第 6 世代 TPU 「Trillium」の一般提供開始を発表

Mark Lohmeyer
VP & GM, AI & Computing Infrastructure
※この投稿は米国時間 2024 年 12 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
テキストや画像などの多様なデータを処理できる大規模な AI モデルの台頭により、特有のインフラストラクチャの課題が生まれています。これらのモデルには、トレーニング、チューニング、推論を効率的に行うための膨大な計算能力と専用ハードウェアが必要です。Google は AI ワークロードの増大する需要に対応するため、10 年以上前からカスタム AI アクセラレータである Tensor Processing Unit (TPU) の開発を開始しており、マルチモーダル AI への道を切り開いてきました。
2024 年、Google Cloud はこれまでで最も高性能な第 6 世代 TPU「Trillium」を発表しました。そして、この度、Google Cloud のお客様向けに一般提供を開始しました。
Trillium TPU は、Google の最も高性能な AI モデルである新しい Gemini 2.0 のトレーニングに使用されています。これにより、企業やスタートアップも、強力で効率的、かつ持続可能なインフラストラクチャを活用できるようになりました。
Trillium TPU は、パフォーマンスに最適化されたハードウェア、オープン ソフトウェア、最先端の ML フレームワーク、柔軟な利用モデルを組み合わせた画期的なスーパーコンピュータ アーキテクチャである Google Cloud の AI ハイパーコンピュータにおける重要な要素です。Trillium TPU の一般提供に合わせて、XLA コンパイラや JAX、PyTorch、TensorFlow などの一般的なフレームワークの最適化など、AI ハイパーコンピュータのオープン ソフトウェア レイヤーの主要な機能強化も行っており、AI のトレーニング、チューニング、サービング全体で優れたコスト パフォーマンスを大規模に実現しています。さらに、大容量のホスト DRAM (高帯域幅メモリ: HBM を補完) を使用したホスト オフロードなどの機能により、次世代の効率性を実現します。AI ハイパーコンピュータは、13Pb /秒の二分割帯域幅を持つ Jupiter ネットワーク ファブリック上に 10 万個以上のTrilliumチップを配置することができ、単一の分散トレーニング ジョブを数十万のアクセラレータに拡張することが可能です。
すでに、AI21 Labs をはじめとするお客様が Trillium を使用して、有意義な AI ソリューションをより迅速にお客様に提供しています。
