AI ファーストな未来に向けたインフラストラクチャの大規模イノベーション

Mark Lohmeyer
VP & GM, AI & Computing Infrastructure
※この投稿は米国時間 2024 年 10 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
生成 AI の台頭によって、過去に例のないほどのイノベーションの時代の幕が開き、複雑でより高性能な AI モデルがますます求められるようになりました。これらの高度なモデルには、AI トレーニングのスケーリング、チューニング、ワークロードの推論を効率的に実施できる高性能なインフラストラクチャが必要となる一方で、システム パフォーマンスと費用対効果の両方を最適化しなければなりません。
ここ十年余りにわたって、Google Cloud は AI インフラストラクチャのパイオニアであり続けており、その結果として AI ハイパーコンピュータと呼ばれる統合アーキテクチャが生まれました。このアーキテクチャでは、ワークロードに最適化されたハードウェア(TPU、GPU、CPU)、オープン ソフトウェア、柔軟な消費モデルをシームレスに統合し、高度な AI モデルの活用につなげます。この包括的なアプローチによって、多岐にわたるモデルとアプリケーション全体で最善のスケール、パフォーマンス、効率性が得られるように、スタックの全レイヤを最適化します。Google Cloud が Forrester の AI Infrastructure Wave でリーダーに指名された理由は多数ありますが、AI ハイパーコンピュータはそのひとつです。つい先週、Google Cloud は Gartner Magic Quadrant の Strategic Cloud Platform Services 部門においてもリーダーに選出されました。連続 2 年目の選出となる Google は、ビジョンと実行能力の両方を向上させる唯一のリーダーです。
Google は今年、お客様にとってのパフォーマンス、使いやすさ、費用対効果の向上に向けて、AI ハイパーコンピュータ スタック全体を強化しています。今回の App Dev & Infrastructure Summit では、以下を発表いたします。
-
Google の第 6 世代 TPU、Trillium のプレビュー版を公開
-
NVIDIA H200 Tensor Core GPU による A3 Ultra VM のプレビュー版が来月公開
-
Google のスケーラビリティに優れた新クラスタリング システム、Hypercompute Cluster が、A3 Ultra VM から利用開始予定
-
Google のカスタム Arm プロセッサ、Axion ベースの C4A VM が一般提供
-
Google のデータセンター ネットワークである Jupiter と、ホストへのオフロード機能である Titanium を、AI ワークロード重視で強化
-
Google の AI / ML を中心としたブロック ストレージ サービスとなる Hyperdisk ML が一般提供
Trillium: TPU パフォーマンスを新次元へ
TPU は、Gemini など最先端のモデルや、検索、フォト、マップといったよく使用される Google サービス、さらに最近のノーベル賞受賞をもたらした AlphaFold 2 などの科学的ブレークスルーを支えています。このたび、Google の第 6 世代 TPU となる Trillium のプレビュー版を、Google Cloud のお客様向けに公開することを発表します。
Trillium は TPU v5e と比較して:
-
トレーニングのパフォーマンスが 4 倍余り向上
-
推論スループットが最大で 3 倍向上
-
エネルギー効率が 67% 向上
-
チップあたりのピーク コンピューティング パフォーマンスが 4.7 倍も向上
-
高帯域幅メモリ(HBM)容量が 2 倍
-
