進化する Jupiter: Google データセンターのネットワークの変遷を振り返って

Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
データセンターのネットワークは最新のウェアハウス スケール コンピューティングおよびクラウド コンピューティングの基盤を形成しています。数百 Gb/秒の帯域幅で、レイテンシを 100 マイクロ秒未満に抑えた均質な通信を何万台ものサーバー間で行えるようになったことで、コンピューティングとストレージは大きな変貌を遂げました。このモデルの主なメリットは、サーバーやストレージ デバイスをより高いレベルのサービスに段階的に追加していくと、それに比例してサービスのキャパシティと機能が向上することです。これは、シンプルながらも非常に重要です。Google では、Jupiter データセンターのネットワーク テクノロジーがユーザー向けの基本的なサービスにおいてこうしたスケールアウト機能をサポートしています。対象のサービスとして、Google 検索、YouTube、Gmail、Cloud サービス(AI および機械学習、Compute Engine、BigQuery による分析、Spanner データベース、その他数多くのサービス)などが挙げられます。
これまでの 8 年間、Google は光回路スイッチ(OCS)と波長分割多重方式(WDM)の Jupiter への統合を推進してきました。何十年もの間、非現実的であると言われてきたこの統合ですが、OCS と Google のソフトウェア定義ネットワーキング(SDN)アーキテクチャを組み合わせることで新しい機能を実現しました。その機能には、異なる技術を使用したネットワークの段階的な増強サポート、パフォーマンスの向上、レイテンシ、コスト、消費電力の削減、リアルタイムのアプリケーション優先度、コミュニケーションパターン、そしてダウンタイムのないアップグレードなどがあります。