「AI21 では、Mamba と Jamba の言語モデルのパフォーマンスと効率を向上させるために常に努力しています。TPU v4 からの長年のユーザーとして、Google Cloud の Trillium の性能には非常に感銘を受けています。今回発表されたスケール、速度、コスト効率の進歩は目覚ましいです。Trillium は、次世代の高度な言語モデルの開発を加速する上で不可欠なものとなり、より強力でアクセスしやすいAIソリューションをお客様に提供できるようになると確信しています。」- AI21 Labs、 CTO、Barak Lenz 氏、
前世代と比較した Trillium の主な改善点は以下の通りです。
-
トレーニングのパフォーマンスが 4 倍以上向上
-
推論スループットが最大で 3 倍向上
-
エネルギー効率が 67% 向上
-
チップあたりのピーク コンピューティング パフォーマンスが 4.7 倍向上
-
高帯域幅メモリ (HBM) 容量が 2 倍
-
チップ間相互接続 (ICI) 帯域幅が 2 倍
-
単一の Jupiter ネットワーク ファブリックに 10 万の Trillium チップを搭載
-
トレーニングのコストパフォーマンスが最大 2.5 倍、推論のコスト パフォーマンスが最大 1.4 倍向上
これらの機能強化により、Trillium は以下のような幅広い AI ワークロードで優れた性能を発揮します。
-
AI トレーニング ワークロードのスケーリング
-
高密度および混合エキスパート (MoE) モデルを含む LLM のトレーニング
-
推論パフォーマンスとコレクションのスケジューリング
-
埋め込みモデル
-
トレーニングと推論のコストパフォーマンス
各ワークロードで Trillium がどのように機能するかを見てみましょう。
AI トレーニング ワークロードのスケーリング
Gemini 2.0 のような大規模なモデルのトレーニングには、膨大なデータと計算能力が必要です。Trillium の線形に近いスケーリング能力により、256 個のチップが備えられているポッド内の高速チップ間相互接続と最先端の Jupiter データセンター ネットワーキングを介して、多数の Trillium ホストにワークロードを効果的かつ効率的に分散させることで、これらのモデルを大幅に高速にトレーニングできます。これは、TPU マルチスライスと大規模トレーニング向けのフルスタック テクノロジーによって可能になり、ホストアダプターからネットワーク ファブリックまでのデータセンター全体の動的なオフロード システムである Titanium によって最適化されています。
3072 個のチップで構成される 12 ポッドの配置で、Trillium は 99% のスケーリング効率を達成し、gpt3-175b の事前学習をデータセンター ネットワーク全体で実行する場合でも、6144 個のチップを持つ 24 ポッドで 94% のスケーリング効率を示しています。
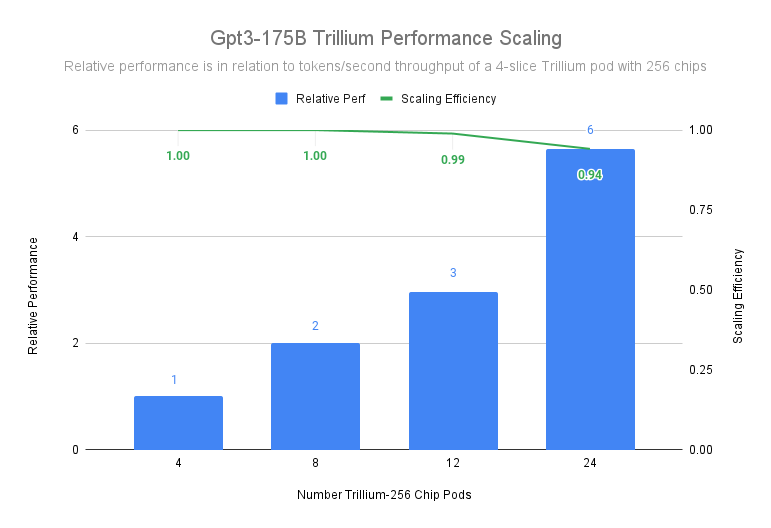
図 1: 出典データ: MLPerf™ 4.1. におけるポッドあたり 256 個の Trillium チップを 1 つの ICI ドメインで実行した Google ベンチマーク結果