チップ間相互接続(ICI)帯域幅が 2 倍
HBM 容量と帯域幅が倍増したことで、Trillium は、重み付けと Key-Value キャッシュのより大きな大規模モデルを、さらに効果的に処理できるようになりました。Trillium はコンピューティングから HBM までが高速で、トレーニングと推論の多彩なモデル アーキテクチャにとって理想的であり、混合エキスパート(MoE)の実装だけでなく、Gemma 2 や Llama などの高密度な大規模言語モデル(LLM)のトレーニングに特に役立ちます。Trillium はさらに、Stable Diffusion XL のような大規模な拡散モデルを含む、コンピューティング負荷の高い推論に優れています。
高速なチップ間相互接続(ICI)により、Trillium は高帯域幅かつ低レイテンシの単一 Pod 内で 256 チップまでスケールアップが可能です。ここからさらに、Jupiter の 13 ペタビット/秒のデータセンター ネットワークで相互接続された、建物規模のスーパーコンピュータの数万に及ぶチップを接続することで、数百 Pod にスケールできます。マルチスライス ソフトウェアにより、Trillium は、数百の Pod 全体で、トレーニング ワークロードのパフォーマンスをほぼ線形にスケールすることが可能です。Trillium はかつてないほどフロップ密度の高い TPU です。単一の TPU クラスタ内に前例のない規模の 91 エクサフロップが詰め込まれており、TPU v5p で Google がビルドした最大クラスタの 4 倍もあります。
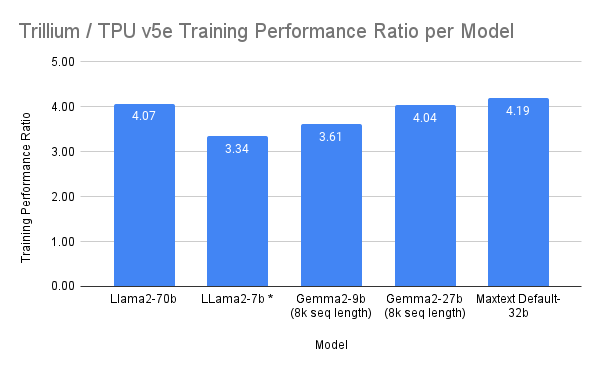
ベンチマーク テストでは、Trillium によるトレーニング パフォーマンスは TPU v5e と比較して、Gemma 2-27b、MaxText Default-32b、Llama2-70B で 4 倍以上、LLama2-7b、Gemma2-9b で 3 倍以上、向上しました。
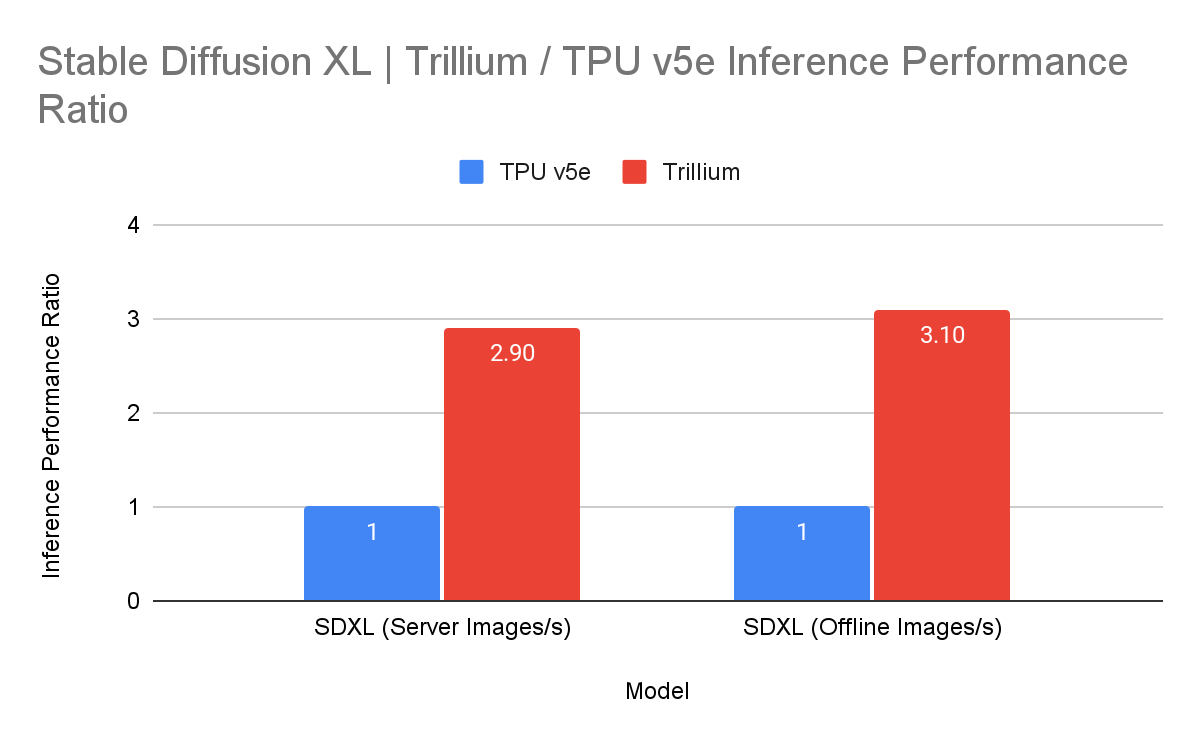
Stable Diffusion XL の推論スループットも、Trillium では TPU v5e と比較して 3 倍、向上しました。
Google は TPU を、1 ドルあたりのパフォーマンスを最適化できるように設計しています。Trillium も例外ではなく、その 1 ドルあたりのパフォーマンスは v5e と比較して 1.8 倍近く、v5p と比較して約 2 倍の向上を示しています。ですから、Trillium はこれまでで最も費用対効果に優れた Google の TPU と言えます。

お客様の声
Trillium を使用し、その結果を目の当たりにしたお客様からは、熱烈な反響が寄せられています。
「Deep Genomics は、これまで治療法がなくアンメット ニーズが高い疾患に向けた次世代 RNA 治療薬をデザインするために、AI 基盤モデルのプラットフォームを構築中です。Deep Genomics 独自の最初の基盤モデルである BigRNA は、RNA 治療の発見における当社のリーダーシップを支えています。BigRNA は、遺伝子制御と RNA 発現の背後にある組織特異的な制御メカニズムを、タンパク質およびマイクロ RNA の結合部位を含めて正確に予測します。Google の Trillium TPU を使用することで、BigRNA 推論をヒトゲノムの数千万のバリアントで実行し、細胞の状態を健全化または異常化させる生体信号を何兆も生成しました。過去に例のないこのデータベースは、Deep Genomics とそのパートナーが、複雑でまれな病気に対する新しい RNA 治療を見出すために役立つでしょう。」- Deep Genomics、VP 兼 ML 責任者、Joel Shor 氏
