マルチスライスで AI トレーニングを最大数万の Cloud TPU チップまでスケーリングする方法
Google Cloud Japan Team
※この投稿は米国時間 2023 年 9 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
最大規模の生成 AI モデルの場合、パラメータの数は数千億以上、使用されるトレーニング トークンの数は 1 兆にもなるとされています。このようなモデルでトレーニング時間を数週間以下に抑えるためには、数十の EFLOP(1018 FLOP)による AI スーパーコンピューティングが必要です。これだけのパフォーマンスを発揮するには、数万のアクセラレータが一体となって効率よく機能する必要があります。しかし、ほとんどのスケーリング ソリューションでは、洗練されたコードを自ら書き、手動でチューニングする必要があります。そのため、ソリューションが脆弱になり、スケーリングのパフォーマンスが劣線形になります。
この課題に対処するため、Google は今週 Google Cloud Next でマルチスライスを発表しました。マルチスライスは、費用対効果に優れた容易な方法で最大数万の Cloud Tensor Processing Unit(TPU)チップまでほぼ線形にスケールアップできるフルスタックの大規模なトレーニング テクノロジーです。従来のトレーニング実行ではスライスを 1 つだけ使用できました。スライスとは、チップ間相互接続(ICI)を介して予約可能なひとまとまりのチップです。つまり、実行で使用できる TPU v4 チップは 3,072 個しかありません。現時点では、これが最大の Cloud TPU システムにおける最大のスライスです。マルチスライスによるトレーニング実行では、データセンター ネットワーキング(DCN)を介して通信することで、単一のスライスを超えてスケーリングし、数多くの Pod で複数のスライスを使用できます。
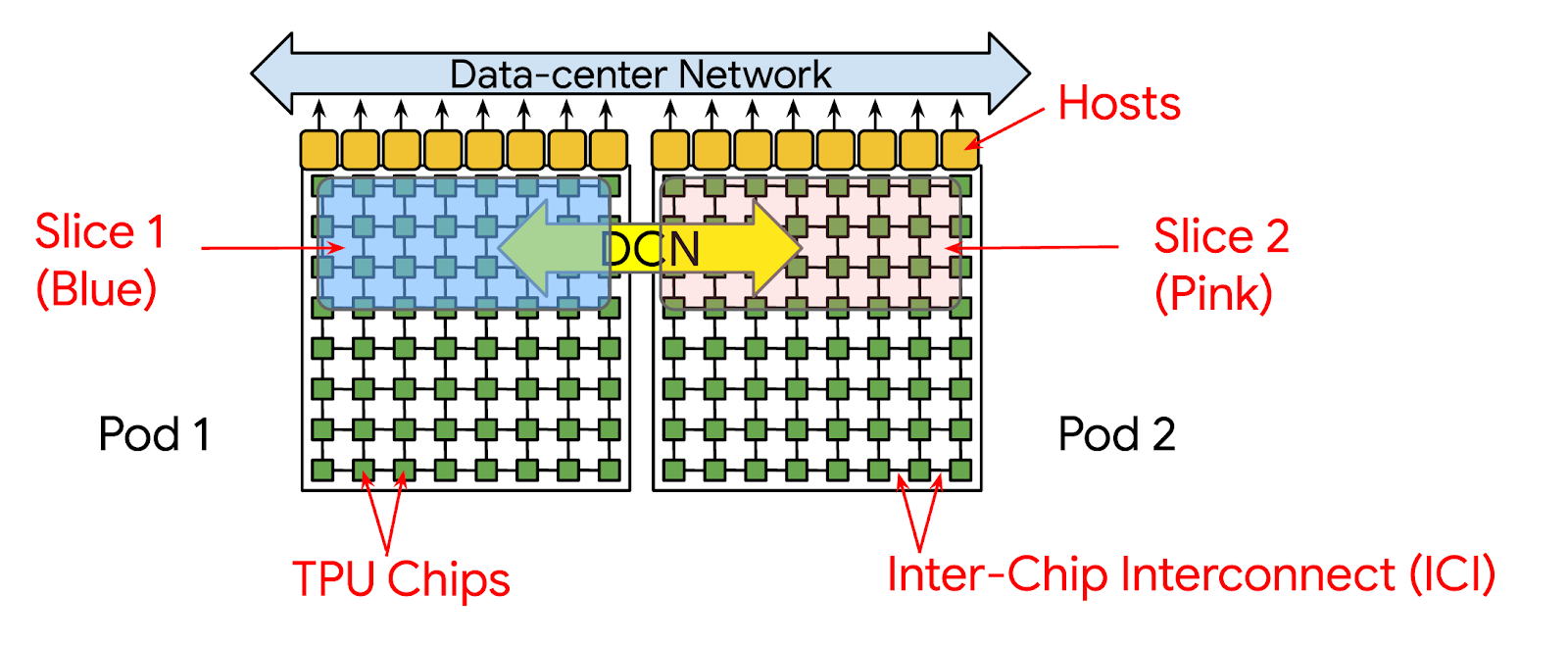
要するに、マルチスライスは次のメリットを備えています。
