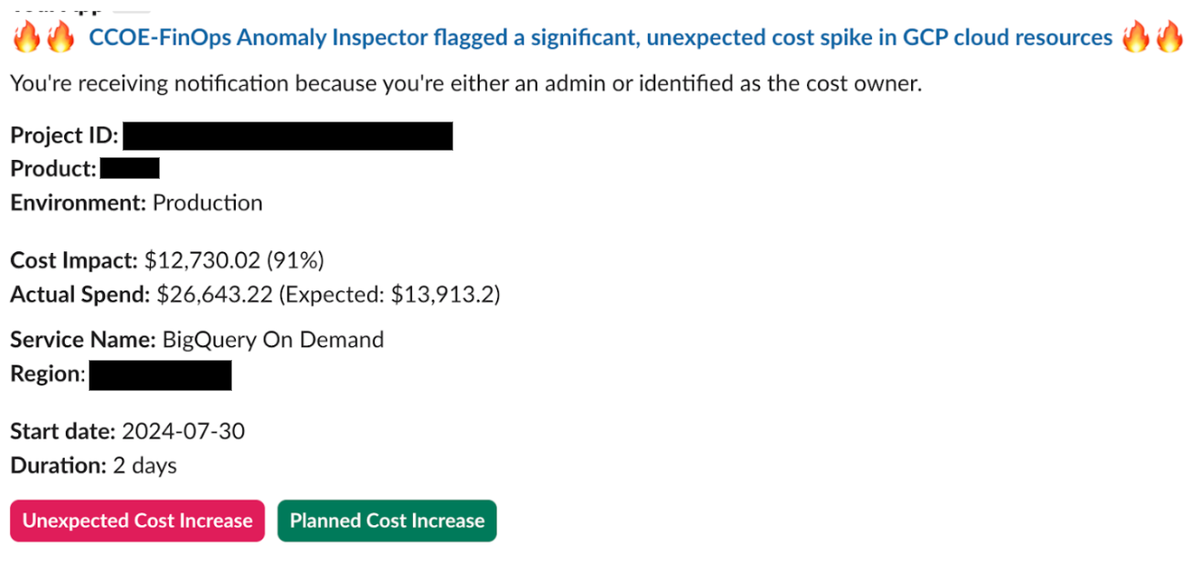
図 4 - Slack 上での異常検出アラートの例
3. 緩和策
根本原因が特定されると、次は異常を緩和するためのアクションを実施します。単純な構成変更からホットフィックスのデプロイまで、あらゆるアクションが考えられます。場合によっては、問題をエスカレーションし、部門横断型チームと連携する必要もあります。
提供された例では、クラウドでホストされたテナントで、構成のエラーが原因でデータ量が大幅に増加しました。この構成ミスにより、BigQuery の使用量が異常に多くなり、新たに確立されたリージョンで BigQuery にデフォルトの予約がなかったことから、システムのデフォルトがオンデマンド料金モデルに設定され、費用の増加を招きました。
この問題に対処するため、チームはベースライン 100 スロットを 3 年間の確約利用で購入し、今後急上昇することがあってもパフォーマンスに影響することなく吸収できるように、自動スケーリングを実装しました。また、特に新しいリージョンでの類似のインシデントを防ぐために、費用の長期的なガバナンス ポリシーを組織レベルで導入しました。
インシデント後には、費用の異常検出ソリューションによって事後検証ドキュメントが生成されます。このドキュメントには、実施した中でも特に注目すべきアクション、連携による影響、迅速な検出と緩和によって節約できた費用について記載されています。このドキュメントは以下を中心としています。
-
イベントの詳細なタイムライン: 費用の上昇を検出した時点とチームにアラートが通知された時点に加えて、再発防止に向けた短期的および長期的な取り組みを含む緩和策が含まれます。
-
実施されたアクション: 異常検出の詳細、アプリケーション チームによる分析、実施された緩和策などです。
-
防止戦略: 類似のインシデントの発生を防ぐための、短期的および長期的な計画について記述されます。
-
費用の影響と費用回避: この異常によって引き起こされた全体的な費用の計算値、問題の検出までに時間がかかった場合の追加費用の推定などの計算結果が含まれます。
その後、Palo Alto Networks の上級管理職を含むアプリケーション チームに正式な通知が送付され、さらに可視性を高めます。
Palo Alto Networks は大規模対応の経験から、クラウド環境での異常の発生は避けられないという事実を学び、受け止めています。これらの異常を効率的に管理するには、ライフサイクル全体での明確に定義された検出、分析、緩和対策が欠かせません。異常の可能性を特定するには、自動モニタリング ツールが重要な役割を果たします。また、チーム間の連携も問題の解決には不可欠です。特に Palo Alto Networks のチームは、異常管理プロセスの最適化の継続的な改善を重視しており、たとえば長期的なガバナンスの維持のために、以下のような報告ダッシュボードを構築しました。

図 5 - 費用の異常報告ダッシュボード(Looker)
AI の機能を活用し、Google Cloud と連携することで、Palo Alto Networks は、企業が AI の潜在的な可能性を十分に引き出しつつ、クラウド支出を責任ある持続可能な範囲に確実にとどめられるようにしています。費用の異常管理への積極的な取り組みにより、組織は自信をもって進化し続ける AI を活用し、イノベーションを進め、戦略目標を達成できます。費用の異常検出のプレビュー版をぜひお試しください。また、ソリューションのカスタマイズについては Google Cloud コンサルティングまでお問い合わせください。
このソリューションの開発のため連携して取り組んだチームの全員に、多大な感謝を申し上げます。Yaping Gu、Matt Orr、Andy Crutchfield、Gina Huh
-Palo Alto Networks、Cloud FinOps マネージャー、Kuntal Patel 氏
-Google Cloud コンサルティング、Cloud FinOps 費用最適化担当リード、Pathik Sharma

