次世代の AI ワークロードを実現: TPU v5p と AI ハイパーコンピュータを発表

Google Cloud Japan Team
※この投稿は米国時間 2023 年 12 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
近年生成 AI モデルは急速に進化しており、あらゆる業界の企業や開発者はその比類のない洗練性と能力を活かし、複雑な問題を解決し、新たな機会を解き放つことができるようになりました。この 5 年間で、AI モデルのパラメータ数が毎年 10 倍増加している一方、学習、チューニング、推論に対する需要も高まっています。パラメータが数千億、数兆規模の今日の大規模モデルは、最も特化したシステムであっても、時には数か月に及ぶ学習期間を必要とします。さらに、効率的な AI ワークロード管理には、最適化されたコンピュート、ストレージ、ネットワーキング、ソフトウェア、開発フレームワークで構成される、統合された AI スタックが必要です。
Google Cloud はこれらの課題に対処すべく、本日、我々の最も強力でスケーラブルかつ柔軟な AI アクセラレータ「Cloud TPU v5p」を発表しました。TPU は、YouTube、Gmail、Google マップ、Google Play、Android などの AI 搭載製品のトレーニングやサービングの基盤となっており、本日発表した、Google の高性能な AI モデルである Gemini のトレーニングおよび提供にも TPU v5p を利用しています。
さらに本日、パフォーマンスに最適化されたハードウェア、オープンソフトウェア、主要な ML フレームワーク、およびそれらを柔軟に利用可能な形で統合した、画期的なスーパーコンピュータアーキテクチャの「AI ハイパーコンピュータ」も発表しました。従来の手法では、要求の厳しい AI ワークロードに対して、コンポーネント レベルの断片的な機能強化を行うことが多いため、非効率的であったり、ボトルネックになる可能性がありました。対照的に AI ハイパーコンピュータは、システムレベルでそれらを最適化し、AI のトレーニング、チューニング、サービング全体の効率と生産性を向上させることができます。

最も強力かつスケーラブルな TPU アクセラレータ、Cloud TPU v5p
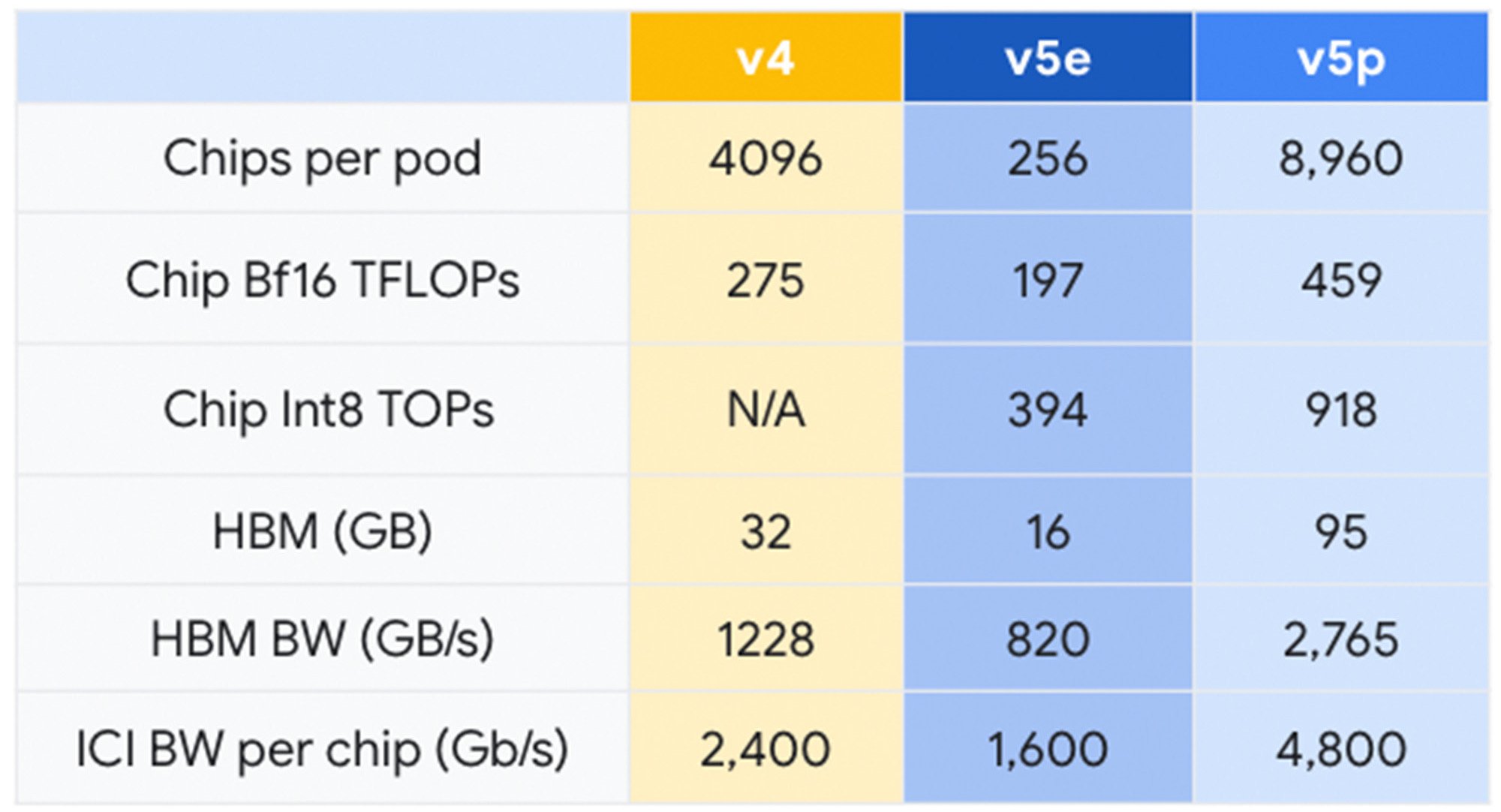
