AssemblyAI leverages Google Cloud TPU v5e for leading price-performance on large-scale AI inference
Domenic Donato
VP of Technology, AssemblyAI
Andy Ehrenberg
Researcher, AssemblyAI
At AssemblyAI, we offer dozens of AI models to help our customers transcribe and understand human speech. On any given day, we handle over 25 million inference calls by customers building voice-enabled AI applications. At such a large scale, the cost of running AI inference naturally constitutes a substantial portion of our total compute costs. Consequently, if we can lower the cost of inference at scale, we can pass material savings onto our customers as well. For example, savings allow customers such as Literably to solve real-world problems by using our cutting-edge AI speech technologies without compromises.
Our goal is to empower as many customers as possible to access useful and valuable AI. That’s why we continue to explore and advance our tech stack: to reduce the hurdle to broader AI adoption.
We recently had the opportunity to experiment with Google Cloud’s new Cloud TPU v5e in GKE to see whether these purpose-built AI chips could lower our inference costs. After running our production speech recognition model on real-world data in a real-world environment, we found that Cloud TPU v5e offers up to 4x greater performance per dollar than other accelerated instances we compared.
Conformer-2 on TPU v5e and other accelerators
Our Conformer-2 model is a state-of-the-art speech recognition model that’s designed to handle real-world data, and we used it as the benchmarking model in our experiments to compare inference costs. Conformer-2 is a good choice for this type of comparison because it incorporates components from several popular architectures — it contains convolutional layers, Transformer blocks, and LSTM blocks.
