Improving model performance with PyTorch/XLA 2.6
Kyle Meggs
Sr. Product Manager, AI Infrastructure
Yifei Teng
Software Engineer
For developers who want to use the PyTorch deep learning framework with Cloud TPUs, the PyTorch/XLA Python package is key, offering developers a way to run their PyTorch models on Cloud TPUs with only a few minor code changes. It does so by leveraging OpenXLA, developed by Google, which gives developers the ability to define their model once and run it on many different types of machine learning accelerators (i.e., GPUs, TPUs, etc.).
The latest release of PyTorch/XLA comes with several improvements that improve its performance for developers:
-
A new experimental
scanoperator to speed up compilation for repetitive blocks of code (i.e., for loops) -
Host offloading to move TPU tensors to the host CPU’s memory to fit larger models on fewer TPUs
-
Improved goodput for tracing-bound models through a new base Docker image compiled with the C++ 2011 Standard application binary interface (C++ 11 ABI) flags
In addition to these improvements we’ve also re-organized the documentation to make it easier to find what you’re looking for!
Let’s take a look at each of these features in greater depth.
Experimental scan operator
Have you ever experienced long compilation times, for example when working with large language models and PyTorch/XLA — especially when dealing with models with numerous decoder layers? During graph tracing, where we traverse the graph of all the operations being performed by the model, these iterative loops are completely “unrolled” — i.e., each loop iteration is copied and pasted for every cycle — resulting in large computation graphs. These larger graphs lead directly to longer compilation times. But now there's a new solution: the new experimental scan function, inspired by jax.lax.scan.
The scan operator works by changing how loops are handled during compilation. Instead of compiling each iteration of the loop independently, which creates redundant blocks, scan compiles only the first iteration. The resulting compiled high-level operation (HLO) is then reused for all subsequent iterations. This means that there is less HLO or intermediate code that is being generated for each subsequent loop. Compared to a for loop, scan compiles in a fraction of the time since it only compiles the first loop iteration. This improves the developer iteration time when working on models with many homogeneous layers, such as LLMs.
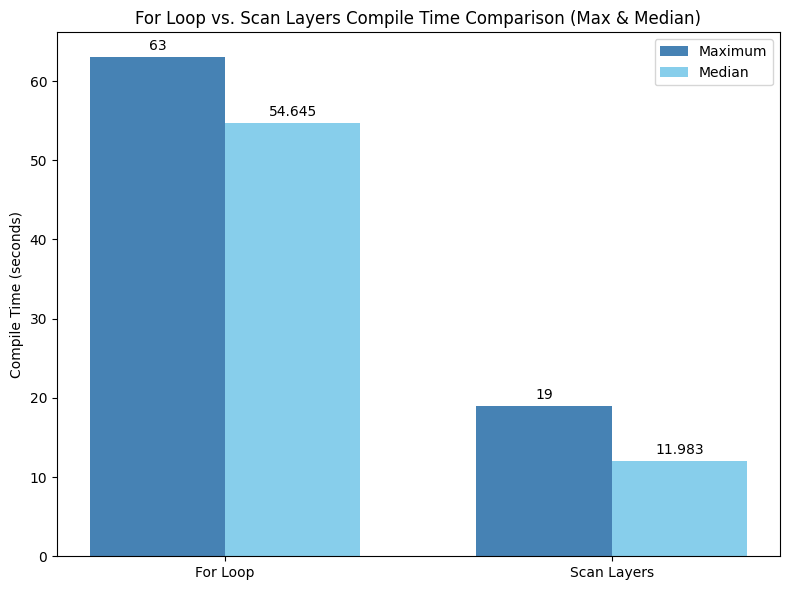
Building on top of torch_xla.experimental.scan, the torch_xla.experimental.scan_layers function offers a simplified interface for looping over sequences of nn.Modules. Think of it as a way to tell PyTorch/XLA "These modules are all the same, just compile them once and reuse them!" For example:
One thing to note is that custom pallas kernels do not yet support scan. Here is a complete example of using scan_layers in an LLM for reference.
Host offloading
Another powerful tool for memory optimization in PyTorch/XLA is host offloading. This technique allows you to temporarily move tensors from the TPU to the host CPU's memory, freeing up valuable device memory during training. This is especially helpful for large models where memory pressure is a concern. You can use torch_xla.experimental.stablehlo_custom_call.place_to_host to offload a tensor and torch_xla.experimental.stablehlo_custom_call.place_to_device to retrieve it later. A typical use case involves offloading intermediate activations during the forward pass and then bringing them back during the backward pass. Here’s an example of host offloading for reference.
Strategic use of host offloading, such as when you’re working with limited memory and are unable to use the accelerator continuously, may significantly improve your ability to train large and complex models within the memory constraints of your hardware.
Alternative base Docker image
Have you ever encountered a situation where your TPUs are sitting idle while your host CPU is heavily loaded tracing your model execution graph for just-in-time compilation? This suggests your model is "tracing bound," meaning performance is limited by the speed of tracing operations.
The C++11 ABI image offers a solution. Starting with this release, PyTorch/XLA offers a choice of C++ ABI flavors for both Python wheels and Docker images. This gives you a choice for which version of C++ you’d like to use with PyTorch/XLA. You'll now find builds with both the pre-C++11 ABI, which remains the default to match PyTorch upstream, and the more modern C++11 ABI.
Switching to the C++11 ABI wheels or Docker images can lead to noticeable improvements in the above-mentioned scenarios. For example, we observed a 20% relative improvement in goodput with the Mixtral 8x7B model on v5p-256 Cloud TPU (with a global batch size of 1024) when we switched from the pre-C++11 ABI to the C++11 ABI! ML Goodput gives us an understanding of how efficiently a given model utilizes the hardware. So if we have a higher goodput measurement for the same model on the same hardware, that indicates better performance of the model.
An example of using a C++11 ABI docker image in your Dockerfile might look something like:
Alternatively, if you are not using Docker images, because you’re testing locally for instance, you can install the C++11 ABI wheels for version 2.6 using the following command (Python 3.10 example):
The above command works for Python 3.10. We have instructions for other versions within our documentation.
The flexibility to choose between C++ ABIs lets you choose the optimal build for your specific workload and hardware, ultimately leading to better performance and efficiency in your PyTorch/XLA projects!
So, what are you waiting for, go try out the latest version of PyTorch/XLA! For additional information check out the latest release notes.
A note on GPU support
We aren't offering a PyTorch/XLA:GPU wheel in the PyTorch/XLA 2.6 release. We understand this is important and plan to reinstate GPU support by the 2.7 release. PyTorch/XLA remains an open-source project and we welcome contributions from the community to help maintain and improve the project. To contribute, please start with the contributors guide.
The latest stable version where a PyTorch/XLA:GPU wheel is available is torch_xla 2.5.