Jupiter は、よく知られている代替手段よりもフロー完了時間を 10% 削減し、スループットを 30% 向上させ、消費電力を 40%、コストを 30% 削減し、ダウンタイムを 50 分の 1 に抑えながらこれらのすべてを実行できます。これらを実現した過程の詳細については、本日 SIGCOMM 2022で発表した論文、Jupiter Evolving: Transforming Google's Datacenter Network via Optical Circuit Switches and Software-Defined Networking をご覧ください。
以下でプロジェクトの概要をご紹介します。
Jupiter データセンターのネットワークの進化
2015 年に、Jupiter データセンターのネットワークが 30,000 台を超えるサーバーに拡張され、サーバーあたり 40 Gb/秒の均一な接続を実現し、1 Pb/秒を超える総帯域幅をサポートする方法をご紹介しました。現在、Jupiter は 6 Pb/秒を超えるデータセンター帯域幅をサポートしています。次の 3 つのアイデアを活用することで、これまでにないレベルのパフォーマンスとスケールが実現しました。
ソフトウェア定義ネットワーキング(SDN) - データセンター ネットワーク内の数千のスイッチング チップをプログラムして管理するための、論理的に一元化された階層型コントロール プレーン。
Clos トポロジ - ブロックなしのマルチステージ スイッチング トポロジ。小型の基盤を用いたスイッチチップで構築され、大規模なネットワークに合わせて自在に拡張できます。
市販のスイッチ シリコン - コスト効率が良く、汎用性の高いイーサネット スイッチング コンポーネント。集約型ストレージとデータ ネットワークに使用します。