最大数万のチップにより、単一のスライスから複数のスライスまでほぼ線形のスケーリング パフォーマンスで大規模なモデルをトレーニングする
わずかにコードを変更するだけの簡単な設定でデベロッパーの生産性を高める
自動コンパイラ最適化を利用して時間を節約する
TPU v5e により、TPU v4 に比べて LLM のトレーニングに対する 1 ドルあたりのパフォーマンスを最大 2 倍にして、費用対効果を最大限に高める
8 チップ ICI ドメイン搭載のシステムに比べて、TPU v5e と TPU v4 でそれぞれピーク FLOP 予算を最大 2~24 倍高めてアクセスする
「マルチスライス Cloud TPU v5e をはじめとする Google Cloud の次世代の AI インフラストラクチャは、当社のワークロードにパフォーマンスの面でその価格からは信じられないほどのメリットをもたらすでしょう。Google Cloud に AI の次の波を構築できることを楽しみにしています。」 - Anthropic 社共同創立者、Tom Brown 氏
マルチスライスの仕組み
マルチスライス構成にデプロイすると、各スライス内の TPU チップが高速 ICI を介して通信します。異なるスライスにある各 TPU チップは、Google Cloud の Jupiter データセンター ネットワーク経由でデータを転送することで互いに通信します。たとえば、データ並列処理を使用すると、単一スライスによる演算と同じく、引き続きアクティベーションは ICI を介して通信されますが、DCN 経由の勾配は削減されます。
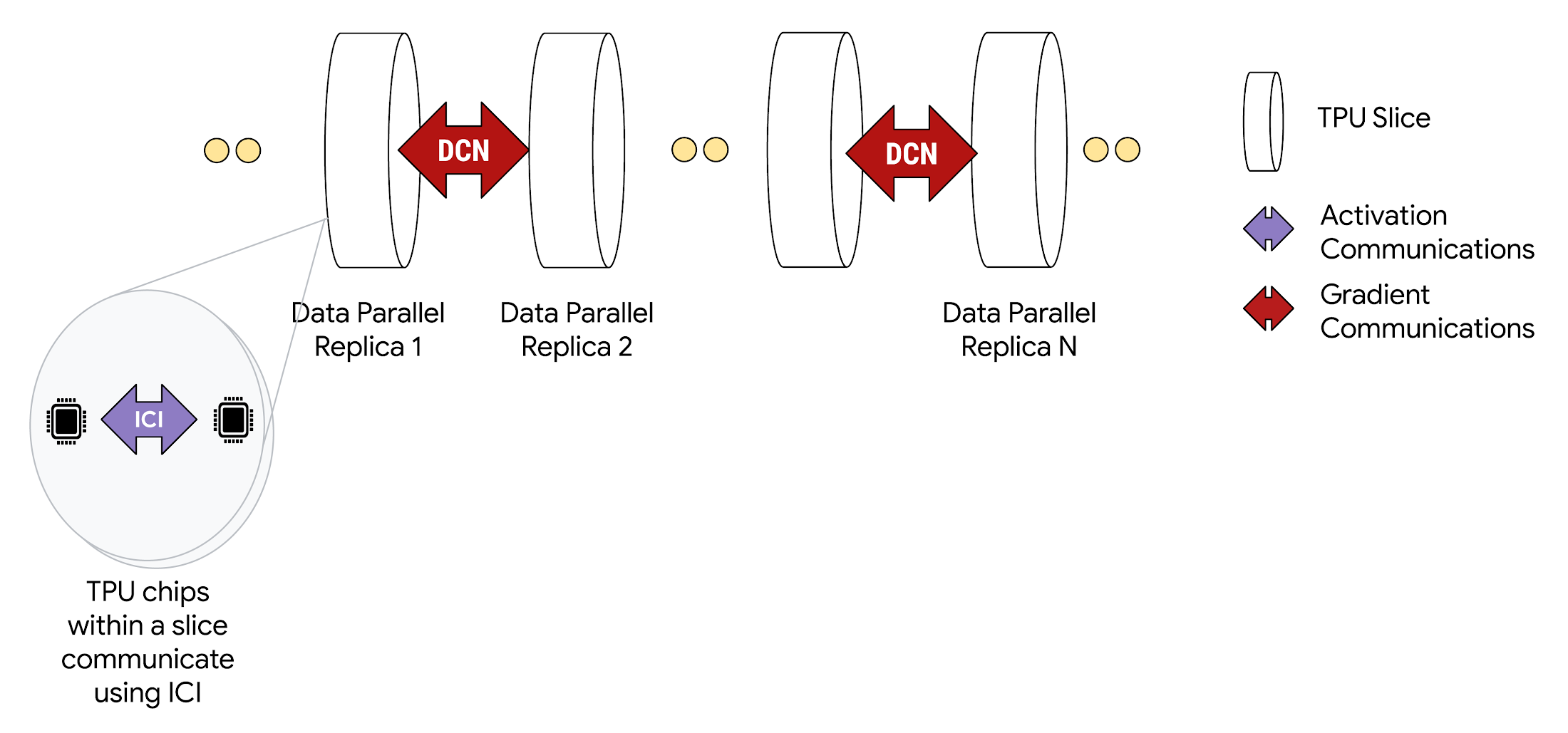
マルチスライスは、同じトレーニング実行で単一 Pod 内の複数のスライスや複数の Pod 内のスライスを使用できるように、さまざまな並列処理手法をサポートしています。高密度デコーダモデルや拡散モデルをはじめとするほとんどのモデルでは、簡単なデータ並列処理(DP)があれば十分です。ただし、もっと大きなモデルやデータサイズに対処できるように、マルチスライスは完全にシャーディングされたデータ並列処理(FSDP)、モデル、パイプライン並列処理もサポートしています。高度な最適化とシャーディング手法については、マルチスライスのユーザーガイドで詳しく説明しています。