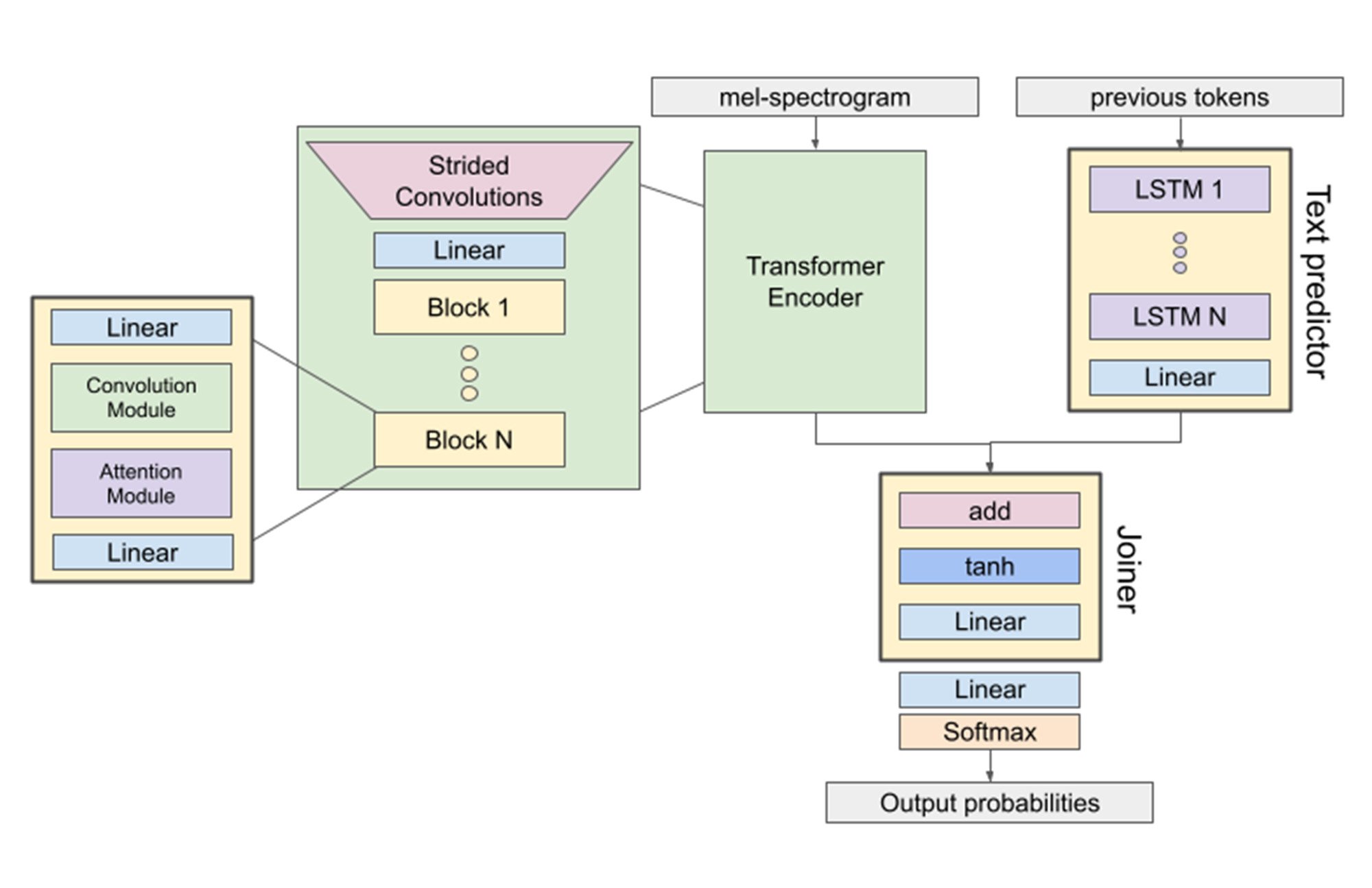
Figure 1: The Conformer-2 model architecture. Source: AssemblyAI. November 2023.
To run these comparisons, we leveraged JAX, a highly efficient library that allows AI models to be compiled with XLA, a compiler designed specifically for AI models. Using XLA, we can build a compiled representation of Conformer-2 that can be conveniently ported to different hardware, making it easy to run on various accelerated instances on Google Cloud for straightforward comparison.
Experimental setup
The Conformer-2 model that we used for testing has 2 billion parameters, with over 1.5k hidden dimensions, 12 attention heads, and 24 encoder layers. We tested the model on three different accelerated instances on Google Cloud TPU v5e, G2, and A2. Given the cloud’s pay-per-chip-hour pricing model, we maximized the batch size for each type of accelerator under the constraint of the chip’s memory. This allowed for an accurate measurement of cost per hour of audio transcribed for a production system.
To evaluate each chip, we passed identical audio data through the model on each type of hardware, measuring the inference speed for each type of hardware. This approach allowed us to evaluate the cost per chip to run inference on 100k hours of audio data with no confounding factors.
Results: Cloud TPU v5e leads in large-scale inference price-performance
Our experimental results show that Cloud TPU v5e is the most cost-efficient accelerator on which to run large-scale inference for our model. It delivers 2.7x greater performance per dollar than G2 and 4.2x greater performance per dollar than A2 instances.