これら 3 本の柱に基づいて構築することにより、Jupiter のアーキテクチャ的アプローチは、分散システム アーキテクチャに大きな変化をもたらし、データセンターのネットワークの構築および管理の方法を業界全体に示しました。
しかし、ハイパースケールのデータセンターには、主要な課題が 2 つ残されていました。一つ目は、データセンターのネットワークは、建物全体を使用する規模(およそ 40 MW 以上のインフラストラクチャ)で導入する必要があることです。さらに、建物内に導入されたサーバーやストレージのデバイスは、常に進化しています。たとえば、ネイティブのネットワーク相互接続は 40 Gb/秒から 100 Gb/秒へと変遷し、さらに 200 Gb/秒を経て、現在では 400 Gb/秒にまで高速化しています。そのため、接続される新しい要素に対応するためには、データセンターのネットワークを動的に進化させる必要があります。
残念ながら、以下に示すように、Clos トポロジでは、接続する可能性のある最速のデバイスを均一にサポートするためのスパインレイヤが必要です。つまり、Clos を基礎とした建物規模のデータセンターのネットワークをデプロイする前に、一定の速度で動作する当時最新世代であった非常に大規模なスパインレイヤをデプロイする必要があったのです。これは、Clos トポロジは本質的に集約ブロック1からスパインへの全面的なファンアウトを必要とするためです。スパインに段階的に追加していくと、データセンター全体の配線のやり直しが必要になります。より高速なラインレートで動作する新しいデバイスをサポートする方法の一つは、スパインレイヤ全体を入れ替えて新たな速度に対応できるようにすることです。しかし、スイッチを収納した数百台のラックが配置され、数万組のファイバーのペアが建物全体にめぐらされていることを考えると、この方法は現実的とは言えません。
