Cloud TPU v5e の一般提供: 費用効率の高い AI モデルのトレーニングと推論が可能に
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
本日は、Cloud TPU プラットフォームに関する 2 つの重要な最新情報をお知らせします。まず、最新の MLPerf™ Training 3.1 の結果1で、大規模言語モデル(LLM)のトレーニングに関して、TPU v5e が前世代の TPU v4 と比較して 2.3 倍のコスト パフォーマンス向上を達成しました。これは、9 月の MLPerf™ Inference 3.1 ベンチマークで、LLM の推論に関して TPU v4 の 2.7 倍のコスト パフォーマンスが示されたことに続く成果です。
次に、Cloud TPU v5e とともに、単一ホスト推論テクノロジーとマルチスライス トレーニング テクノロジーも一般公開されました。これらの新テクノロジーにより、Google Cloud のお客様はトレーニングと推論のワークロード両方に統合 TPU プラットフォームを使用できるようになり、費用効率、スケーラビリティ、汎用性を向上させることができます。
8 月の発表以降、お客様は AI モデルのトレーニングと提供に関する幅広いワークロードに TPU v5e を活用してきました。たとえば、Anthropic は TPU v5e を使用して同社の Claude LLM の提供を効率的にスケールしています。Hugging Face と AssemblyAI はそれぞれ、TPU v5e を使用して画像生成と音声認識のワークロードの提供を効率的に行っています。さらに Google も、TPU v5e を利用して Google Bard などの社内の最新テクノロジーのワークロードを大規模にトレーニングし、提供しています。
MLPerf Training 3.1 LLM ベンチマークで 2.3 倍のパフォーマンス効率を達成
GPT-3 175B モデルの MLPerf Training 3.1 ベンチマークでは、ネイティブの BF16 に加えて INT8 の精度形式を利用する新しい混合精度トレーニング アプローチを採用しました。この新しい手法は Accurate Quantized Training(AQT)と呼ばれるもので、近年の AI ハードウェア アクセラレータの低ビット、高パフォーマンスの数値を使用する量子化ライブラリを利用しており、GitHub で開発者向けに提供されています。GPT-3 175B モデルは、マルチスライス トレーニング テクノロジーによって 4,096 個の TPU v5e チップにスケールしている間に収束(トレーニングを続けてもモデルがそれ以上改善されることがなくなるポイントに到達)しました。コスト パフォーマンスが向上すれば、お客様は費用を抑えながらモデルの精度向上を継続できるようになります。