「HubX はテクノロジー ハブです。ワールドクラスの専門家が最先端テクノロジーで次世代のアプリをビルドしています。Trillium TPU は MaxDiffusion と FLUX.1 でのテキスト画像変換生成に利用しており、その結果はすばらしいものです。この TPU で 4 つの画像を 7 秒で生成できました。現行システムと比較して、レスポンスのレイテンシは 35% の向上、画像当たりコストは約 45% の節減となります。2025 年には、世界中で HubX のアプリを使用している数百万のユーザーの皆様に、まずはフラッグシップの Nova と DaVinci からこれらの改善を実際に体験していただける予定です。」- HubX、開発責任者、Deniz Tuna 氏
「Lightricks では、Cloud TPU v4 以来、TPU をテキスト画像変換モデルとテキスト動画変換モデルに使用してきました。TPU v5p と AI ハイパーコンピュータの効率化により、トレーニング速度が 2.5 倍も向上しました。第 6 世代の Trillium TPU は、前の世代に比べてチップあたりのコンピューティング パフォーマンスが 4.7 倍、HBM の容量と帯域幅が 2 倍に向上しています。テキスト動画変換モデルを拡大しようしていた私たちにとって、ちょうどよいタイミングでした。Dynamic Workload Scheduler の Flex Start モードを使用して、バッチ推論ジョブや将来の TPU 予約を管理することも計画しています。」- Lightricks、コア生成 AI リサーチ チーム リーダー、Yoav HaCohen 博士
「SkyPilot は、組織が AI ワークロードをシームレスかつ高い費用対効果で、リージョン間横断的にさまざまなアクセラレータで実施できるようにします。ますます多くのお客様が、基盤モデルのトレーニングに Google Cloud の Trillium TPU を利用し、役立てているのを見てきました。前世代の TPU からも移行しやすく、Trillium のパフォーマンスおよび費用対効果と組み合わせれば、お客様のモデル開発と試験運用を促進できます。」- SkyPilot、プロジェクト リーダー、Zongheng Yang 氏
NVIDIA の高速コンピューティングで対象領域を拡大
Google はまた、NVIDIA とのパートナーシップおよびこのパートナーシップで提供できる機能に引き続き投資します。Google Cloud の優れたデータセンター、インフラストラクチャ、ソフトウェア分野での専門性を、NVIDIA H100 Tensor Core GPU に支えられた A3 および A3 Mega VM に代表される NVIDIA の AI プラットフォームと組み合わせます。
このたび、Google はこのポートフォリオを拡大し、NVIDIA H200 Tensor Core GPU による A3 Ultra VM を新たに加えることをお知らせします。来月から Google Cloud で利用できるようになります。
A3 Ultra VM はパフォーマンス面で前世代から飛躍的に進歩しています。Google の新しい Titanium ML ネットワーク アダプタを備えたサーバー上にビルドされており、セキュアで高性能なクラウド体験を、NVIDIA ConnectX-7 ネットワーク インターフェース カード(NIC)と、このカード上でのビルドも含めた AI ワークロードに提供できるように最適化されています。Google のデータセンター全体の、4 方向のレールに沿ったネットワークと組み合わせると、A3 Ultra VM は、RDMA over Converged Ethernet(RoCE)で、GPU 間での 3.2 Tbps の非ブロッキング トラフィックを達成します。
A3 Mega と比較して、A3 Ultra は:
-
Google Cloud の Titanium ML ネットワーキング アダプタで強化し、Jupiter データセンター ネットワークで支えることで、GPU 間のネットワーキング帯域幅が 2 倍に増加
-