スライス間 DCN 通信を実装するためにデベロッパーがコードを記述することはありません。XLA コンパイラが、そのコードを生成し、最大限のパフォーマンスが発揮できるようにコンピューティングと通信を自動的にオーバーラップします。
システム スケーリングを 2 倍以上に
ソフトウェア スケーリングは、ハードウェアの制限を受けます。アクセラレータ システムは、その FLOP 予算までしかスケールアップできません。そのうえ、パフォーマンスは通信ボトルネックの制限を受けます。スケーリングを効果的に行うには、ハードウェア システム自体がスケーリングをサポートする必要があります。Cloud TPU システムの大規模な ICI ドメインでは、通信ボトルネックを発生させることなく、8 チップ ICI ドメイン搭載の従来のシステムよりも FLOP を最大 24 倍も高めることができます。
その計算をよく理解するため、ICI ドメインの説明から始めます。高速 ICI で接続された最大チップ数をシステムの ICI ドメインといいます。TPU v4 Pod の ICI ドメインは 3,072 個のチップで、TPU v5e Pod の ICI ドメインは 256 個のチップです。
システムがパフォーマンスの面からスケーリングできるピーク FLOP を P と定義しましょう。DP と FSDP を使用した高密度の LLM を実現するには、DCN 算術強度にほぼ等しくなるように ICI ドメインあたりのバッチサイズを最小限に抑える必要があります。こうしたモデルの場合、DCN 算術強度はチップあたりの DCN 帯域幅に対するチップあたりの FLOP の比率に近くなります。つまり、P は次のようになります。
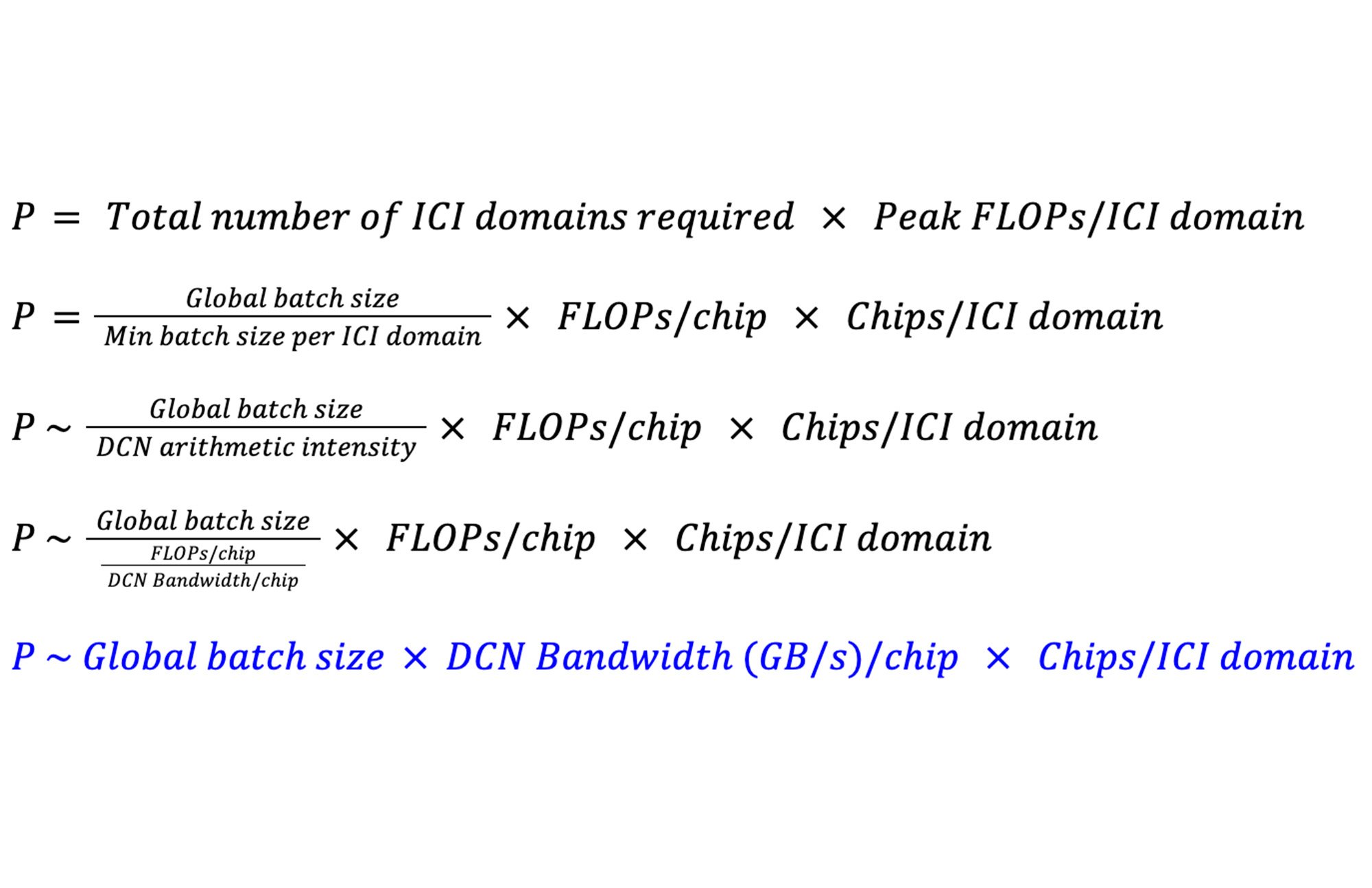