Google Cloud は 2023 年 11 月、Cloud TPU v5e の一般提供を発表、前世代の TPU v4 と比較して 2.3 倍のコスト パフォーマンス向上を達成し、これまでで最もコスト パフォーマンスの高い TPU を実現しました。本日発表した Cloud TPU v5p は、最も強力な TPU です。TPU v5p の各ポッドは、8,960 個のチップで構成されており、3D トーラスのトポロジーで4,800 Gbps / チップという最高帯域幅のチップ間相互接続(ICI)を 実現しています。また TPU v5p は TPU v4 と比較して 2 倍以上の 浮動小数点演算性能(FLOPS)と 3 倍以上の高帯域幅メモリ(HBM)を備えています。
TPU v5p は、パフォーマンス、柔軟性、スケールを重視して設計されており、TPU v4 と比較して 2.8 倍高速に大規模言語モデル(LLM)をトレーニングできます。 さらに、第 2 世代の SparseCores を使用することで、TPU v41 より 1.9 倍高速に密埋め込みモデルを学習できます。
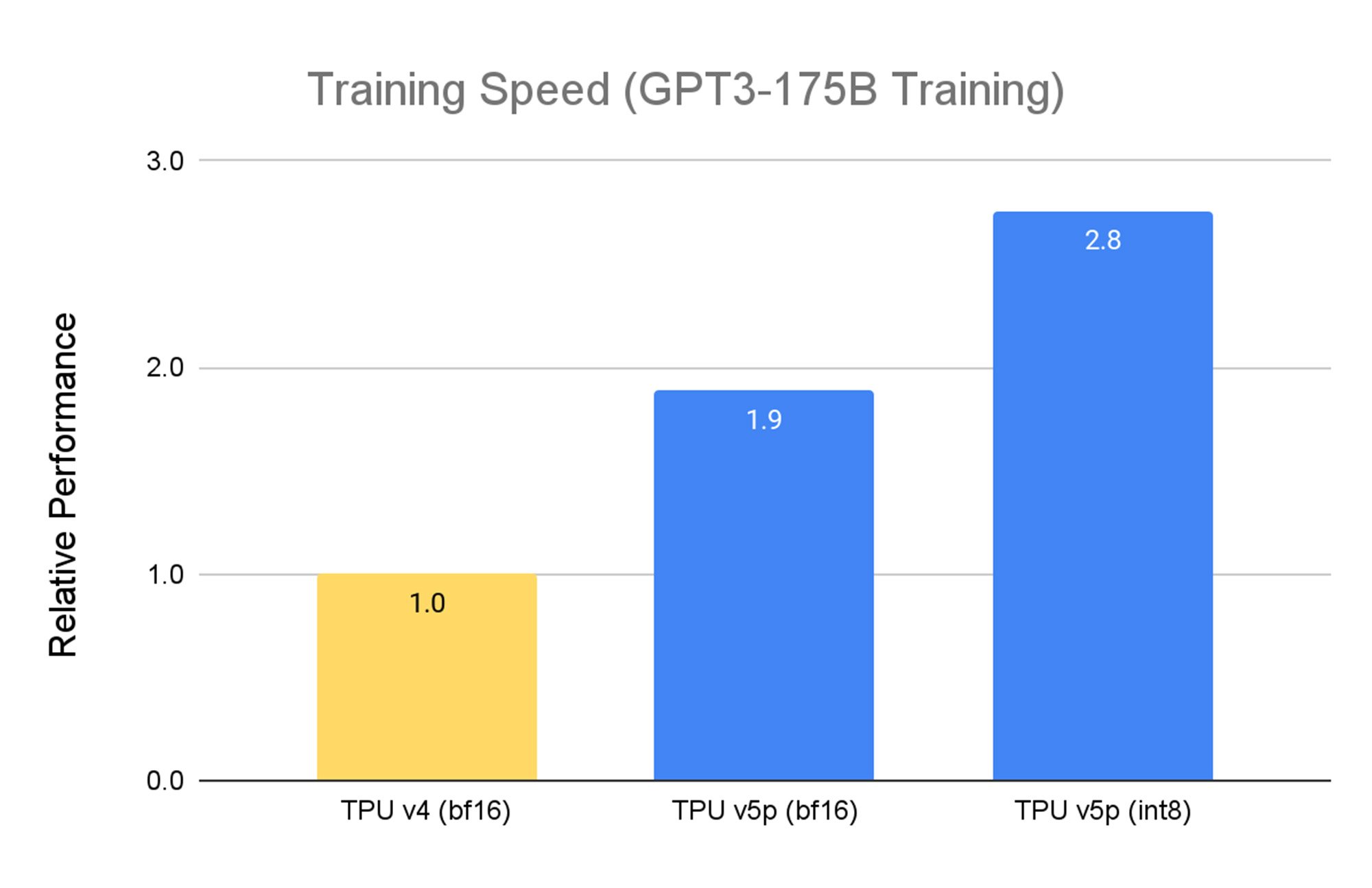
Google 内部データ。2023 年 11 月時点の情報。GPT3-175B すべての数値はチップごとに正規化
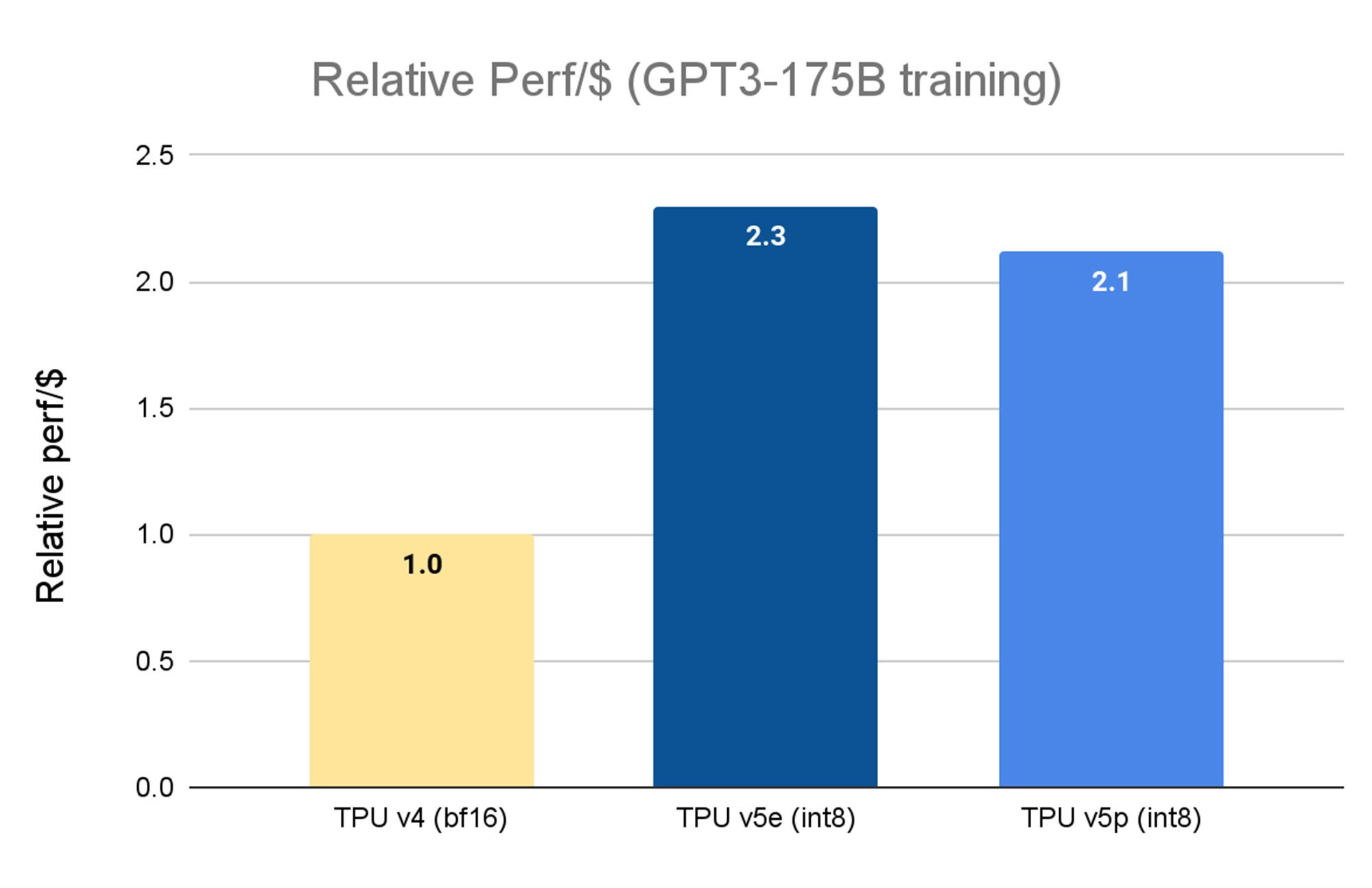
TPU v5e は MLPerf™ 3.1 Training Closed の結果、TPU v5p と TPU v4 については Google 内部データ。2023 年 11 月時点の情報: すべての数値は、チップごとに正規化。相対的なパフォーマンスで実装した GPT-3 1,750 億パラメータモデルの場合、seq-len=2048。使用した正規料金: TPU v4 はチップ時間あたり $ 3.22、TPU v5e は、チップ時間あたり $ 1.2、TPU v5p は、チップ時間あたり。
TPU v5p は性能向上に加え、ポッドごとに利用可能な FLOPS も TPU v4 と比べて 4 倍スケーラブルです。さらに、1 秒あたりの FLOPS の合計数が TPU v4 の 2 倍、1 つの Pod 内のチップ数が 2 倍のため、トレーニング速度における相対的なパフォーマンスが大幅に向上します。
Google AI ハイパーコンピュータ、大規模で最高の性能と効率を実現
