Caso de éxito: Cómo Safari Books Online usa BigQuery para la inteligencia empresarial.
Nota del editor: Este artículo fue escrito por el autor invitado, Daniel Peter. Daniel es analista programador sénior en Safari Books Online, un servicio de suscripción a bibliotecas en línea fundado por O’Reilly Media y Pearson Education. Safari Books Online usa BigQuery para resolver algunos desafíos clave: compila paneles de control empresariales detallados a fin de detectar tendencias y administra el abuso, mejorar la efectividad del equipo de ventas a través de la inteligencia de ventas, y habilitar consultas ad-hoc para responder a preguntas comerciales específicas. Eligieron BigQuery sobre otras tecnologías debido a la velocidad de las consultas en las que se usa un lenguaje familiar, similar al de SQL, y por el escaso mantenimiento requerido.
Safari Books Online tiene una base de clientes grande y diversa, quienes buscan y acceden constantemente a nuestra creciente biblioteca de más de 30,000 libros y videos desde una variedad de computadoras de escritorio y dispositivos móviles. Este flujo de actividad contiene un conocimiento importante que podemos usar para mejorar nuestro servicio y aumentar la rentabilidad. En las grandes cantidades de datos de uso se encuentran tendencias como los usuarios principales, los títulos principales y la conexión de los puntos para las consultas de ventas.
Nuestros datos de uso eran muy masivos (en el rango de miles de millones de registros) para realizar consultas en línea en su totalidad con nuestro conjunto de herramientas anterior. El análisis se podía realizar con herramientas de estadísticas web de terceros, como Omniture, pero esas herramientas carecían de la capacidad de consultar y explorar datos de nivel de registro en tiempo real. Además, no tenían un gran backend para desarrollar visualizaciones en contra. La consulta similar a SQL tenía que hacerse en partes más pequeñas de los datos, requería mucho trabajo y era lenta. Estábamos impacientes esperando a que terminaran las consultas de MySQL y, a menudo, teníamos dudas sobre si terminarían o no. En cuanto alcanzas un tiempo de espera de 10 minutos para el cliente de la base de datos, estarás en una situación en la que no podrás hacer análisis ad-hoc. Responder preguntas operativas (como rastrear el abuso) puede ser urgente, por lo que la velocidad es importante. Trabajamos con Hadoop, pero nos costó mucho trabajo mantenerlo, así que terminamos poniéndolo en segundo plano para futuros proyectos.
Luego nos enteramos de Google BigQuery en un video de Google E/S y determinamos que parecía perfecto para nuestro caso práctico, por lo que decidimos probarlo. Sigue leyendo para ver cómo pudimos crear rápidamente conocimientos útiles a partir de datos que, de otra manera, serían difíciles de usar con BigQuery.
Cómo obtener nuestros datos en BigQuery
Independientemente de la plataforma de base de datos que uses, el paso de extracción, transformación y carga (ETL) puede ser un desafío según tus fuentes de datos. BigQuery no es una excepción. Google tiene un excelente artículo sobre Cargar datos en BigQuery para ayudar a que esto sea más fácil.
Este diagrama muestra una descripción general de cómo los datos fluyeron a través de los servidores de destino y ETL hasta llegar a BigQuery.