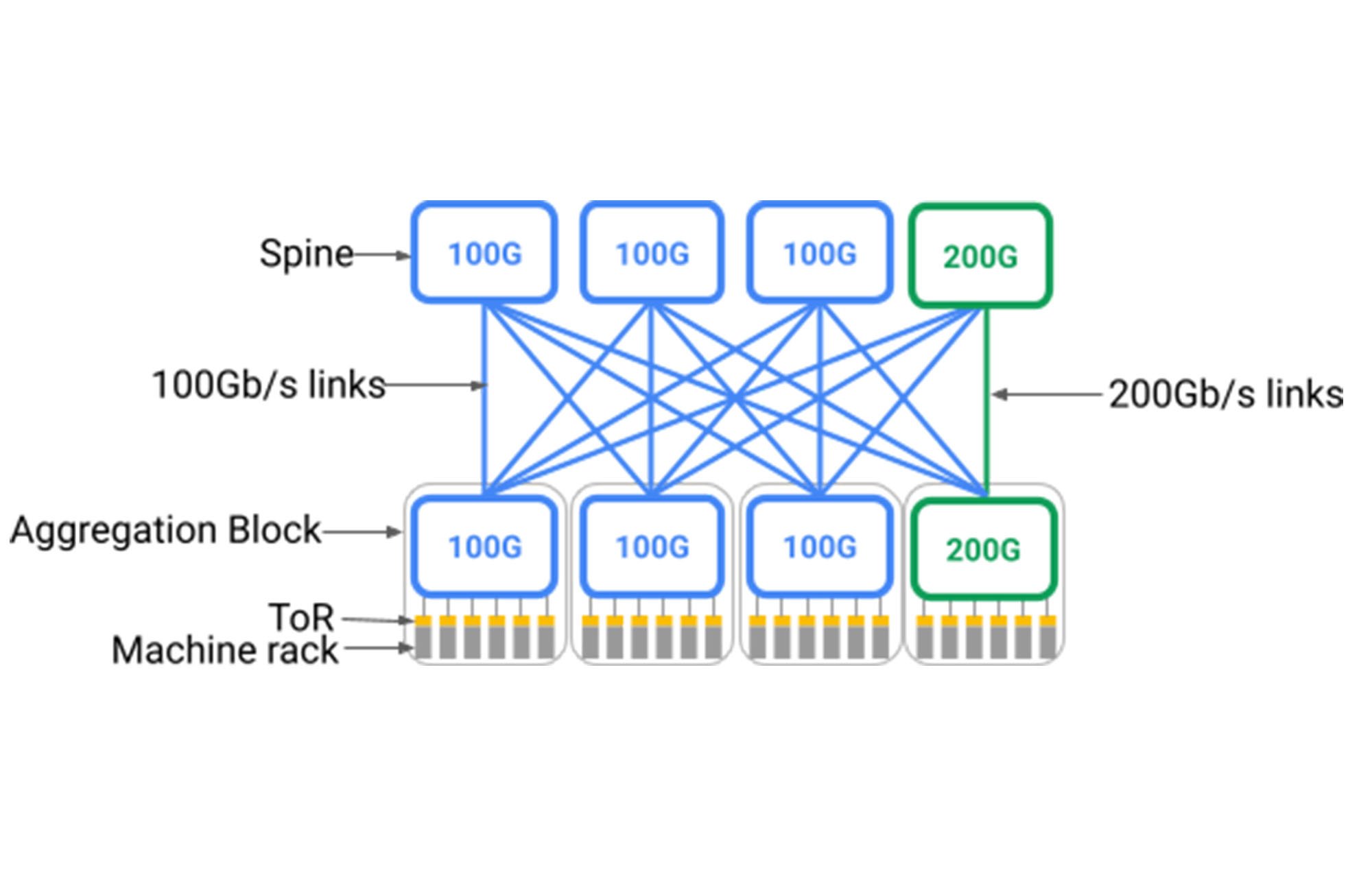
理想的には、データセンターのネットワークが「従量課金制」のモデル内で異なるネットワーク要素をサポートしており、必要なときにのみネットワーク要素を追加して、最新のテクノロジーを段階的に追加していくことが望ましいでしょう。このネットワークでは、サーバーとストレージに同じように適用可能な理想的なスケールアウト モデルをサポートし、ネットワーク容量を段階的に追加できます。そのため、たとえ以前は異なるテクノロジーがデプロイされていたとしても、デバイスの全体的な構築に比例した容量の追加やネイティブの相互運用性が可能となります。
二つ目は、建物規模の均質な帯域幅は強みの一つである反面、データセンターのネットワークが本質的にマルチテナントであり、メンテナンスや局所的な障害が継続的に発生することを考慮すると制限的である、ということです。単一のデータセンターのネットワークは、何百ものサービスをホストしています。それらのサービスの優先順位はそれぞれ異なり、帯域幅やレイテンシの変動に対する感度もさまざまです。たとえば、ウェブ検索の結果をリアルタイムで提供するには、リアルタイムのレイテンシの保証と帯域幅の割り当てが必要になる場合がありますが、数時間のバッチ分析ジョブには、短期間のより柔軟な帯域幅要件が必要になる場合があります。このため、データセンターのネットワークは、リアルタイムの通信パターンとアプリケーションを意識したネットワークの最適化に基づいて、サービスの帯域幅とパスを割り当てる必要があります。アップグレードのためにネットワーク容量を一時的に 10% 削減する必要がある場合、この 10% はすべてのテナントに均一に分散するのではなく、個々のアプリケーションの要件と優先度に基づいて配分するのが理想的です。
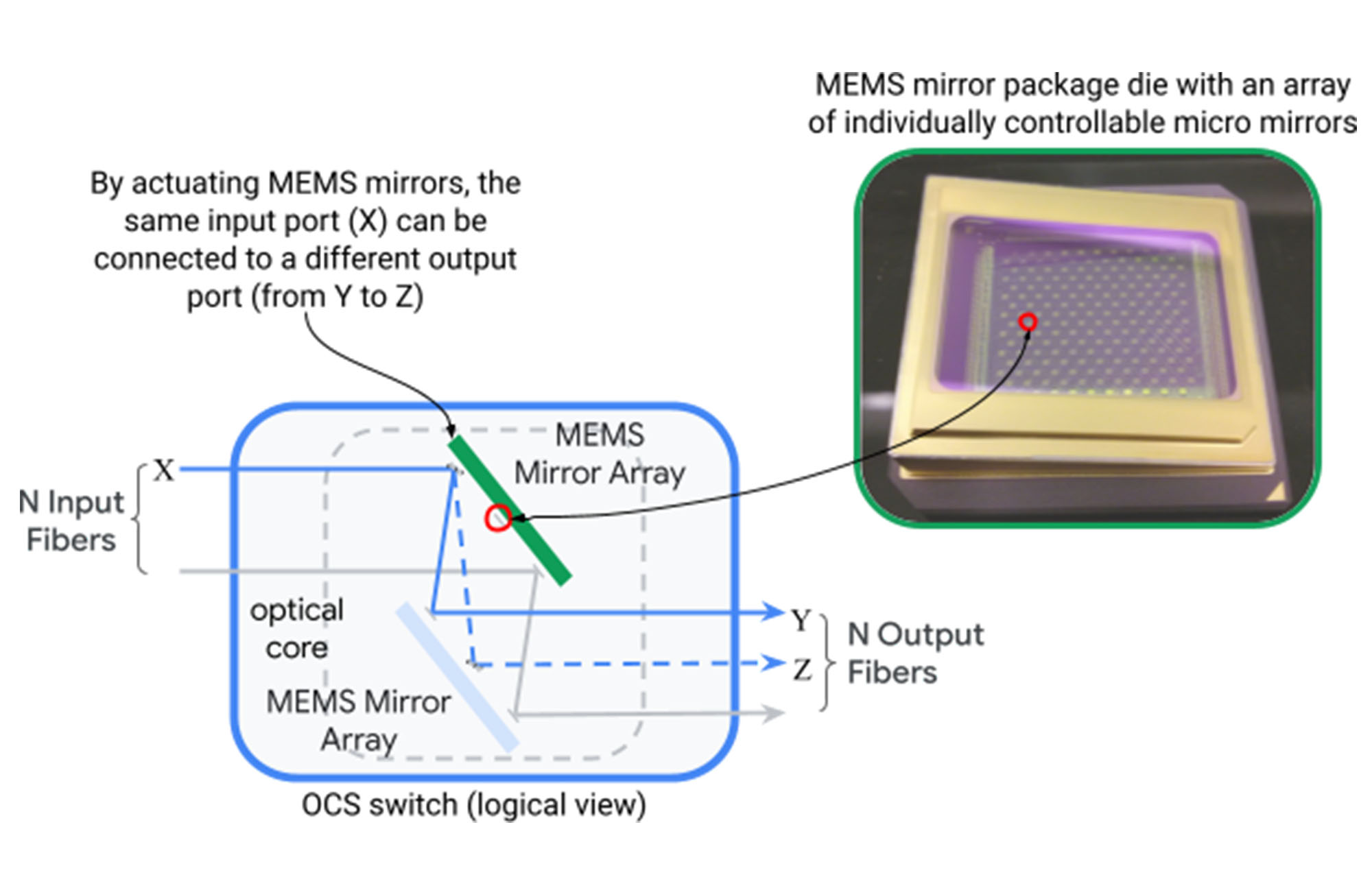
