元データを Python や SQL を使わずに機械学習モデルに変える
Google Cloud Japan Team
※この投稿は米国時間 2020 年 4 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習はかつては専門の研究者の領域で、ソリューションの構築には複雑なモデルや独自のコードが必要でした。しかし、Cloud AutoML によって機械学習はこれまでになく身近なものになりました。モデルの構築プロセスを自動化することで、ユーザーは最小限の機械学習の専門知識(しかも最小限の時間)で高性能のモデルを作成できます。
ただし、多くの AutoML チュートリアルや入門ガイドでは、適切に整理されたデータセットがすでに用意されていることを前提としています。とはいえ実際には、データを前処理して特徴量エンジニアリングを行うために必要な手順は、モデルの構築と同じくらい複雑になることもあります。この投稿では、実際の元データからトレーニングされたモデルに至るまでどのような道のりをたどるのかをご紹介します。
ユースケース
ここでの目標は、ニューヨーク市消防局(FDNY)の月平均のインシデント対応時間を予測することです。まず、NYC OpenData のウェブサイトから 2009 年から 2018 年までの過去のデータを CSV 形式でダウンロードします。
データセットには 4,368 行があり、それぞれにその月の平均対応時間が表示されます。データは、インシデントの種類(誤報、救急医療など)、行政区、その月のインシデント件数で区切られています。
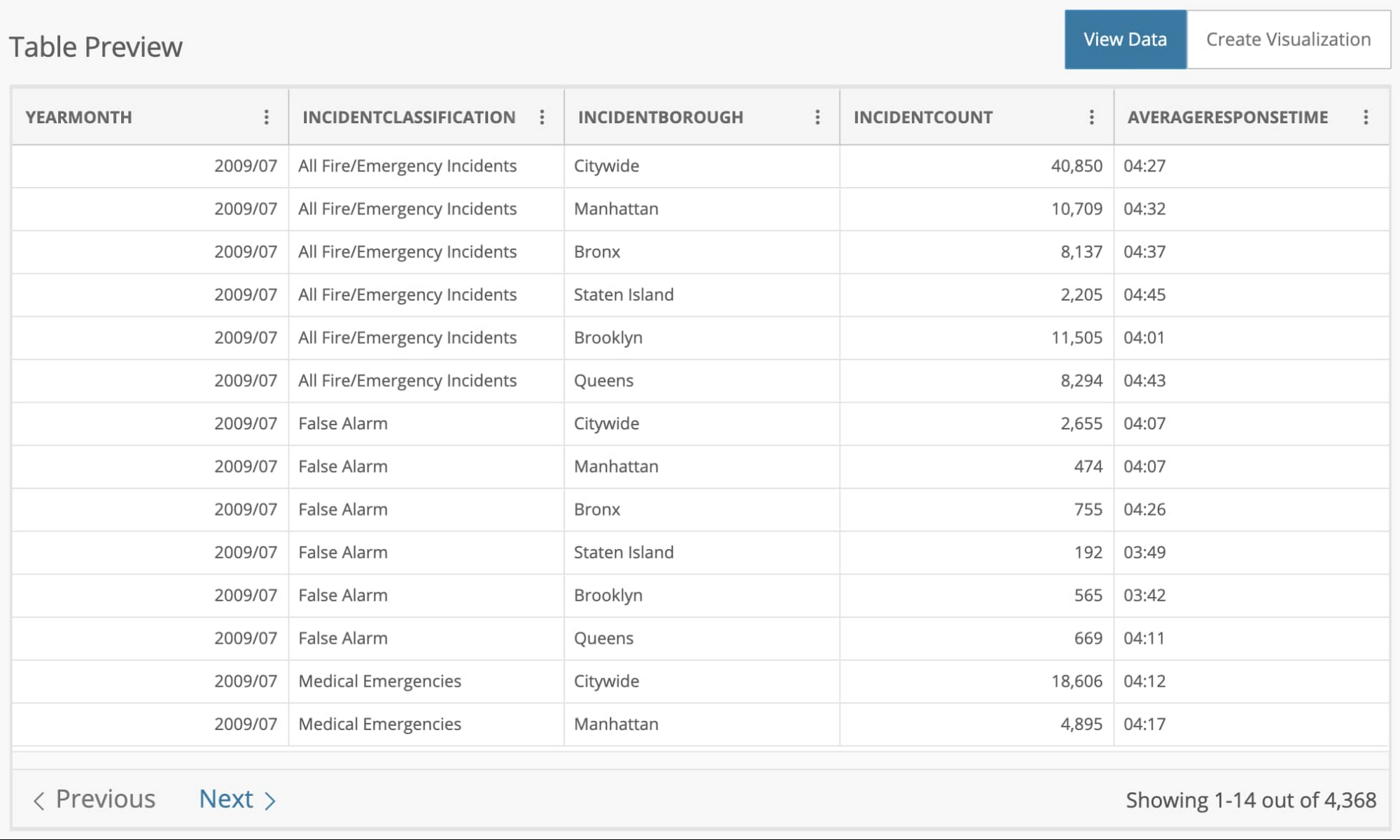
