7 tips for trouble-free ML model training
Michi Yamamoto
Technical Solutions Engineer
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialIntro
Vertex AI offers a fully managed training service, Vertex AI Training, which provides a set of prebuilt algorithms and enables you to create ML models using custom training.
Machine learning (ML) engineers are responsible for training ML models. In most situations, training completes successfully, but it does sometimes fail. When it does, engineers often reach out to customer support for help in troubleshooting the problem. It turns out, however, that there are a fair number of ML training support cases that the ML engineers could handle themselves. This post covers seven common causes of ML model training failures, along with time-saving tips on how to avoid them and how to fix them.
Tip 1: Use the right software package for your architecture
TensorFlow supports CPU, GPU, and TPU architectures. CPU architectures work great for training with tabular data, whereas GPU architectures are a better fit for neural networks, which are often used in computer vision and natural language processing. TensorFlow GPU support requires specific drivers and libraries, such as cuDNN, that perform convolution, pooling, normalization, layer activation and other functions. It’s important to use the right TensorFlow package for your architecture especially if you run a custom training job that uses a custom container.

Resources: GPU Support - Pip package
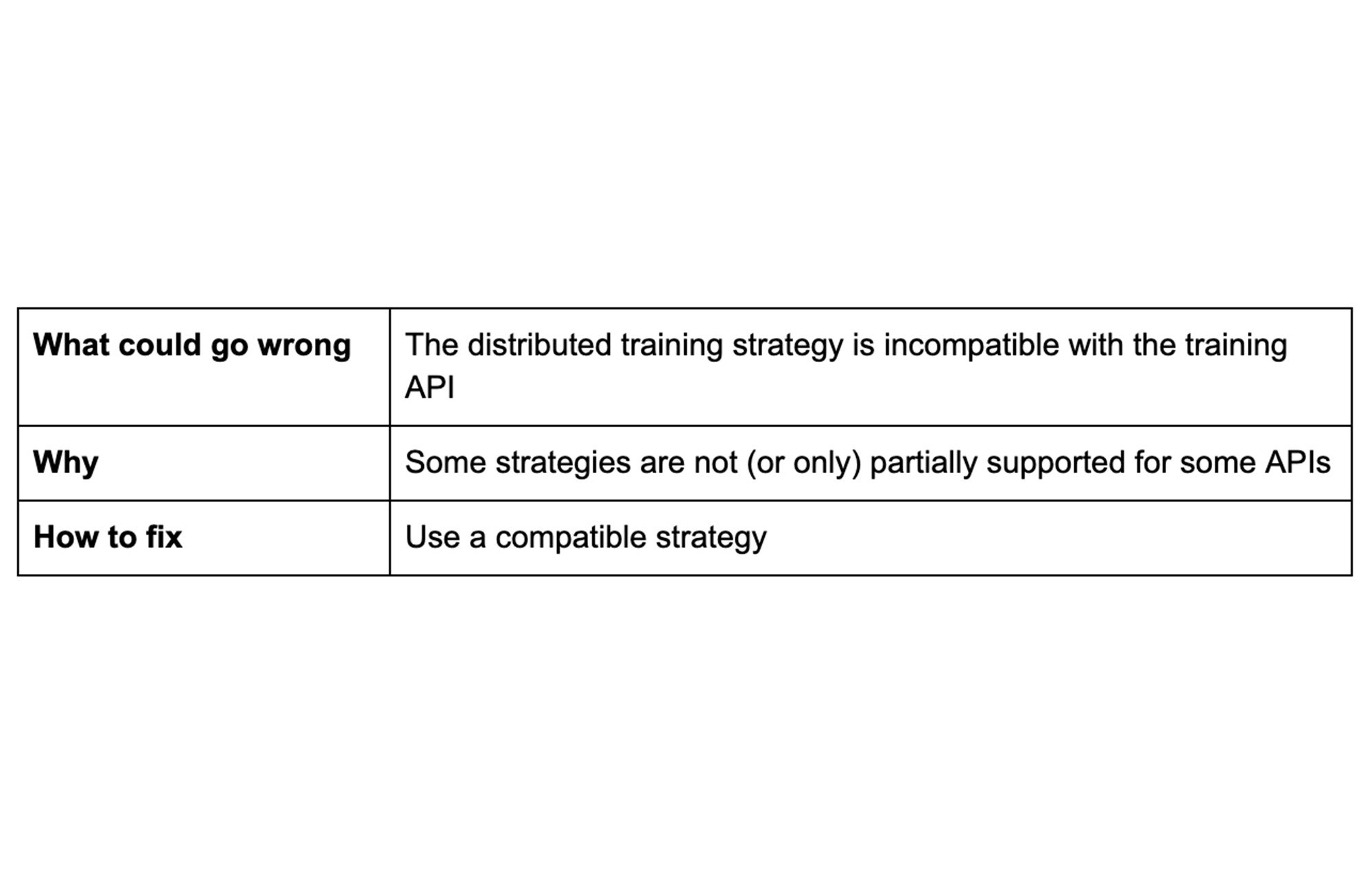
Tip 2: Examine training strategies
When using just a single unit of CPU or GPU, it can take a huge amount of time to train a complex model on a large dataset. You can reduce the training time by distributing training across multiple units. TensorFlow distribution strategies enable you to distribute your data across multiple GPUs, multiple machines, or TPUs without making significant code changes. The choice of strategy depends on your use-case, data, model, and API choice.