当初は、これらの残された課題に対応すること不可能のように思えました。データセンターのネットワークは、大規模な物理的スケールの階層型トポロジを中心に構築されていたため、異質な要素を段階的に追加したり、動的なアプリケーションをサポートしたりできる機能を設計に組み込むことはできませんでした。Google は光回路スイッチ(OCS)を Jupiter アーキテクチャに導入することでこの難局を突破しました。光回路スイッチ(下図)は、2 次元でローテーション可能な 2 セットの微小電気機械システム(MEMS)ミラーを介して、光ファイバーの入力ポートを出力ポートに動的にマッピングし、任意のポート間マッピングを作成します。
以下に示すように、データセンターのパケット スイッチ間に OCS 仲介層を導入することで、データセンターのネットワークに任意の論理トポロジを作成できるという知見が得られました。
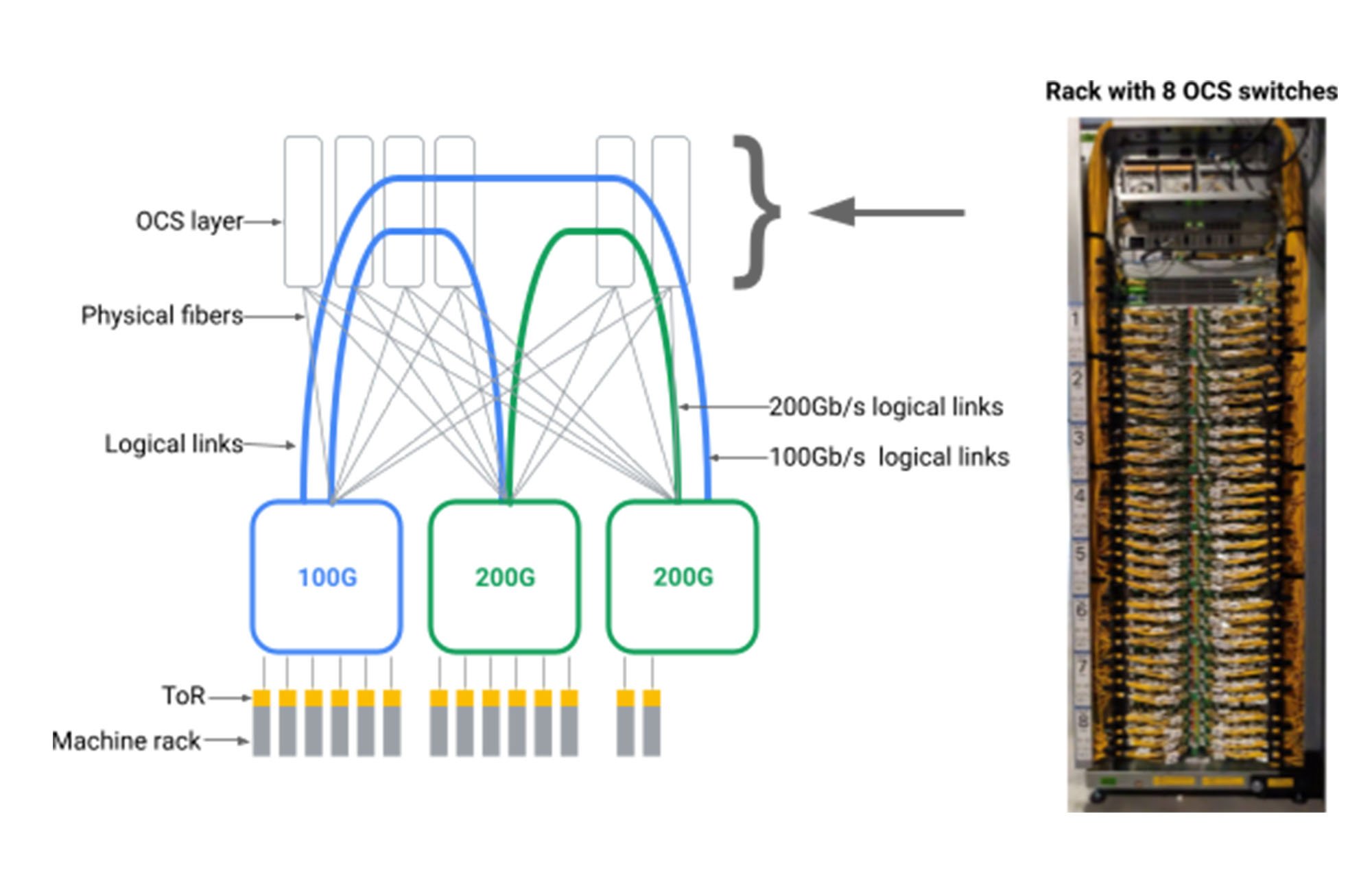
そのためには、これまでに例のない規模、製造可能性、プログラマビリティ、信頼性を備えた OCS トランシーバおよびネイティブ WDM トランシーバを構築する必要がありました。光スイッチは、学術研究においては利点が調査されていましたが、OCS のテクノロジーは商業的な実現は不可能であるというのが従来の通念でした。何年もの歳月をかけて、Google は Apollo OCS を設計しました。これは現在、Google のデータセンター ネットワークの大部分の基盤となっています。
OCS の顕著な利点の一つは、オペレーションにパケット ルーティングやヘッダー解析が関与しないことです。OCS は、光を入力ポートから出力ポートに反射するシンプルな方法で、驚くべき精度を実現し、ロスをほとんど出しません。