GPU と TPU を使用して、高パフォーマンスで費用対効果の高い大規模な AI 推論の実現をサポート
Google Cloud Japan Team
※この投稿は米国時間 2023 年 9 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
AI モデル アーキテクチャの進歩のペースは驚異的です。これを推進しているのは、Transformer などの画期的な発明と、高品質のトレーニング データの急速な増加です。たとえば、生成 AI では、大規模言語モデル(LLM)の規模は 1 年につき 10 倍も増大しています。組織は、世界中のユーザーに AI モデルを確実かつ効率的に提供するために、こうした AI モデルを製品やサービスにデプロイしています。これにより、AI トレーニングと推論のための AI で高速化したコンピューティングの需要が飛躍的に増加しています。
最新の MLPerf™ 3.1 Inference の結果1 は、Google のシステムの画期的な進歩によって、お客様が最新の AI モデルの増え続けるコンピューティング需要にどのように対応できるかを示しています。Google Cloud の推論システムは、既存のサービスと比較してパフォーマンスは 2~4 倍、費用対効果は 2 倍以上向上します。Google Cloud は、NVIDIA GPU と Google Cloud の専用 Tensor Processor Unit(TPU)の両方を搭載した、高パフォーマンスで費用対効果が高く、スケーラブルな AI 推論サービスを幅広く提供する唯一のクラウド プロバイダであることを誇りに思います。
Google Cloud での GPU アクセラレーションによる AI 推論
Google Cloud と NVIDIA は、最先端の GPU アクセラレーションによる推論プラットフォームをお客様に提供できるよう、協力関係を継続しています。Google Cloud は最近、NVIDIA の A100 GPU を搭載した A2 VM に加えて、NVIDIA L4 Tensor コア GPU を搭載したクラウド業界初で唯一のサービス、G2 VM を発表しました。さらに、H100 GPU を搭載した次世代 A3 VM は現在限定公開プレビュー版で提供されており、来月には一般提供が開始される予定です。Google Cloud は、これら 3 つの NVIDIA 搭載 AI アクセラレータをすべて提供する唯一のクラウド プロバイダです。
H100 GPU に対する MLPerf™ 3.1 Inference Closed の素晴らしい結果では、A3 VM は、要求の厳しい推論ワークロードに対し、A2 VM と比べてパフォーマンスが 1.7~3.9 倍向上しています。一方、L4 GPU を搭載した Google Cloud G2 VM は、推論の費用対効果の最適化を検討しているお客様にとって最適な選択肢です。L4 GPU に対する NVIDIA の MLPerf™ 3.1 の結果は、G2 の強みを示しています。G2 は同等のパブリック クラウド推論サービスと比較して、1 ドルあたりのパフォーマンスが最大 1.8 倍向上します。Bending Spoons などの Google Cloud のお客様は、G2 VM を使用して、AI を活用した新しいエクスペリエンスをエンドユーザーに提供しています。