予測する列 [AVERAGERESPONSETIME] が mm:ss 形式であることに注目してください。この形式を秒などの数値形式に変える必要があります。これはモデルを構築するために必要な元データの処理手順の一例です。
始める前に
この記事では、4 つのサービスを紹介します。
Google Cloud Storage: 元データを保存するストレージ サービス
Cloud Data Fusion: データ パイプラインをオーケストレートするデータ統合サービス
BigQuery: 処理されたデータを保存するデータ ウェアハウス
AutoML Tables: 機械学習モデルを自動的に構築、デプロイするサービス
最初の手順は、CSV ファイルを Google Cloud Storage バケットにアップロードして、パイプラインで使用できるようにすることです。次に、Cloud Data Fusion のインスタンスを作成します。このドキュメントの最初の 2 つの手順に従って、API を有効にしてインスタンスを作成します。
BigQuery では、新規または既存のデータセット内にテーブルを作成する必要があります。
スキーマを作成する必要はありません。データ パイプラインで自動的に作成されます。では、パイプラインから始めましょう。
データ パイプラインを作成する
Cloud Data Fusion を使用すると、バッチのシナリオやリアルタイムのシナリオに対応したスケーラブルなデータ統合パイプラインを構築できます。標準的なデータソースと変換を表す UI コンポーネントを使用してパイプラインを設計できます。その後、パイプラインは MapReduce、Spark、Spark Streaming プログラムとして Dataproc クラスタ上で実行され