合計ピーク FLOP で見た場合、システムの最大スケーリングはチップあたりの使用可能な DCN 帯域幅、ICI ドメインのサイズ、グローバル バッチサイズの影響を受けることがわかります。
ICI ドメインのサイズが通信ボトルネックなしのシステムで実現できる最大スケーリングにどのような影響を及ぼすのか、さまざまなシステムの例で確認していきましょう。いずれの例でも、モデルは 32M グローバル バッチサイズでトレーニングされているとします。
ベースラインとして、8 チップ ICI ドメイン搭載のシステムが従来の高速 DCN テクノロジーを使用して 400 Gbps / チップの速度で DCN 全体にわたって通信しているものとします。

このシステムがパフォーマンスを低下させることなく実現できる最大合計ピーク FLOP は P8 = 12.8 EFLOP です。
TPU Pod の ICI ドメインはもっと大きく、DCN で転送されるバイトあたりの算術強度が高くなります。TPU v5e Pod の場合、ICI ドメインあたり 256 個のチップを搭載して 25 Gbps / チップを実現しており、P256 = 25.6 EFLOP となります。
TPU v4 Pod の場合、ICI ドメインあたり 3,072 個のチップを搭載して 25 Gbps / チップを実現しており、P3072 = 307.2 EFLOP となります。
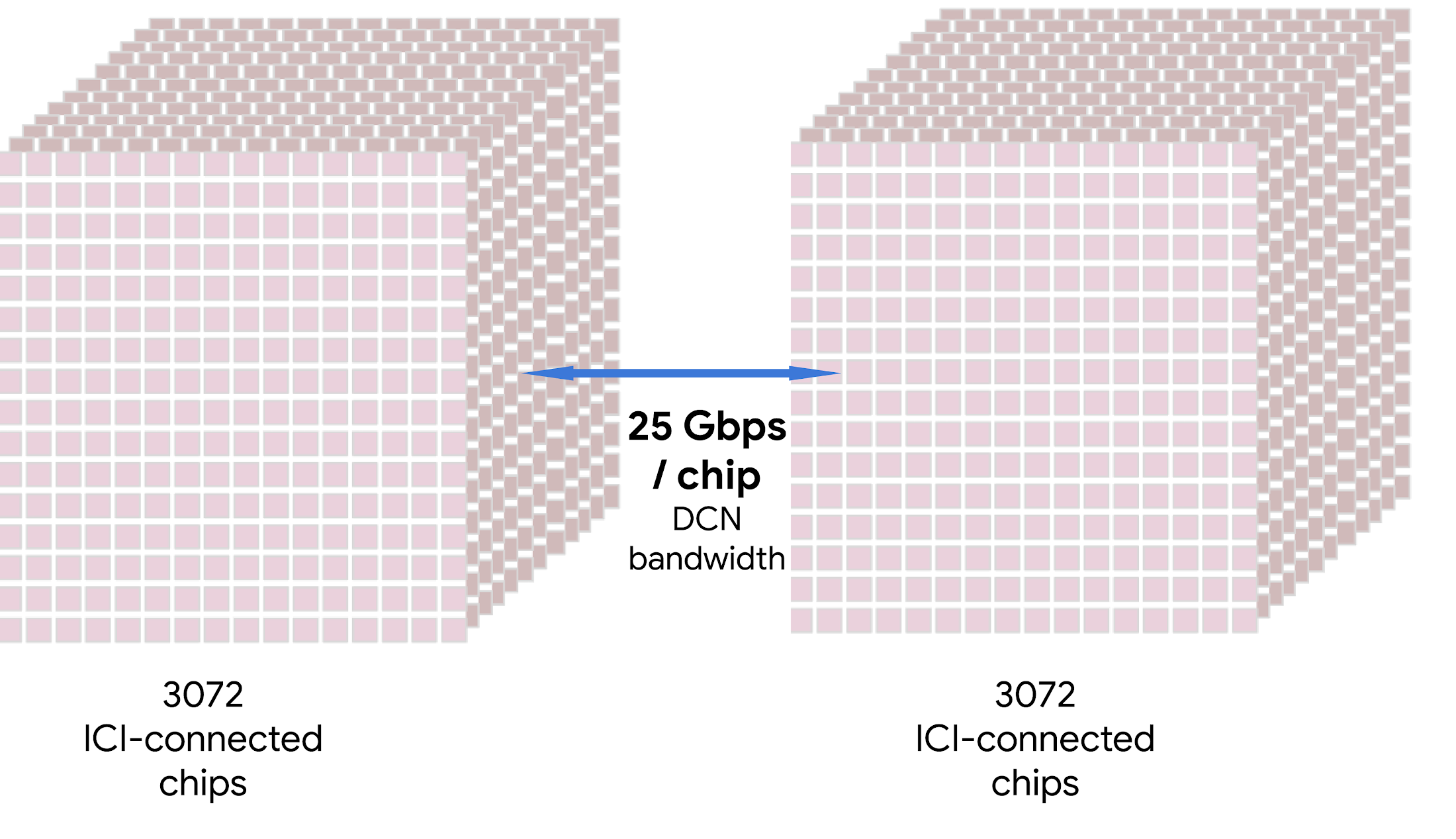
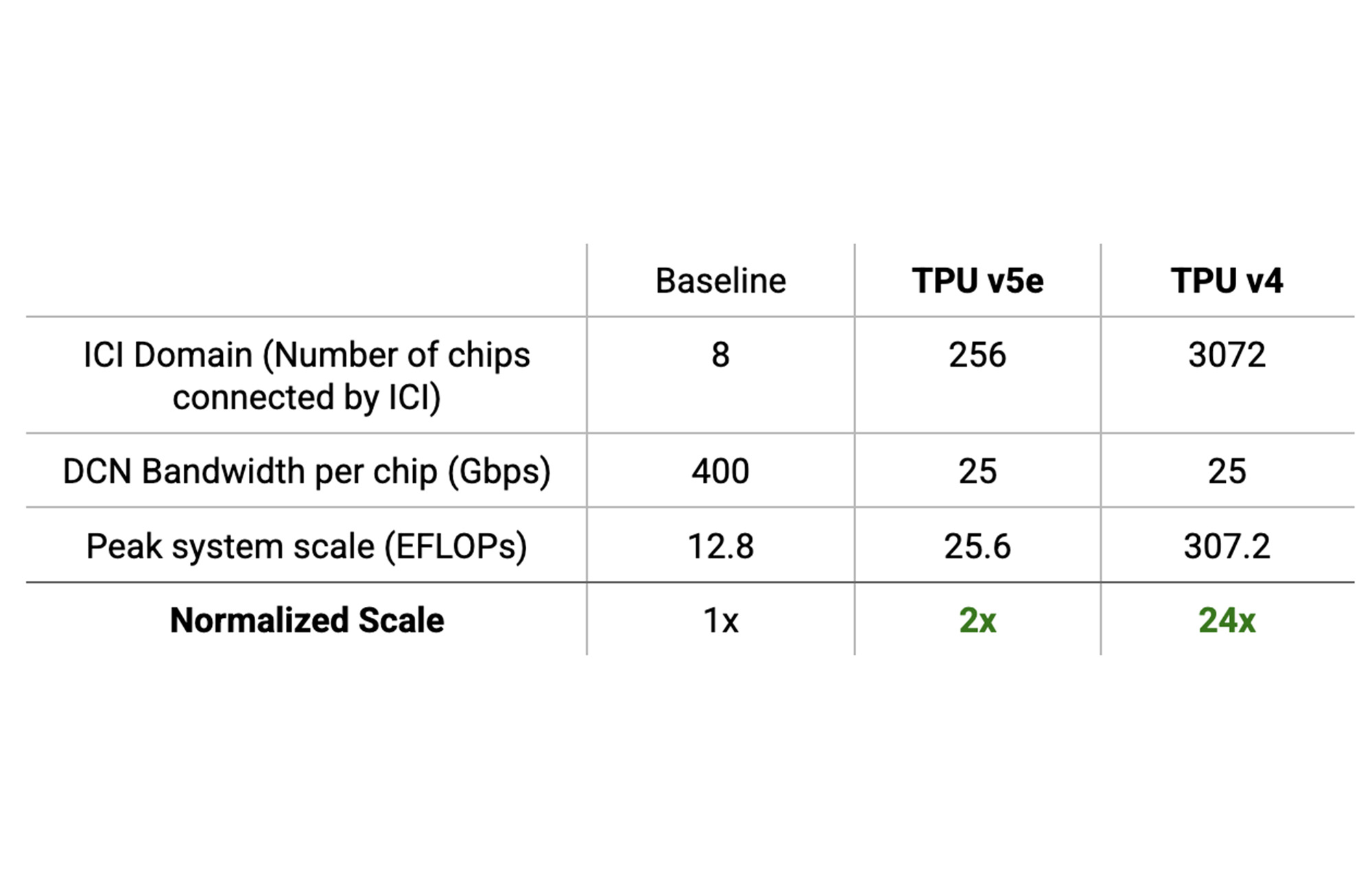
8 チップ ICI ドメインを搭載してチップあたり 400 Gbps の DCN 帯域幅のシステムと比べて、TPU v5e システムと TPU v4 システムはそれぞれ最大 2 倍または 24 倍高いスケーリングを実現しています。
「Google DeepMind と Research はそれぞれ、数千もの TPU v5e チップを使用してこれまでいくつかのトレーニング実行に成功してきました。その中には、TPU v4 世代と同じようにスケーリング効率に優れた LLM ユースケースのモデルに対してマルチスライス スケーリング ソフトウェアを使用して行ったトレーニングも含まれています。」 - Google チーフ サイエンティスト、Jeff Dean