上のグラフでは、4 スライスの Trillium 256 チップのポッドをベースラインとして使用していますが、1 スライスの Trillium 256 チップのポッドをベースラインとしても、24 ポッドまでスケールアップする際に 90% 以上のスケーリング効率を維持します。
Llama-2-70B モデルのトレーニングでは、4 スライスの Trillium-256 チップポッドから 36 スライスのTrillium-256 チップポッドまで、99% のスケーリング効率で線形に近いスケーリングを達成することが実証されています。
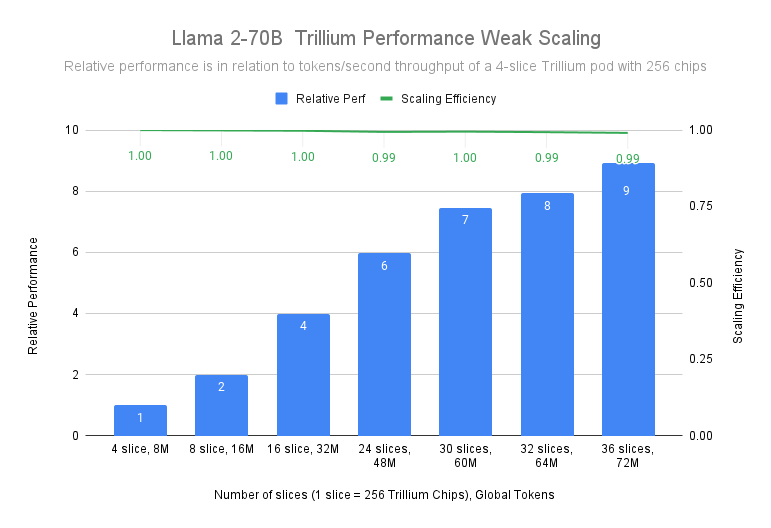
図 2: 出典データ: 4k Seq Length の MaxText リファレンス実装を使用し 256 個の Trillium チップを 1 つの ICI ドメインで実行した Google ベンチマーク結果
Trillium TPU は前世代と比較して、大幅に優れたスケーリング効率を示しています。下のグラフは、同等のスケール (総ピーク FLOP) の Cloud TPU v5p クラスターと比較して、12 個のポッドで 99% のスケーリング効率を達成する Trillium の性能を示しています。
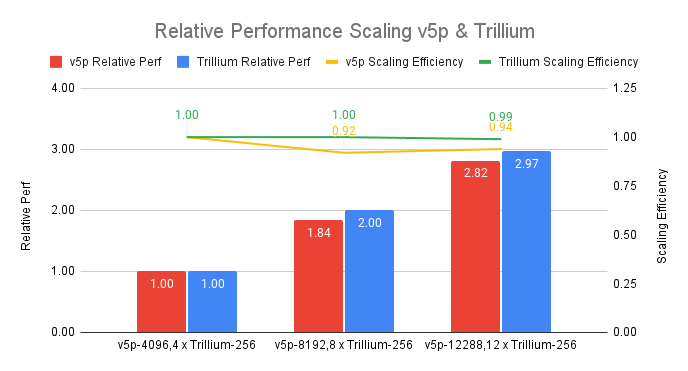
図 3:出典データ: MLPerf™ 4.1 トレーニング、GPT3-175b トレーニング タスクの Trillium (プレビュー) と v5p のクローズド結果。Weak scalling による Trillium と Cloud TPU v5p の比較、スケール係数としてはそれぞれ、v5p-4096 と 4xTrillium-256 として検証。256 個の Trillium チップを 1 つの ICI ドメインで実行、v5p に関しては n/2 v5p チップを 1 つの ICI ドメインで実行。
高密度モデルと混合エキスパートモデル(MoE)を含む LLM のトレーニング
Gemini のような LLM は、本質的に強力かつ複雑で、数十億のパラメータを持っています。このような高密度 LLM のトレーニングには、膨大な計算能力と共同設計されたソフトウェアの最適化が必要です。Trillium は Llama-2-70b や gpt3-175b などの密な LLM のトレーニングを前世代の Cloud TPU v5e と比較して最大 4 倍高速に行うことができます。
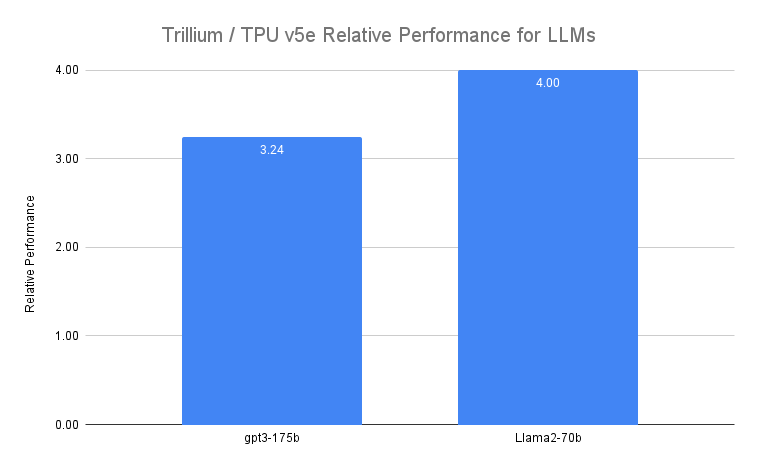
図 4: 出典データ: v5e と Trillium でのステップタイム実行に関する Google ベンチマーク
高密度 LLM に加えて、MoE アーキテクチャを使用して LLM をトレーニングすることは、AI タスクの異なる側面に特化した複数の「エキスパート」ニューラルネットワークを組み込んだアプローチとしてますます人気が高まっています。トレーニング中にこれらのエキスパートを管理および調整すると、1 つのモノリシック モデルのトレーニングに比べて複雑さが増します。Trillium は、前世代の Cloud TPU v5e よりも MoE モデルのトレーニングを最大 3.8 倍高速化します。