ます。
パイプラインは次の 3 つの手順で作成します。
Cloud Storage から CSV ファイルを取得する
データを機械学習に適した形式に変換する
処理されたデータを BigQuery テーブルに保存する
まず、[Studio] ビューをクリックして新しいパイプラインを作成します。図に表示されているパイプラインの各ステップについてご説明します。
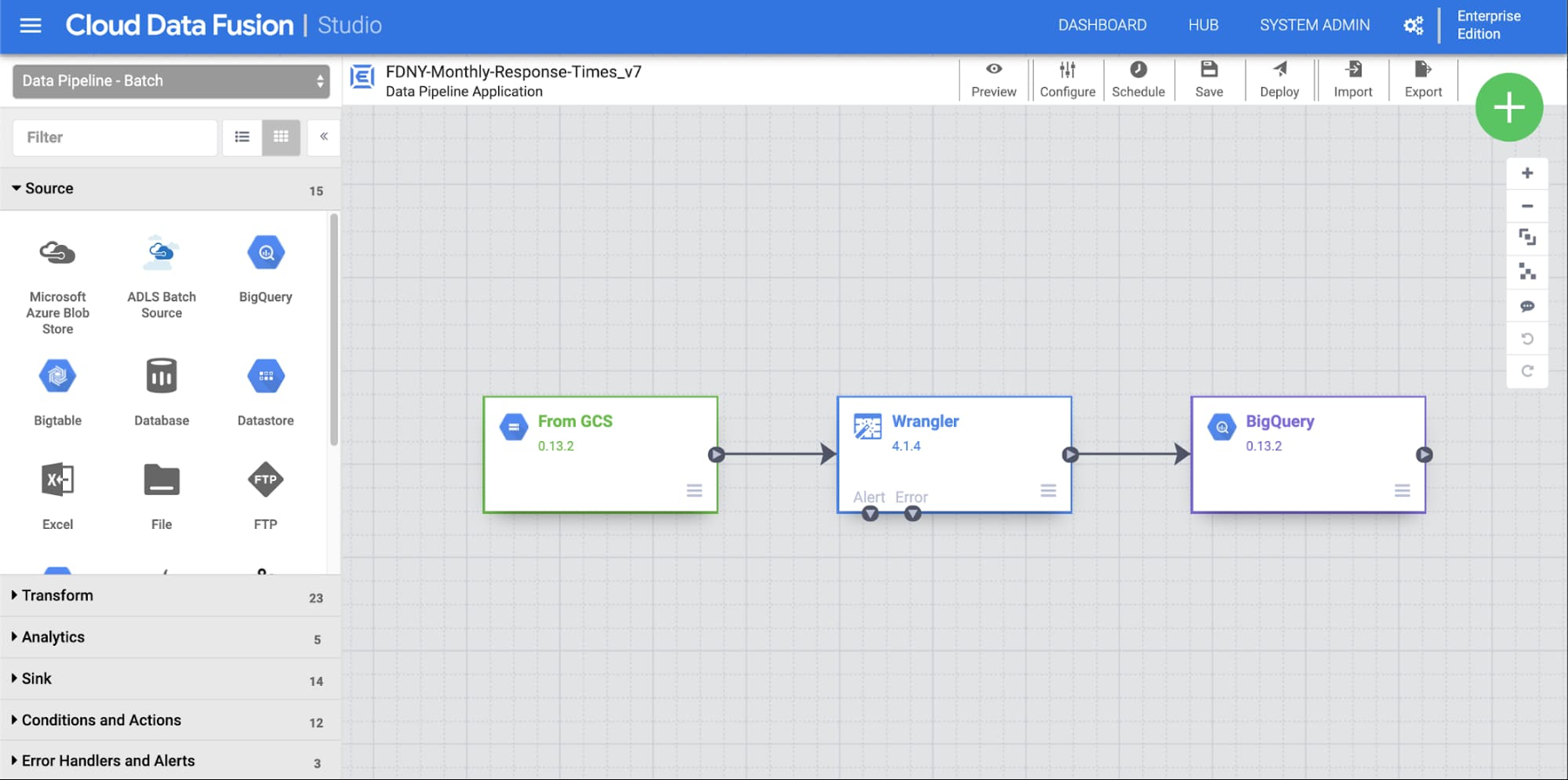
各ノード(プラグイン)をキャンバスにドラッグ&ドロップし、ノード同士を紐付けできます。まずは入力ノードから見てみましょう。[Source] プラグインのリストから、新しい [GCS] プラグインをキャンバスに追加し、プロパティを更新します。独自のラベルと参照名を自由に使い、パスが CSV ファイルの場所と一致していることを確認してください。
ラベル: From GCS
参照名: GCS1
パス: gs://<YOUR_BUCKET>/FDNY_Monthly_Response_Times.csv
データを変換する
次に、Wrangler プラグインを使用してデータを変換します。これは、一般的なデータ処理作業を行うための解析、変換、マッピングといったユーティリティ スイートを含む便利なコンポーネントです。
[Transform] プラグインのリストから [Wrangler] プラグインを追加し、その入力を [From GCS] の出力に紐付けます。ラベル名は自由につけることができます(「FDNY Response Time Wrangler」など)。
