AI ハイパーコンピュータ ソフトウェアのアップデート: トレーニングや推論の高速化、新しいリソースハブなど
Vaibhav Singh
Group Product Manager
Mohan Pichika
Group Product Manager
※この投稿は米国時間 2024 年 10 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
AI が持つ可能性はかつてないほど向上し、インフラストラクチャはそれを推進する基礎的な役割を担っています。AI ハイパーコンピュータは、パフォーマンスが最適化されたハードウェア、オープン ソフトウェア、柔軟な消費モデルに基づくスーパーコンピューティング アーキテクチャです。これらの組み合わせにより、卓越したパフォーマンスと効率性、大規模な復元力を提供し、ニーズに合わせてレイヤごとにサービスを柔軟に選択できます。
本日、AI ハイパーコンピュータ ソフトウェア レイヤのメジャー アップデートによるトレーニングおよび推論のパフォーマンス向上、大規模な復元力の向上、AI ハイパーコンピュータ リソースのための中央ハブを発表します。
GitHub の AI ハイパーコンピュータ リソース
AI ハイパーコンピュータのオープン ソフトウェア レイヤは、主要な ML フレームワークとオーケストレーション オプションをサポートするだけでなく、ワークロードの最適化とリファレンス実装を提供することで、特定のユースケースにおける価値創出までの時間を短縮します。オープン ソフトウェア スタックのイノベーションを開発者や実務担当者が簡単に利用できるよう、Google は、AI ハイパーコンピュータ GitHub 組織を導入します。これは、MaxText、MaxDiffusion などのリファレンス実装、XPK(クラスタ作成とワークロード管理用の Accelerated Processing Kit)などのオーケストレーション ツール、そして Google Cloud の GPU 用のパフォーマンス レシピを見つけることができる中央ハブです。Google は今後もこのリストを拡充し、急速に進化する状況にこれらのリソースを適応させていきます。皆様からの貢献もお待ちしています。