光は、データセンターの建物全体で確実かつ効率的にデータを送信するためにすでに必要な WDM トランシーバでの電気光学変換によって生成されます。したがって、OCS は、建物のインフラストラクチャの一部となり、データレートと波長に依存しないため、電気インフラストラクチャが 40 Gb/秒から 100 Gb/秒、200 Gb/秒、さらにはそれ以上の伝送およびエンコード レートに移行しても、アップグレードは必要ありません。
OCS レイヤを使用して、データセンターのネットワークからスパインレイヤを排除し、代わりにダイレクト メッシュ内で異種の集約ブロックを接続することで、初めてデータセンターの Clos トポロジを超えました。Google は、物理的な容量とアプリケーション通信パターンの両方を反映した論理トポロジを作成しました。Google のネットワーク内のスイッチから見た論理的な接続の再構成は、現在では標準的な操作手順となっており、アプリケーションに目に見える影響を与えることなく、あるパターンから別のパターンにトポロジを動的に進化させます。Google では、ルーティング ソフトウェアと OCS の再構成によってリンクのドレインを調整し、Orion のコントロール プレーンを大いに活用して、依存関係のある操作や独立した操作など、何千もの操作をシームレスにオーケストレートすることでこれを実現しました。
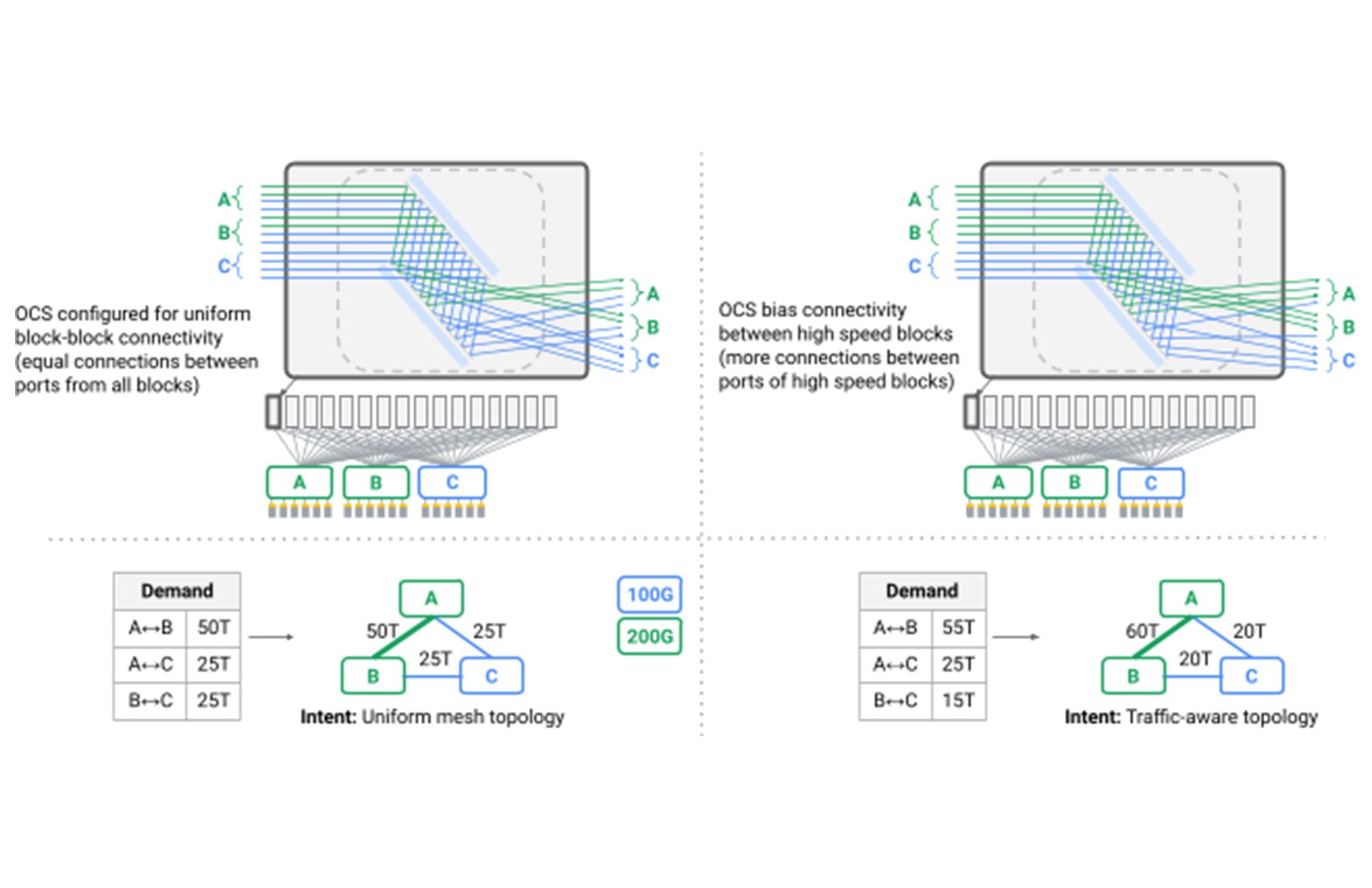
図. トポロジ エンジニアリングを実現する複数の OCS
特に興味深い課題は、メッシュ トポロジを介した最短パス ルーティングでは、Google のデータセンターに必要なパフォーマンスと堅牢性を提供できなくなったことでした。一般的な方法でデプロイされる Clos トポロジの副作用は、ネットワークを介して多くのパスが使用可能である一方で、すべてのパスが同じ長さとリンク キャパシティを持つため、無視されたパケットの振り分け、つまりバリアント ロード バランシングが十分なパフォーマンスを提供することです。