Titanium: ワークロードに最適化されたクラウド コンピューティングのための堅牢な基盤

Google Cloud Japan Team
主要ハイパースケーラーの中で最速のブロック ストレージ性能を実現
※この投稿は米国時間 2023 年 8 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud は、Google 検索、YouTube、Gmail、Google マップなど、世界中の何十億もの人々に利用され、信頼されているサービスを支える、ワールドクラスの技術インフラストラクチャを基盤として構築されています。Google Cloud の中心となる方針は、可用性と信頼性の高い世界規模のコンピューティング システム、ストレージ システム、ネットワーク システム、データセンターを構築、運用してきた Google の経験を活用することです。
Google は、ワークロード最適化アプローチでインフラストラクチャを構築しており、専用のハードウェア コンポーネントとソフトウェア コンポーネントの組み合わせを採用することで、増大し続けるワークロードの需要に対応しています。このインフラストラクチャを支えているのが Titanium です。Titanium は、専用に構築されたカスタム シリコンと複数層のスケールアウト オフロードからなるシステムで、お客様のワークロードのパフォーマンス、信頼性、セキュリティをまとめて向上させます(たとえば、他の主要ハイパースケーラー 2 社と比較して、ブロック ストレージのインスタンスあたりの IOPS が 25% 速くなります)。このたび Google Cloud Next で発表された Titanium テクノロジーは、Google Cloud の最近のインフラストラクチャ サービスの多くに採用されています。