MaxText で A3 Mega VM をサポート
MaxText は、大規模言語モデル(LLM)用の高パフォーマンスでスケーラビリティに優れたオープンソースのリファレンス実装です。NVIDIA H100 Tensor Core GPU を搭載し、A3 VM と比較して GPU 間ネットワーク帯域幅が 2 倍向上した A3 Mega VM で、パフォーマンスが最適化された LLM トレーニング サンプルを使用できるようになりました。NVIDIA との緊密な協力により、JAX と XLA を最適化し、GPU 上での集団通信と計算のオーバーラップを可能にしました。さらに、XLA フラグを有効にした GPU 用に最適化されたモデル構成とサンプル スクリプトを追加しました。
Llama2-70b 事前トレーニングによって以下に示すとおり、MaxText と A3 Mega VM の組み合わせでは、クラスタ内の VM 数の増加に合わせてトレーニング パフォーマンスがほぼ線形にスケーリングされます。
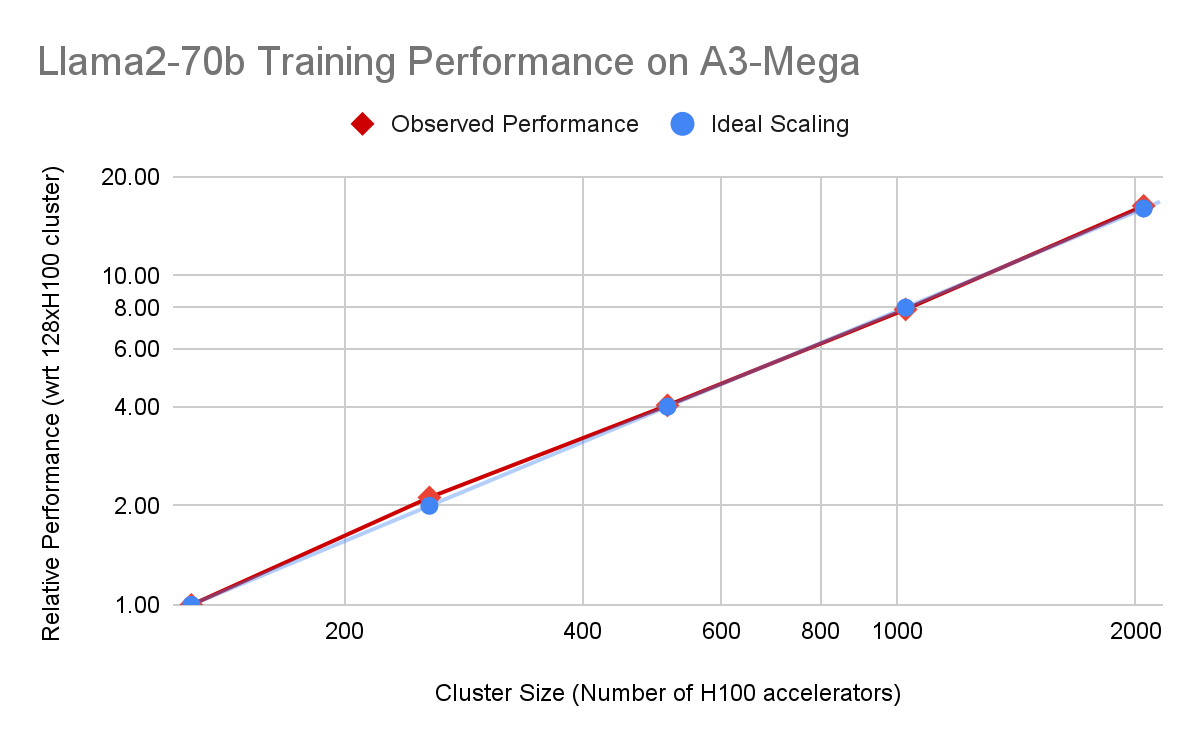
図 1a: A3 Mega での Llama2-70b(MaxText)事前トレーニングに関する Google 内部データ。相対的なパフォーマンス(bf16 トレーニング)と理想的なスケーリングを比較しています。bf16 を使用した A3 Mega でのトレーニングでも、線形に近いスケーリングが示されました。
さらに、A3 Mega VM 上で FP8 混合精度トレーニングを使用することにより、さらなる高速化とハードウェア使用率を実現できます。MaxText での FP8 サポートを追加するには、Accurate Quantized Training(AQT)を利用しました。これは、Cloud TPU の INT8 混合精度トレーニングにも使用される量子化ライブラリです。