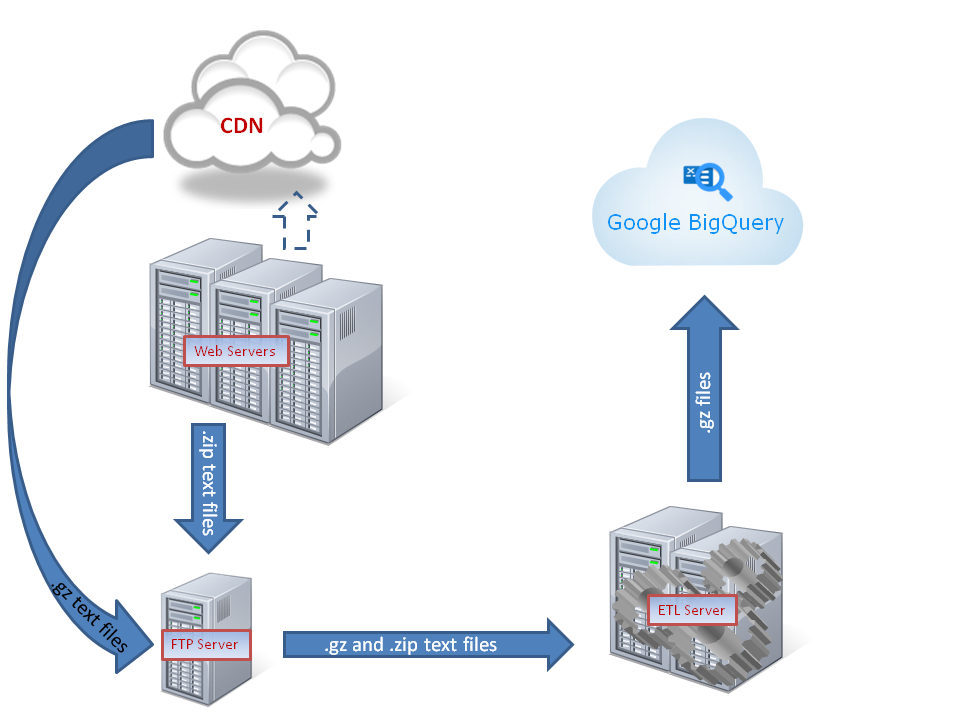
Nuestros datos de uso provienen de nuestra red de entrega de contenido (CDN) y de nuestros registros del servidor de aplicaciones web. Estos datos se empaquetaron en fragmentos por lotes basados en el tiempo y se copiaron automáticamente en un 'directorio de destino'. Se necesitaba cierta transformación para su carga en BigQuery en un formato que nos permitiera sacar el máximo provecho.
A continuación, se describen los pasos básicos por los que pasamos:
Obtén una lista de todos los archivos fuente que cargamos previamente en BigQuery
Esto fue tan simple como realizar una llamada a la herramienta de línea de comandos de BigQuery con el parámetro format=json desde una secuencia de comandos de PHP:
bq --format=json query SELECT sourcefile FROM PageViews GROUP BY sourcefile
Eso nos dio el resultado de JSON siguiente:
[{"sourcefile":"PageViews.201207122232.gz"},
{"sourcefile":"PageViews.201207111006.gz"},
{"sourcefile":"PageViews.201207121024.gz"}]
Lo que podría implementarse fácilmente en un arreglo con la función json_decode de PHP.
Valida nuestra lista de archivos fuente que esperan cargarse en BigQuery
Obtuvimos una lista de todos los archivos de nuestro directorio de destino, así como su suma de comprobación con el comando md5sum de Linux. Esperamos un poco y, luego, volvimos a obtener la lista de archivos con las sumas md5. Todos los archivos cuya suma de md5 cambió eran archivos que se estaban subiendo actualmente, así que los quitamos de nuestra lista a fin de darles más tiempo para subirse.
También quitamos cualquier archivo de la lista que ya estuviera cargado en BigQuery.
Luego, verificamos la integridad de nuestros archivos con el comando gunzip -t de Linux.
Transforma los archivos
Procesamos alrededor de 40 archivos de texto comprimidos con aproximadamente 60 MB cada uno durante 24 horas. Hacer ETL en este volumen de datos necesita un servidor aceptable. Usamos una máquina Linux con 256 GB de RAM y 32 núcleos, pero podrías lograrlo con menos. Cuanto más grande sea el servidor, mejor, especialmente durante el proceso de desarrollo cuando estás iterando una y otra vez. Para la producción, y solo con el procesamiento los datos incrementales, podrías disminuir los recursos. Lo principal es que el tiempo de procesamiento de 1 hora de datos de uso tarde menos de 1 hora en procesarse o nunca obtendrás los datos de BigQuery actualizados.
El proceso comienza con la descompresión de los archivos y el análisis de la línea de texto por línea.
Una línea de ejemplo podría verse así:
50.0.113.6 - - [21/May/2012:06:12:51 +0000] "GET /techbus.safaribooksonline.com/9780596805395/how_python_runs_programs?reader=html HTTP/1.1" 504 417 "-" "Apple-PubSub/65.28" "-"
Queríamos excluir campos vacíos o irrelevantes, cambiar el formato de otros campos y dividir campos de valores múltiples para terminar con una tabla como esta:
| host | fecha y hora | método de http | dominio | ruta | recurso | cadena de consulta | estado | bytes | usuario-agente | archivo fuente |
|---|---|---|---|---|---|---|---|---|---|---|
| 50.0.113.6 | 2012/05/21 06:12:51 | GET | techbus.safaribooksonline.com | /9780596805395/ | how_python_runs_programs | lector=html | 504 | 417 | Apple-PubSub/65.28 | PageViews.201207122232.gz |
| STRING | STRING | STRING | STRING | STRING | STRING | STRING | NÚMERO ENTERO | NÚMERO ENTERO | STRING | STRING |
Esta función de PHP funcionó bien para analizar la entrada de la línea de registro web en un arreglo:
str_getcsv($line, " ", '"', '\\');
Hicimos un procesamiento especial en varios campos:
- Optamos por almacenar la fecha y la hora como una string en lugar de como un número entero de marca de tiempo (Nota del editor: Desde entonces, BigQuery implementó la compatibilidad con el tipo MARCA DE TIEMPO). Usamos PHP para obtener las partes de la fecha y les cambiamos el formato de la manera siguiente:
Y/m/d H:i:s, que se puede clasificar como texto. - Desglosamos la solicitud HTTP en el dominio, la ruta de acceso, el recurso y la string de consulta con el comando
explodede PHP y alguna otra lógica. - Agregamos el nombre del archivo fuente para poder rastrear un registro hasta su archivo fuente original y evitar que insertáramos cualquier archivo fuente más de una vez.
Escribimos cada línea transformada en un archivo nuevo, con la omisión de caracteres especiales y la delimitación de campos mediante un carácter de barra vertical |.
Luego comprimimos el archivo transformado con el comando gzip -f -v de Linux.
Copia los archivos a Google Cloud Storage
La copia de los archivos en Google Cloud Storage es muy sencilla gracias a la utilidad de línea de comandos de gsutil. Literalmente, es tan fácil como copiar archivos en tu máquina local. Una vez instalada, solo tuvimos que iterar en nuestros archivos transformados y ejecutar el comando gsutil cp para realizar la copia en Google:
foreach ($arrFiles as $file) {
echo 'Sending file to Google Cloud Storage: '.$file;
echo shell_exec('gsutil cp '.$file.' gs://data_warehouse/');
echo ' (COMPLETE).';
echo "\n";
}
Carga los archivos en BigQuery
Creamos el archivo de esquema siguiente:
[
{"type":"STRING","name":"host","mode":"NULLABLE"},
{"type":"STRING","name":"datetime","mode":"NULLABLE"},
{"type":"STRING","name":"httpMethod","mode":"NULLABLE"},
{"type":"STRING","name":"domain","mode":"NULLABLE"},
{"type":"STRING","name":"path","mode":"NULLABLE"},
{"type":"STRING","name":"resource","mode":"NULLABLE"},
{"type":"STRING","name":"querystring","mode":"NULLABLE"},
{"type":"INTEGER","name":"status","mode":"NULLABLE"},
{"type":"INTEGER","name":"bytes","mode":"NULLABLE"},
{"type":"STRING","name":"useragent","mode":"NULLABLE"},
{"type":"STRING","name":"sourcefile","mode":"NULLABLE"}
]
y lo guardamos como schema.txt.