MirroredStrategy supports synchronous distributed training on multiple GPUs on one machine. MultiWorkerMirroredStrategy is similar to MirroredStrategy, except that it supports distribution across multiple machines, each with potentially multiple GPUs. Both strategies create copies of all variables in the model on each device (i.e. GPU) across all the machines.
To avoid issues, make sure your training strategy is compatible with your training API. For example the above two strategies are only partially supported with the Estimator API. Besides, make sure to verify your code runs locally successfully without a distributed training strategy.
Resources:
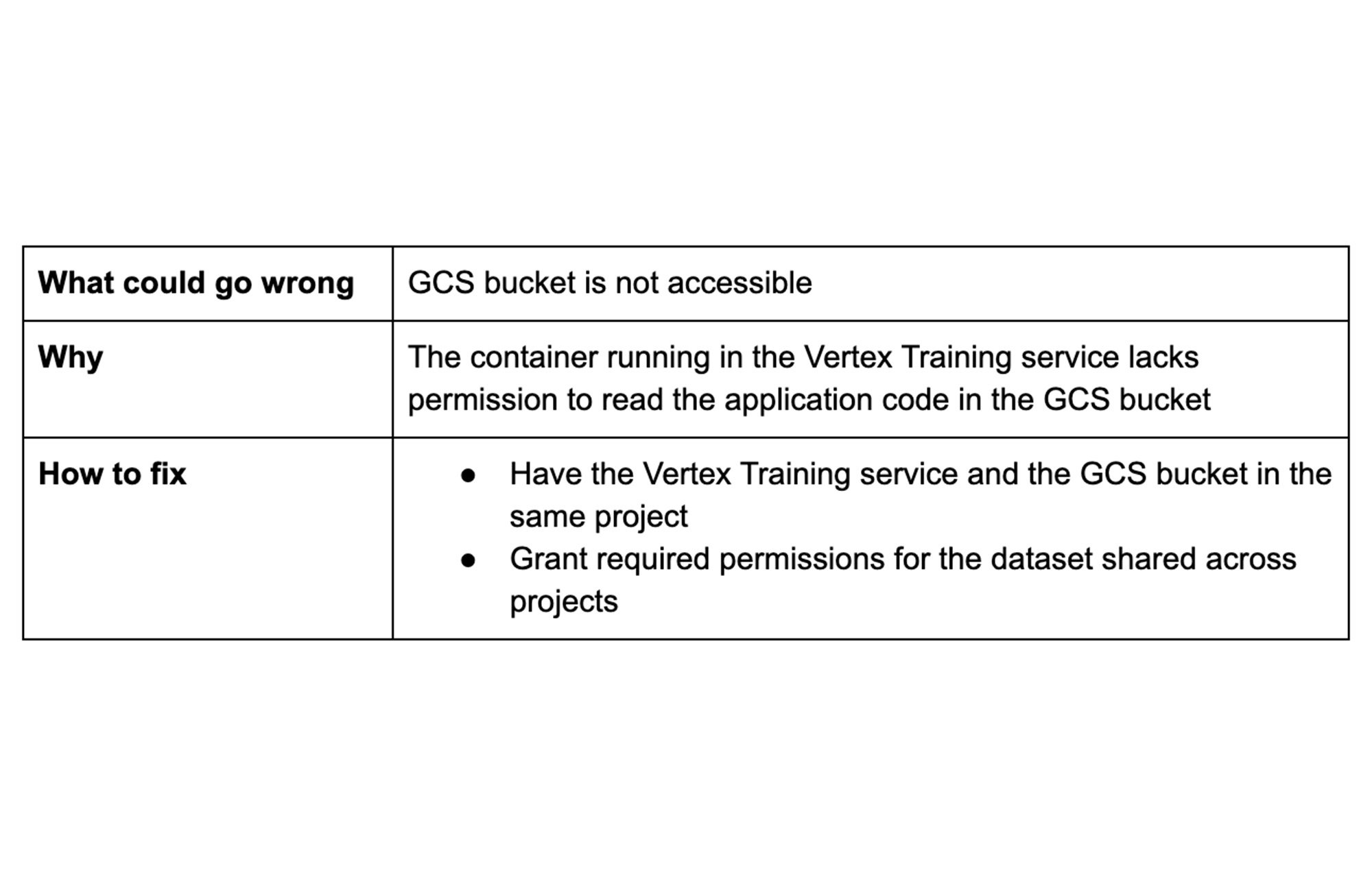
Tip 3: Grant necessary permissions
During training,Vertex AI reads data from Cloud Storage locations, where you have granted access to your Vertex AI training project. It’s a good idea to use Cloud Storage for:
Staging your training application and custom dependencies
Storing your training input data, such as tabular or image data
Storing your training output data
You can either create a new bucket or use an existing bucket. You don't need to explicitly grant bucket access to the Vertex AI service accounts as long as the bucket is part of the project you are using to run Vertex AI training.
If you choose to use a custom service account to achieve a fine-grained access control, then make sure to grant bucket access permissions to your account.
Resources: Using a Cloud Storage bucket from a different project
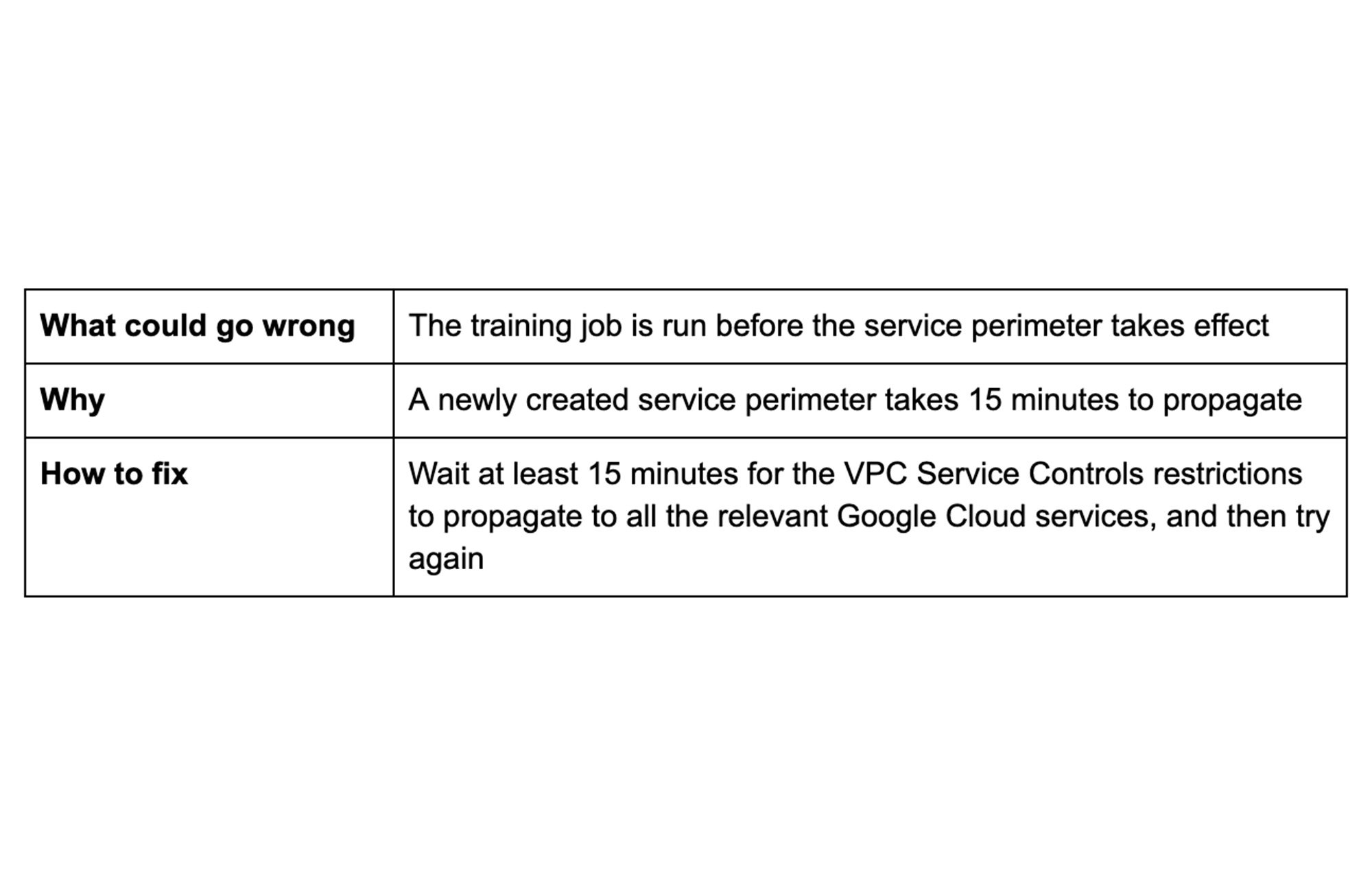
Tip 4: Check security setting changes
VPC Service Controls can help you mitigate the risk of data exfiltration from your Vertex AI training jobs. When you run a training job from a project inside a service