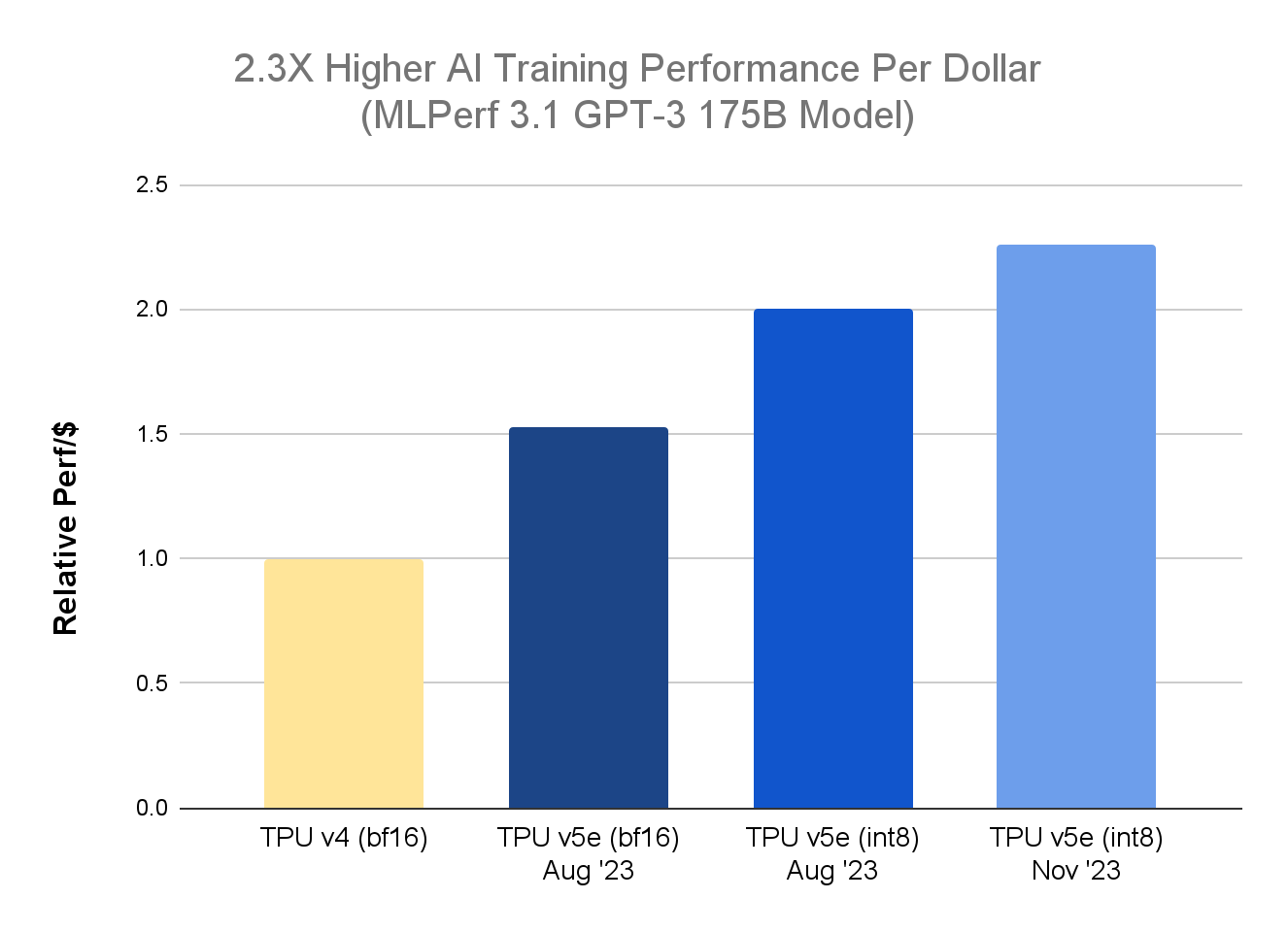
v5e の MLPerf™ 3.1 Training Closed の結果、TPU v4 については Google 内部データ。2023 年 11 月時点の情報: すべての数値はチップごとに正規化。相対的なパフォーマンスで実装した GPT-3 の 1,750 億パラメータ モデルの場合、seq-len=2048。使用した正規料金: TPU v4 はチップ時間あたり $3.22、TPU v5e はチップ時間あたり $1.2。*1
一般提供が開始されたマルチスライス トレーニング テクノロジーを介して 5 万個のチップにスケール
Cloud TPU マルチスライス トレーニングは、数万個の TPU チップでの大規模な AI モデルのトレーニングを可能にするフルスタックのテクノロジーです。大規模な生成 AI モデルのトレーニングを信頼性の高い方法で簡単に行うことができ、価値創出までの時間の短縮と費用効率の向上を実現します。
先日、Google は LLM 向けの世界最大規模の分散トレーニング ジョブの一つを最大数の AI アクセラレータ チップで実行しました。マルチスライスと AQT による INT8 精度形式で 5 万個以上の TPU v5e チップにスケールして、320 億パラメータの高密度 LLM モデルをトレーニングし、53% という効果的なモデルの FLOP 使用率(MFU)を達成しました。これに対し、6,144 個の TPU v4 チップで 5,400 億パラメータの PaLM をトレーニングした際の MFU は 46% でした。
さらに、このテストでは効率的なスケーリングも確認されました。これにより、研究者とトレーニング担当者は大規模で複雑なモデルを短時間でトレーニングでき、幅広い AI アプリケーションにおける短期間での飛躍的な成果につながっています。
しかし、これで終わりではありません。Google は今後も新しいソフトウェア手法への投資を継続し、スケーラビリティとパフォーマンスの限界を押し上げていきます。すでに TPU v5e に AI トレーニングのワークロードをデプロイしているお客様には、新機能が追加されるたびにそのメリットを享受していただけます。たとえば、データセンター ネットワーク(DCN)の階層集団演算などのソリューションを検討しており、複数の TPU Pod でコンパイラのスケジューリングをさらに最適化する予定です。
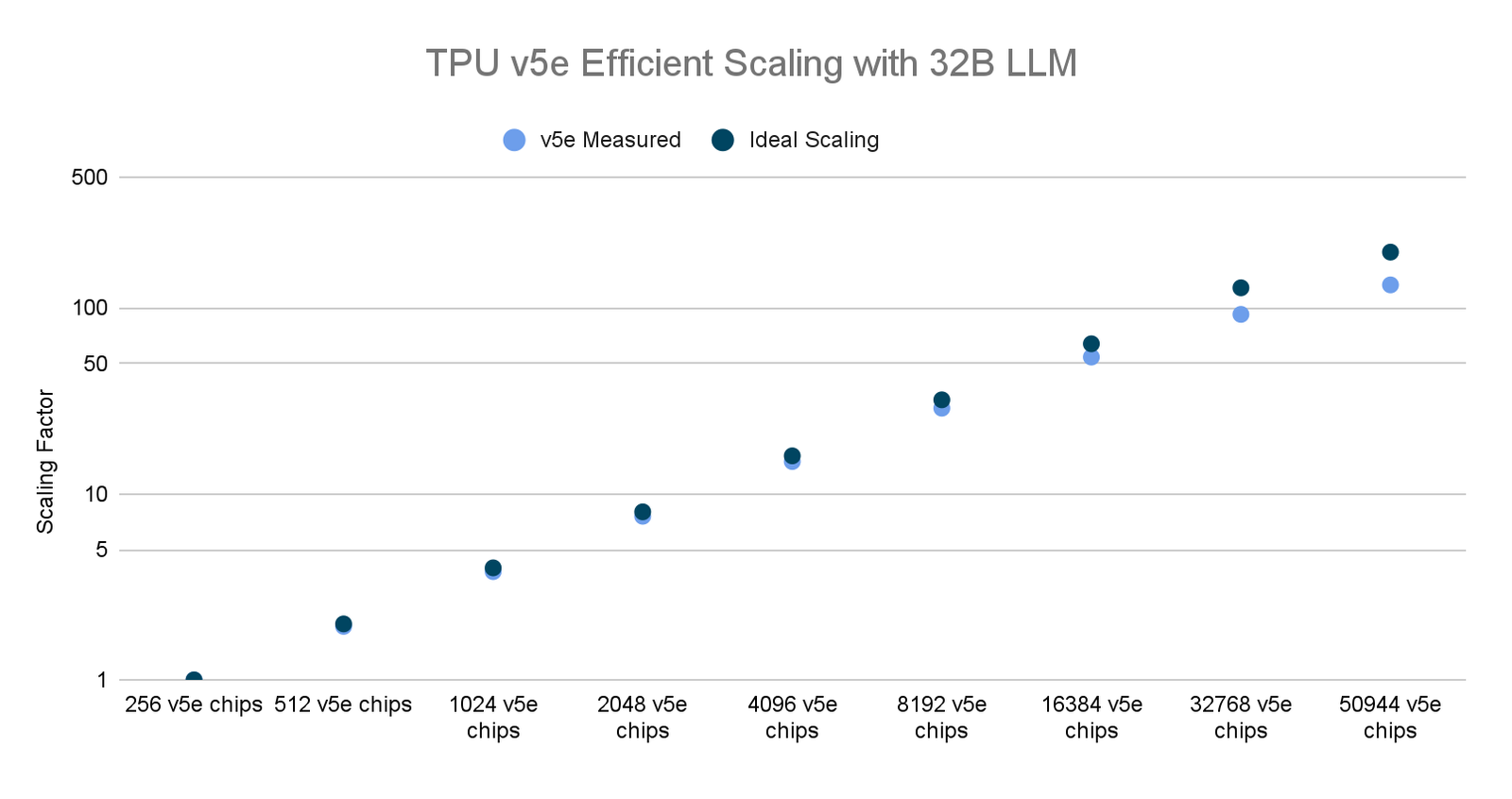