10 倍に高まる将来の需要
クラウド インフラストラクチャ プロバイダにとって、旧来のワークロードと新たなワークロードの両方のパフォーマンス、信頼性、セキュリティに関する要求の高まりに対応することが常に課題となっています。そして今、ほとんどすべての業界で生成 AI の採用が進み、こうした要求が格段に高まっています。一方、ムーアの法則の効果は近年低下しています。明日の要求に応えるためには、シリコンの進歩だけに頼ることはできません。
ほんの一例として、以下のグラフは、大規模言語モデルのコンピューティング需要の飛躍的高まりを示しています。
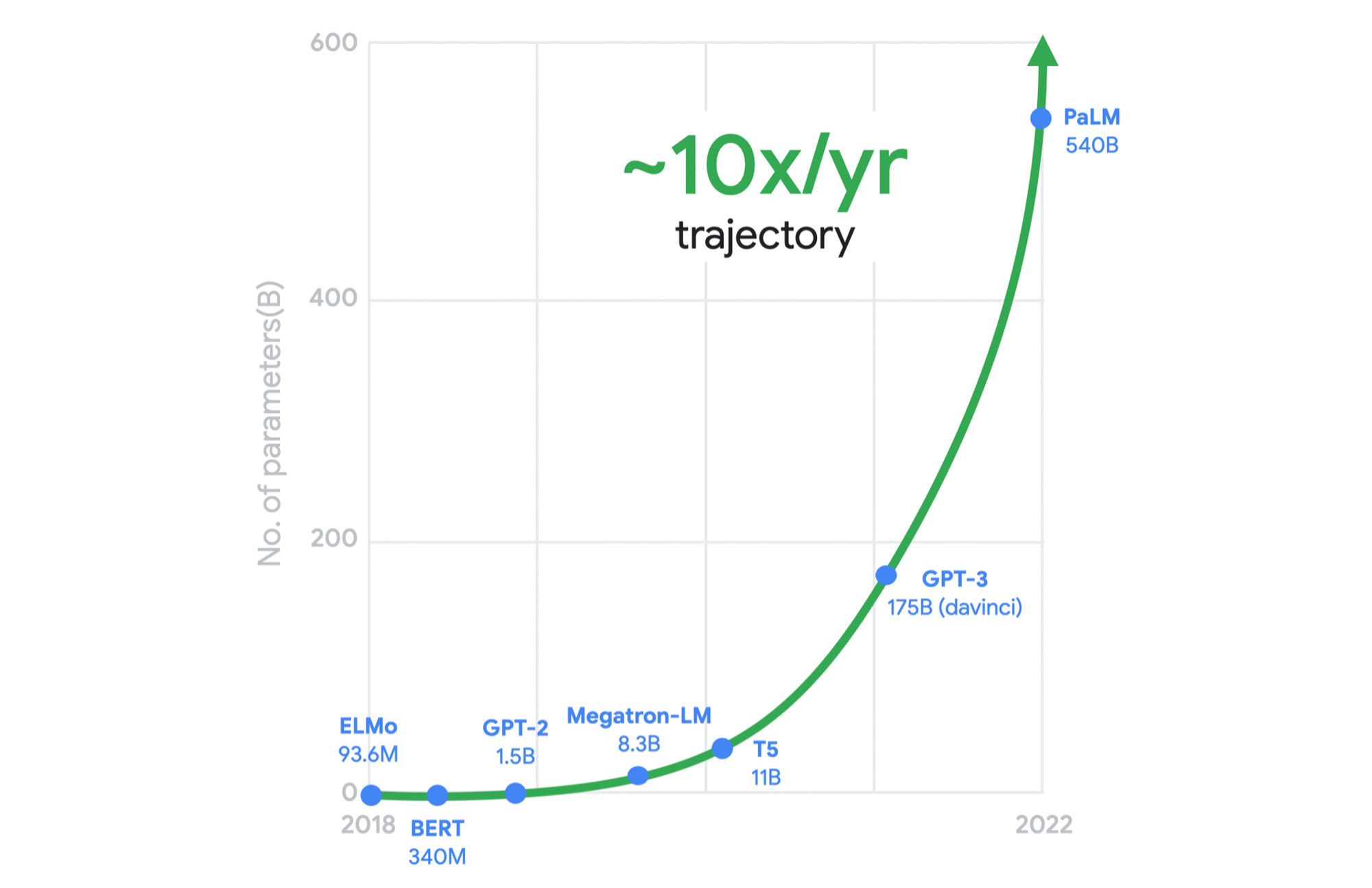
このような需要に対応するためにインフラストラクチャの設計を見直す必要があることは、かなり以前から明らかでした。このため、この数年間、ワークロードの最適化と計画的な設計をインフラストラクチャ プラットフォームの基本方針として採用しています。Google は、専用のインフラストラクチャ、規範的なアーキテクチャ、オープン エコシステムを組み合わせたワークロードに最適化されたインフラストラクチャを提供し、シリコンからお客様のワークロードまでに至る最良パスを構築しています。
重要な役割を担うオフロード