[Wrangle] をクリックして、Storage バケット内の CSV に移動します。次に、[body] の横にある矢印をクリックし、[Parse] -> [CSV] を選択して、次のオプションを設定します。
区切り文字として [comma] を使う
[Set first row as header] チェックボックスをオンにする
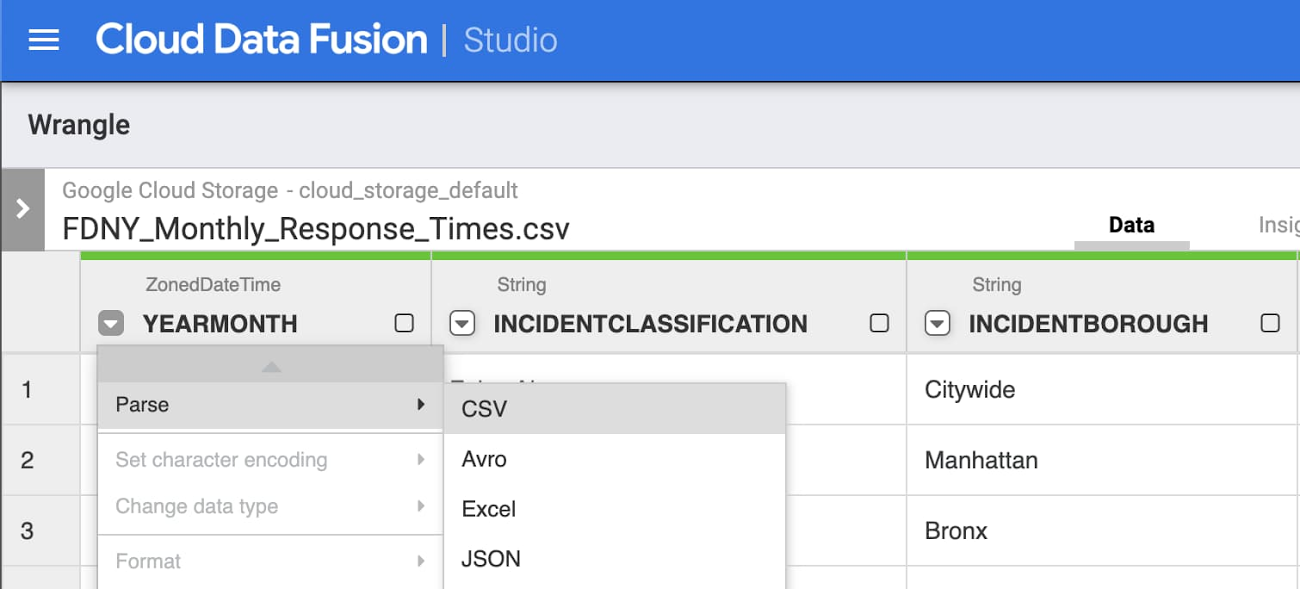
解析手順と同様の処理を行った後、次の追加手順に沿って変換を完了します。
[YEARMONTH] を単純な日付として解析する
カスタム形式 yyyy/MM を使用します
[INCIDENTCLASSIFICATION] 列のすべてのインシデントを除外する
[Filter] -> [Remove Rows] と選択し、値を [All Fire/Emergency Incidents] とし
ます[INCIDENTBOROUGH] 列の市全域を除外する
[Filter] -> [Remove Rows] と選択し、値を [Citywide] とします
各列の内容とインシデント件数を削除する
月の初めより前のインシデント件数は不明です
次の手順で平均対応時間からコロンを削除する:
「:」を検索して「」に置換します(かぎかっこなし)
平均対応時間を秒に変換する:
次のとおりカスタム変換します。(AVERAGERESPONSETIME / 100) * 60 + (AVERAGERESPONSETIME % 100)
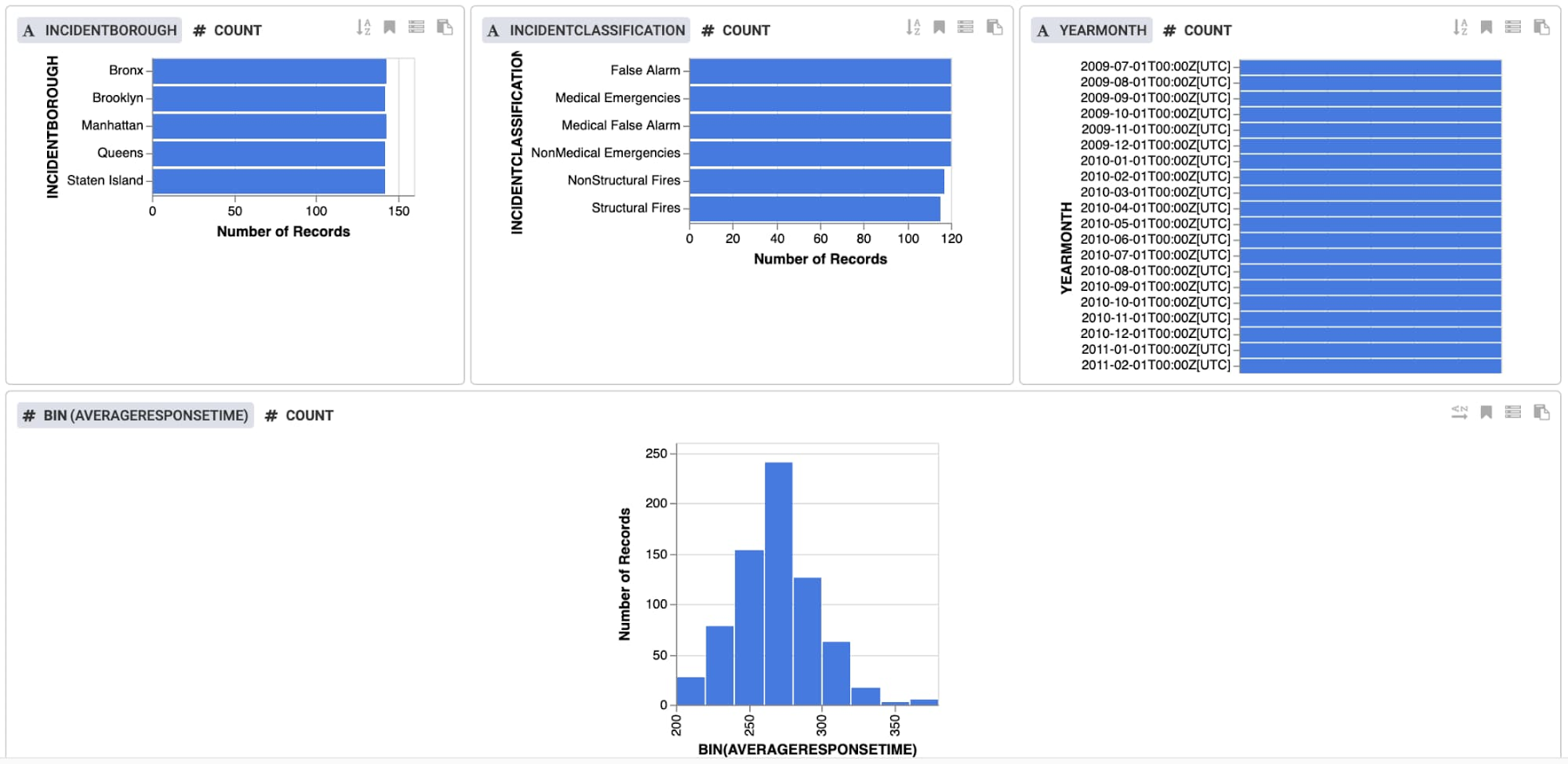