TPU v5e に関する Google 内部データ(2023 年 11 月現在): すべての数値はチップごとに正規化。MaxText を使用して実装された 320 億パラメータ デコーダのみの言語モデルの場合、seq-len=2048。*2
Cloud TPU v5e を AI のトレーニングと提供のためにデプロイしたお客様の事例
お客様は、最新の LLM を迅速かつ効率的にトレーニングして提供するために Cloud TPU v5e の大規模なクラスタを活用しています。たとえば、AssemblyAI は、最新の AI 音声モデルに誰もがアクセスできるようにするための取り組みを行っており、TPU v5e で目覚ましい成果を達成しました。
「先日、GKE で Google Cloud の新しい Cloud TPU v5e をテストする機会があり、この専用の AI チップによって当社の推論にかかる費用を削減できるかどうかを確認できました。実際の環境とデータを使って当社の実稼働環境用の音声認識モデルを実行したところ、他のソリューションと比較して TPU v5e が 1 ドルあたり最大 4 倍のパフォーマンスを発揮することがわかりました。」- AssemblyAI、テクノロジー担当バイス プレジデント Domenic Donato 氏
別の事例として、10 月の始めに Google は Hugging Face と連携し、TPU v5e を使用して Stable Diffusion XL 1.0(SDXL)での推論を高速化するデモを実施しました。現在、Hugging Face の Diffusers は Cloud TPU での JAX を介した SDXL の提供をサポートしているため、コンテンツ作成のユースケースで推論のパフォーマンスと費用対効果の両方を向上させることが可能です。たとえば、テキストから画像を生成するワークロードの場合、チップ 8 個の TPU v5e で SDXL を実行すると、チップ 1 個で 1 個のイメージを作成するために必要なのと同じ時間で 8 個のイメージを生成できます。
Google Bard チームも、生成 AI chatbot のトレーニングと提供に Cloud TPU v5e を使用しています。
「TPU v5e は、Bard の早期リリース以降、このプラットフォームの ML トレーニングと推論ワークロードの両方を支えてきました。TPU v5e は柔軟性に優れており、大規模な(数千個のチップの)トレーニングの実施と、200 か国 40 言語以上に及ぶユーザーをサポートする効率的な ML 提供の両方に活用できるため、非常に満足しています。」- Google Bard、上級ソフトウェア エンジニア Trevor Strohman
TPU v5e を使用して本番環境向けの AI ワークロードを今すぐ実現