このブログ投稿全体で使用している 1 ドルあたりのパフォーマンス指標は、MLPerf™ v3.1 Inference Closed の結果から導出しました。すべての価格は本稿公開時点の最新のものです。1 ドルあたりのパフォーマンスは MLPerf™ の公式指標ではなく、MLCommons® Association による検証は行われていません。
Cloud TPU を使用した費用対効果の高い大規模な AI 推論
Google Cloud Next で発表された新しい Cloud TPU v5e では、最新の LLM や生成 AI モデルなど、幅広い AI ワークロードに対して高パフォーマンスで費用対効果の高い推論を行えます。効率的でスケーラブルかつ汎用的になるよう設計された Cloud TPU v5e では、高スループットで低レイテンシの推論パフォーマンスが実現します。各 TPU v5e チップは int8 演算を 1 秒あたり最大 393 兆回(TOPS)行うため、極めて複雑なモデルで素早く予測できます。
高速チップ間相互接続(ICI)により、Cloud TPU v5e は複数の TPU が緊密に連携して動作する最大のモデルにスケールアウトできます。MLPerf™ 3.1 の推論結果では、4 個の TPU v5e チップを使用して、60 億のパラメータがある GPT-J LLM ベンチマークを実行しています。TPU v5e は、TPU v4 と比較して 1 ドルあたり 2.7 倍のパフォーマンスを実現します。
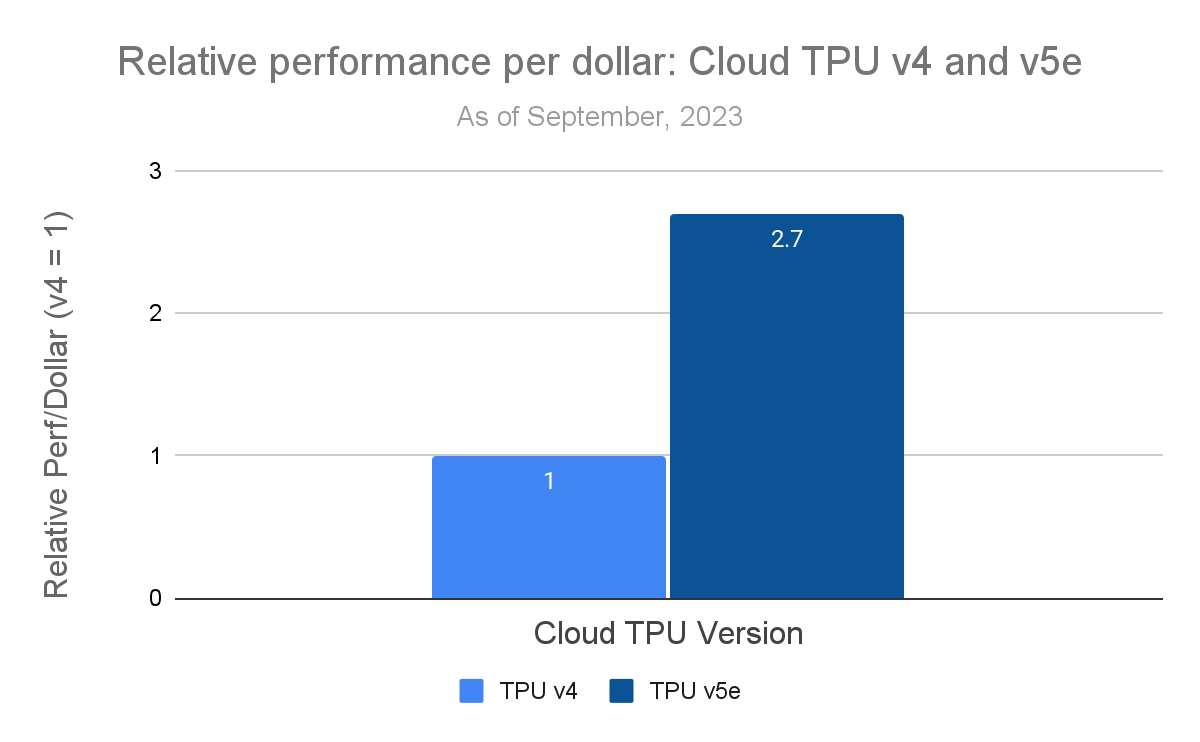
G2 の 1 ドルあたりのパフォーマンス指標と同様に、TPU3 の 1 ドルあたりのパフォーマンス指標も、MLPerf™ v3.1 Inference Closed の結果から導出しました。すべての価格は本稿公開時点の最新のものです。1 ドルあたりのパフォーマンスは MLPerf™ の公式指標ではなく、MLCommons® Association による検証は行われていません2。
パワフルな TPU v5e ハードウェアを最大限に活用する最適化された推論ソフトウェア スタックのおかげで、1 ドルあたりのパフォーマンスが 2.7 倍向上し、GPT-J LLM ベンチマークで Cloud TPU v4 システムの QPS と一致するようになります。推論スタックは、高パフォーマンスの AI 推論のために Google DeepMind によって作成されたシステム、SAX と、Google の AI コンパイラ、XLA を使用します。主な最適化には、次のようなものがあります。
XLA の最適化と Transformer 演算子の融合
int8 の精度によるトレーニング後重み量子化
GSPMD を使用した 2x2 トポロジ全体にわたる高パフォーマンス シャーディング