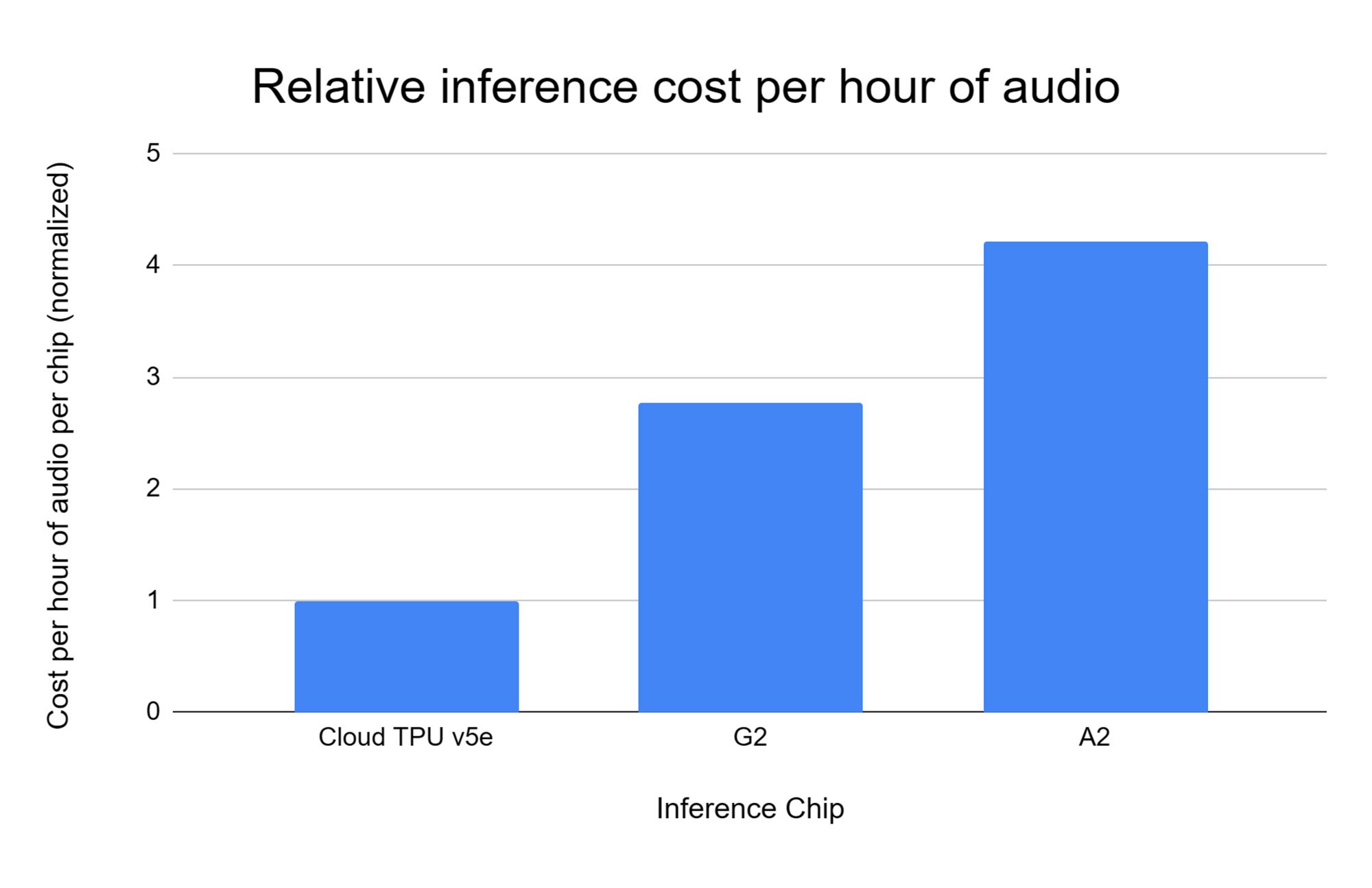
Figure 2: Inference cost per hour of audio on Cloud TPU v5e, G2, and A2, respectively.
Source: AssemblyAI. All comparisons were done on Google Cloud by AssemblyAI, where Cloud TPU v5e = 1 on the relative vertical scale. All else equal, smaller numbers are better. Cost per hour is based on publicly available list prices on Google Cloud. November 2023
Given that inference accounts for the majority of our operational costs in serving models, we believe leveraging Cloud TPU v5e for large-scale production inference will yield a significant cost saving.
Downstream impact
Lowering our inference costs allows us to pass on these savings to our customers, which has far-reaching implications. As AI becomes more integrated into our daily lives, engendering widespread use of AI capabilities by lowering the costs of access can make a substantial difference to all players in the ecosystem.
For example, Literably leverages AssemblyAI’s speech-to-text to help children build foundational literacy skills. Literably provides a service to schools that helps teachers understand whether and how students may be struggling with their reading by transcribing and identifying areas of difficulty. These insights allow teachers to adapt lessons to target specific areas for improvement. By leveraging the new Cloud TPU v5e to lower our inference costs, we can contribute to the advancement and adoption of AI that make a difference to our broader society.
To learn more, please view the interview video:


