エージェントと AI ネイティブな基盤で、企業データのあり方を根本から変える
Yasmeen Ahmad
Managing Director, Data Cloud, Google Cloud
※この投稿は米国時間 2025 年 8 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
世界は変わりつつあるだけでなく、データと AI によって今まさに再構築されています。私たちのデータとの関わり方も根本的な変革を遂げており、従来の人間主導の分析を超えて、インテリジェントなエージェントと協働する新たなパートナーシップへと進化しています。この「エージェンティック シフト」と呼ばれる新しい時代では、専門性を持つ AI エージェントが自律的かつ協調的に動作し、これまでは想像できなかった規模と速度で洞察を生み出します。Google Cloud は、この変革の一端を担う企業にとどまらず、それを支える核となるインテリジェンス、相互接続されたエコシステム、そして AI ネイティブなデータ プラットフォームを生み出しています。
エージェント主導の未来を実現するためには、従来のサイロ化されたツール群ではなく、単一で統合された AI ネイティブなクラウドという新しいデータ プラットフォームが必要です。それこそが Google Cloud の Data Cloud です。その中核にある統合された分析エンジンと運用エンジンは、ビジネス トランザクション データと戦略的分析の間に従来存在していた分断を解消しています。Google Cloud のData Cloud は、エージェントにビジネス全体の包括的かつリアルタイムな理解を提供し、複数のプロセスの集合体から自己認識、自律調整および高い信頼性を備えた組織へと変革します。
