Announcing Cloud TPU v5e GA for cost-efficient AI model training and inference
Amin Vahdat
VP/GM, Machine Learning, Systems, and Cloud AI, Google Cloud
Mark Lohmeyer
VP & GM, AI & Computing Infrastructure
Today, we are announcing two important updates to our Cloud TPU platform. First, in the latest MLPerf™ Training 3.1 results1, the TPU v5e demonstrated a 2.3X improvement in price-performance compared to the previous-generation TPU v4 for training large language models (LLMs). This builds upon the 2.7X price performance advantage over TPU v4 for LLM inference that we demonstrated in September for the MLPerf™ Inference 3.1 benchmark.
Second, Cloud TPU v5e is now generally available, as are our Singlehost inference and Multislice Training technologies. These advancements bring cost-efficiency, scalability, and versatility to Google Cloud customers, with the ability to use a unified TPU platform for both training and inference workloads.
Since we introduced it in August, customers have embraced TPU v5e for a diverse range of workloads spanning AI model training and serving: Anthropic is using TPU v5e to efficiently scale serving for its Claude LLM. Hugging Face and AssemblyAI are using TPU v5e to efficiently serve image generation and speech recognition workloads, respectively. Additionally, we rely on TPU v5e for large-scale training and serving workloads of cutting-edge, in-house technologies such as Google Bard.
Delivering 2.3X higher performance efficiency on MLPerf Training 3.1 LLM benchmark
In our MLPerf Training 3.1 benchmark for GPT-3 175B model, we advanced our novel mixed-precision training approach to leverage the INT8 precision format in addition to native BF16. This new technique, called Accurate Quantized Training (AQT), employs a quantization library that uses low-bit and high-performance numerics of contemporary AI hardware accelerators and is available to developers on Github. The GPT-3 175B model converged (the point in which additional training would not further improve the model) while scaling to 4,096 TPU v5e chips via Multislice Training technology. Better price-performance implies that customers can now continue to improve the accuracy of their models while spending less money.
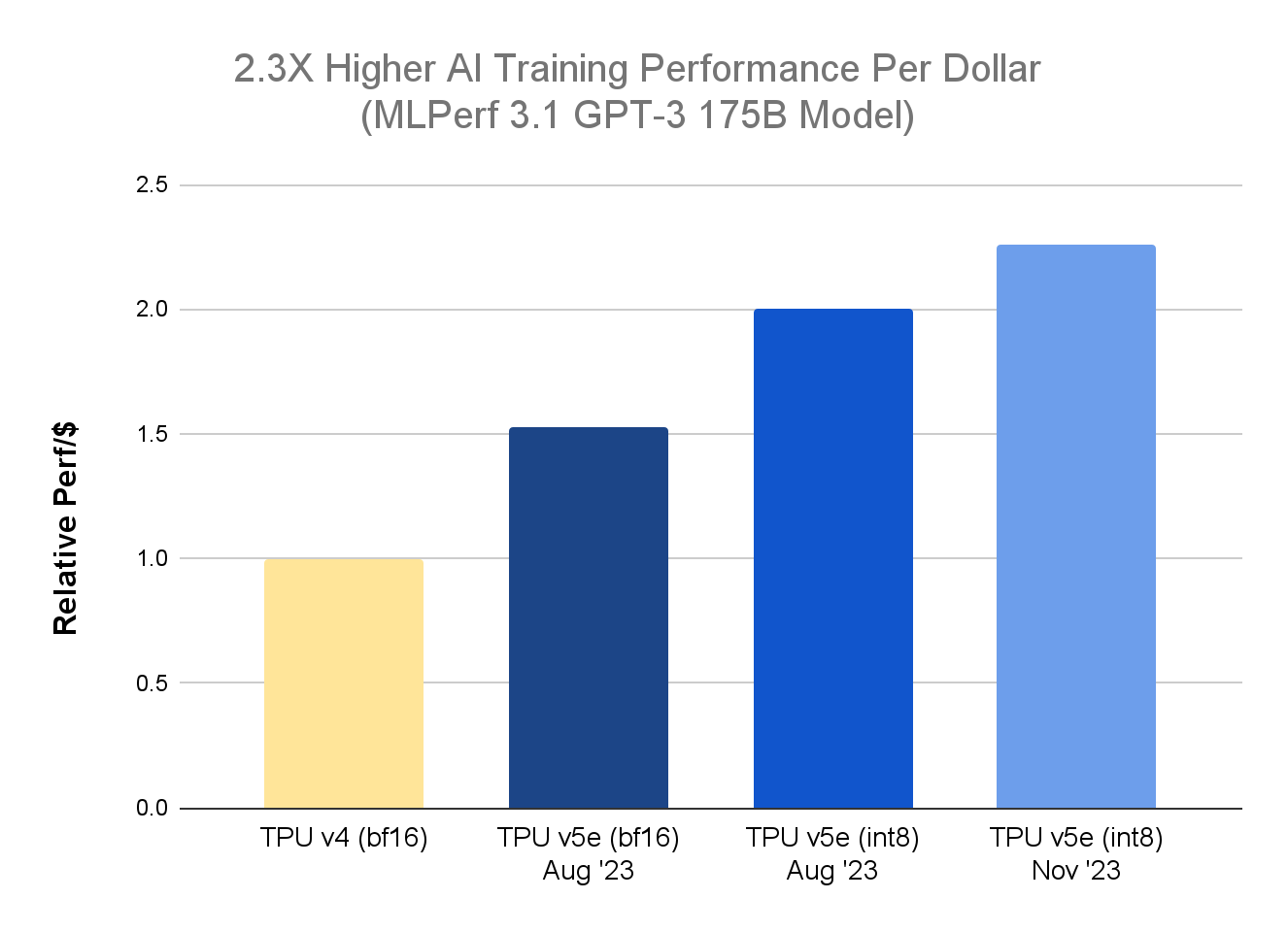
MLPerf™ 3.1 Training Closed results for v5e, Google Internal data for TPU v4. As of November, 2023: All numbers normalized per chip seq-len=2048 for GPT-3 175 billion parameter model implemented using relative performance using public list price of TPU v4 ($3.22/chip/hour) and TPU v5e ( $1.2/chip/hour).*1