最新の AI/ML アプリケーションやサービスのニーズを満たすには、スケールとスピードの両立が不可欠です。それだけでなく、ハードウェアとソフトウェアのコンポーネントが統合され、使いやすく、安全で信頼性の高いコンピューティングシステムが求められています。この課題について数十年にわたる研究開発を行った結果、最新の AI ワークロードを実現するために連携して動作する、最適化されたテクノロジー システムである AI ハイパーコンピュータが実現しました。

- パフォーマンスに最適化されたハードウェア: AI ハイパーコンピュータ は、高密度化されたチップ、液体冷却、Jupiter データセンターのネットワーク テクノロジーを活用し、パフォーマンスに最適化されたコンピュート、ストレージ、ネットワーキングがウルトラスケールのデータセンター インフラ上に構築されています。これらはすべて、効率性を重視しつつ、カーボンフリーの未来に向けて前進するためのクリーンエネルギーとウォーター スチュワードシップへのコミットメントに基づいています。
- オープン ソフトウェア: 開発者は、オープンソフトウェアを使用してハードウェアにアクセスし、パフォーマンスに最適化された AI ハードウェア上で AI トレーニングおよび推論ワークロードのチューニング、管理、動的なオーケストレーションなどを行うことができます。
- JAX、TensorFlow、PyTorch などの一般的な ML フレームワークが、すぐに利用できます。JAX と PyTorch は、洗練された LLM を構築するための OpenXLA コンパイラを搭載しています。XLA は基礎的なバックボーンとして機能し、PyTorch/XLAによる Cloud TPU 上での Llama 2 の学習と推論など、複雑な多層モデルの作成を可能にします。また、幅広いハードウェア プラットフォームで分散アーキテクチャを最適化し、AssemblyAI での大規模な AI 推論を含む、多様な AI ユースケースで使いやすく効率的なモデル開発も実現します。
- オープンでユニークなマルチスライス トレーニングとマルチホスト推論ソフトウェアが、ワークロードのスケーリング、トレーニング、サービングをスムーズかつ簡単にします。開発者は、要求の厳しい AI ワークロードをサポートするために、数万チップまで拡張することができます。