Jupiter では、Google の SDN コントロール プレーンを活用して動的なトラフィック エンジニアリングを導入し、Google の B4 WAN で開発された技術を採用しています。リンク容量、リアルタイムの通信パターン、個々のアプリケーションの優先度を観察しながら、複数の最短パスと非最短パスにトラフィックを分割します(下図の赤い矢印)。
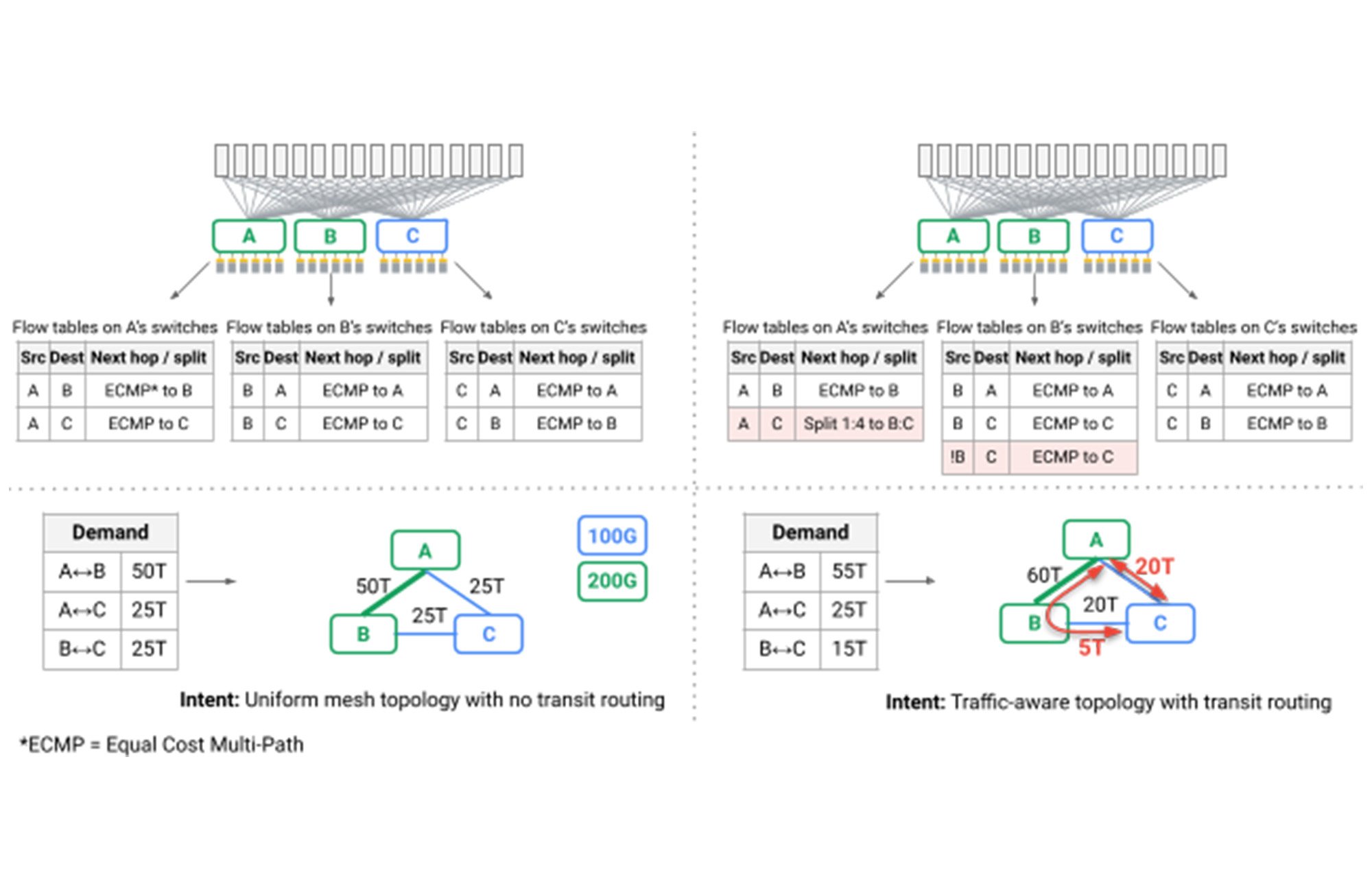
図. トラフィック エンジニアリングを実行するスイッチのフローテーブル
つまり、Google では、ウェアハウス規模のコンピュータを駆動する Jupiter データ センター ネットワークを繰り返し完全に再設計し、その過程で多くの業界初を導入してきました。
建物規模のネットワークの相互運用性ポイントとしての光回線スイッチ。異種テクノロジー、アップグレード、サービス要件をシームレスにサポートします。
高性能、低レイテンシ、低コスト、低消費電力を実現する、ダイレクトでメッシュ ベースのネットワーク トポロジ。
リアルタイムのトポロジとトラフィック エンジニアリング。リアルタイムのメンテナンスと障害を監視しながら、アプリケーションの優先度と通信パターンに一致するようにネットワーク接続とパスを同時に適応させます。
ローカライズされたキャパシティの追加または削除によるネットワークのヒットレス アップグレード。これにより、以前は何百もの顧客とサービスが建物の長時間のダウンタイムのためにサービスを移行する必要があった、コストと手間のかかる「すべてのサービスをアウト」するスタイルのアップグレードが不要になります。