高密度モデルに関する Google のベンチマークでは、AQT を使用した FP8 トレーニングによって、モデルの実効 FLOP 使用率(EMFU)が bf16 と比較して最大 55% 向上することが示されています。A3 Mega 用のレシピと最適なトレーニング サンプルは、こちらをご覧ください。
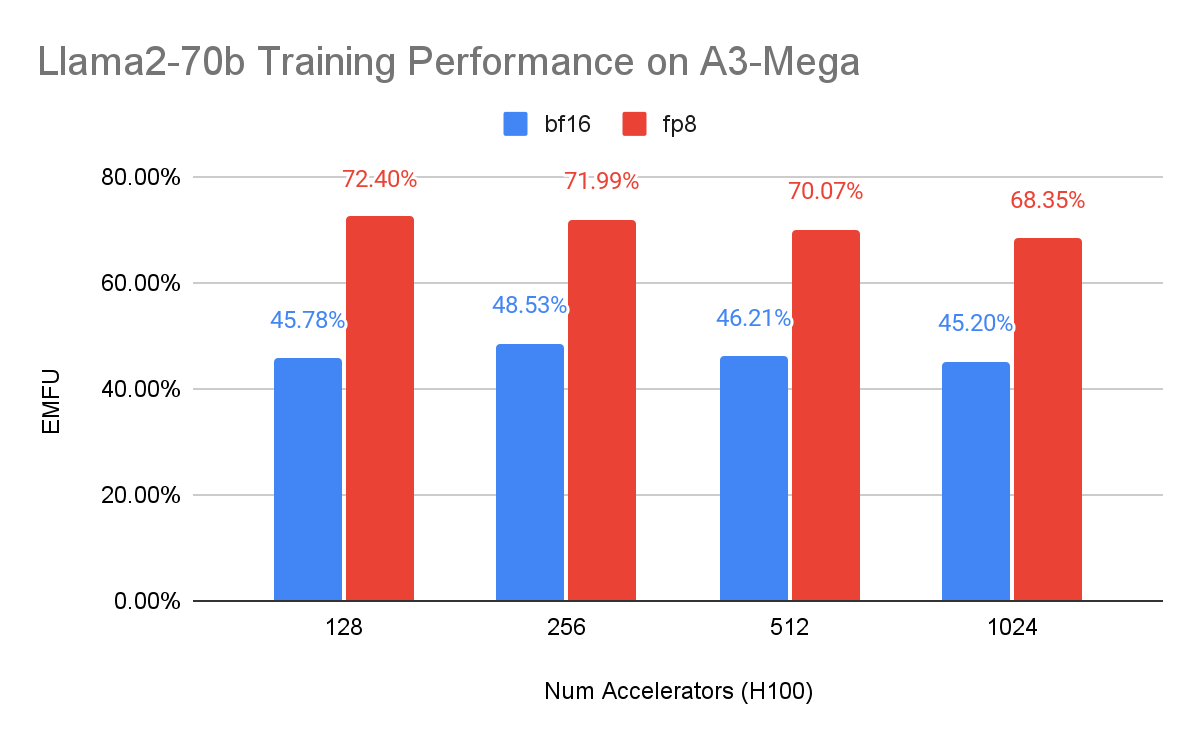
図 1b: A3 Mega での Llama2-70b(MaxText)事前トレーニングに関する Google 内部データ。bf16 と fp8 の両方の混合精度トレーニングで、実効 MFU(EFMU)はベース bf16 ピーク FLOP を使用して算出しています。シーケンスの長さは 4,096 トークンです。
MoE のリファレンス実装とカーネル
ほとんどの Mixture of Experts(MoE)ユースケースでは、限られた数のエキスパートのリソース使用率を一定にすることが有用です。ただし、特定のアプリケーションでは、使用するエキスパートの数を増やしてより高度な回答を開発する能力がさらに重要になります。この柔軟性を実現するために、MaxText を拡張して「上限あり」と「上限なし」の両方の MoE 実装を含め、お使いのモデル アーキテクチャに最適な実装を選択できるようにしました。上限ありの MoE モデルは予測可能なパフォーマンスを提供し、上限なしのモデルは最適な効率性を得るためにリソースの動的割り当てを行います。
MoE トレーニングをさらに高速化させるために、Cloud TPU 上のブロック スパース行列乗算に最適化された Pallas カーネルをオープンソース化しました(Pallas は、GPU や TPU などの XLA デバイス用に生成されたコードをきめ細かに制御できる JAX の拡張機能です。ブロック スパース行列乗算は現在 TPU でのみ利用可能です)。これらのカーネルは PyTorch と JAX の両方で使用でき、MoE モデルのトレーニングのための高パフォーマンスの構成要素となります。

図 2: Cloud TPU v5p での Mixtral-8x7b(MaxText)事前トレーニングに関する Google 内部データ。シーケンスの長さは 4,096 トークンです。ウィーク スケーリングは、デバイスごとの固定バッチサイズで測定されます。