上部にある [Insights] をクリックして、データの詳細を確認します。ビューは列ごとに表示されますが、カスタムビューを作成することもできます。このデータは各特徴量の値のバランスが良好であることを示しており、約 270 秒を中心とした応答時間の正規分布が見られます。
[Apply] をクリックして変換を適用し、続けて [Validate] をクリックしてプラグインを検証します。[No Errors] と表示されます。
BigQuery にデータを保存する
パイプラインの最後の手順は、各レコードを BigQuery テーブルに書き込むことです。BigQuery プラグインで [Update Table Schema] オプションを設定して、各データの項目名とタイプが BigQuery に自動的に入力されるようにします。
[Sink] プラグインのリンクから、BigQuery をキャンバスに追加します。次に、[Properties] をクリックして、項目を次のように設定します。
ラベル: To BigQuery
参照名: BQ1
データセット: <YOUR_DATASET>
テーブル: <YOUR_NAME>
テーブル スキーマを更新: True
[Validate] をクリックして、プラグインが正しく構成されていることを確認します。
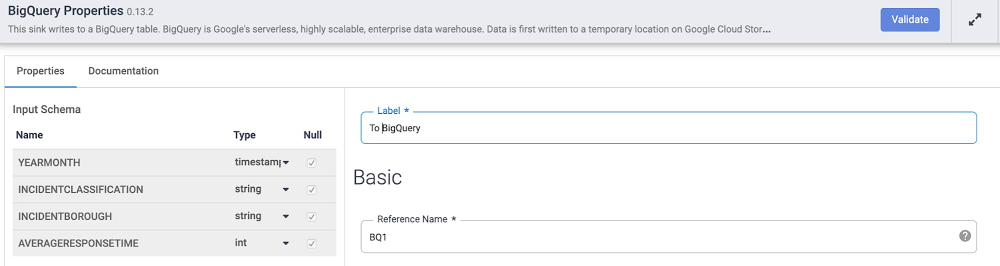
パイプラインをデプロイして実行する
データが変換され、BigQuery でパイプラインをデプロイする準備が整いました。上部のメニューバーで、パイプラインに fdny_monthly_response_time のような名前を付けて保存します。次に、パイプラインをデプロイします。これには 1 分ほどかかります。これで、パイプラインを実行する準備が整いました。この手順では、Dataproc クラスタをプロビジョニングして実行するのに数分かかります。