本日、このビジョンを実現するため、次の 3 つの主要分野において画期的なイノベーションを発表しました。
- 新しいデータ エージェント群: データ サイエンティストやエンジニアからビジネス アナリストまで、あらゆるデータユーザーの専門的なパートナーとして機能する特化型の新たな AI エージェント群です。
- エージェント協働のための相互接続ネットワーク: 開発者が Google Cloud のエージェントを自社のエージェントや AI プロジェクトと統合し、単一のインテリジェント エコシステムを構築できる API、ツール、プロトコル群です。
- 統一された AI ネイティブ基盤: データ統合、永続的なメモリの提供、AI 主導推論の組み込みにより、インテリジェント エージェントを可能にするプラットフォームです。
専門的パートナーとしての特化型データ エージェント
エージェント時代は、意図を行動へと変換するための AI ネイティブなインターフェースを提供する、専門的な AI エージェントという新しい労働力の登場とともに始まります。
- データ エンジニア向け: 複雑なデータ パイプラインの簡素化と自動化を実現する、データ エンジニアリング エージェント(プレビュー版)を BigQuery で提供開始します。Google Cloud Storage などのデータソースからの取り込み、変換やデータ品質の維持を含むワークフロー全体を、自然言語によるプロンプトで効率化できます。「CSV ファイルを読み込み、この列をクレンジングして別のテーブルと結合するパイプラインを作成してください」と指示するだけで、エージェントがワークフロー全体を生成し、制御します。さらに、モダナイゼーションを加速させるため、MySQL などのレガシー システムからの移行を劇的に簡素化する AI 搭載 Spanner 移行エージェント(プレビュー版)も新たにリリースします。

複雑なデータ パイプラインの自動化を実現する データ エンジニアリング エージェント
- データ サイエンティスト向け: BigQuery と Vertex AI で利用可能な AI ファーストな Google Colab 企業向けノートブック体験を再構築し、新たにデータ サイエンス エージェント(プレビュー版)を搭載します。Gemini を搭載した データ サイエンス エージェント は、探索的データ分析(EDA)、データ クレンジング、特徴量作成、機械学習による予測など、完全に自律的な分析ワークフローを実行します。計画立案、コード実行、結果検証、洞察提示のすべてを実行し、同時にユーザーのフィードバックを受けながら、協調した共同作業を可能にします。
データ サイエンス エージェント によるデータ サイエンス作業の各段階の変革
- ビジネスユーザーおよびアナリスト向け: 昨年、ユーザーが自然言語を使ってデータから答えを得られる、対話型分析エージェントを発表しました。本日、そのエージェントを次のレベルに引き上げる、コード インタープリタ(プレビュー版)を発表しました。この拡張により、単純な SQL では解決できない多くの重要なビジネス課題にも対応可能となります。例えば、「顧客を明確なコホートに分類する顧客セグメンテーション分析を実施して」といった課題に対応できます。Gemini の高度な推論能力を活用し、Google DeepMind と共同開発したコード インタープリタは、複雑な自然言語の質問を実行可能な Python コードに変換し、完全な分析フローを提供します。コード生成、わかりやすい自然言語での説明、インタラクティブな可視化の作成など、すべて Google Cloud のData Cloud の管理された安全な環境内で実現されます
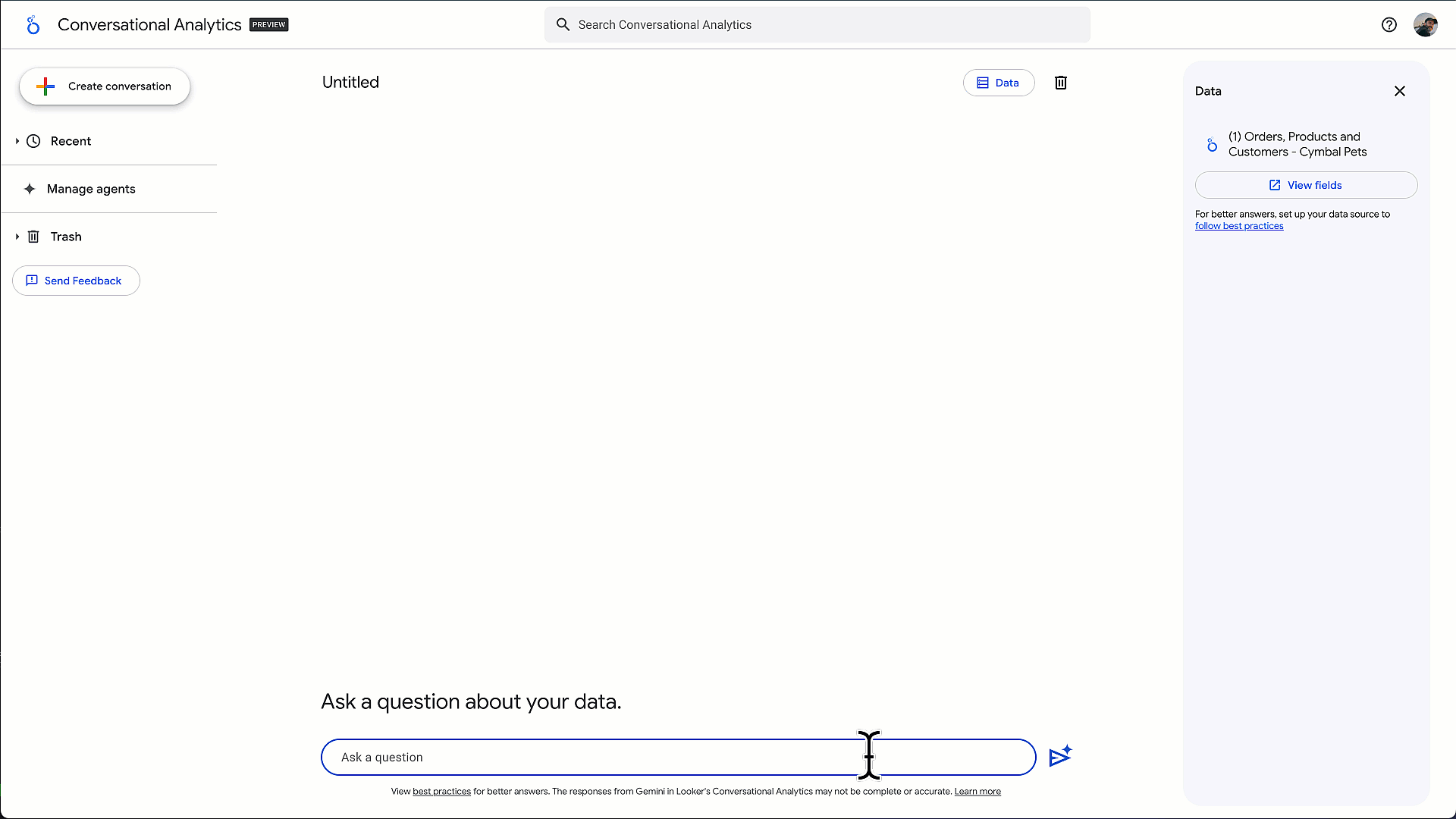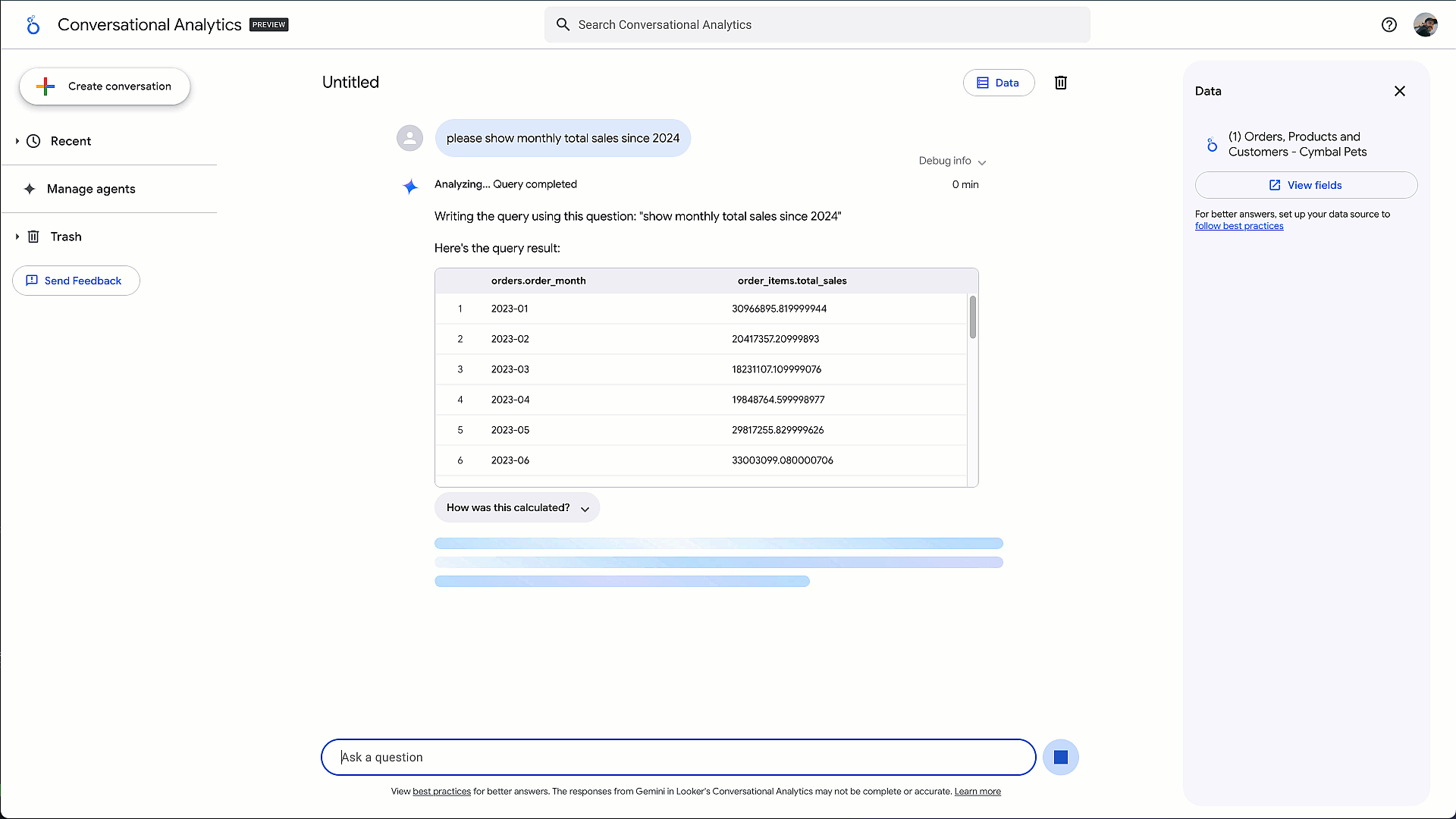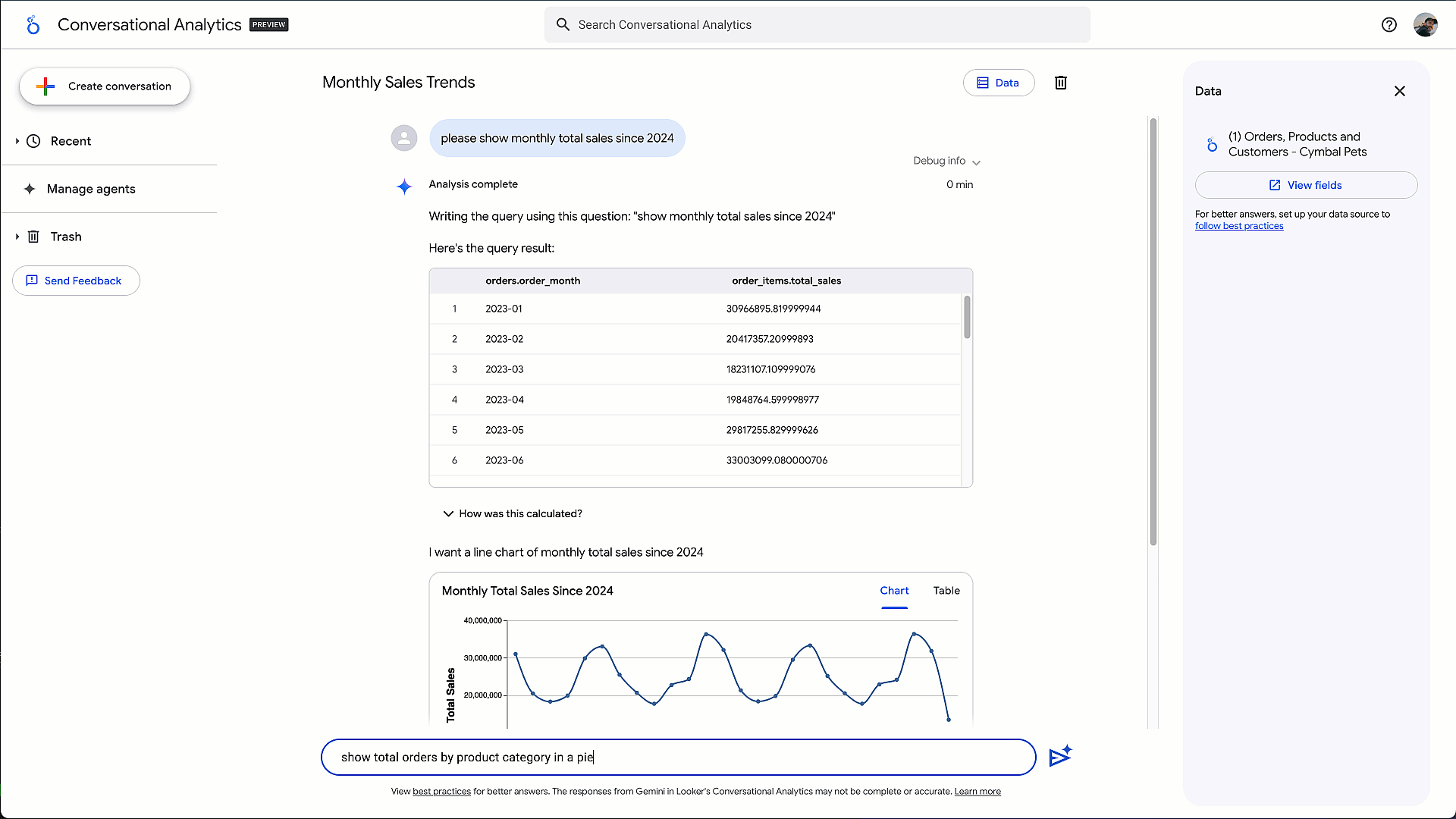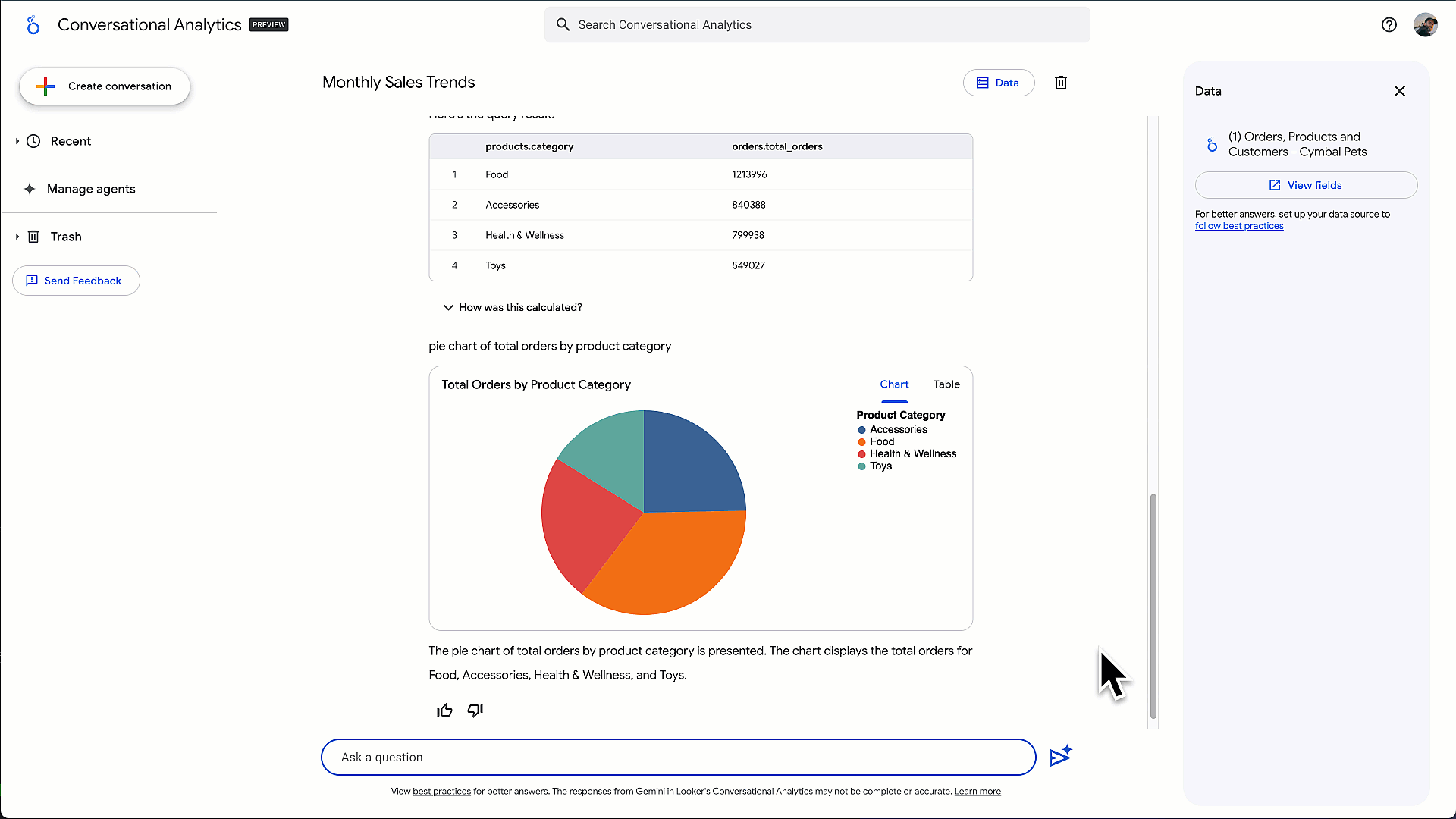
対話型分析エージェントと コード インタープリタで高度分析
相互接続エージェント エコシステムの構築
エージェンティック エコシステムは閉鎖的なシステムではなく、開発者のためのオープン プラットフォームです。エージェント シフトの真の可能性は、開発者が既存のエージェントを利用するだけでなく、自社のインテリジェント システムの拡張、連携によって、より広範なネットワークを形成するときに実現します。Google Cloud が提供するエージェントは、強力ですぐに使用できる機能と、カスタム エージェントの構築、会話型インテリジェンスの既存アプリケーションへの統合、独自のビジネス課題を解決する複雑なマルチエージェント ワークフローの調整を可能にするAPI、ツール、プロトコルといった基礎的な構成要素も提供します。
これを実現するため、Gemini Data Agents API をローンチし、第一弾として新しい対話型分析API(プレビュー版)を公開しました。この API は、Looker の強力な自然言語処理とコード インタープリタ機能を独自のアプリケーションや製品、ワークフローに直接統合するための構成要素を提供します。これにより、特定のビジネス ニーズに応じたユニークで魅力的、かつ使いやすいデータ体験を創出できます。
会話型体験にとどまらず、ゼロからカスタム エージェントを作成するためのツールも公開します。新しい Data Agents API と Agent Development Kit(ADK)により、独自のビジネス プロセスに特化したエージェントを構築できます。これらの安全な相互作用の基盤として、MCP Toolbox for Databases や新たに追加された Looker MCP Server(プレビュー版)を含む、Model Context Protocol(MCP)への投資を進めています。
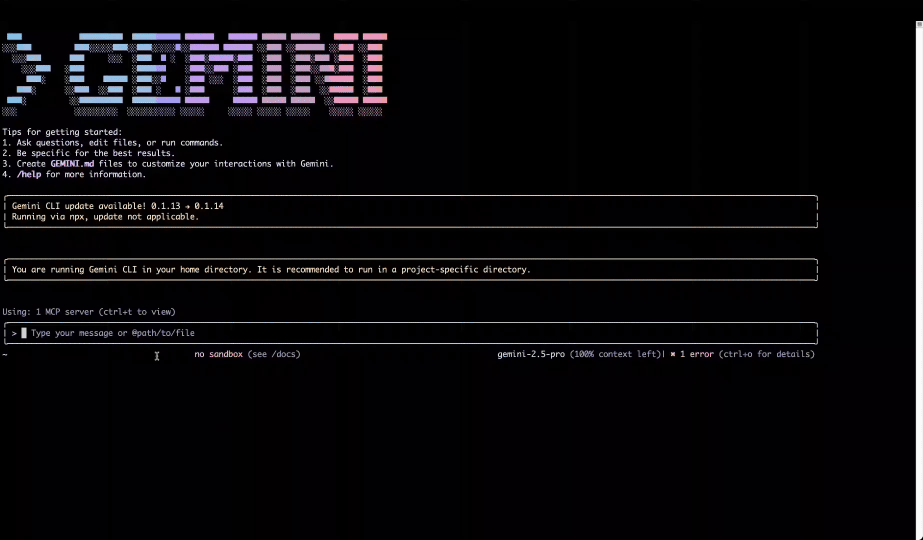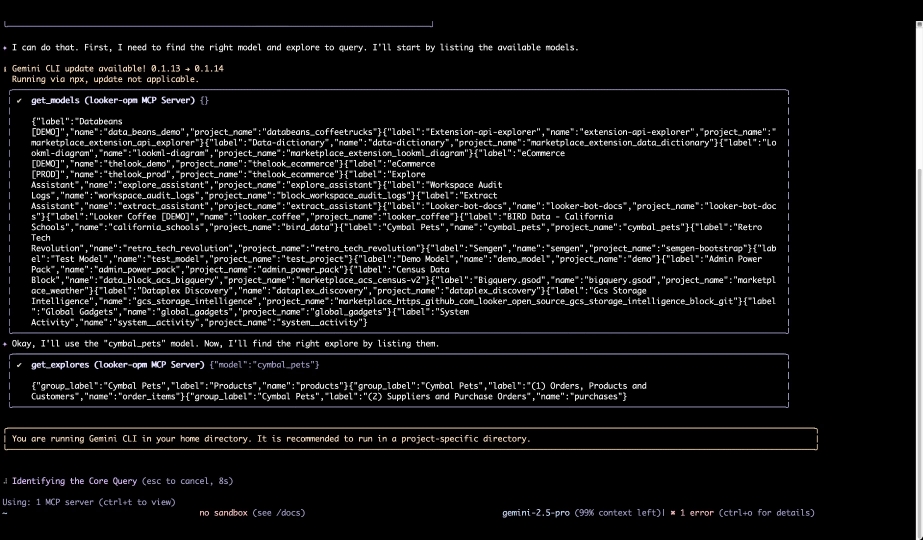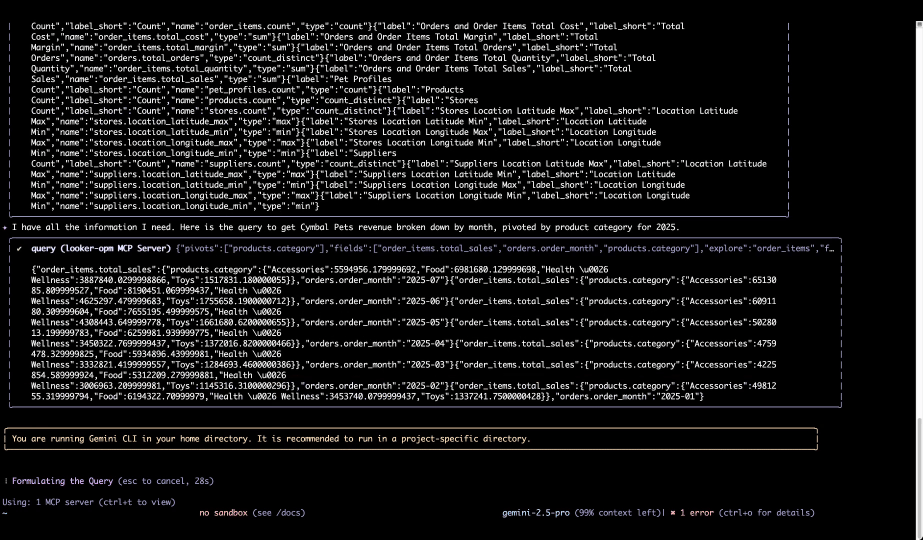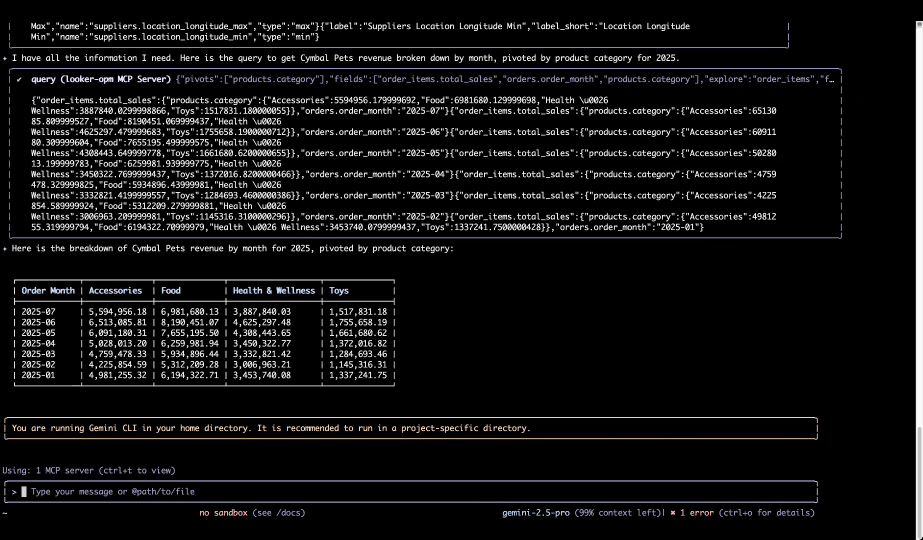
Gemini CLI が Looker MCP Server からセマンティック レイヤーをクエリを実行
統一された AI ネイティブ データ基盤
インテリジェントなエージェントとそれらが形成するネットワークは、従来のデータスタック上では機能しません。企業全体のデータ統合、その意味の理解、推論を行うための永続的なメモリを提供する認知的基盤が必要です。
AI ネイティブ基盤の中核要件は、OLTP(オンライン トランザクション処理)システムと OLAP(オンライン分析処理)システムに保存されたライブ トランザクション データと過去の分析データの統合です。PostgreSQL ワークロードの分析を加速する AlloyDB カラム型エンジンに続き、スケールアウト可能なフラグシップ データベースである Spanner にカラム型エンジン(プレビュー版)を新たに導入し、パフォーマンスへのコミットメントを拡大します。Spanner カラム型エンジン上での分析クエリは、SSD 上の Spanner の行ストアに比べて最大 200 倍高速に実行でき、さらにライブ トランザクション データに対して直接実現されています。統合 Data Cloud の一部として、分析エンジン BigQuery の Data Boost 機能にも直接恩恵をもたらし、Spanner カラム型エンジンを活用してトランザクションと分析ワークロードのギャップを埋め、BigQuery によるライブ運用データをより高速に分析できるようにします。
統一されたデータプレーンが整った後の次の要件は、企業の事実データに基づく包括的なメモリをエージェントに提供することです。信頼できるエージェントを実現し、ハルシネーションを防ぐためには、Retrieval-Augmented Generation(RAG)と呼ばれる技術を用いる必要があります。効果的な RAG の基礎は、リアルタイムの運用データと深い過去データの双方を横断するベクター検索です。ベクター検索と生成機能はデータ基盤に直接組み込まれており、エージェントはトランザクション メモリと分析メモリの両方にアクセスできます。
しかし、ベクター検索の最適化は複雑で、開発者はパフォーマンス、品質、運用負荷の間でトレードオフを迫られることが多くあります。AlloyDB AI では、新たな適応フィルタリング(プレビュー版)により、トランザクション メモリについてのこの問題を解決し、ベクター インデックスを自動的に管理してライブ運用データに対する高速クエリを最適化します。さらに、深い分析メモリを提供するために、BigQuery にも自律的なベクター埋め込みと生成機能も導入しています。これにより、BigQuery は自動的にマルチモーダル データのベクター検索用インデックスを作成でき、エージェント向けの豊かで長期的なセマンティックメモリ構築の重要な一歩となります。
最後に、この統一され、アクセス可能なデータの基盤として、AI 推論をクエリエンジンに直接組み込んでいます。新たな AI Query Engine in BigQuery(プレビュー版)により、すべてのデータ ユーザーは構造化および非構造化データに対して AI による演算を BigQuery 内で簡単かつ高速に実行でき、「顧客レビューの中で最も不満を感じているものはどれですか?」といった主観的な質問に対しても答えを得ることが可能になります。

AI Query Engine は、大規模言語モデル(LLM)の力を SQL で直接活用できるようにします
未来はエージェンティック
本日発表した内容は、あらゆるユーザー向けの特化型エージェントから、それらを支える AI ネイティブな基盤に至るまで、単なるロードマップではありません。これらは新しいエージェンティック企業を形作るための基盤です。インテリジェント エージェントという新たな労働力を結集し、オープンで相互接続されたネットワークの中で協調できるようにし、運用と分析の世界の境界をなくした統一データ クラウドに基盤を置くことで、単なる統合者ではなくイノベーターとなるためのプラットフォームを提供しています。これは組織がデータと関わる方法の根本的な変革であり、複雑な人間主導の分析から、チームとインテリジェント エージェントの強力なパートナーシップへと移行するものです。エージェンティック時代はすでに始まっています。皆様がどのようにデータの可能性を再定義し、何を創造するか、私たちは非常に楽しみにしています。
- Google Cloud, Managing Director Data Cloud, Yasmeen Ahmad
