AssemblyAI、大規模な AI 推論で Google Cloud TPU v5e を活用してトップレベルのコスト パフォーマンスを実現
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
AssemblyAI では、お客様による人間の発話の文字起こしと理解を支援するために、多数の AI モデルを提供しています。日々、音声対応 AI アプリケーションを開発するお客様による 2,500 万回以上の推論呼び出しを処理しています。これほど規模が大きい場合、当然のことながら、コンピューティング費用全体のかなり大きな部分を AI 推論の実行にかかる費用が占めることになります。つまり、推論にかかる費用を大幅に削減できれば、その成果をお客様にも還元できることになります。たとえば、Literably のようなお客様は、こうした費用削減によって当社の最新の AI 音声認識技術を制限なく活用して現実的な問題を解決できます。
当社の目標は、可能な限り多くのお客様に価値ある有用な AI を活用していただくことです。このため、技術スタックの検討と強化によって、AI を幅広く浸透させるための障害を減少させる取り組みを継続しています。
先日、GKE で Google Cloud の新しい Cloud TPU v5e をテストする機会があり、この専用の AI チップによって当社の推論にかかる費用を削減できるかどうかを確認できました。実際の環境で実際のデータに対して当社の実稼働環境用の音声認識モデルを実行したところ、他の高速化されたインスタンスと比較して Cloud TPU v5e が 1 ドル当たり最大 4 倍のパフォーマンスを発揮することがわかりました。
TPU v5e と他のアクセラレータでの Conformer-2 の比較
当社の Conformer-2 モデルは最新の音声認識モデルであり、実際のデータを処理するように設計されています。テストではこれをベンチマーク モデルとして使用し、推論にかかる費用を比較しました。よく使用される複数のアーキテクチャのコンポーネントが組み込まれているため、Conformer-2 はこの種の比較テストには最適です。畳み込みレイヤ、Transformer ブロック、LSTM ブロックで構成されています。