- Google Kubernetes Engine(GKE)および Google Compute Engine との統合により、効率的なリソース管理、一貫した運用環境、自動スケーリング、ノードプールの自動プロビジョニング、自動チェックポイント、自動リカバリ、タイムリーな障害復旧を実現します。
- フレキシブルな利用: AI ハイパーコンピュータ は、確約利用割引(CUD)、オンデマンド料金、スポット料金といった従来の選択肢に加え、Dynamic Workload Scheduler を通じて AI ワークロードに合わせ、柔軟でダイナミックな幅広い消費オプションを提供します。Dynamic Workload Scheduler は、より高いリソース取得可能性と最適化された経済性を実現する Flex Start Mode と、ジョブ開始時間の予測可能性が高いワークロードを対象とする Calendar Mode の 2 つのモデルを導入しています。
Google の知見を AI の未来に活用
Salesforce や Lightricks などのお客様は、Google Cloud の TPU v5p AI ハイパーコンピュータで大規模 AI モデルをトレーニングしたサービスを提供しています。
「Salesforce では、基礎モデルの事前トレーニングに Google Cloud TPU v5p を活用することでトレーニング速度が大幅に向上しました。Cloud TPU v5p の計算性能は、前世代の TPU v4 を 2 倍も上回っており、JAX を使った Cloud TPU v4 からv5p への移行もシームレスで簡単です。Accurate Quantized Training(AQT)ライブラリを介して INT8 精度フォーマットのネイティブ サポートを活用し、モデルを最適化することで、これらの速度向上をさらに進めたいと考えています」- Salesforce、 シニア リサーチ サイエンティスト、Erik Nijkamp 氏
「Lightricks では、Google Cloud TPU v5p の卓越した性能とメモリ容量を活用し、別々のプロセスに分割することなく、テキストから動画への生成モデルの学習に成功しました。最適なハードウェア利用により、各トレーニング サイクルが大幅に高速化され、一連の実験を迅速に実施できるようになっています。各実験でモデルを迅速にトレーニングおよび反復できることは、競争の激しい生成 AI の分野において、私たちの研究チームの貴重なアドバンテージとなっています」- Lightricks、 コア 生成AI チーム リーダー、Yoav HaCohen 博士
