トラブルのない機械学習モデル トレーニングのための 7 つのヒント
Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
Vertex AI はフルマネージドのトレーニング サービス、Vertex AI Training を提供しています。このサービスは一連の事前構築済みアルゴリズムを提供しており、カスタム トレーニングを使用して ML モデルを作成できます。
機械学習(ML)エンジニアは、ML モデル トレーニングの責任を担っています。ほとんどの場合、トレーニングは正常に完了しますが、失敗することもあります。失敗した場合、エンジニアはカスタマー サポートに連絡して、問題のトラブルシューティングを依頼します。しかし、ML エンジニアが自分で対応できる ML トレーニングのサポートケースも比較的多いことがわかりました。この投稿では、ML モデル トレーニングの失敗を引き起こす 7 つの一般的な原因を取り上げ、それらを回避する方法と修正する方法、そして時間を節約するためのヒントをご紹介します。
ヒント 1: アーキテクチャに適したソフトウェア パッケージを使用する
TensorFlow は、CPU、GPU、TPU の各アーキテクチャをサポートしています。CPU アーキテクチャは表形式データを使用したトレーニングに適していますが、GPU アーキテクチャはニューラル ネットワークに適しており、多くの場合コンピュータ ビジョンや自然言語処理で使用されます。TensorFlow GPU サポートには、畳み込み、プーリング、正規化、レイヤの有効化やその他の機能を実行する cuDNN などの特定のドライバやライブラリが必要です。特に、カスタム コンテナを使用するカスタム トレーニング ジョブを実行する場合は、アーキテクチャに適した TensorFlow パッケージを使用することが重要です。

リソース: GPU サポート - PIP パッケージ
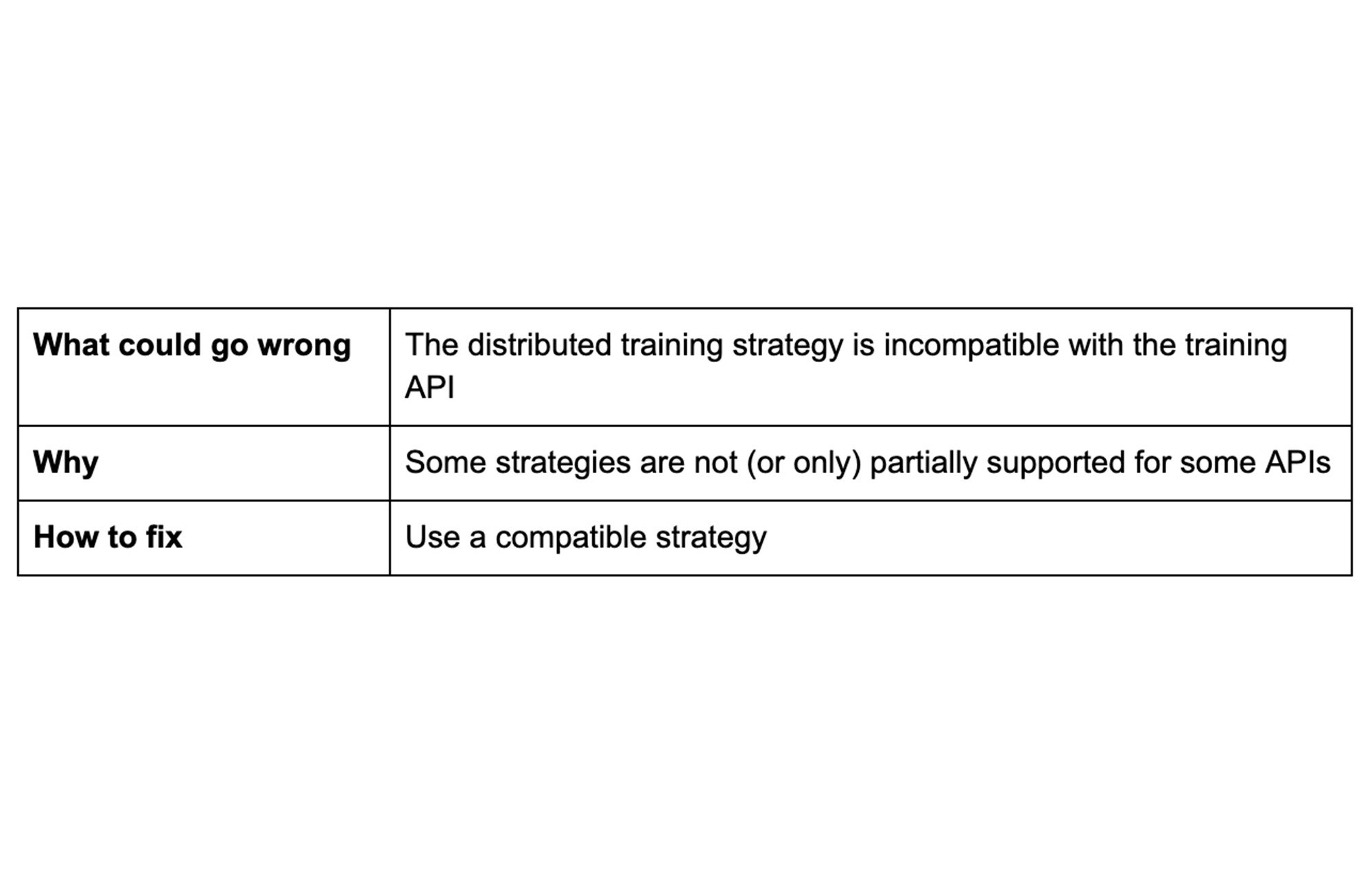
ヒント 2: トレーニング戦略を検討する
単一ユニットの CPU や GPU だけを使用する場合、大規模なデータセットで複雑なモデルをトレーニングするには膨大な時間がかかってしまいます。複数のユニットにトレーニングを分散させることで、トレーニング時間を短縮できます。TensorFlow の分散戦略を使用すると、コードを大幅に変更することなく、複数の GPU、複数のマシン、または TPU にデータを分散できます。選択する戦略は、ユースケース、データ、モデル、API の選択によって異なります。