メモリ容量がほぼ 2 倍になり、メモリ帯域幅が 1.4 倍に増加したことで、LLM 推論のパフォーマンスが最大 2 倍に向上
-
大規模な AI および HPC ワークロード向けに、高密度で最適化されたパフォーマンスを誇るクラスタ内で数万 GPU までスケールアップが可能
A3 Ultra VM は今後、Google Kubernetes Engine(GKE)からも利用できるようになり、移植可能、拡張可能でスケーラビリティに優れたオープンなプラットフォームを、大規模な AI ワークロードのトレーニングと提供に役立てられます。
A3 Ultra VM の初期のテストの一部を担うのは、JetBrains などの組織です。
「JetBrains AI アシスタントはデベロッパー タイプに合わせたコード候補リストをリアルタイムで提供するため、シームレスなユーザー エクスペリエンスのためにレイテンシの最小化が重要です。JetBrains は NVIDIA H100 Tensor Core GPU による A3 Mega GPU を Google Cloud で使用し、複数リージョンにわたり ML サービスを提供してきました。これから NVIDIA H200 Tensor Core GPU による A3 Ultra VM でさらにレイテンシを下げ、JetBrains AI アシスタントの応答性を強化できる見込みですので、試用を楽しみにしています。」- JetBrains、ML チームリーダー、Uladzislau Sazanovich 氏
Hypercompute Cluster: AI アクセラレータ クラスタの合理化とスケーリング
これは個別のアクセラレータや VM だけの話ではありません。非常に多くの AI アクセラレータをデプロイして管理、最適化する必要のある AI ワークロードと HPC ワークロード、それらに関連するネットワーキングとストレージまで含むため、複雑になり、時間もかかる可能性があります。だからこそ、Google はこのたび、インフラストラクチャとワークロードのプロビジョニング、そして進行中の AI スーパーコンピュータのオペレーションを最大数万のアクセラレータで合理化する、Hypercompute Cluster を発表することにしました。Hypercompute Cluster の中心部では、Google Cloud の最先端の AI インフラストラクチャ技術が組み合わされており、非常に多くのアクセラレータを単一ユニットとしてシームレスにデプロイし、管理できます。Hypercompute Cluster は、超低レイテンシ ネットワーキングでの高密度なリソースのコロケーション、ターゲット設定によるワークロード配置、そして高度なメンテナンス管理でワークロード停止を最小限に抑えるといった特長を備えており、卓越したパフォーマンスとレジリエンスを提供できるため、特に高負荷な AI や HPC のワークロードも安心して実行できます。
Hypercompute Cluster は事前に構成された検証済みのテンプレートから、単一の API 呼び出しで設定でき、信頼性と再現性のあるデプロイが可能です。コンテナ化されたソフトウェアと、フレームワークおよびリファレンス実装(JAX、PyTorch、MaxText など)、オーケストレーション(GKE、Slurm など)、一般的なオープンモデル(Gemma2、Llama3 など)も含まれます。お客様がビジネスを成長させるためのイノベーションに集中できるように、それぞれの事前構成済みテンプレートは AI ハイパーコンピュータ アーキテクチャの一部としてアクセスでき、パフォーマンスと効率性は検証済みです。
Hypercompute Cluster は来月、A3 Ultra VM での利用から提供開始となります。
今後の予定を一部ご紹介: NVIDIA GB200 NVL72