「初期段階での使用ではありますが、Google DeepMind と Google Research は、TPU v5p チップを使用した LLM トレーニングのワークロードにおいて、TPU v4 のパフォーマンスと比較して 2 倍のスピードを確認しています。また、ML フレームワーク(JAX、PyTorch、TensorFlow)とオーケストレーション ツールの強固なサポートにより、v5p 上でさらに効率的にスケーリングすることができます。さらに、第 2 世代の SparseCores により、埋め込みを多用するワークロードのパフォーマンスが大幅に向上しました。TPU は、Gemini のような最先端のモデルで、我々の最大規模の研究とエンジニアリングの取り組みを可能にするために不可欠です」- Google DeepMind / Google Research チーフ サイエンティスト、Jeff Dean
Google は、AI により、あらゆる課題を解決することができると考えています。近年まで、大規模な基礎モデルをトレーニングし、大規模に提供することは、多くの組織にとって複雑で多額の費用がかかる取り組みでした。今回発表した Cloud TPU v5p と AI ハイパーコンピュータ によって、AI とシステム設計における数十年の研究成果をお客様に提供できることを嬉しく思います。
Cloud TPU v5p および AI ハイパーコンピュータ へのアクセスに関しては、Google Cloud アカウント担当者にお問い合わせください。Google Cloud の AI インフラストラクチャの詳細については、Google Cloud Applied AI Summit にご登録ください。
1: 2023 年 11 月時点の TPU v5p の Google 内部データ: E2E ステップタイム、SearchAds pCTR、TPU コアあたりのバッチサイズ 16,384、125個のvp5チップ
2: 2023 年 11 月時点の TPU v5eのGoogle内部データ: seq-len=2048、MaxText を使用して実装された 320 億パラメータ デコーダのみの言語モデル。
-VP/GM ML, Systems, and Cloud AI, Amin Vahdat
-VP/GM, Compute and ML Infrastructure, Mark Lohmeyer