この戦略の中心となるのがオフロード技術です。従来から、CPU は多くの役割を担っています。たとえば、ワークロードを処理するための仮想化スタックであるハイパーバイザーを動作させ、ストレージとネットワークの I/O を管理し、仮想インターフェースと物理ハードウェアのためのセキュリティ分離を担っています。このモデルでは、CPU で処理されるお客様のワークロードがこれらのプラットフォーム タスクとリソースを取り合います。
専用ハードウェア上のオフロードは、これまでホスト CPU が裏で実行していたセキュリティ、ネットワーキング、ストレージの機能を実行し、CPU がお客様のワークロードの処理を最大化効率化することに集中できるようにします。
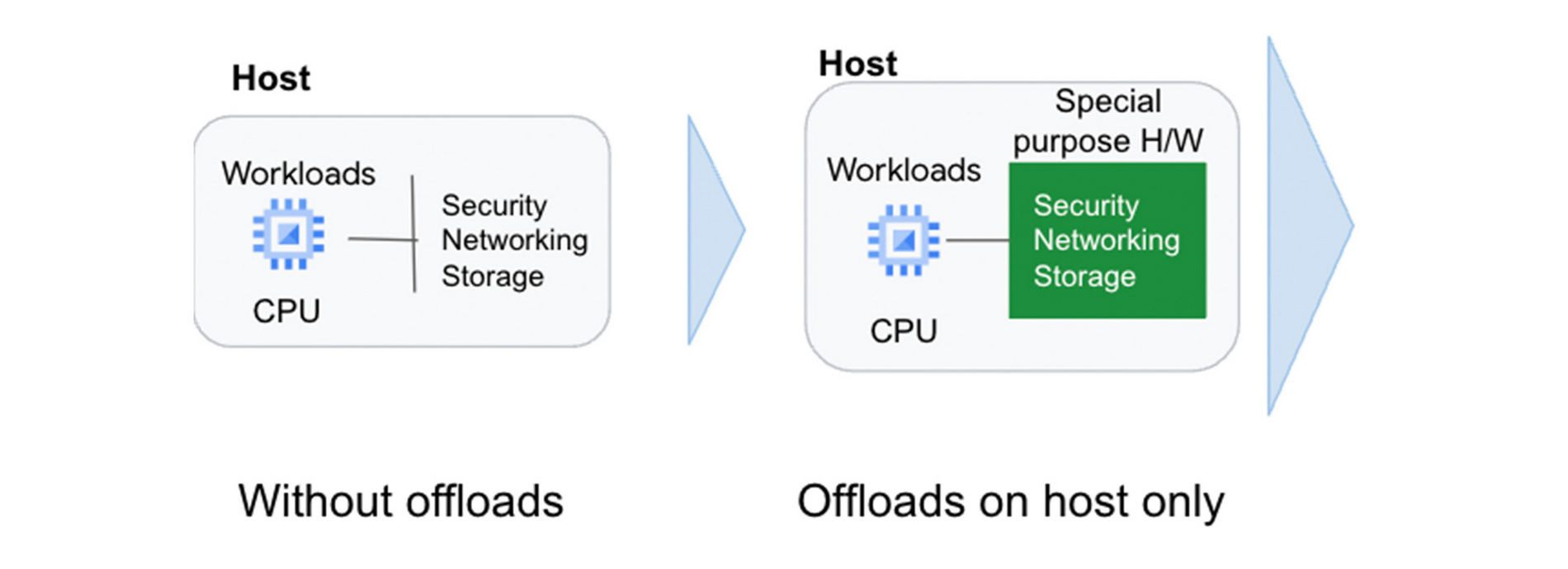
ホスト上のオフロードやアクセラレータの最近の例としては、Infrastructure Processing Unit(IPU)が挙げられます。これは、Intel と共同で設計したシステム オン チップで、Google の第 3 世代コンピューティング インスタンスでより優れたセキュリティ分離とパフォーマンスを実現するものです。IPU により、以下が可能となります。
予測可能で効率的なコンピューティング
低レイテンシを実現するプログラム可能なパケット処理。Google の前世代のコンピューティング インスタンスと比べて一秒あたりのパケット数が 3 倍の 200 Gbps ネットワーキング
PSP プロトコルによる転送中の暗号化
Google のホスト上ハードウェアのもう一つの重要な例として、Titan が挙げられます。Titan は、Google Cloud の各マシンが信頼できる状態から確実に起動できるようにする、安全で消費電力の小さいマイクロコントローラです。