デフォルトでは、Cloud Data Fusion によってエフェメラル クラスタが作成され、パイプラインが実行されます。終了時に、クラスタが削除されます。既存のクラスタ上でパイプラインを実行することもできます。ジョブの進行に伴って、ステータス、期間、エラーなどの情報を確認できます。
BigQuery で変換されたデータを確認する
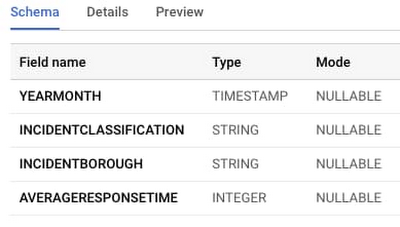
AutoML Tables にモデルを直接インポートする手順に進むこともできますが、ここで変換の出力を確認しておくことも重要です。BigQuery コンソールにアクセスして、作成したテーブルに移動します。[スキーマ] をクリックして、パイプラインによって何が作成されたかを確認します。
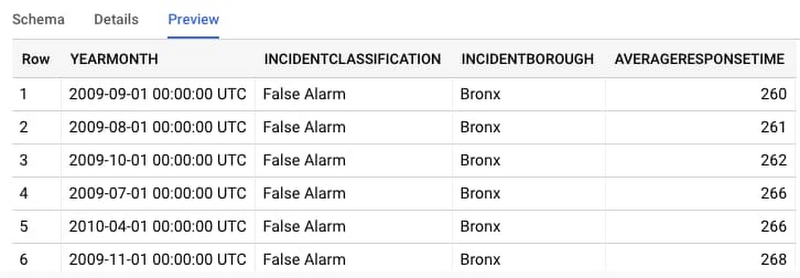
次に、[プレビュー] をクリックして、データセットのいくつかの行をサンプルとして確認します。
AutoML Tables を使用してモデルを構築する
データに問題がなければ、次はモデルを作成してみましょう。AutoML Tables にアクセスして、新しいデータセットを作成することから始めます。
そこから、データをモデルにインポートする必要があります。BigQuery から直接データをインポートするので簡単です。プロジェクト ID、データセット ID、テーブル名を指定して、データをインポートするだけです。
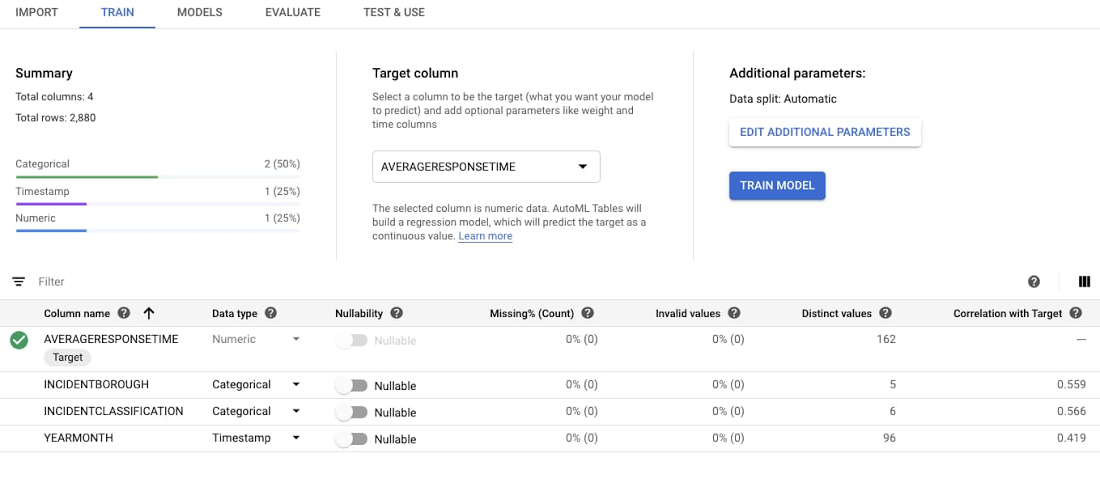