TPU v5e では最大数万のチップまでほぼ線形にスケールアップ
マルチスライスのパフォーマンスと単一スライスのパフォーマンスを比較する場合は、モデルの FLOP 使用率(MFU)という指標を使用できます。この指標は、ピーク FLOP で動作するシステムの理論上の最大スループットに対する実際に観察されたスループット(1 秒あたりのトークン)の比率であると定義されています。
マルチスライスで複数のスライスを使用して TPU トレーニングを実行すると、コンパイラ最適化が機能するため、単一のスライスを使用した場合と同じ MFU 率が得られます。以下に例を示します。
誤差逆伝播法とオーバーラップする FSDP の勾配削減
通信テクノロジーに基づいて従来の集団演算を分解する特別な階層集団演算
また、他のアクセラレータとは異なり、TPU チップはスロットリングなしでピーク FLOP を持続できるため、FLOP と MFU 率が高くなります。
マルチスライスを使用すると、数千億ものパラメータを駆使して生成 AI モデルをトレーニングできます。その結果、TPU v4 で数十億のパラメータ モデルを対象とした場合の MFU が 58.9% も高くなります。
スケーリングが脆弱で、使用する Pod の数が増えるに従ってバッチサイズが大きくなっていたケースで、GPT-3 175B を TPU v5e1 でトレーニングすると、パフォーマンスがほぼ線形に向上します。
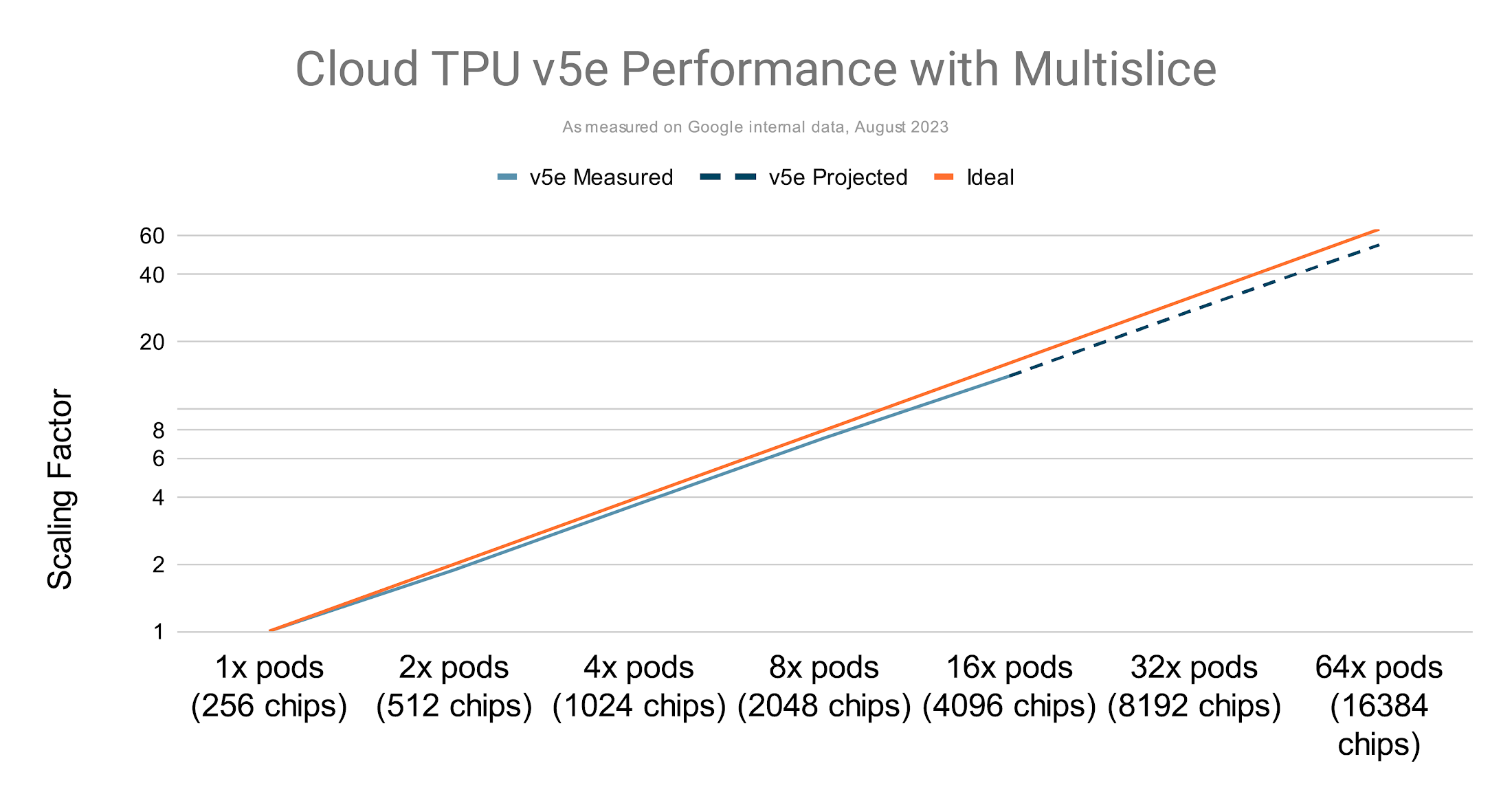
Cloud TPU でマルチスライスが使いやすく
スケーリング テクノロジーの通信階層の管理が複雑になって、デベロッパーの生産性が低下することがあります。マルチスライスは、追加の設定なしで有効に機能するスループットが最適化されたソフトウェア スタックによって、スケーリングを簡素化します。ユーザーは、複雑さの管理ではなく AI モデルのトレーニングに集中できます。その結果、大規模なスケーリングでも優れたデベロッパー エクスペリエンスを実現できます。単一スライスのジョブで使い慣れているプロファイリング ツールやオーケストレーション ツールと統合することで、セットアップ時間をさらに短縮できます。