しかし、Google の開発はそれだけにとどまりませんでした。将来の需要に応えるためには、ホストの専用オフロード ハードウェアを使用して確保できる性能を超える必要があることがわかっていました。
段階的なオフロードの体系
Titanium の重要な要素として、その最新のオフロード アーキテクチャが挙げられます。このアーキテクチャは、Google 内で定評のあるスケールとパフォーマンスを誇る機能と、クラウドのユースケースに合わせた新しい機能を兼ね備えています。
最新のワークロードがクラウド上で水平方向にスケールアウトするのと同様、Google は、Titanium を使用して、ホストの外部で動作するもう一つのスケールアウト オフロード層によってオン上のオフロードを補強できるようアーキテクチャを拡張しました。このオフロード体系はフリート全体にデプロイされ、ワークロードの需要の変化に応じて動的に調整され、継続的に最適なパフォーマンスを発揮します。
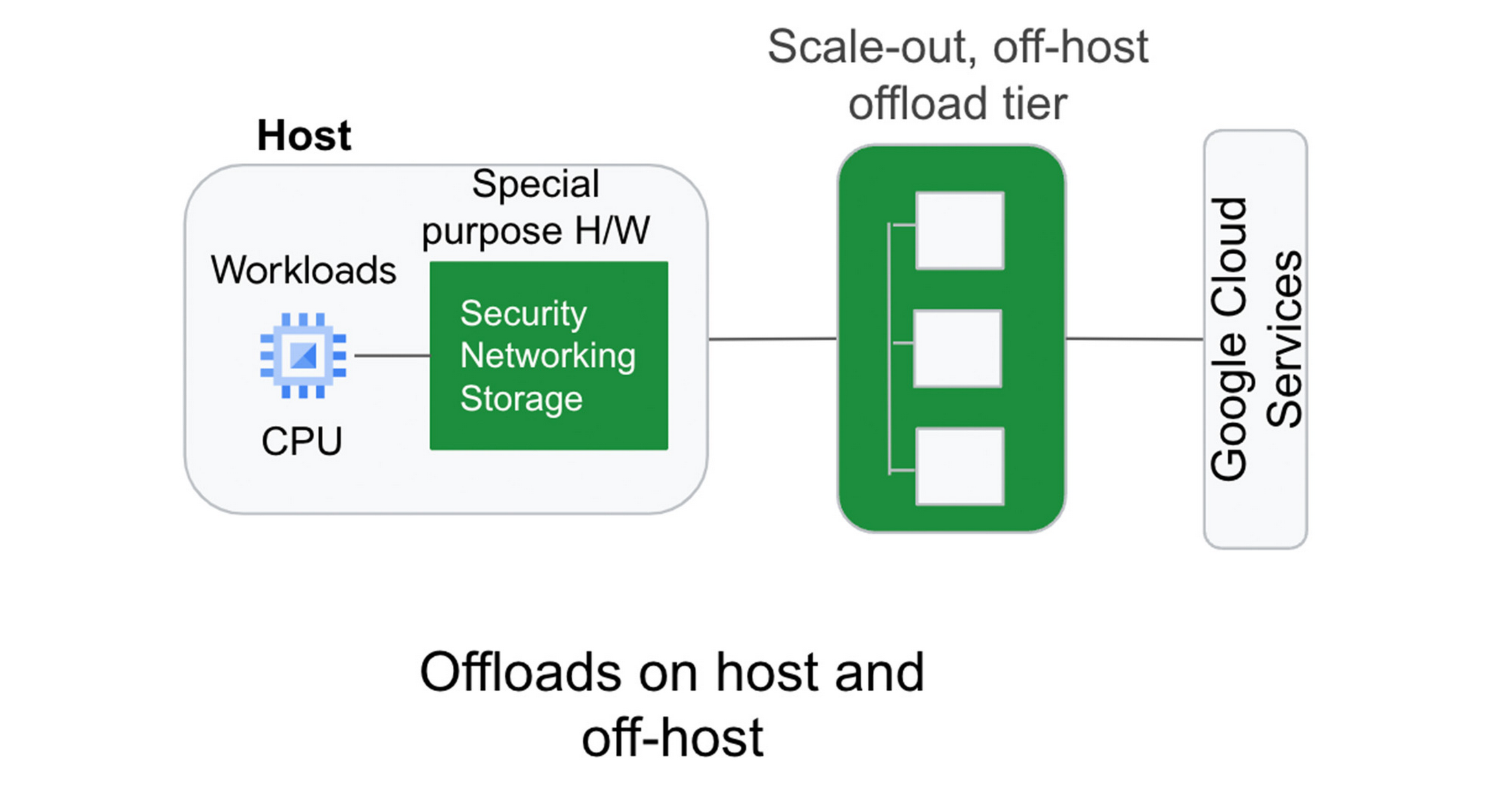
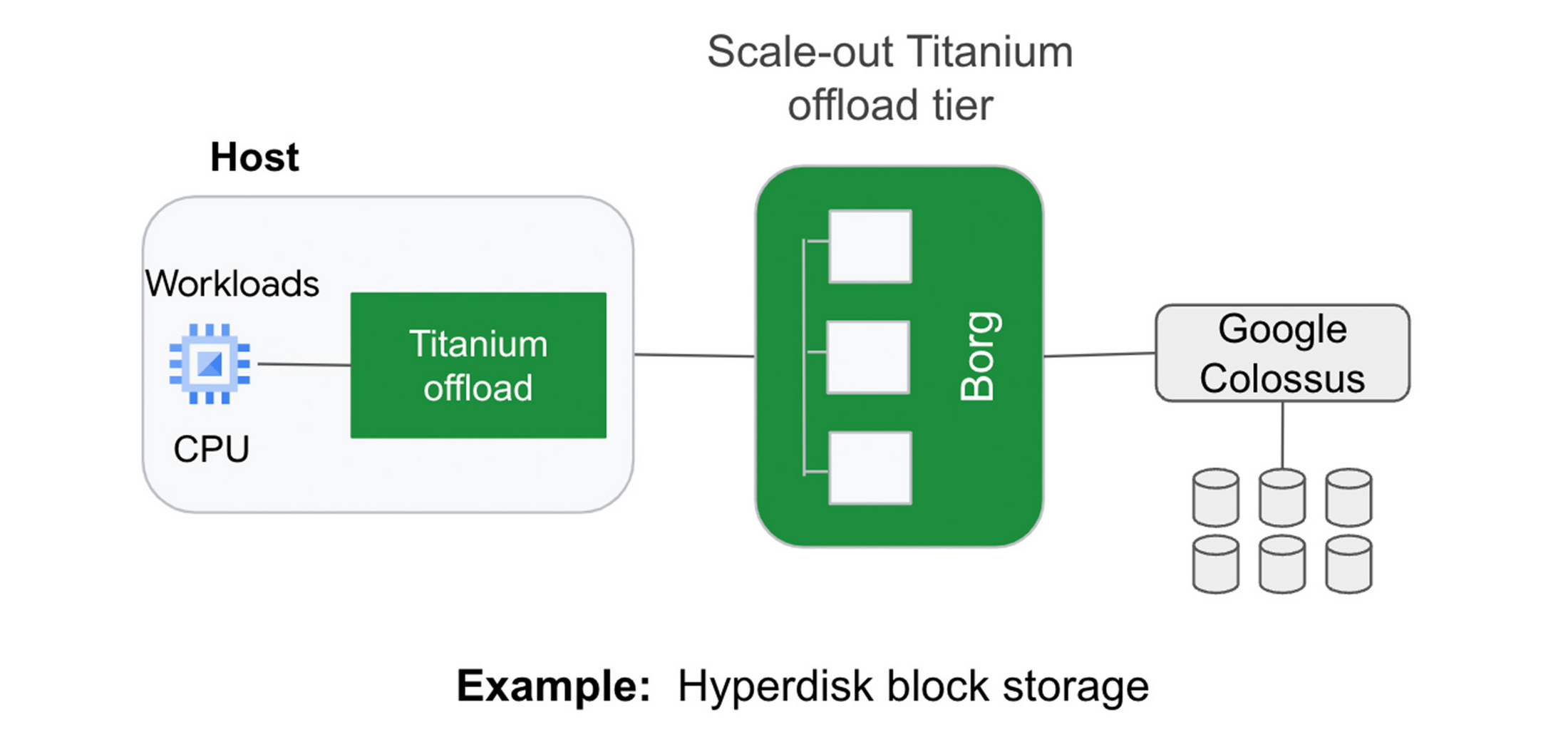
従来のオフロード アーキテクチャでは、ブロック ストレージの IOPS を高めるために、より大きなコンピューティング インスタンスを購入する必要があります。たとえば、十分なストレージ性能を得るために、場合によっては、データ集約型ワークロードを、そのワークロードが必要とするよりも多くの vCPU を持つコンピューティング インスタンスにデプロイする必要があります。この蜜結合は、お客様にとってリソースの無駄使いと費用の増大につながります。さらに、大規模なインスタンスであっても、クラウドのストレージ性能が、お客様がオンプレミスのストレージ システムで慣れ親しんでいるものに比べて不十分な場合があります。