Scaling to 50K chips with Multislice Training technology, now generally available
Cloud TPU Multislice Training is a full-stack technology that enables large-scale AI model training across tens of thousands of TPU chips. It allows for an easy and reliable way to train large generative AI models that can drive faster time-to-value and cost-efficiency.
Recently, we ran one of the world’s largest distributed training jobs for LLMs over the most number of AI accelerator chips. Using Multislice and the AQT-driven INT8 precision format, we scaled to 50,000+ TPU v5e chips to train a 32B-parameter dense LLM model, while achieving 53% effective model flop utilization (MFU). For context, we achieved 46% MFU when training a PaLM-540B on 6,144 TPU v4 chips.
Furthermore, our testing also reported efficient scaling, enabling researchers and practitioners to train large and complex models quickly, to help for faster breakthroughs across a wide variety of AI applications.
But we are not stopping there. We are continuing to invest in novel software techniques to push the boundaries of scalability and performance so that customers who have already deployed AI training workloads on TPU v5e can benefit as new capabilities become available. For instance, we’re exploring solutions such as hierarchical data center network (DCN) collectives and further optimizing compiler scheduling across multiple TPU pods.
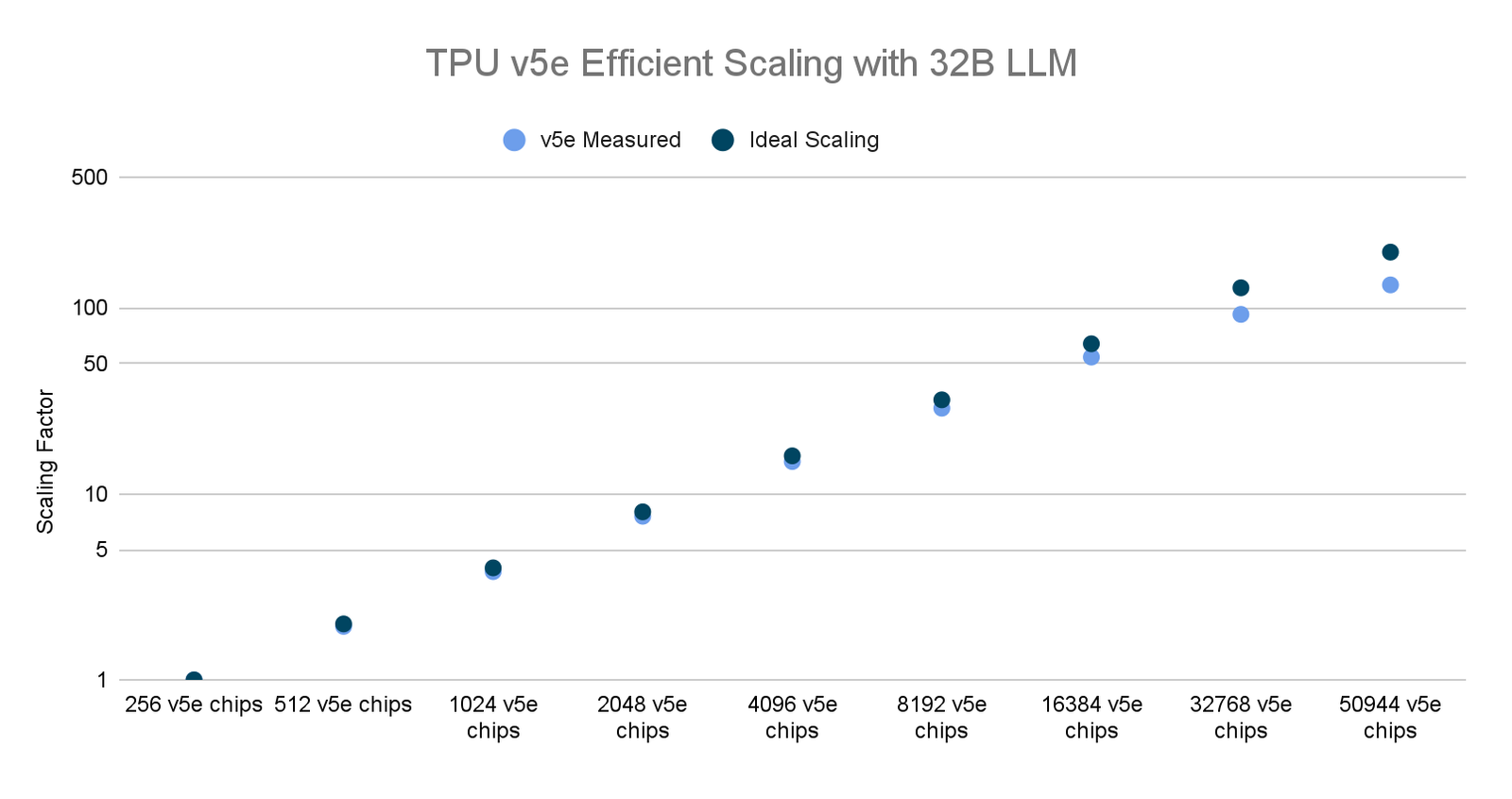
Google Internal data for TPU v5e As of November, 2023: All numbers normalized per chip. seq-len=2048 for 32 billion parameter decoder only language model implemented using MaxText. *2
Customers deploy Cloud TPU v5e for AI training and serving
Customers rely on large clusters of Cloud TPU v5e to train and serve cutting-edge LLMs quickly and efficiently. AssemblyAI, for example, is working to democratize access to cutting-edge AI speech models, and has achieved remarkable results on TPU v5e.
“We recently had the opportunity to experiment with Google’s new Cloud TPU v5e in GKE to see whether these purpose-built AI chips could lower our inference costs. After running our production Speech Recognition model on real-world data in a real-world environment, we found that TPU v5e offers up to 4x greater performance per dollar than alternatives.” - Domenic Donato, VP of Technology at AssemblyAI