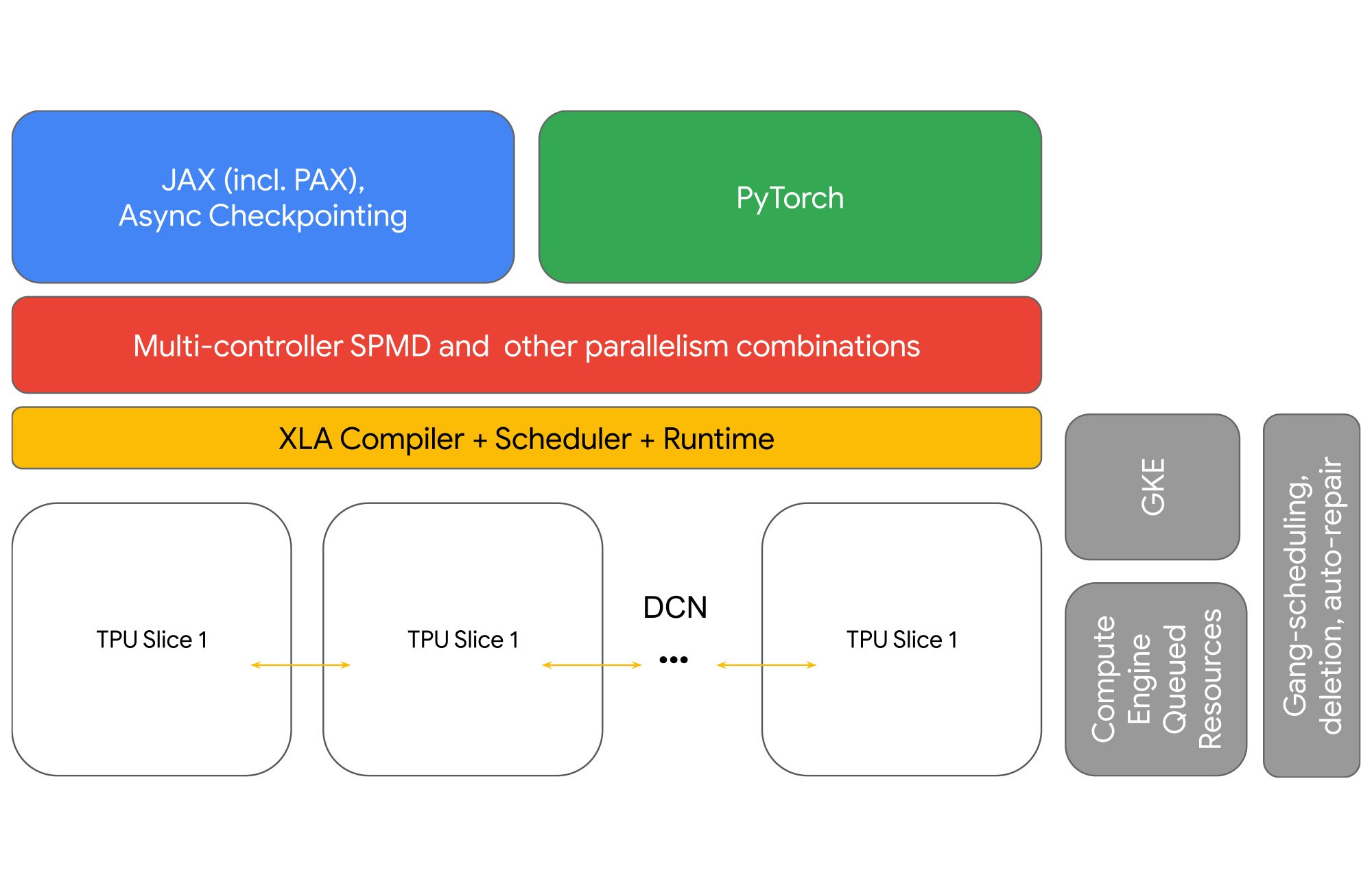
GSPMD を使用すると、シャーディング軸を操作してテンソル、データ、FSDP 並列処理を切り替えるだけで、スライスを 2 個から 2,000 個に増やすことができます。そのため、マルチスライス ワークロードに合わせてランタイムとインフラストラクチャの残りの部分を調整し、DCN に JAX と PyTorch 向けの新しいシャーディング ディメンションを導入しました。
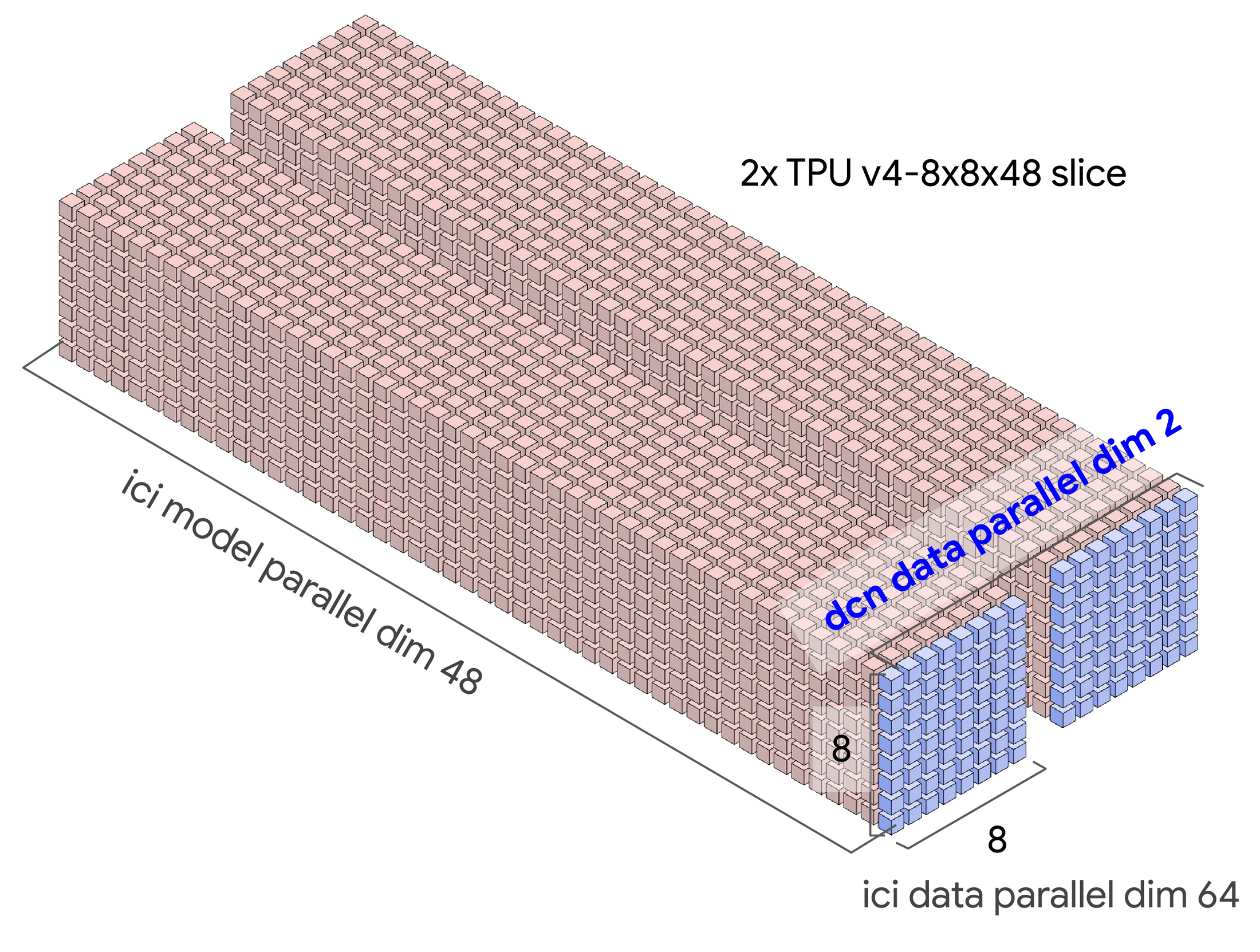
Google では、GSPMD 用語である「メッシュ」を使用しています。分散しているデバイスを複数のディメンションで論理的に編成したものと定義されており、デバイス全体にモデル マトリックス ディメンションを割り当てるように構成できます。
以下の表は、2 つのスライスの構成オプションの例を示しています。各スライスとも、簡単なデータ並列処理を備え、DCN がデータ並列処理軸にマッピングされています。
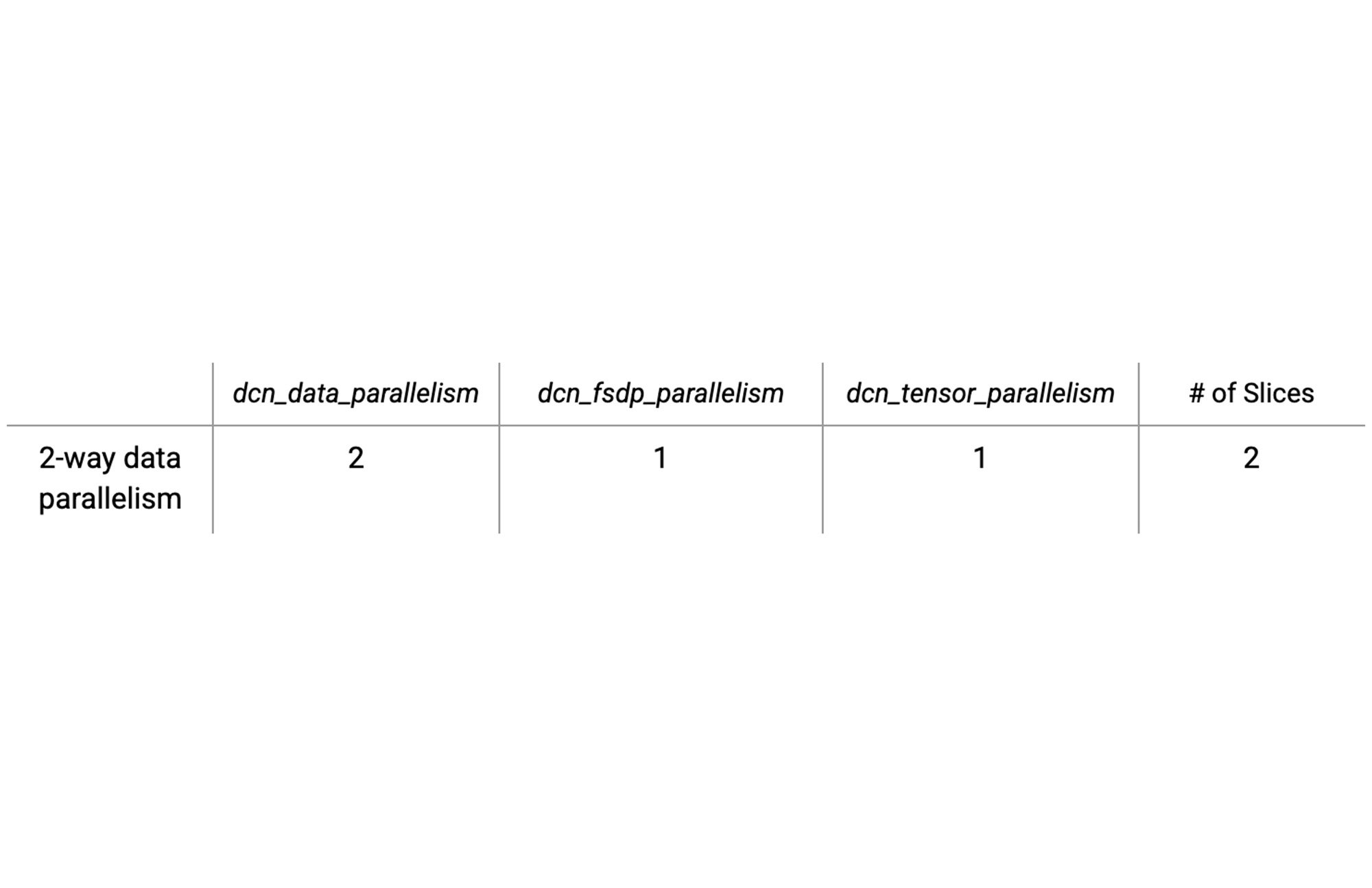
こうした並列処理タイプの値を計算するのは簡単です。並列処理変数 dcn と ici の積がチップの総数になることを確認するだけです。
また、XLA コンパイラは、基盤となるハイブリッド DCN / ICI ネットワーク トポロジを認識するため、適切な階層集団演算を自動的に挿入できるほか、単一スライス演算をマルチスライス階層集団演算に変換して、コンピューティングと通信のオーバーラップを改善できます。
例として、all-reduce 演算を考えてみます。コンパイラは、この演算を次の 3 段階の階層集団演算に自動的に分解します。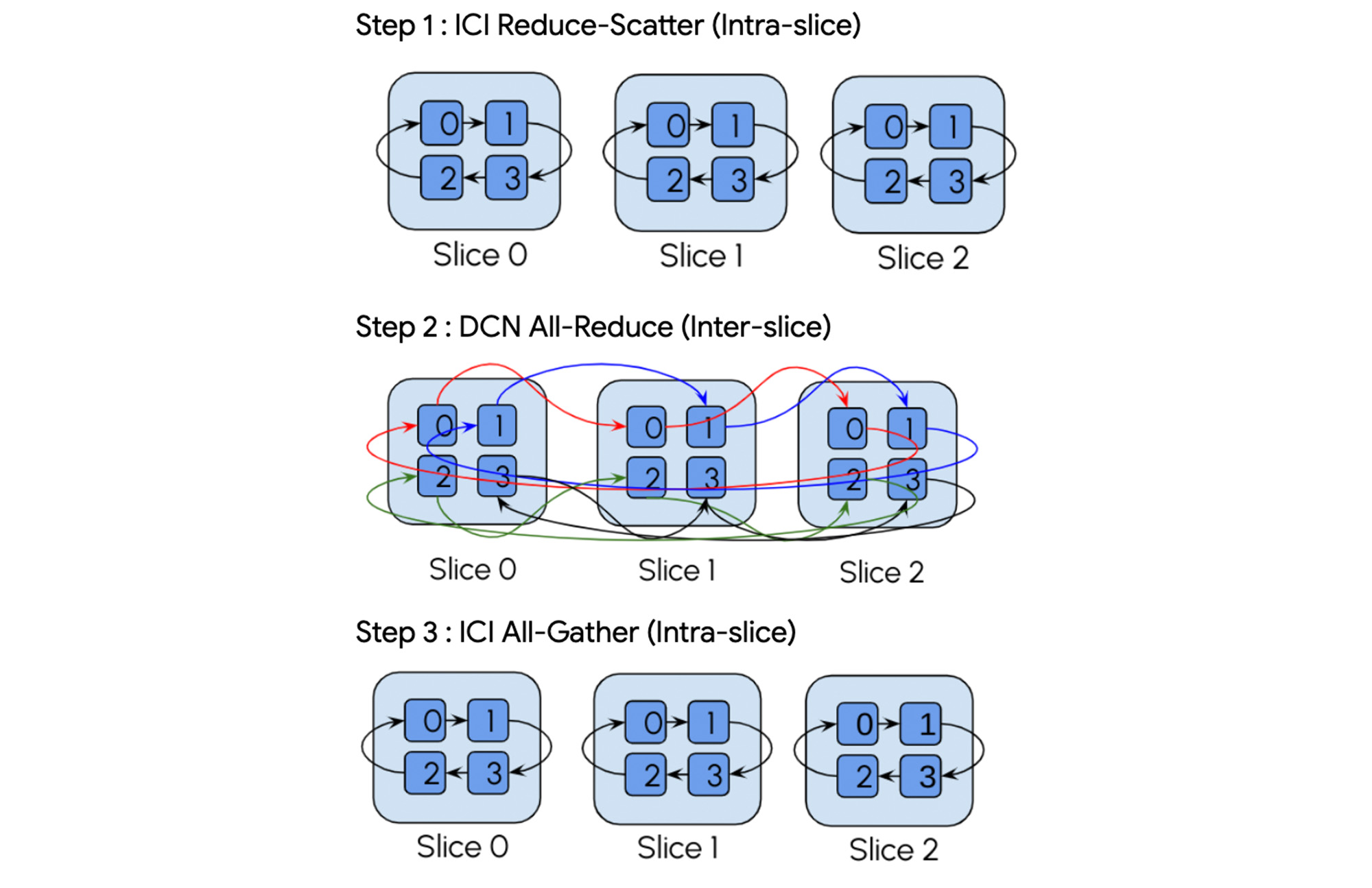