Google の新しいブロック ストレージである Titanium 搭載 Hyperdisk では、計算インスタンス サイズとストレージ性能を切り離しました。Hyperdisk は、Google のクラウド ファブリックのオフロード階層を使用して、お客様のホストからストレージ I/O をオフロードし、汎用 VM でもストレージ性能の向上を図ります。
Google はこのたび、Hyperdisk Extreme を実装した Titanium 搭載 C3 VM が、最も要求の厳しいワークロードの需要に対応するために、プレビュー版機能として、コンピューティング インスタンスあたり 500K IOPS のサポートを開始することを発表いたしました。これで、Titanium システムのおかげで、他の主要ハイパースケーラー 2 社と比較して、インスタンスあたりの IOPS が 25% 高速化されることになります。
例 2: ネットワーク ルーティング
仮想ネットワーク ルーティングでも、スケールアウト オフロードの第二階層(「ホバーボード」)が使用されます。Titanium により、IPU オフロード デバイス上の Google の Andromeda 仮想ネットワーキング スタックが、対応するルートのないすべてのパケットを、すべての仮想ネットワークの転送情報を持つホバーボード ゲートウェイに送信します。ホバーボードは、スタンドアロン型ソフトウェア スイッチで、一部のフローではデフォルト ルーターとして機能します。