SAX でのプレフィックス計算とデコードのバッチのバケット化された実行
SAX での動的バッチ処理
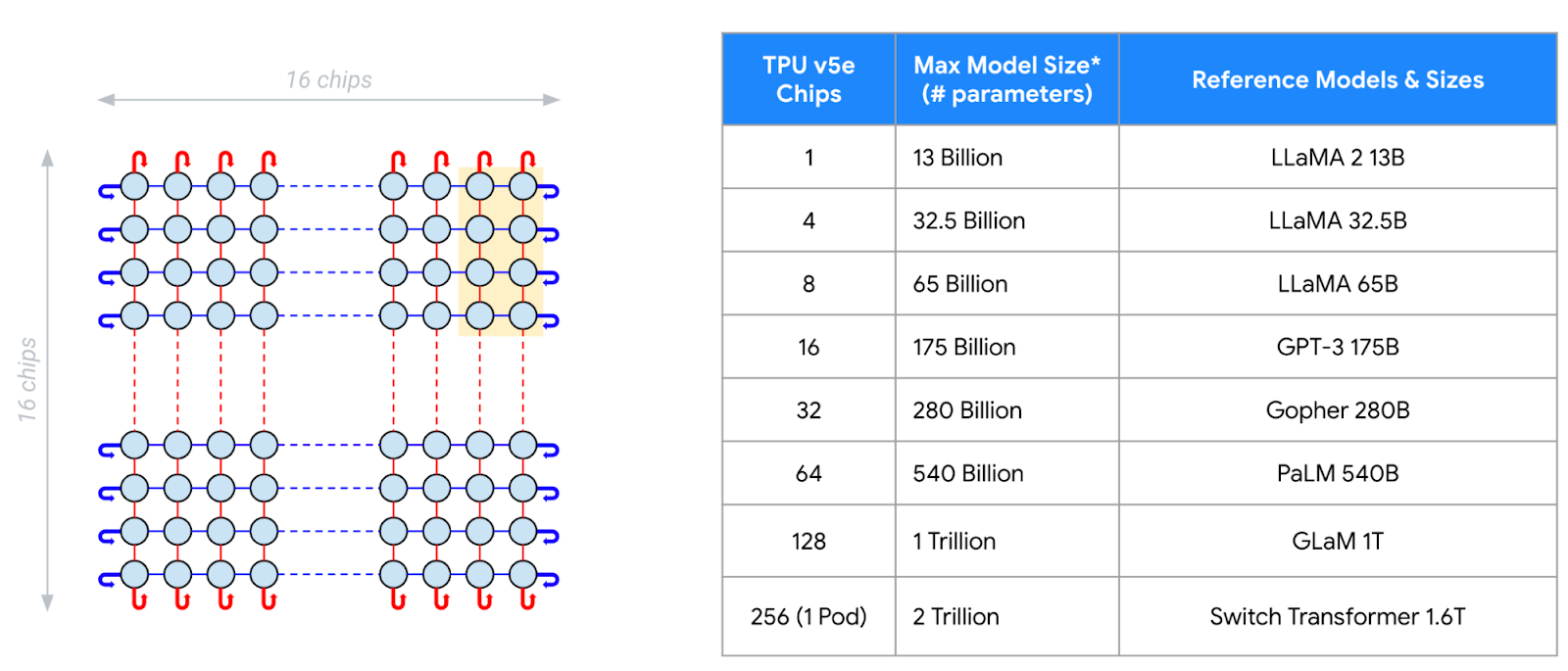
これらの結果は 4 個のチップ構成での推論パフォーマンスを示していますが、TPU v5e は ICI によりチップが 1 個から 256 個までシームレスに拡張するため、プラットフォームはさまざまな推論とトレーニングの要件を柔軟にサポートできます。以下に示すように、256 個のチップを備えた 16x16 TPU v5e トポロジは、最大 2 兆個のパラメータ モデルの推論をサポートします。新しく利用可能になったマルチスライス トレーニングとマルチホスト推論ソフトウェアを使用すると、Cloud TPU v5e はさらに 256 個のチップを備えた複数の Pod に拡張できます。そのためお客様は Google が社内で使用しているのと同じテクノロジーを活用して、最大かつ最も複雑なモデルのトレーニング システムとサービング システムの要件を満たすことができます。
AI イノベーションを大規模に加速
GPU と TPU を搭載した高パフォーマンスで費用対効果の高い AI 推論の幅広い選択肢を備えた Google Cloud は、組織が AI ワークロードを大規模に加速できるようにする唯一無二の立場にあります。
「当社のチームは Google Cloud の AI Infrastructure ソリューションの大ファンで、AI 写真アプリ Remini の「AI フィルタ」機能に Google Cloud G2 GPU VM を使用しています。最新のフィルタ「バービーとケン」もそうです。G2 VM を使用することで、処理のレイテンシー時間を大幅に短縮でき、その時間はタスクあたり最大 15 秒になりました。また、Google Cloud のおかげで、Remini アプリが米国のアプリストアで総合第 1 位に急上昇したときなど、ピーク時には 32,000 GPU までシームレスにスケールアップでき、1 日平均では 2,000 GPU までスケールダウンできました。」 — Bending Spoons CEO / 共同創業者 Luca Ferrari 氏
「Cloud TPU v5e は、当社の本番環境モデルで推論を実行する際に、市販の同等のソリューションと比較して、1 ドルあたり最大 4 倍のパフォーマンスを一貫して実現しました。Google Cloud のソフトウェア スタックは高パフォーマンスと効率を実現するよう最適化されており、最先端の AI モデルと ML モデルを高速化することに特化した TPU v5e ハードウェアを最大限に活用します。このハードウェアとソフトウェアのパワフルで汎用性の高い組み合わせにより、解決までの時間が劇的に短縮されました。何週間もかけてカスタム カーネルを手作業で調整するのではなく、数時間以内にモデルを最適化して推論パフォーマンスの目標を達成し、上回ることができました。」 — AssemblyAI テクノロジー担当バイス プレジデント Domenic Donato 氏