perimeter, VPC Service Controls ensures that your data does not leave the perimeter. This includes training data that your job accesses and artifacts that your job creates.
Fifteen minutes after you have created a service perimeter and added your Google Cloud project to it, you can run training jobs without any additional configuration. If you run training jobs too soon, then VPC Service Controls errors can be thrown and immediately rendered in your audit logs.
Resources: VPC Service Controls - Limitations
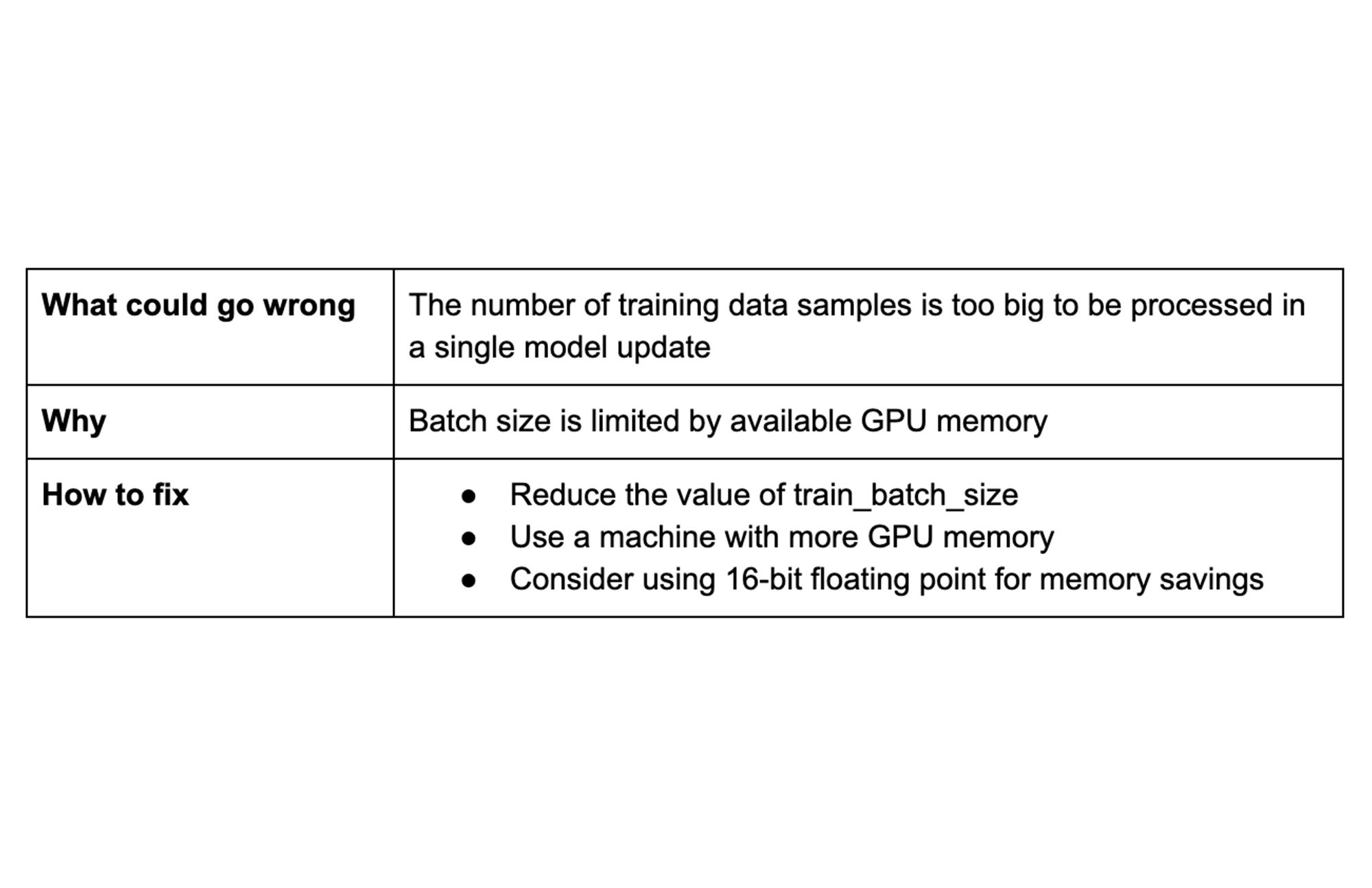
Tip 5: Beware of batch size limits
Batch size is a hyperparameter that defines the number of data samples used to compute each update to the model's trainable parameters (i.e. weights and biases). Batch size has a critical impact on training time and the resulting accuracy of the trained model.
The larger the batch, the more samples propagate through the model in the forward pass. Since a batch size increase will require more GPU memory, a lack of GPU memory can prevent you from increasing the batch size.
Resources:
- Overview of hyperparameter tuning
- train_batch_size in hyperparameter examples
- TensorFlow guide to mixed precision training
Tip 6: Avoid NaN errors
Gradient descent is one of the most used algorithms in machine learning. Using this algorithm, model training generates error gradients to update model parameters (i.e. network weights). A single NaN in any part of the computation can quickly propagate to the entire model.
The accumulation of large error gradients can cause model training to become unstable, which consequently makes weight values so high that they overflow and result in NaN values. A naive implementation of certain loss functions will overflow at surprisingly low values.