上限なしの MoE モデル(Mixtral-8x7b)を使用した場合の Google のベンチマークでは、デバイスごとの固定バッチサイズで、ほぼ線形のスケーリングが示されました(図 2)。また、アクセラレータの数に応じて基本構成のエキスパートの数を増やした場合(図 3)も、線形に近いスケーリングが確認されました。これは、スパース性の高いモデルでもパフォーマンスが発揮されることを示唆しています。
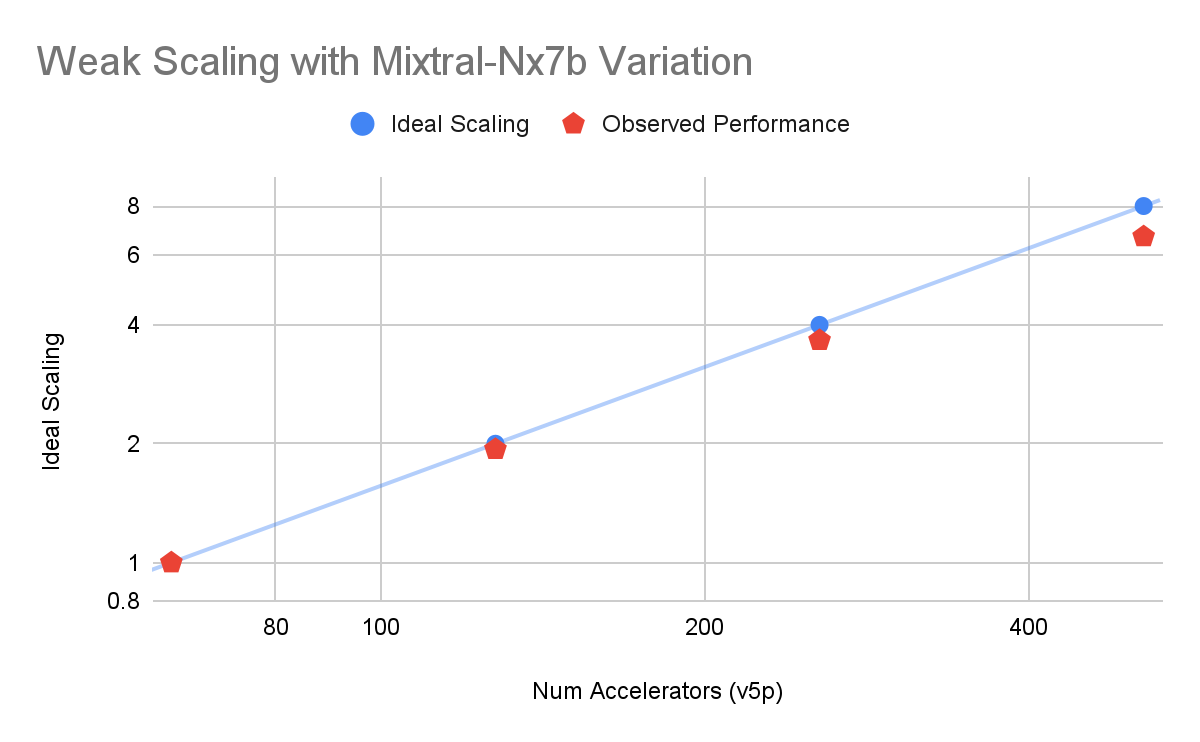
図 3: Cloud TPU v5p での Mixtral-8xNb(MaxText)事前トレーニングに関する Google 内部データ。シーケンスの長さは 4,096 トークンです。ウィーク スケーリングは、クラスタサイズ 64~512 v5p チップの範囲でエキスパートの数(N)を増やすことによって測定されます。
大規模なトレーニングのモニタリング
トレーニング タスクでユニットとして連動することを想定した大規模なアクセラレータ クラスタがある場合、MLOps が複雑になる可能性があります。「ホスト転送のレイテンシが急増したのは何か原因があるのだろうか」「このデバイスだけがセグメンテーション違反になったのはなぜか」などと疑問に思う場合もあるかもしれません。しかし、適切な指標を使用して大規模なトレーニング ジョブをモニタリングすることは、リソース使用率を最大化し、全体的な ML グッドプットを向上させるうえで不可欠です。MLOps 計画のこの重要な部分を簡素化するために、リファレンス モニタリング レシピを導入しました。このレシピにより、Google Cloud プロジェクト内に Cloud Monitoring ダッシュボードを作成することで、平均または最大 CPU 使用率などの有益な統計指標を表示し、セットアップ内の外れ値を特定して、是正措置を取ることができます。
Cloud TPU v5p の SparseCore の一般提供開始
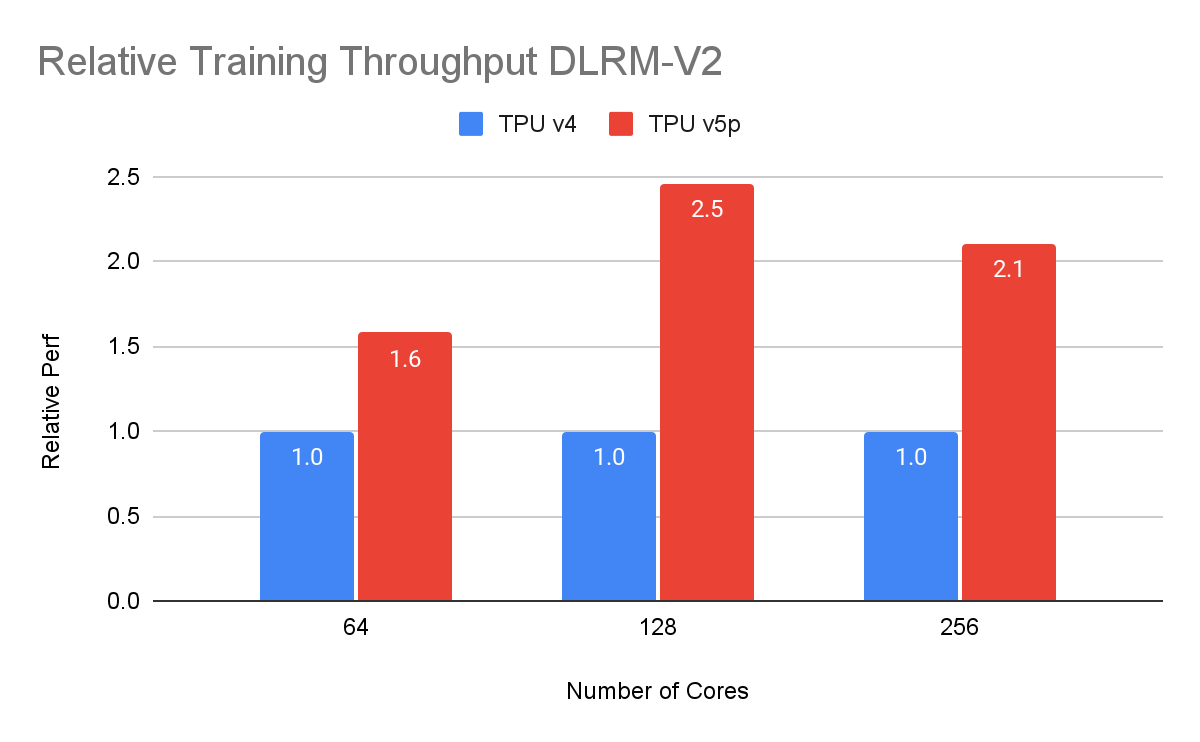