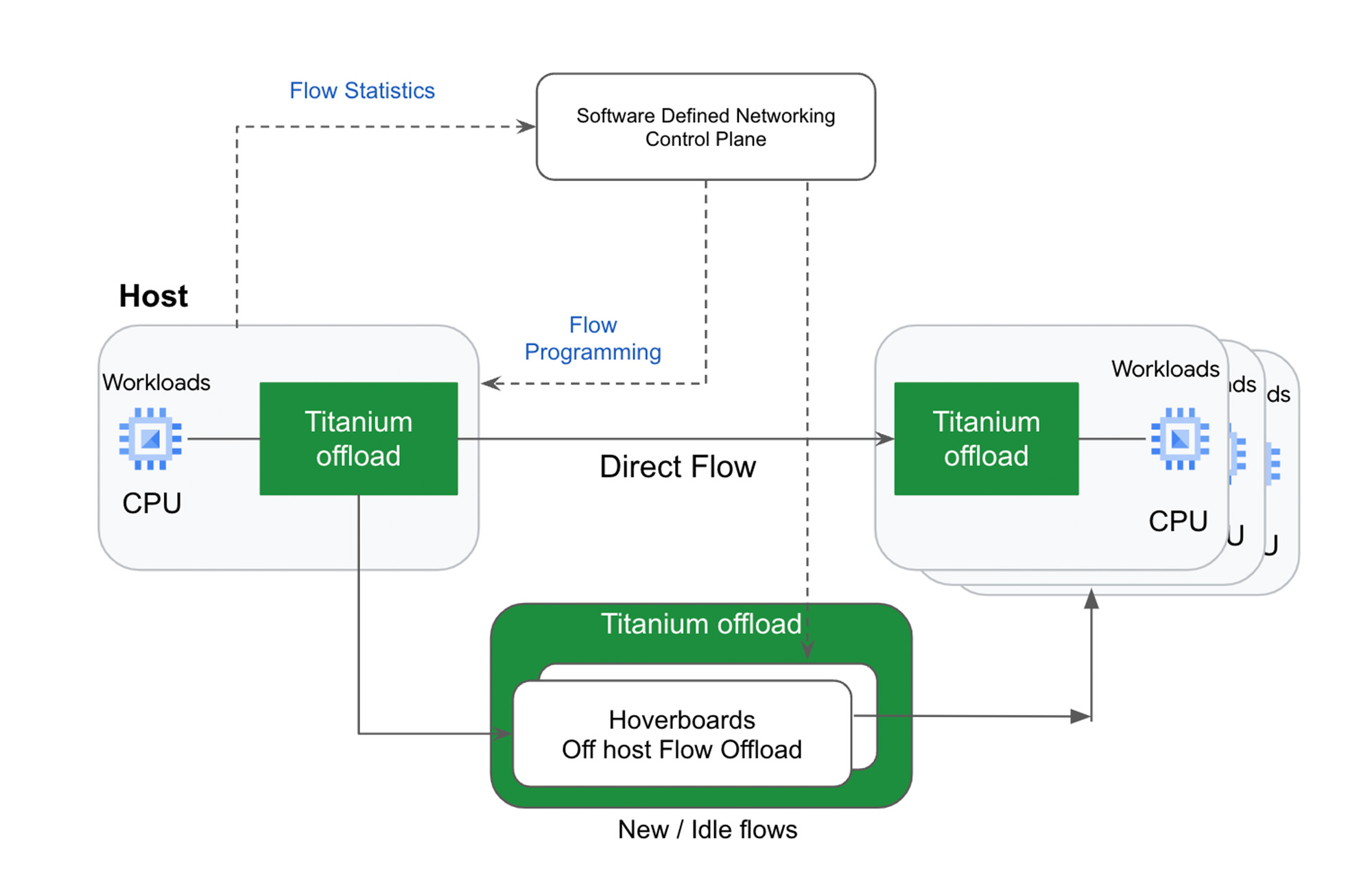
従来のゲートウェイ モデルとは異なり、コントロール プレーンが指定された使用量しきい値を超えるフローを動的に検出し、ホスト間の直接フローになるようにプログラムするため、フローがホバーボードを迂回し、ホバーボードが使用頻度の低いフローのロングテールに集中できます。通常、ネットワーク内で互いに通信を行う VM ペアはごく一部であるため、VM は、個々の VM ホスト上で、通常のネットワーク構成のごく一部を保存、処理するだけで済むため、サーバーごとのメモリ使用率とコントロール プレーンの CPU スケーラビリティが向上します。
すでにワークロード処理効率を向上させている Titanium
Titanium の歴史は、数年前に上述のコンポーネント技術から始まりました。Google のプロダクトの多くはすでにこのアーキテクチャの恩恵を受けています。このアーキテクチャの最新の要素は、C3 や新しい Hyperdisk ブロック ストレージなどの第 3 世代の Compute Engine インスタンスで利用できます。
今後は、Google のインフラストラクチャ ソリューションの全世代で基盤として Titanium アーキテクチャを検討することになります。その過程で単一サーバー領域をはるかに超えた新しいクラスのインフラストラクチャ機能を実現していきます。
- ML、システム、Cloud AI 担当バイス プレジデント兼ゼネラル マネージャー Amin Vahdat
- コンピューティング プロダクト シニア管理ディレクター Nirav Mehta