「YouTube は TPU v5e プラットフォームを使用して、YouTube のトップページと WatchNext で何十億ものユーザーにおすすめを提供しています。TPU v5e は、前の世代と比較して、同じ費用で最大 2.5 倍のクエリを実行します。」 — YouTube、プロダクト管理ディレクター Todd Beaupré 氏
Google Cloud GPU と TPU の使用を開始するには、担当の Google Cloud アカウント マネージャーか、Google Cloud セールスにお問い合わせください。
1. MLPerf™ v3.1 Inference Closed、表示した複数のベンチマーク、オフライン、99%。2023 年 9 月 11 日に mlcommons.org から取得。結果 3.1-0106、3.1-0107、3.1-0120、3.1-0143。1 ドルあたりのパフォーマンスは MLPerf の指標ではありません。TPU v4 の結果は未検証: MLCommons Association による検証は行われていません。MLPerf™ の名前とロゴは、米国および他の国々における MLCommons Association の商標です。権利はすべて同組織が有しており、無断使用は固く禁じられています。詳しくは、www.mlcommons.org をご覧ください。
2. Oracle BM GPU v2.8 の 1 ドルあたりのパフォーマンスを導出するために、A100 の結果として Oracle から提出された QPS を $32.00(一般公開されている 1 時間あたりのサーバー料金(米ドル))で割りました。Oracle システムでは 8 個のチップが使用されました。G2 の 1 ドルあたりのパフォーマンスを導出するために、L4 の結果から得た QPS を $0.85(us-central1 リージョンの g2-standard-8(一般に入手可能な価格帯の同等の Google インスタンス タイプ)の一般公開されているチップ時間あたりのオンデマンド料金(米ドル))で割りました。L4 システムでは 1 個のチップが使用されました。
3. TPU v5e の 1 ドルあたりのパフォーマンスを導出するために、使用したチップの数(4 個)に $1.20(us-west4 リージョンの TPU v5e の一般公開されているチップ時間あたりのオンデマンド料金(米ドル))を乗じた数で QPS を割りました。TPU v4 の 1 ドルあたりのパフォーマンスを導出するために、チップの数に $3.22(us-central2 リージョンの TPU v4 の一般公開されているチップ時間あたりのオンデマンド料金(米ドル))を乗じた数で QPS(Google Cloud の内部結果であり、MLCommons Association によって検証されたものではない)を割りました。
- ML、システム、Cloud AI 担当バイス プレジデント兼ゼネラル マネージャー Amin Vahdat
- コンピューティングおよび ML インフラストラクチャ部門バイス プレジデント兼ゼネラル マネージャー Mark Lohmeyer

