GPU のコストを削減: GKE の推論ワークロード向けのスマートな自動スケーリング
Anna Pendleton
Software Engineer
Luiz Oliveira
GKE Software Engineer
※この投稿は米国時間 2024 年 10 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
LLM モデルが多大な価値をもたらすユースケースの数は増えているものの、LLM 推論ワークロードの実行にはコストがかかります。最新のオープンモデルとインフラストラクチャを活用している場合、自動スケーリングによってコストを最適化することで、必要な AI アクセラレータの料金のみを支払いつつ、顧客の需要を確実に満たせます。
マネージド コンテナ オーケストレーション サービスの Google Kubernetes Engine(GKE)を使用すると、LLM 推論ワークロードのデプロイ、管理、スケールが容易になります。GKE 上で推論ワークロードを設定する際には、HorizontalPodAutoscaler(HPA)の使用をご検討ください。HPA は、モデルサーバーが負荷に応じて適切にスケールできるようにする効率的かつシンプルな方法です。HPA の設定をファインチューニングすることで、プロビジョニングしたハードウェアのコストを受信トラフィックの需要に合わせ、推論サーバーのパフォーマンス目標を達成できます。
LLM 推論ワークロード向けに自動スケーリングを構成することは困難な場合もあります。そこで、ベスト プラクティスを提供するために、ai-on-gke/benchmarks を利用して GPU 上の自動スケーリングに関する複数の指標を比較しました。この設定では、Text-Generation-Inference(TGI)モデルサーバーと HPA を使用します。なお、以下の実験は同様の指標を実装する他の推論サーバー(vLLM など)にも適用できます。
適切な指標の選択