データをインポートしたら、トレーニングを開始できます。設定する必要があるオプションは、ターゲット列、つまり予測する変数 1 つだけです。回帰モデルの数値を予測します。
また、AutoML は分類モデルもサポートしています。AutoML Tables はデータ型を推測します。[80/10/10 Train/Test/Validate split] などの標準設定はそのままで問題ありません。ターゲット列 [AVERAGERESPONSETIME] を選択します。
ターゲット列を選択すると、AutoML Tables は各モデル特徴量に関する統計を再計算します。これで、[モデルをトレーニング] を選択できるようになります。
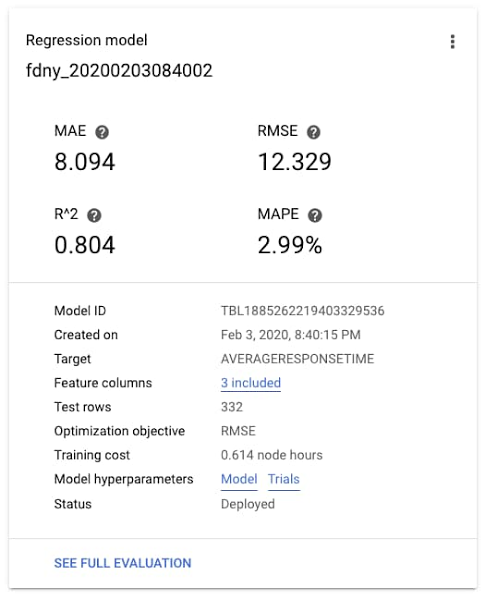
しばらくするとトレーニングが完了し、モデルの精度データを確認できます。この場合、MAE(平均絶対誤差)は約 8 日で、R^2、つまりモデルで明らかになる分散値(0~1 の範囲)は約 0.8 です。問題ないでしょう。
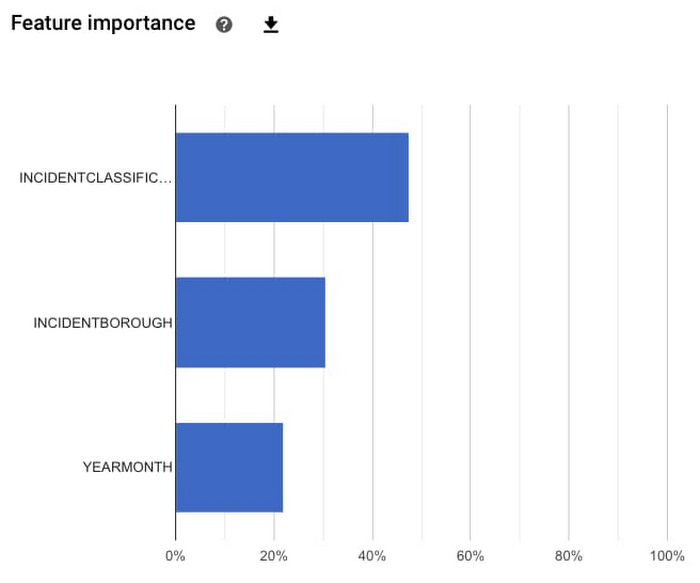
また、モデル内で最も予測力の高い特徴量はどれかを確認することもできます。この場合、最も重要な特徴量はインシデントの種類、次にインシデントが発生した行政区、そして最後にその年の時期だったことがわかります。ここで示した特徴量の重要度はテスト データセット全体から算出されているため、これにより一般的な影響の大きさを把握できます。特定の予測における特徴量の重要度については、別途ご説明します。
最後に、モデルを使って予測してみることができます。バッチ予測、オンライン予測、Docker コンテナとしてのモデルのエクスポートなど、いくつかのオプションが用意されています。