Recommender モデルやエンベディングに依存するモデルでは、それらのエンベディングを使用するために高パフォーマンスのランダムメモリ アクセスが必要です。TPU のエンベディング用ハードウェア アクセラレータである SparseCore を使用すると、よりパワフルで効率的なレコメンデーション システムを構築できます。各 Cloud TPU v5p チップには 4 つの専用 SparseCore が搭載され、DLRM-V2 のパフォーマンスは前世代に比べて最大 2.5 倍向上します。
LLM 推論パフォーマンスの向上
最後に、LLM 推論のパフォーマンスを向上させるために、Google は、LLM 推論用のオープンソースのスループットおよびメモリ最適化エンジンである JetStream に KV キャッシュ量子化と不規則なアテンション カーネルを導入しました。これらの機能強化の組み合わせにより、Cloud TPU v5e の推論パフォーマンスが最大 2 倍向上します。

JetStream スループット(出力トークン / 秒)。Google 内部データ。基準: Google Cloud TPU と GPU で AI 推論を高速化
現行: Cloud TPU v5e-8 上で Gemma 7B(MaxText)、Llama 2 13B(PyTorch/XLA)、Llama 2 70B を使用して測定。入力最大文字数: 1,024、出力最大文字数: 1,024。
AI の取り組みを支える
モデルのトレーニングと推論の限界への挑戦から、中央リソース リポジトリによるアクセシビリティの向上に至るまで、AI ハイパーコンピュータの各コンポーネントは AI の次世代を形作る構成要素となります。Google は、AI 実務担当者がインフラストラクチャの制限に悩まされることなく、コンセプトから実稼働までシームレスにスケーリングできる未来を思い描いています。
最適化されたレシピ、Accelerated Processing Kit、リファレンス実装などの最新の AI ハイパーコンピュータ関連リソースをご覧ください。