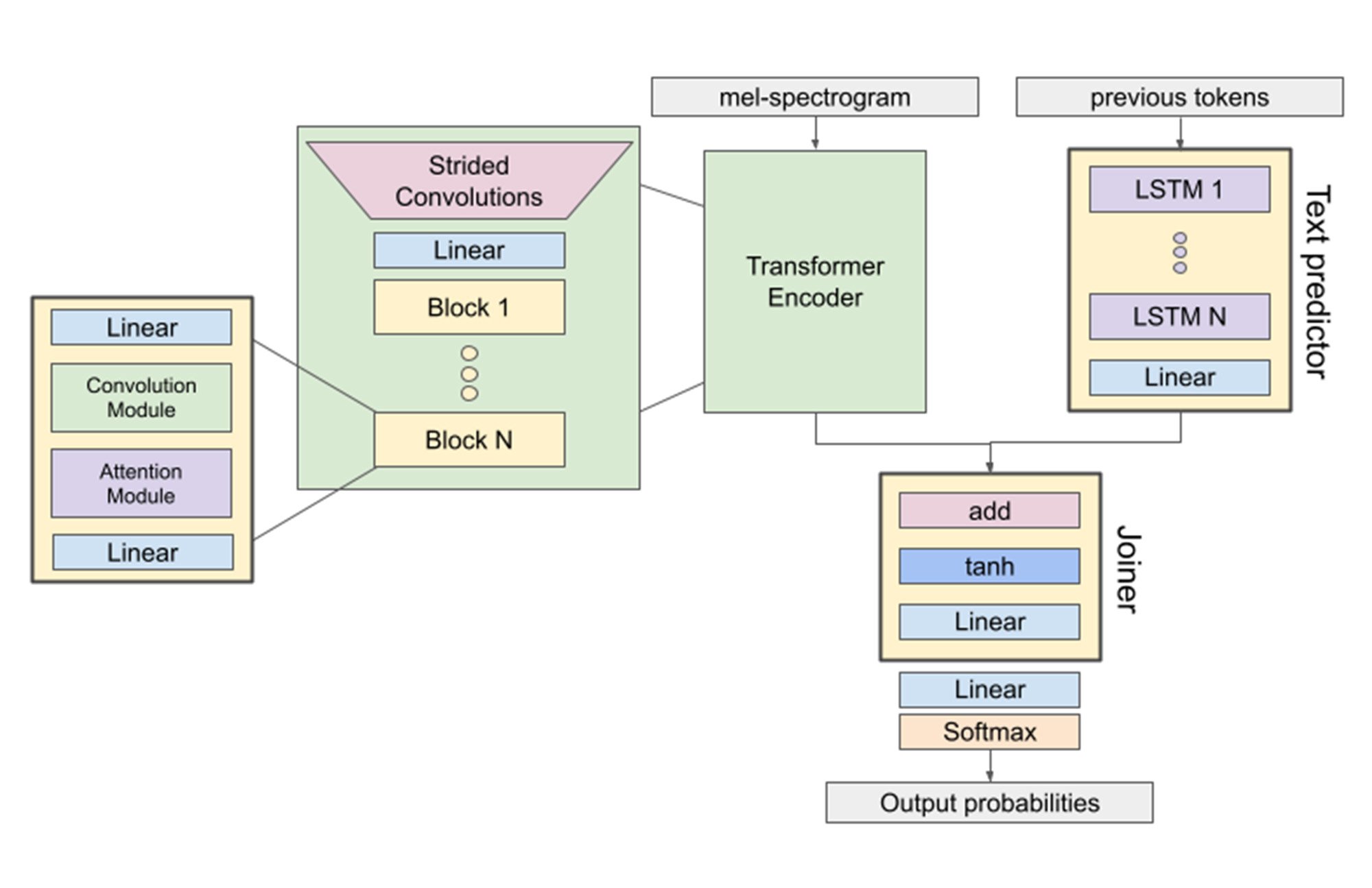
図 1: Conformer-2 モデルのアーキテクチャ。データ提供: AssemblyAI。2023 年 11 月。
この比較では JAX を利用しました。これは、AI モデルを XLA(AI モデル専用に設計されたコンパイラ)でコンパイルできるようにする非常に効率的なライブラリです。XLA を使用すると、さまざまなハードウェアに適宜移行できる Conformer-2 のコンパイル済み表現を構築できます。これにより、Google Cloud の高速化された各インスタンスでモデルを簡単に実行できるようになり、シンプルに比較できます。
テストの環境
テストに使用した Conformer-2 モデルには 20 億個のパラメータがあり、1,500 個以上の隠れ次元、12 個のアテンション ヘッド、24 個のエンコーダ レイヤを備えています。Google Cloud TPU v5e、G2、A2 の 3 種類の高速化されたインスタンスでこのモデルをテストしました。チップ時間あたりの課金というクラウドの料金モデルを考慮し、チップのメモリの制限内で、アクセラレータのタイプごとにバッチサイズを最大化しました。これにより、本番環境システムで文字起こしされる音声にかかる 1 時間あたりの費用を正確に測定できました。
各チップを評価するために、各ハードウェアにモデルを介して同じ音声データを渡し、各ハードウェアの推論速度を測定しました。このアプローチにより、結果に影響を及ぼす不要な要素を排除した形で、10 万時間分の音声データに対する推論を実行するための費用をチップごとに評価できました。
結果: Cloud TPU v5e が大規模な推論に関して最高のコスト パフォーマンスを発揮
テストの結果、モデルの大規模な推論を実行する場合に最も費用対効果が高かったアクセラレータは Cloud TPU v5e であることが判明しました。G2 インスタンスに比べて 1 ドルあたり 2.7 倍のパフォーマンスを、A2 インスタンスに比べて 1 ドルあたり 4.2 倍のパフォーマンスを達成しました。