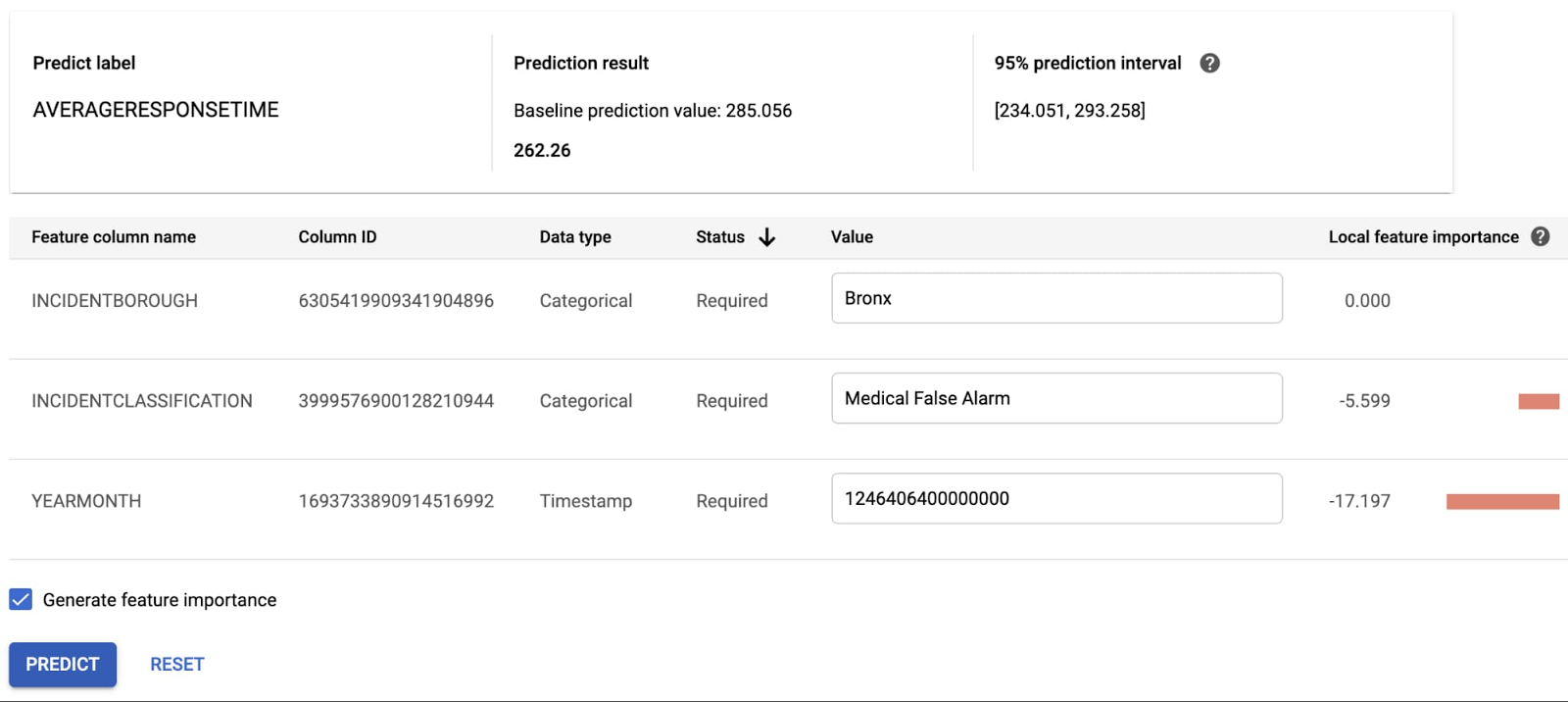
オンライン予測を試してみましょう。モデルをデプロイした後、REST API としてモデルにアクセスできます。AutoML Tables のユーザー インターフェースには、この API をテストするための便利な方法が提供されています。いくつかテスト値を入力してみましょう(YEARMONTH 項目は、マイクロ秒単位の Unix タイムスタンプであることにご注意ください。たとえば、下の表の「1246406400000000」は、2009 年 7 月 1 日の午前 0 時です)。予測結果は 262.26 秒です。また、[YEARMONTH] がこの特定の予測に最も大きな影響を与えたことがわかります。
まとめ
この記事では、コーディングしなくても堅牢なパイプラインと ML モデルを構築できることがわかりました。内部的には、各処理手順をスケーラブルなインフラストラクチャによって実現しています。パイプラインはクラウド ネイティブの Dataproc クラスタ上で実行され、スケーラブルな BigQuery データ ウェアハウスにレコードを挿入します。次に、AutoML Tables でニューラル アーキテクチャ検索を行い、モデルを構築します。
決してクリーンなデータセットから作業を始めたわけではありません。完全ではないデータをモデルで使用可能な形に変換できることで、機械学習のユースケースがさらに広がります。ユースケースを問わず、こうした便利なツールを活用して、新たな体験をお楽しみください。
- By デベロッパー アドボカシー マネージャー Karl Weinmeister