「マルチスライス トレーニングは、ゲーム チェンジャーの役割を果たしてきました。データセンター ネットワーキングを使用して、高密度に相互接続された単一のスライスを超えて当社の ML ワークロードを簡単にスケーリングできます。JAX XLA のおかげで、追加の設定なしで容易にセットアップし、パフォーマンスを高めることができます。」 - Character AI 社共同創立者、Myle Ott 氏
マルチスライスは、JAX と PyTorch フレームワークをサポートしています。追加の設定なしで高速のパフォーマンスが得られるように、すべてのモデルをサポートするコンパイラだけでなく、LLM 向けに MaxText と PAX も用意されています。オープンソースの十分にテストされたサンプルも利用できます。ピュア Python と JAX で書かれたサンプルであり、スターター コードとして使用できます。PAX は、大規模なモデルをトレーニングするためのフレームワークです。高度なテストと並列処理を完全に構成でき、業界をリードする MFU 率を実証しています。MaxText は、フォークと適応を目的した最小限のフレームワークです。単一スライスのコードと比べて、DCN 並列処理用にシャーディング ディメンションが追加されていることが唯一異なるコードです。
ハイ パフォーマンス ネットワーキング
マルチスライスは、Google の Jupiter データセンター ネットワークで AllReduce、Broadcast、Reduce、AllGather、ReduceScatter の各集団通信演算をサポートしています。2022 年 8 月に報告したように、Jupiter は前世代の Google データセンター ネットワークに比べてフロー完了時間を 10% 削減し、スループットを 30% 高めています。その一方で、消費電力を 40%、資本支出コストを 30% それぞれ削減し、ダウンタイムを 50 分の 1 に抑えています。3
管理が容易