How to fix:
Use a smaller initial_learning_rate value or a larger warmup_steps value so you can reduce the impact of large initial gradients
Use an optimizer that is less sensitive to the gradient's magnitude (prefer Adam over SGD)
Verify that the loss function is not returning NaN. The builtin loss functions are robust, custom loss-functions may not be
Consider using gradient clipping to artificially limit (clip) the maximum value of gradients
Resources:
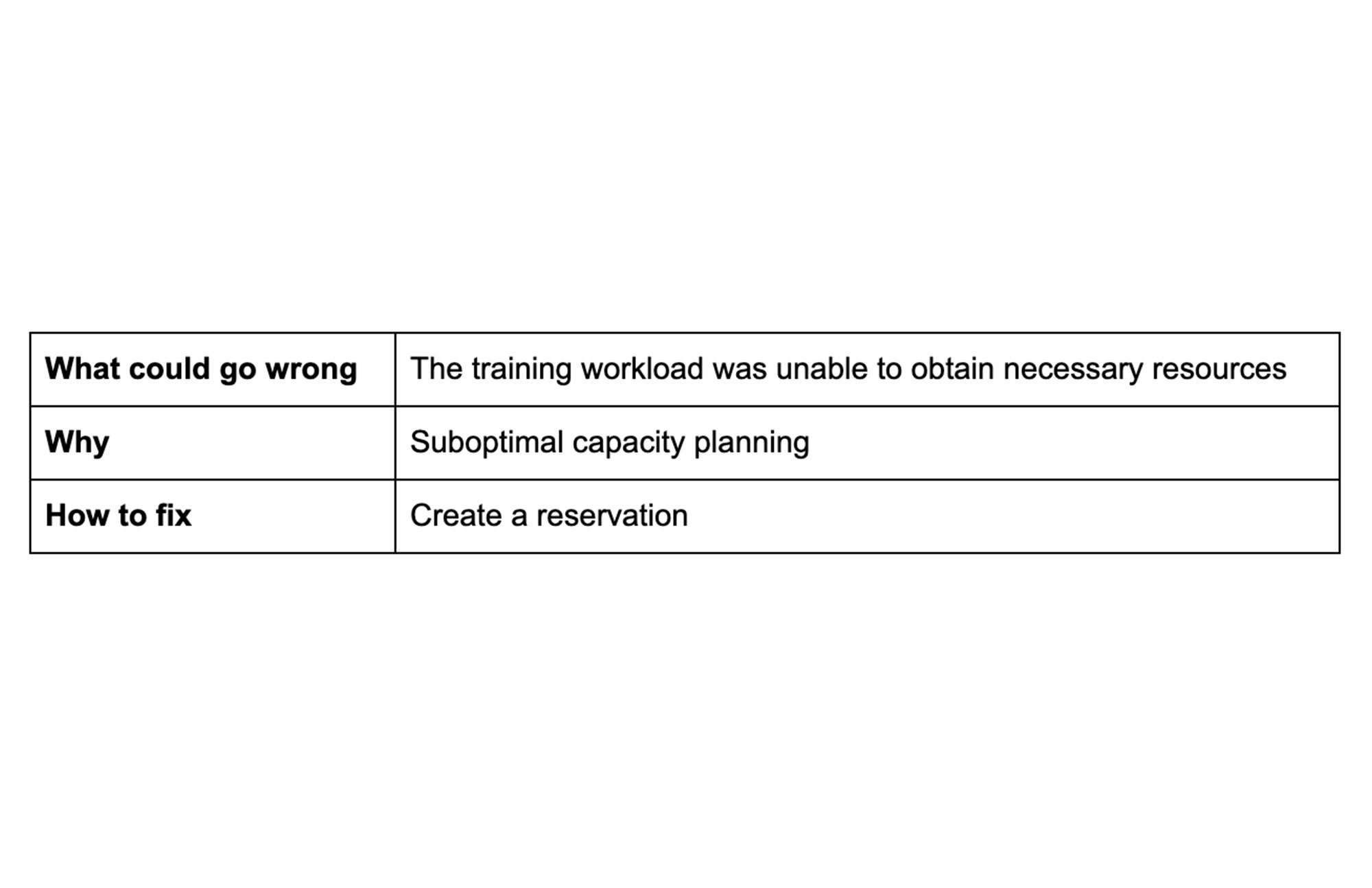
Tip 7: Simplify capacity planning
Elastic workloads are subject to resource reallocation. Reservations can help here. A reservation is a capacity fulfillment offering, which protects existing resources and provides you with high assurance in obtaining capacity for your business-critical workloads.
You can allocate a reservation at the GCP project level. However, it can be challenging for you to forecast your capacity needs at a project level and predict the exact number of reservations required for each project.
With shared reservations, you can share your Compute Engine reservations across multiple projects in your GCP organization, simplifying capacity planning reservations and reducing wasted spend.
Resources: Reservations for Compute Engine zonal resources
Conclusion
If you run into an issue with model training, use the tips and guidelines covered here to help resolve it. Better yet, look for opportunities to avoid issues by applying the guidelines proactively. If you’ve run through this list and still haven’t resolved your training problem, be sure to check out the known issues and feature requests or report your issue.
Acknowledgements
Special thanks to Karl Weinmeister, Nikita Namjoshi, Mark Daoust, Manoj Koushik, and Urvashi Kohli for valuable feedback on this content.