基盤テクノロジーは素晴らしいものですが、Google の最終的な目標は、Google と Google Cloud を支える最も要求の厳しい分散サービスに革新的な機能を提供するパフォーマンス、効率性、信頼性を提供し続けることです。前述のように、Jupiter ネットワークは、フロー完了時間を 10% 削減し、スループットを 30% 向上させながら、40% の消費電力削減、30% のコスト削減を実現してダウンタイムを 50 分の 1 に短縮します。本日、SIGCOMM でこの技術的な偉業について詳細を共有できることを誇りに思います。また、私たちの発見についてコミュニティと議論できることを楽しみにしています。
日々 Jupiter の業務に携わっている数えきれないほどの Google 社員と、この最新の研究の著者である Leon Poutievski、Omid Mashayekhi、Joon Ong、Arjun Singh、Mukarram Tariq、Rui Wang、Jianan Zhang、Virginia Beauregard、Patrick Conner、Steve Gribble、Rishi Kapoor、Stephen Kratzer、Nanfang Li、Hong Liu、Karthik Nagaraj、Jason Ornstein、Samir Sawhney、Ryohei Urata、Lorenzo Vicisano、Kevin Yasumura、Shidong Zhang、Junlan Zhou、Amin Vahdat の各氏に、この場をお借りして心からの祝福と感謝の気持ちを贈ります。
1. 集約ブロックは、通常同じ場所に配置されたスイッチのレイヤによって接続されたトップオブラック(ToR)スイッチを含む一連のマシン(コンピューティング / ストレージ / アクセラレータ)のラックで構成されます。
- システムおよびサービス インフラストラクチャ部門バイス プレジデント兼ゼネラル マネージャー Amin Vahdat