Google は NVIDIA GB200 NVL72 GPU によって可能になる技術的進歩にも期待を寄せています。この開発についてさらに詳細な更新情報を、近々お伝えできることを楽しみにしています。それまでにお伝えできることとして、NVIDIA Blackwell プラットフォームのパフォーマンス上のメリットを、来年初旬に Google Cloud の先進的でサステナブルなデータセンターに取り入れるために構築中のラックについて、少しだけご紹介します。

Google Axion プロセッサ: CPU のパフォーマンスと効率性を再定義
TPU と GPU が特定タスクに優れている一方で、CPU は費用対効果が高く、汎用ワークロードに幅広く対応できる選択肢です。複雑なアプリケーションを提供するために、AI ワークロードと連携して使用されることもよくあります。Google Cloud Next ‘24 で発表された Google Axion プロセッサは、Google 初の Arm® ベースのカスタム CPU で、データセンター向けに設計されています。現在、Google Cloud のお客様は、初の Axion ベース VM シリーズであるC4A 仮想マシンを活用し、他の主要なクラウド プロバイダで利用できる最新世代の Arm ベース インスタンスと比べて最大 10% 高い費用対効果を得られます。また、C4A は現行世代の x86 ベース インスタンスと比べて、ウェブサーバーやアプリサーバー、コンテナ化されたマイクロサービス、オープンソース データベース、インメモリ キャッシュ、データ分析エンジン、メディア処理、AI 推論アプリケーションなどの汎用ワークロードで最大 65% 費用対効果が高く、最大 60% エネルギー効率に優れています。
C4A に対して、お客様とパートナーからすでに大きな反響をいただいています。
「Paramount+ は、全プラットフォームで最高品質の視聴体験を提供するために力を尽くしています。Google Cloud の Axion VM と C4A VM は、動画エンコード技術における最新の技術的進歩を活用するために必要なパフォーマンスと効率性をもたらしてくれています。C4A VM によって新しい Arm プロセッサのより高い効率性を活かし、旧来の VM と比較してエンコード時間を 33% 短縮できました。これで動画の品質、精彩な画面、臨場感のある音響に重点を置いたまま、視聴者のデバイスや接続性を問わず、確実に大きな規模でコンテンツをエンコードし、すばやく配信することができます。」- Paramount Streaming、動画エンジニアリング VP、Jignesh Dhruv 氏
「loveholidays は旅行業界で最速のウェブサイトのひとつです。Axion によって、コスト最適化のためにパフォーマンスを犠牲にしなくても済むようになりました。これまでにないパフォーマンスのレベルを達成し、T2D インスタンスと比較して 40% レイテンシが下がり、一方で容量にかかる費用も節約できました。」- loveholidays、エンジニアリング責任者、Dmitri Lerko 氏
AI モデルとしてカウントされるすべての単位時間あたり作業で、パワーとパフォーマンスがさらに求められています。Google のシリコン設計における専門性を、Arm Neoverse の柔軟性と組み合わせることで、C4A VM は多種多様な主要ワークロード全体でパフォーマンスと効率性を大幅に向上させます。ソフトウェア最適化も、AI の能力を加速度的に向上させるために重要です。また、Google のオープンな Arm Kleidi テクノロジーを主要なフレームワークに統合するといった取り組みにより、C4A では、Google Cloud 上で稼働する前世代の Arm ベース VM と比較して、さまざまな AI 推論ワークロードで最大 2~3 倍も高いパフォーマンスが得られます。」- Arm、インフラストラクチャ部門シニア バイスプレジデント兼ゼネラル マネージャー、Mohamed Awad 氏
Titanium と Jupiter ネットワーク: 光の速さで AI を有効化