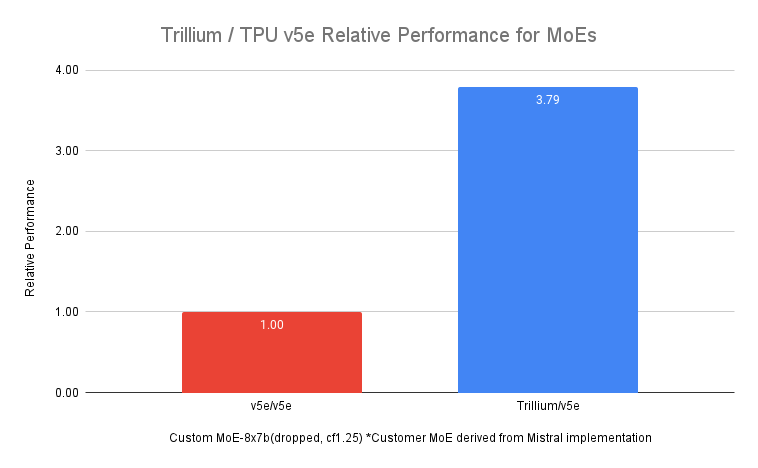
図 5: 出典データ: v5e と Trillium でのステップタイム実行に関する Google ベンチマーク
さらに、Trillium TPU は Cloud TPU v5e と比較して 3 倍のホスト DRAM を提供します。これにより、一部の計算をホストにオフロードし、パフォーマンスと グッドプットを大規模に最大化することができます。Trillium のホストオフロード機能により、モデルの FLOP 使用率 (MFU) で測定された Llama-3.1-405B モデルのトレーニング時のパフォーマンスを 50% 以上向上させます。
推論パフォーマンスとコレクション スケジューリング
推論時のマルチステップ推論の重要性が高まっていることから、増大する計算需要を効率的に処理できるアクセラレータが求められています。Trillium は推論ワークロードに対して大幅な進歩をもたらし、より高速で効率的な AI モデルのデプロイを可能にします。実際、Trillium は画像生成と高密度 LLM の推論において、最高の TPU 推論パフォーマンスを提供します。当社のテストでは、 Cloud TPU v5e と比較して、Stable Diffusion XL の相対推論スループット (画像/秒) が 3 倍以上、Llama2-70B の相対推論スループット (トークン/秒) が 2 倍近く高いことが示されています。
Trillium は、オフライン推論とサーバー推論の両方のユースケースで、最高のパフォーマンスを発揮する TPU です。下のグラフは、Cloud TPU v5e と比較して、Stable Diffusion XL のオフライン推論の相対スループット(画像/秒)が 3.1 倍、サーバー推論の相対スループットが 2.9 倍高いことを示しています。
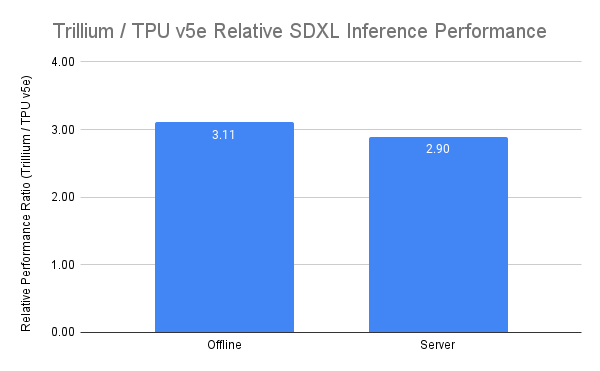
図 6:出典データ: MaxDiffusion リファレンス実装を使用したオフラインとオンラインの両方の SDXL ユースケースの画像/秒に関する Google のベンチマーク
パフォーマンスの向上に加えて、Trillium は新しいコレクション スケジューリング機能を導入しています。この機能により、Google のスケジューリング システムはコレクション内に複数のレプリカが存在する場合に、ジョブのスケジューリングに関するインテリジェントな決定を行い、推論ワークロードの全体的な可用性と効率を向上させることができます。これは、Google Kubernetes Engine (GKE) を含む、シングルホストまたはマルチホストの推論ワークロードを実行する複数の TPU スライスを管理する方法を提供します。これらのスライスをコレクションにグループ化することで、需要に合わせてレプリカの数を簡単に調整できます。
埋め込みモデル