Separately, in early October, we collaborated with Hugging Face on a demo that showcases using TPU v5e to accelerate inference on Stable Diffusion XL 1.0 (SDXL). Hugging Face Diffusers now support serving SDXL via JAX on Cloud TPUs, thus enabling both high-performance and cost-effective inference for content-creation use cases. For instance, in the case of text-to-image generation workloads, running SDXL on a TPU v5e with eight chips can generate eight images in the same time it takes for one chip to create a single image.
The Google Bard team has also been using Cloud TPU v5e for training and serving its generative AI chatbot.
"TPU v5e has been powering both ML training and inference workloads for Bard since the early launch of this platform. We are very delighted with the flexibility of TPU v5e that can be used for both training runs at a large scale (thousands of chips) and for efficient ML serving that supports our users in over 200 countries and in over 40 languages." - Trevor Strohman, Distinguished Software Engineer, Google Bard
Start powering your AI production workloads using TPU v5e today
AI acceleration, performance, efficiency, and scale continue to play vital roles in the pace of innovation, especially for large models. Now that Cloud TPU v5e is GA, we cannot wait to see how customers and ecosystem partners push the boundaries of what's possible. Get started today with Cloud TPU v5e by contacting a Google Cloud sales specialist today.
1. MLPerf™ v3.1 Training Closed, multiple benchmarks as shown. Retrieved November 8th, 2023 from mlcommons.org. Results 3.1-2004. Performance per dollar is not an MLPerf metric. TPU v4 results are unverified: not verified by MLCommons Association. The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
2. Scaling factor is ratio of (throughput at given cluster size) / (throughput at the base cluster size). Our base cluster size is one v5e pod (e.g., 256 chips). Example: at 512-chip scale, we have 1.9 times the throughput at 256-chip scale, therefore leading to a scaling factor of 1.9.
3. To derive TPU v5e performance per dollar, we divide the training throughput per chip (measured in tokens/sec) by the on-demand list price $1.20, which is the publicly available price per chip-hour (US$) for TPU v5e in the us-west4 region. To derive TPU v4 performance per dollar, we divide the training throughput per chip (measured in tokens/sec; internal Google Cloud results, not verified by MLCommons Association) by the on-demand list price of $3.22, the publicly available on-demand price per chip-hour (US$) for TPU v4 in the us-central2 region.