MirroredStrategy は、1 台のマシン上の複数の GPU での同期分散トレーニングをサポートします。MultiWorkerMirroredStrategy は MirroredStrategy に似ていますが、それぞれが複数の GPU を搭載している可能性のある、複数のマシン間の分散をサポートしています。どちらの戦略でも、モデルのすべての変数のコピーを、すべてのマシンの各デバイス(すなわち、GPU)に作成します。
問題を回避するためには、トレーニング戦略がトレーニング API に適合するかどうかを確認してください。たとえば、上の 2 つの戦略は、Estimator API では部分的にしかサポートされていません。また、分散トレーニング戦略なしで、コードがローカルで正常に実行されることを確認してください。
リソース:
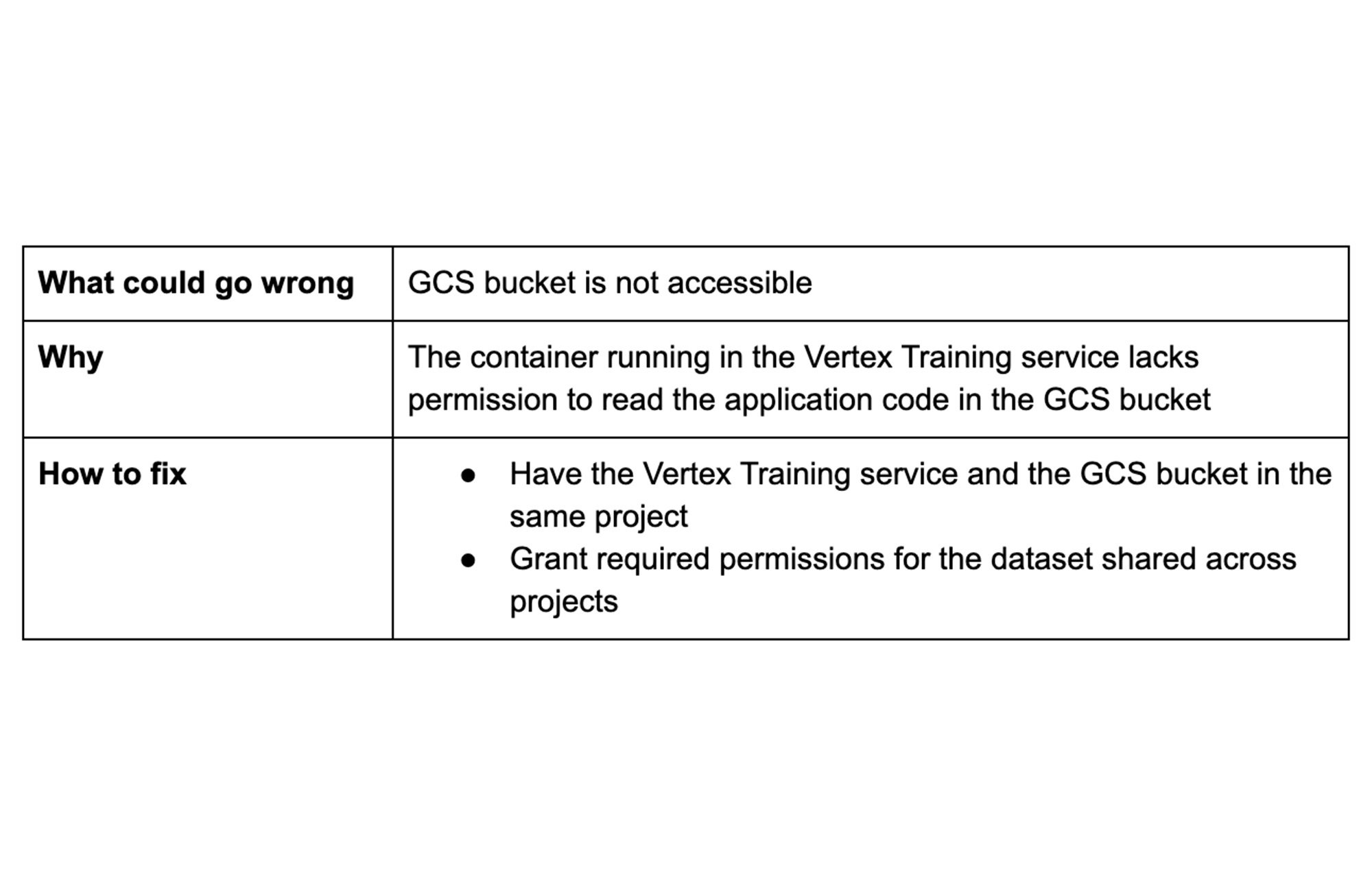
ヒント 3: 必要な権限のみを付与する
トレーニング中、Vertex AI は Vertex AI トレーニング プロジェクトにアクセス権を付与した Cloud Storage ロケーションからデータを読み取ります。次のような場合に Cloud Storage を使用することをおすすめいたします。
トレーニング アプリケーションとカスタム依存関係をステージングする