Titanium についてもお知らせがあります。Google のインフラストラクチャを支えているこのオフロード技術のシステムは、AI ワークロード支援のため拡張されてきました。Titanium はオンホストとオフホストのオフロードを組み合わせることでホストでの処理のオーバーヘッドを軽減し、ワークロードで使用できるコンピューティング リソースとメモリリソースを増やしています。また、AI インフラストラクチャは Titanium のあらゆる中核機能から恩恵を得られるものの、AI ワークロードはそのアクセラレータ間でのパフォーマンス要件において特異的です。
これらのニーズを満たすために、Google は新たに Titanium ML ネットワーク アダプタを導入しました。これは NVIDIA ConnectX-7 NIC を搭載し、VPC、トラフィックの暗号化、仮想化をさらに支援します。Google のデータセンター全体で 4 方向のレールに沿ったネットワークと統合した場合、このシステムは RoCE を介して GPU 間で 3.2 Tbps の非ブロッキング トラフィックを達成し、最高水準のセキュリティとインフラストラクチャ管理を可能にします。
Titanium の機能は、高グレードなデータセンター ネットワークである Google の Jupiter 光回路スイッチ ネットワーク ファブリックによって、さらに強化できます。ネイティブで 400 Gb/s のリンク速度と 13.1 Pb/s の全二分割帯域幅(ネットワークの半分がもう片方の半分と通信できるようにする方法を表す帯域幅の現実的手段)を提供する Jupiter は、地球上のすべての個人が同時にビデオ通話しても対応できる能力を備えています。この莫大なスケールが、AI コンピューティングの需要の高まりに対応するには不可欠です。
Hyperdisk ML が一般提供
高性能ストレージは、コンピューティング リソースの高い使用率とコスト効率を維持し、システムレベルのパフォーマンスに最適化したままにするために重要です。Hyperdisk ML は Google の AI にフォーカスしたブロック ストレージ サービスで、2024 年 4 月に発表しました。現在は一般提供されており、このブログ記事で取り上げたコンピューティングとネットワーキングのイノベーションを、AI および HPC ワークロード用の専用ストレージで補完します。
-
Hyperdisk ML がデータの読み込み時間を効果的に加速します。推論ワークロードの場合は、最大でモデル読み込み時間を 11.9 倍まで高速化でき、トレーニング ワークロードについては最大で4.3 倍までトレーニング時間を高速化できます。
-
同一ボリュームに 2,500 インスタンスをアタッチでき、ボリューム当たりの集計スループットは 1.2 TB/s です。これはブロック ストレージの主な競合他社と比べて 100 倍も高速です。
-
データ読み込み時間が速いということは、アクセラレータがアイドル状態となる時間がより短く、費用対効果が高いということになります。
-
GKE は現在、マルチゾーン ボリュームをデータに対して自動作成しています。これにより、複数ゾーン横断的に実行し、Spot でのプリエンプション削減など、より大きなコンピューティングの柔軟性が得られる一方で、Hyperdisk ML でモデル読み込み時間を短縮できます。
AI ワークロードのためのその他のストレージ強化については、最近の Parallelstore に関するブログ記事でさらに詳細をご確認いただけます。
AI の未来を作る
AI インフラストラクチャにおけるこれらの技術的進歩を通して、Google Cloud はビジネスと研究者を支援し、AI 革新の地平を再定義しています。Google は、この力強い基盤から斬新な AI アプリケーションが新たに登場することを楽しみにしています。
これらの発表の詳細については、Google の App Dev & Infrastructure Summit 基調講演のオンデマンド録画をご参照ください。