マルチスライス ジョブを管理する方法として、2 つの選択肢が用意されています。Compute Engine Queued Resource CLI と API を使用する方法と、Google Kubernetes Engine(GKE)を使用する方法です。
1 回のステップでスライスのコレクションを削除および作成できる特別な選択肢もあります。また、高速復旧により、個々のスライスが中断しても、ジョブがすばやく再開されます。
高い信頼性とフォールト トレラント
モデル トレーニング ジョブは、個々のスライスが失敗しても、前回のチェックポイントから自動的に再開されます。マルチスライスを GKE で使用すると、障害復旧時のエクスペリエンスがさらに向上します。具体的には、yaml ファイルのフィールドを 1 つ変更するだけで、エラー発生時に自動的に再試行が実施されます。
「Google Cloud の TPU マルチスライスのおかげで、追加の設定なしですぐに生産性と効率が大幅に向上し、言語モデルのトレーニングを問題なくスケーリングできるようになりました。マルチスライスは、大規模な生成言語 AI モデルを構築する誰にでもおすすめできます。」 - Stability AI 社 CEO、Emad Mostaque 氏
使ってみる
マルチスライスは、大規模な AI モデルを効率的にトレーニングすることを目的に設計されたものです。AI ワークロードをスケーリングするには、ハードウェアとソフトウェアが協調して機能する必要があります。Google では、AI 開発の生産性を常に念頭に置いています。Cloud TPU v4 と新たに発表した Cloud TPU v5e のプレビューでぜひマルチスライスをお試しください。
PAX と MaxText を使用して Cloud TPU をマルチスライスで試す方法と詳しい内容については、Google Cloud アカウント担当者にお問い合わせください。
1. 2023 年 8 月現在 Google 内部データ
2. 2023 年 8 月現在 Google 内部データ
3. 2023 年 8 月現在 Google 内部データ
- ソフトウェア エンジニアリング マネージャー、Andi Gavrilescu