第 3 世代 SparseCore の追加により、Trillium は埋め込み処理のモデルのパフォーマンスを 2 倍に向上させ、DLRM DCNv2 のパフォーマンスを 5 倍向上させました。
SparseCore は、埋め込み処理するワークロードに対して、より適応性の高いアーキテクチャ基盤を提供するデータフロー プロセッサです。Trillium の第 3 世代 SparseCore は、scatter-gather、sparse segment sum、パーティショニングなどの動的でデータに依存する操作の高速化に優れています。
トレーニングと推論のコストパフォーマンスを提供
Trillium は、世界最大規模の AI ワークロードをトレーニングするために必要な絶対的なパフォーマンスとスケールに加えて、コストあたりのパフォーマンスを最適化するように設計されています。現在までに、Trillium は Llama2-70b や Llama3.1-405b などの高密度な LLM のトレーニングにおいて、Cloud TPU v5e と比較して1ドルあたりのパフォーマンスが最大 2.1 倍、Cloud TPU v5pと比較して 1 ドルあたりのパフォーマンスが最大 2.5 倍向上しています。
Trillium は大規模モデルの並列処理を費用対効果の高い方法で実現します。研究者や開発者が以前よりも大幅に低コストで堅牢で効率的な画像モデルを提供できるように設計されています。Trillium で 1,000 枚の画像を生成するコストは、オフライン推論の場合で Cloud TPU v5e よりも 27%、SDXLでのサーバー推論の場合は 22% 低減されています。
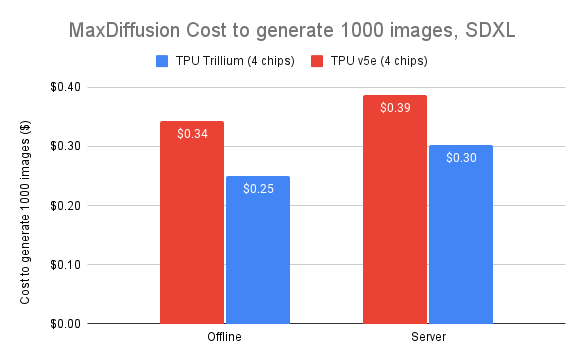
図 7: 出典データ: MaxDiffusion リファレンス実装を使用したオフラインとオンラインの両方の SDXL ユースケースの画像/秒に関する Google のベンチマーク
AI イノベーションをさらなる段階へ
Trillium は、Google Cloud の AI インフラストラクチャにおける大きな飛躍を表しており、幅広い AI ワークロードに対して驚異的なパフォーマンス、スケーラビリティ、効率性を提供します。Trillium は、グローバル水準の共同設計されたソフトウェアを使用して数十万個のチップにスケールできるため、より迅速なブレークスルーと優れた AI ソリューションの提供を可能にします。さらに、Trillium の優れたコストパフォーマンスにより、AI 投資の価値を最大化しようとする組織にとって費用対効果の高い選択肢となります。AI を取り巻く環境が進化し続ける中、Trillium は 企業の AI の可能性を最大限に引き出すための最先端のインフラストラクチャを提供するというGoogle Cloud のコミットメントの証です。
皆様が Trillium とAI ハイパーコンピュータを活用して AI 革新の可能性をさらに押し広げていくことを楽しみにしています。Trillium システムが最も要求の厳しい AI ワークロードの加速を実現する仕組みを紹介する動画をご覧ください。