以下に、Cloud Monitoring ダッシュボードで可視化した指標比較の実験例をいくつか示します。各実験では、g2-standard-16 マシンのシングル L4 GPU 上で HPA のカスタム指標 Stackdriver アダプタを使用して TGI を Llama 2 7b とともに実行し、ai-on-gke locust-load-generation ツールを使用して、さまざまなリクエスト サイズのトラフィックを生成しました。以下に示す各実験のトラフィック負荷は一定にしました。以下のしきい値は実験を通じて特定したものです。
mean-time-per-token(トークンあたりの平均時間)のグラフは、プリフィルとデコードの合計時間を、リクエストごとに生成された出力トークン数で割った TGI の指標です。この指標により、異なる指標を使用した自動スケーリングがレイテンシに与える影響を比較できます。
GPU 使用率
自動スケーリングのデフォルトの指標は、CPU 使用率またはメモリ使用率です。これらの指標は CPU 上で実行されるワークロードには有効です。しかし、推論サーバーの場合、これらの指標を単独で使用してもジョブのリソース使用率を適切に把握することはできません。推論サーバーは主に GPU に依存するためです。GPU の同等の指標は GPU 使用率です。GPU 使用率は GPU デューティ サイクル、つまり GPU がアクティブな時間を表します。
以下のグラフは、ターゲット値のしきい値を 85% に設定した場合の、GPU 使用率に基づく HPA 自動スケーリングの結果を示しています。

GPU 使用率のグラフには、リクエストの mean-time-per-token グラフとの明確な関係はありません。リクエストの mean-time-per-token が減少しても GPU 使用率は増加し続け、継続的に HPA のスケールアップを引き起こしています。LLM の自動スケーリングの場合、GPU 使用率は有効な指標ではありません。この指標を推論サーバーで現在発生しているトラフィックと対応付けることは困難です。GPU デューティ サイクル指標では FLOPS 使用率を測定できないため、アクセラレータの作業量や、アクセラレータが最大容量で動作しているタイミングは把握できません。GPU 使用率は、以下の他の指標と比較してオーバープロビジョニングされる傾向があり、コスト面で非効率的です。
つまり、推論ワークロードの自動スケーリングに GPU 使用率指標を使用することは推奨しません。