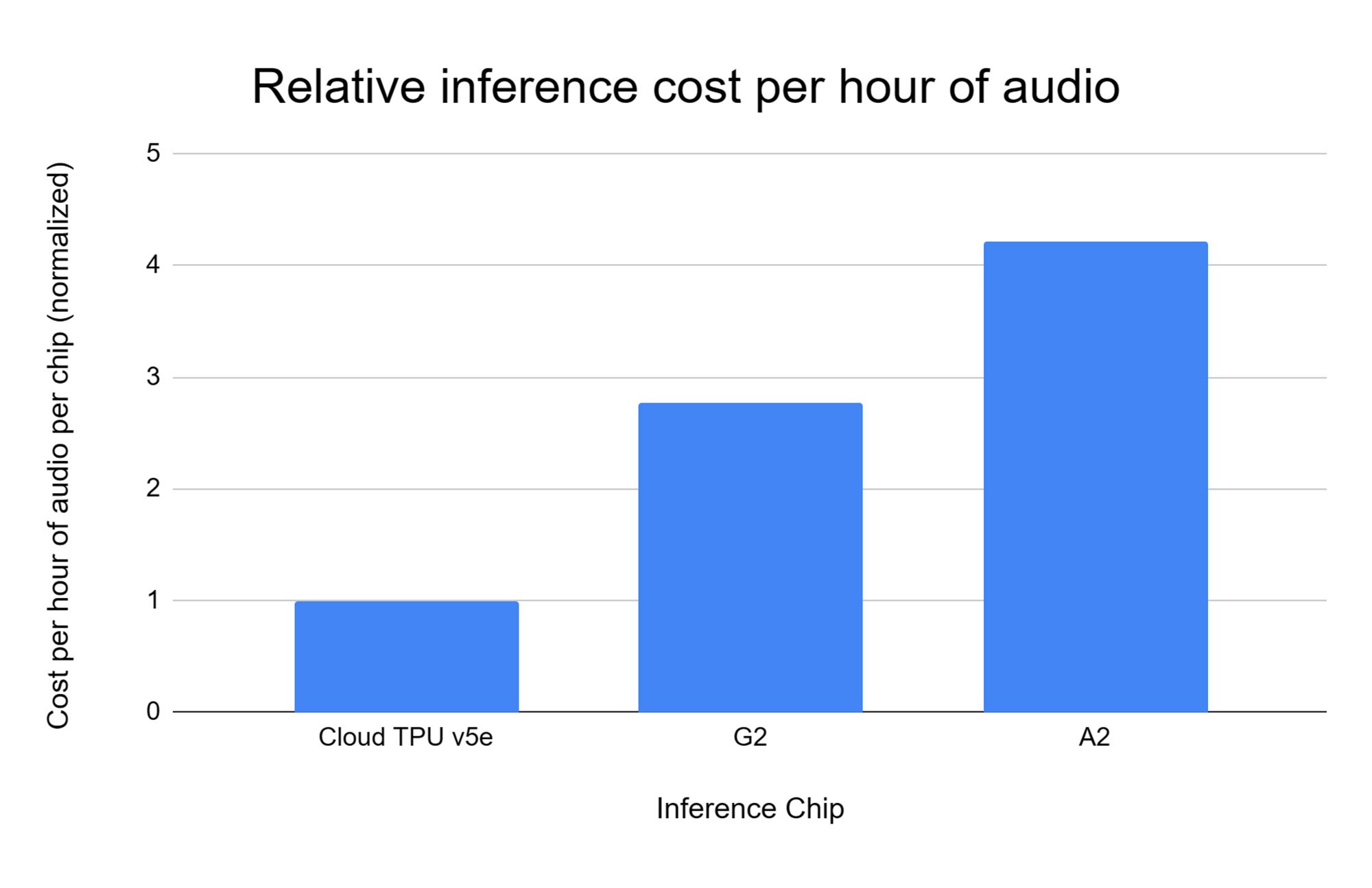
図 2: Cloud TPU v5e、G2、A2 で音声の推論を実行した際のそれぞれの 1 時間あたりの費用。
データ提供: AssemblyAI。すべての比較は AssemblyAI が Google Cloud で実行したもの。縦軸の基準値は Cloud TPU v5e = 1。他はすべてが同等で、数値が小さいほど優れていることを示す。1 時間あたりの費用は、Google Cloud で公開されている正規料金に基づく。2023 年 11 月
当社のモデル提供の運用費の大部分を推論が占めていることを考慮すると、本番環境の大規模推論に Cloud TPU v5e を利用することで大幅な費用を削減できると見込めます。
お客様への影響
当社の推論にかかる費用を削減することで、その効果をお客様にも還元できるため、広範囲に影響が及びます。AI は私たちの日常生活に浸透し始めており、その利用に必要な費用を削減することで AI 機能を広範囲で活用できるようになれば、このエコシステムのすべての関係者にとって大きな差別化要因となり得ます。
たとえば、Literably は AssemblyAI の音声文字変換を利用して、子供たちが基本的な読み書きのスキルを習得できるよう支援しています。Literably は、文字起こしによって生徒が苦手とする領域を特定することで、生徒が読むことに問題を抱えているかどうか、また問題がある場合はその状態を教師が把握できるようにするサービスを学校に提供しています。この情報を活かして、教師が特定の改善領域に合わせて授業内容を調整できます。当社が新しい Cloud TPU v5e を利用して推論にかかる費用を削減することで、AI の進化と普及に貢献できます。そしてこれは、社会のより幅広い層に対する差別化要因となります。
詳しくは、以下のインタビュー動画をご覧ください。

-AssemblyAI、テクノロジー担当 VP Domenic Donato 氏
-AssemblyAI、研究者 Andy Ehrenberg 氏