特に大規模モデルの場合、AI の高速化、パフォーマンス、効率、スケールは、イノベーションのペースに関して今後も重要な役割を果たし続けるでしょう。Cloud TPU v5e の一般提供が開始された今、お客様やエコシステムのパートナーが可能性をどのように押し広げていくかを目にすることを楽しみにしています。Cloud TPU v5e の導入の詳細については、Google Cloud のセールス スペシャリストまでお問い合わせください。
1.MLPerf™ v3.1 Training Closed、複数のベンチマークを含む。2023 年 11 月 8 日に mlcommons.org から取得。3.1-2004 の結果。1 ドルあたりのパフォーマンスは MLPerf の指標ではありません。TPU v4 の結果は未検証: MLCommons Association による検証は行われていません。MLPerf™ の名前とロゴは、米国および他の国々における MLCommons Association の商標です。権利はすべて同組織が有しており、無断使用は固く禁じられています。詳細については、www.mlcommons.org をご覧ください。
2. スケーリング ファクタは(特定のクラスタサイズのスループット)/(ベースクラスタ サイズのスループット)の比率。ベースクラスタ サイズは v5e Pod 1 個分(例: 256 チップ)。例: 512 チップのスケールでは 256 チップのスケールのスループットの 1.9 倍になるため、スケーリング ファクタは 1.9。
3. TPU v5e の 1 ドルあたりのパフォーマンスを導出するには、チップあたりのトレーニングのスループット(1 秒あたりのトークン数で測定)をオンデマンドの正規料金 $1.20 で割ります。この料金は、us-west4 リージョンの TPU v5e に関して公開されているチップ時間あたりの料金(米ドル)です。TPU v4 の 1 ドルあたりのパフォーマンスを導出するには、チップあたりのトレーニングのスループット(1 秒あたりのトークン数で測定、Google Cloud の内部結果であり MLCommons Association によって検証されたものではない)をオンデマンドの正規料金 $3.22 で割ります。この料金は、us-central2 リージョンの TPU v4 に関して公開されているチップ時間あたりのオンデマンド料金(米ドル)です。
-ML、システム、クラウド AI 担当バイス プレジデント兼ゼネラル マネージャー Amin Vahdat
-コンピューティングおよび AI インフラストラクチャ部門バイス プレジデント兼ゼネラル マネージャー Mark Lohmeyer