バッチサイズ
GPU 使用率指標の制約を踏まえて、TGI で提供される LLM サーバー指標も検討しました。これらの LLM サーバー指標は、一般的な推論サーバーで、すでに提供されているものです。
この実験で選択したオプションの一つはバッチサイズ(tgi_batch_current_size)で、この指標は推論の反復処理ごとに処理されたリクエスト数を表します。
以下のグラフは、ターゲット値のしきい値を 35 に設定した場合の、現在のバッチサイズに基づく HPA 自動スケーリングの結果を示しています。

現在のバッチサイズのグラフとリクエストの mean-time-per-token グラフには直接的な関係があり、バッチサイズが小さいほどレイテンシは低くなります。バッチサイズは、低レイテンシに最適化するための優れた指標であり、推論サーバーで現在処理中のトラフィック量を直接示しています。現在のバッチサイズ指標の制約は、最大バッチサイズ(ひいては最大スループット)の達成を目指す場合にスケールアップをトリガーすることが容易でなかった点です。バッチサイズは、さまざまな受信リクエスト サイズごとにわずかに変化する可能性があるためです。HPA で確実にスケールアップをトリガーするためには、最大バッチサイズより若干小さい値を選択する必要がありました。
特定のテール レイテンシをターゲットにしたい場合は、現在のバッチサイズ指標を利用することを推奨します。
キューサイズ
この実験で選択した TGI の LLM サーバー指標のもう一つのオプションはキューサイズ(tgi_queue_size)です。キューサイズは、現在のバッチに追加されるまで推論サーバーキューで待機しているリクエスト数を表します。
以下のグラフは、ターゲット値のしきい値を 10 に設定した場合の、キューサイズに基づく HPA スケーリングの結果を示しています。

* Pod 数の一時的な減少は、デフォルトの 5 分間の安定化期間が終了した後に HPA でダウンスケールをトリガーした際に発生しています。トラフィックの需要に合わせて、この安定化期間やその他のデフォルトの HPA 構成オプションは簡単にファインチューニングできます。
キューサイズのグラフとリクエストの mean-time-per-token グラフの間には直接的な関係が見られ、キューサイズが大きいほどレイテンシは高くなります。キューサイズは推論ワークロードの自動スケーリングの優れた指標であり、推論サーバーによる処理を待機中のトラフィック量を直接示していることがわかりました。キューサイズの増大は、バッチが上限に達していることを示しています。キューサイズは、現在処理中のリクエスト数ではなく、キューに残っているリクエスト数のみに関連しているため、キューサイズに基づく自動スケーリングでは、バッチサイズほどの低レイテンシは達成できません。
テール レイテンシを制御しながらスループットを最大化したい場合には、キューサイズ指標を利用することを推奨します。
ターゲット値のしきい値の特定
キューサイズ指標とバッチサイズ指標の有効性をさらに示すために、ai-on-gke/benchmarks の profile-generator を使用して、これらの実験に使用するしきい値を特定しました。しきい値は以下に従って選択しました。
-
最適なスループット ワークロードを表すため、レイテンシのみが増加し、スループットが増加しなくなった時点のキューサイズを特定しました。
-
レイテンシの影響を受けやすいワークロードを表すため、最適なスループットの約 80% のレイテンシしきい値でバッチサイズを自動スケールすることにしました。
以下は、ai-on-gke/benchmarks の profile-generator のデータを使用して作成した、スループットとレイテンシの関係を表したグラフです。
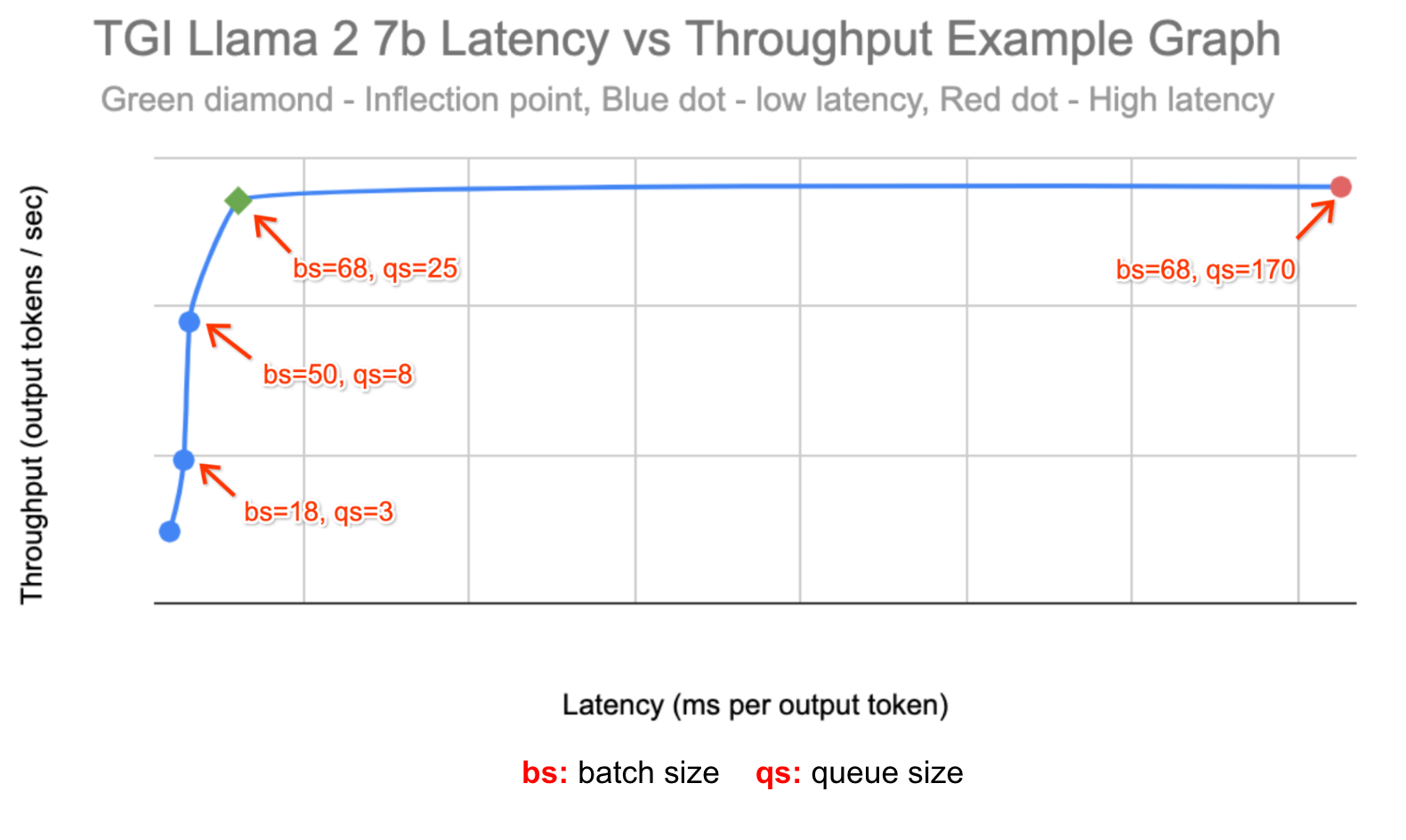
各実験では、2 台の g2-standard-96 マシンのシングル L4 GPU 上で HPA のカスタム指標 Stackdriver アダプタを使用して TGI と Llama 2 7b を実行し、1~16 の範囲でレプリカの自動スケーリングを有効にしました。ai-on-gke locust-load-generation ツールを使用して、さまざまなリクエスト サイズのトラフィックを生成しました。レプリカ数が約 10 で安定化する負荷を特定したうえで、負荷を 150% 増加させてトラフィックの急増をシミュレートしました。
キューサイズ
以下のグラフは、ターゲット値のしきい値を 25 に設定した場合の、キューサイズに基づく HPA スケーリングの結果を示しています。
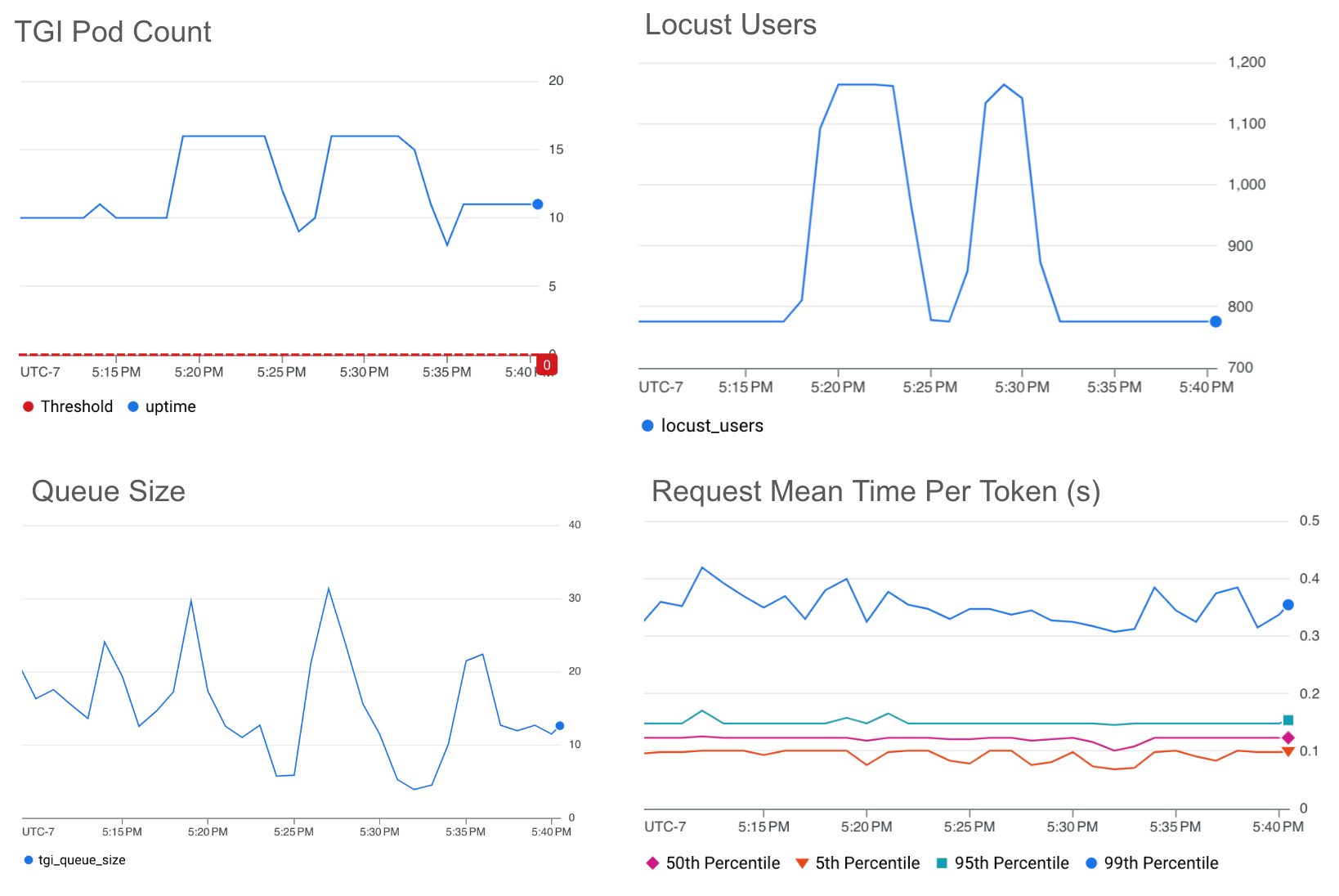
選択したターゲット値のしきい値では、トラフィックが 150% 急増しても、mean-time-per-token を約 0.4 秒以下に維持できています。
バッチサイズ
以下のグラフは、ターゲット値のしきい値を 50 に設定した場合の、バッチサイズに基づく HPA スケーリングの結果を示しています。
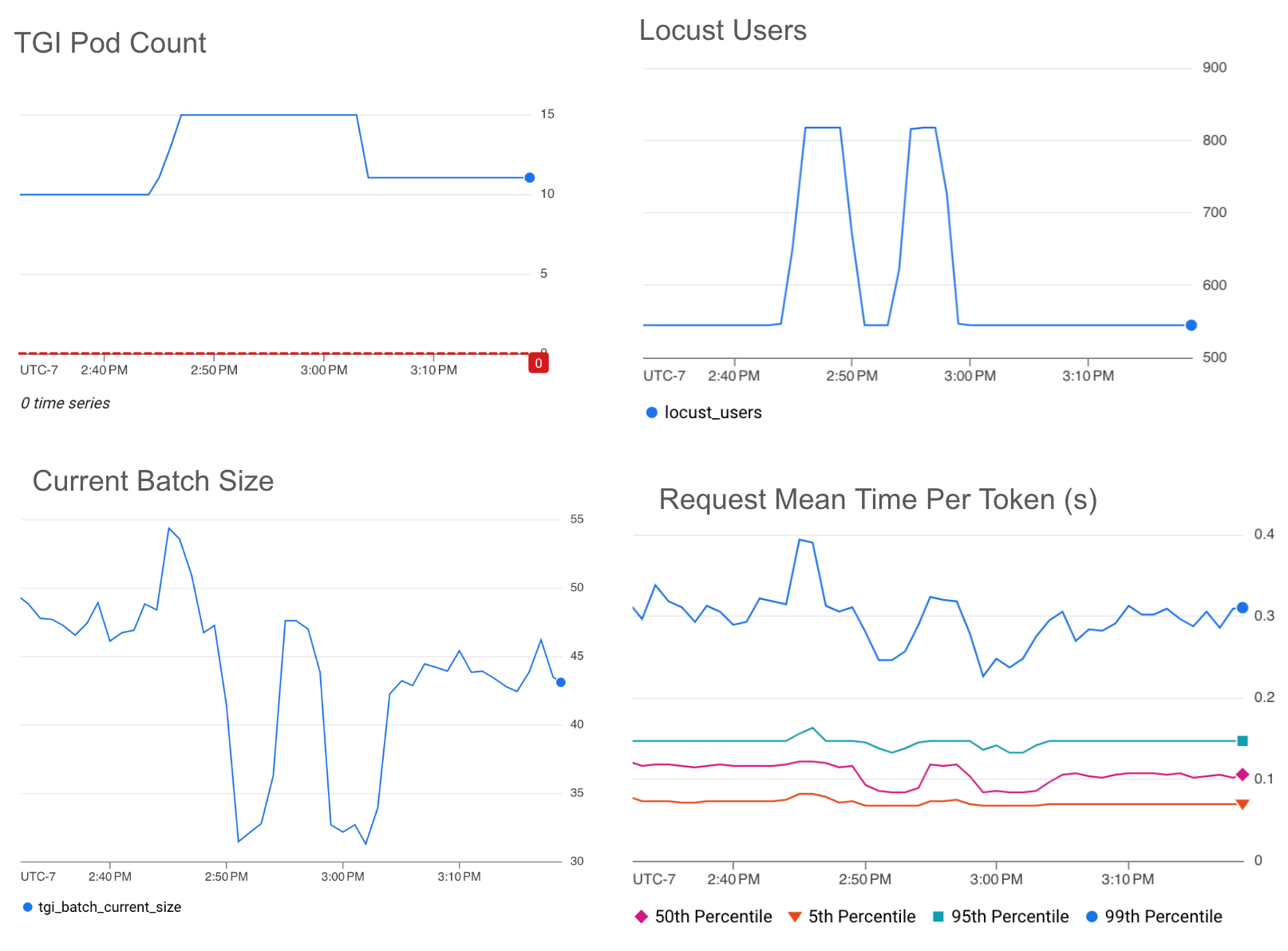
* 平均バッチサイズが 60% 近く低下した箇所は、トラフィックが約 60% 減少したことを反映しています。
選択したターゲット値のしきい値では、トラフィックが 150% 急増しても、mean-time-per-token を約 0.3 秒以下に維持できています。
バッチサイズのしきい値を最大スループットの約 80% にすることで、キューサイズのしきい値を最大スループットにした場合と比較して、mean-time-per-token を約 80% 未満に維持しています。
自動スケーリングの改善に向けて
GPU 使用率による自動スケーリングでは、LLM ワークロードをオーバープロビジョニングし、パフォーマンス目標を達成するために不必要な追加コストが発生する可能性があります。
LLM サーバー指標による自動スケーリングでは、アクセラレータのコストを最小限に抑えながら、レイテンシ目標やスループット目標を達成できます。バッチサイズを使用すると、特定のテール レイテンシをターゲットにできます。キューサイズを使用すると、スループットを最適化できます。
上記のベスト プラクティスを利用して独自の LLM 推論サーバーの自動スケーリングを設定する方法については、Google Kubernetes Engine で GPU 上の LLM ワークロードの自動スケーリングを構成するに記載されている手順を実施してください。
ー ソフトウェア エンジニア Anna Pendleton
ー ソフトウェア エンジニア Luiz Oliveira