表形式のデータや画像データなどのトレーニング入力データを保存する
トレーニングの出力データを保存する
新しいバケットを作成することも、既存のバケットを使用することもできます。バケットが Vertex AI トレーニングを実行するために使用しているプロジェクトの一部である限り、Vertex AI のサービス アカウントにバケットのアクセス権を明示的に付与する必要はありません。
細かいアクセス制御を行うためにカスタム サービス アカウントを使用することを選択した場合は、必ずバケットのアクセス権限をアカウントに付与してください。
リソース: 別のプロジェクトの Cloud Storage バケットを使用する
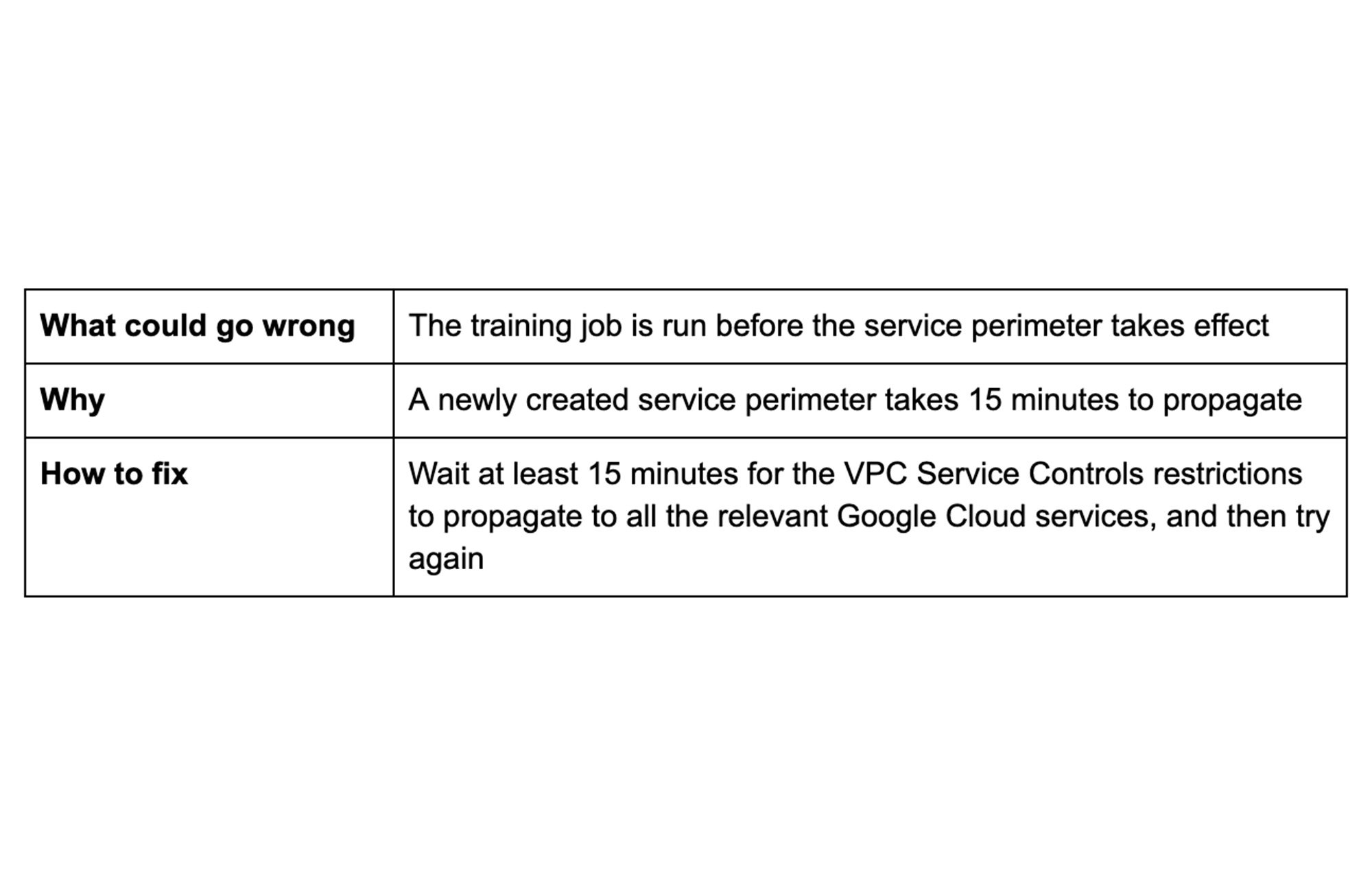
ヒント 4: セキュリティ設定の変更を確認する
VPC Service Controls を使用すると、Vertex AI トレーニング ジョブからのデータの引き出しリスクを軽減できます。サービス境界内のプロジェクトからトレーニング ジョブを実行すると、VPC Service Controls により、データが境界の中に留められます。このデータには、ジョブがアクセスするトレーニング データだけでなく、ジョブが作成するアーティファクトも含まれます。
サービス境界を作成し、Google Cloud プロジェクトを追加してから 15 分後には、追加の構成を行うことなくトレーニング ジョブを実行できます。トレーニング ジョブの実行が早すぎると VPC Service Controls のエラーがスローされ、即座に監査ログにレンダリングされる場合があります。
リソース: VPC Service Controls - 制限事項
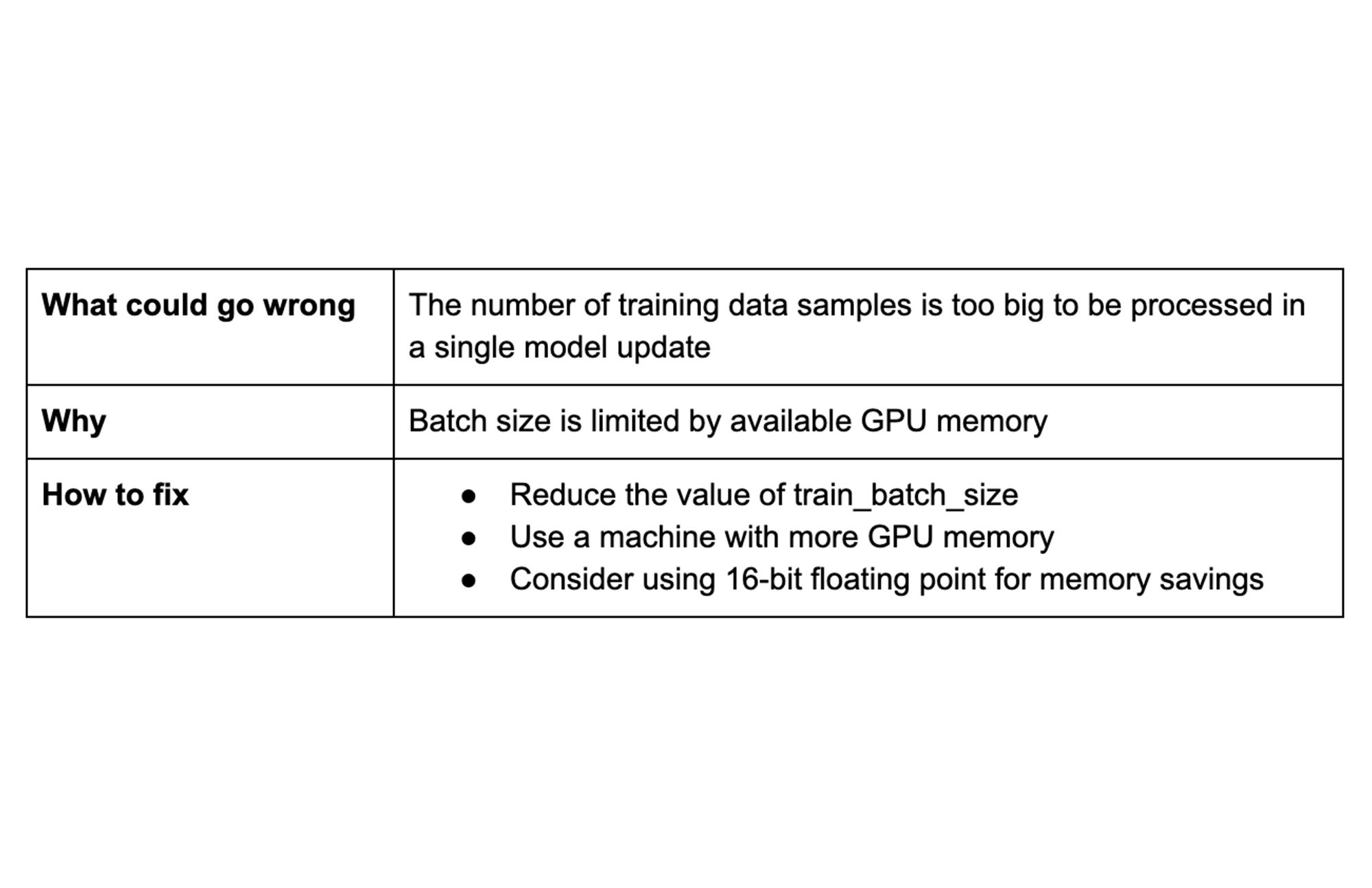
ヒント 5: バッチサイズの上限に注意する
バッチサイズはモデルのトレーニング可能なパラメータ(すなわち、重みとバイアス)の各更新をコンピューティングするために使用するデータサンプルの数を定義するハイパーパラメータです。バッチサイズは、トレーニング時間と結果のトレーニング モデルの精度に決定的な影響を与えます。
バッチが大きいほど、フォワードパスでモデルを通じて伝播されるサンプルが多くなります。バッチサイズを大きくするには、より多くの GPU メモリが必要になるため、GPU メモリが不足していると、バッチサイズを大きくすることができません。
リソース:
ハイパーパラメータの例における train_batch_size
ヒント 6: NAN エラーを回避する
勾配降下法は、機械学習で最もよく使われるアルゴリズムの一つです。このアルゴリズムを使用すると、モデルのトレーニングでモデル パラメータ(すなわち、ネットワークの重み)を更新するための誤差勾配が生成されます。計算のどこかに 1 つの NAN が含まれると、すぐにモデル全体に伝播される可能性があります。
大きな誤差勾配が蓄積されるとモデル トレーニングが不安定になり、その結果としてウェイト値が大きくなってオーバーフローし、NAN 値になってしまう場合があります。特定の損失関数を何も考えずに実装すると、驚くほど低い値でオーバーフローします。

解消策:
値を小さくした initial_learning_rate を使用するか、値を大きくした warmup_steps を使用することで、大きな初期の勾配の影響を軽減できます
損失関数が NAN を返していないことを確認します。組み込みの損失関数は堅牢性に優れており、カスタムの損失関数はそうでない場合があります
勾配の最大値を人為的に制限(クリップ)するために、勾配のクリップの使用を検討します
リソース:
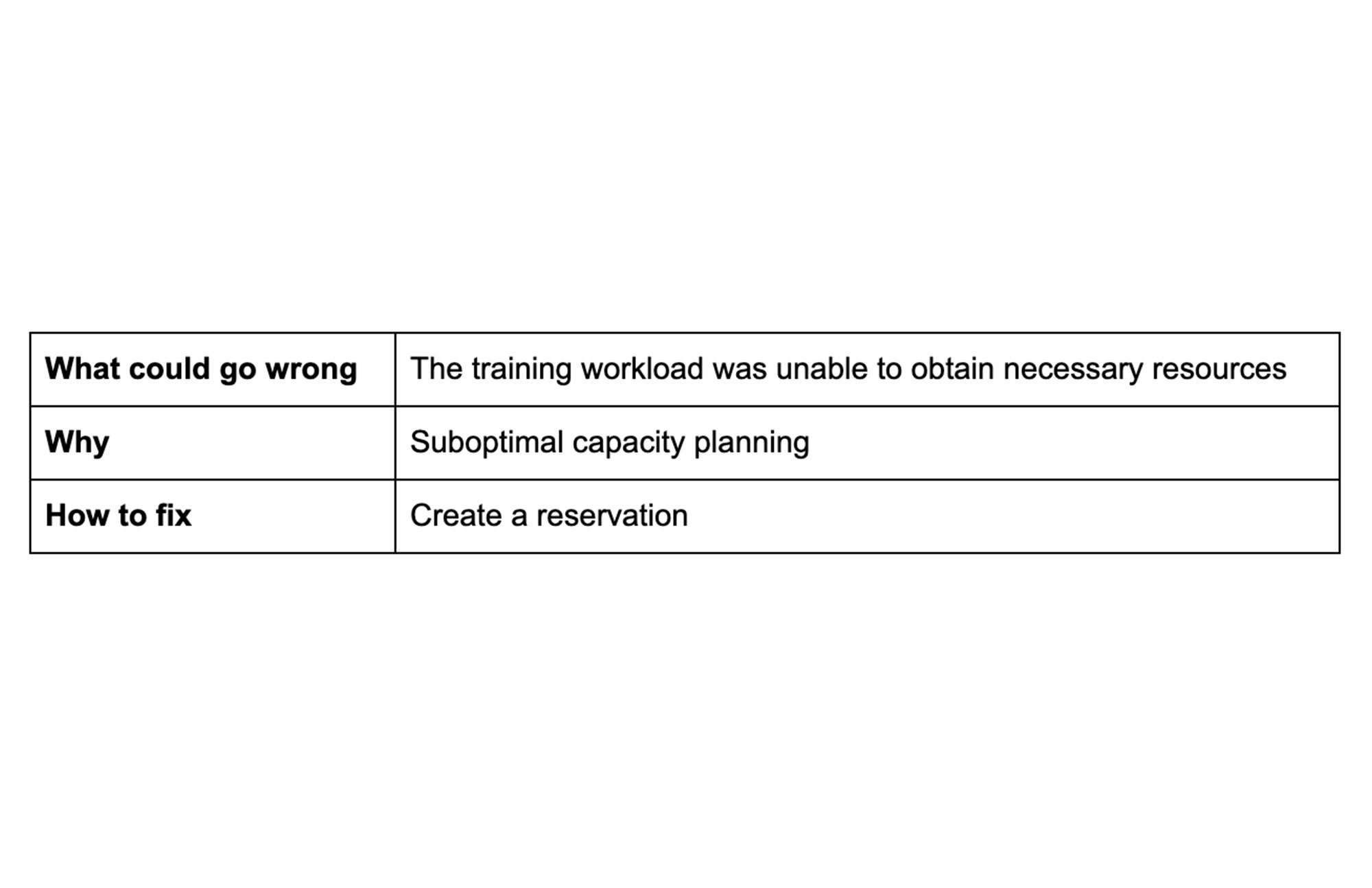
ヒント 7: キャパシティ プランニングを簡素化する
弾力性のあるワークロードはリソース再割り当ての対象となります。予約はそのような場合に役立ちます。予約は既存のリソースを保護し、ビジネスに不可欠なワークロードのためのキャパシティを確保する高度な保証を提供する、キャパシティ フルフィルメント提供サービスです。
予約は GCP プロジェクト レベルで割り当てることができます。しかし、プロジェクト レベルでキャパシティのニーズを予測し、各プロジェクトに必要な正確な予約数を予測することは困難な場合があります。
共有予約では、GCP 組織内の複数のプロジェクト間で Compute Engine の予約を共有でき、キャパシティ プランニングの予約を簡素化し、無駄な支出を削減できます。
リソース: Compute Engine ゾーンリソースの予約
結論
モデル トレーニングで問題が発生した場合は、ここで紹介したヒントやガイドラインを参考にして解決してください。さらに、ガイドラインを積極的に適用することで、問題を回避する機会を見つけてください。このリストをご覧になってもトレーニングに関する問題が解決しない場合は、既知の問題と機能のリクエストを確認するか、問題を報告してください。
謝辞
Karl Weinmeister、Nikita Namjoshi、Mark Daoust、Manoj Koushik、Urvashi Kohli のこのコンテンツに対する貴重なフィードバックに感謝します。
-テクニカル ソリューション エンジニア Michi Yamamoto