Cargar nuestros archivos de Google Cloud Storage en BigQuery es muy fácil. Con la herramienta de línea de comandos de bq instalada, simplemente ejecutamos este comando:
bq load --field_delimiter='|' --max_bad_records=99999999 dataset.tableName gs://data_warehouse/file1.gz, gs://data_warehouse/file2.gz, gs://file3.gz schema.txt
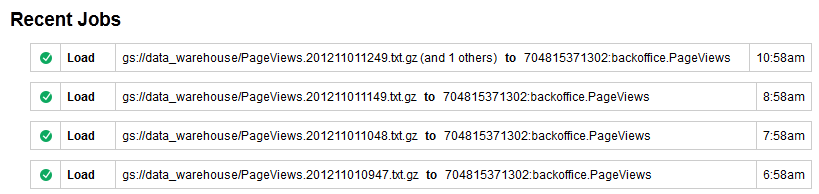
Un gran lote de archivos comprimidos grandes se transfiere sorprendentemente rápido. Gzipping y el procesamiento por lotes son el camino a seguir para nosotros, aunque Google recomienda descomprimir los archivos de origen y así obtener las velocidades de transferencia más altas posibles debido a las operaciones de carga en paralelo. De cualquier manera, podemos supervisar el estado de estos trabajos de carga a través del "Historial de trabajos" de la herramienta de navegación de BigQuery:
Usa los datos una vez que estén en BigQuery
BigQuery demostró ser una buena plataforma para los datos del panel y ofrece la posibilidad de profundizar en los datos en los paneles con la IU basada en el navegador de BigQuery para el análisis ad hoc.
A continuación, se muestra un panel que usa nuestro equipo de operaciones internamente para supervisar a los principales usuarios:

Si surge una pregunta, puedes obtener más información acerca de un usuario, un título o una dirección IP mediante una consulta con la herramienta de navegación de BigQuery.
A continuación, se muestra un panel que usamos internamente para vigilar los títulos principales de las tendencias:

Nuevamente, si surge alguna pregunta en este panel, BigQuery puede responderlas por ti.
Los datos se envían a estos paneles mediante un trabajo programado intermediario que se ejecuta a través de cron. Esta secuencia de comandos consulta a BigQuery con la herramienta de línea de comandos de bq, obtiene el resultado en JSON, luego contacta a otros servicios web para obtener más información que no se almacena en BigQuery, como los datos del usuario y las imágenes en miniatura de los libros. Entonces todo se mezcla y se presenta en el panel. Este es un buen patrón, ya que no querrás consultar BigQuery cada vez que se carga el panel, debido a que puede ser costoso. Es mejor hacer el trabajo analítico pesado con BigQuery, luego almacenar los resultados en algo parecido a una LAMP Stack barata para el consumo masivo. (Nota del editor: con BigQuery ahora se dispone de almacenamiento en caché de consultas, que maneja parte de esto automáticamente).
Inteligencia de ventas
Otro caso práctico por el que BigQuery fue excelente, fue en el rastreo de nuestros registros web en busca de clientes potenciales que llegaron a nuestro departamento de ventas. Esto nos permitió relacionar una ventaja con otras cuentas en nuestro sistema, o medir el nivel de interés que alguien pueda tener en nosotros por el número de libros de vista previa que habían leído en el último mes en nuestro sitio. El cliente potencial se crea en nuestro sistema de CRM y luego BigQuery busca de forma asíncrona en nuestros registros de la siguiente manera:
$query->setQuery("SELECT userid, COUNT(userid) AS countUserid FROM [backoffice.PageViews] WHERE remoteip='".$ip."' GROUP BY userid ORDER BY countUserid DESC LIMIT 20");
El resultado se muestra rápidamente y se vuelve a adjuntar al registro de clientes potenciales, lo que permite que nuestro departamento de ventas adquiera inteligencia y se comunique con el cliente potencial sin tener que esperar la información.
Esto nos da un buen resumen de los usuarios (o solicitudes anónimas) que ha hecho la dirección IP del cliente potencial. Si bien las direcciones IP no son identificadores perfectos, son mucho mejores que cualquier otra cosa.
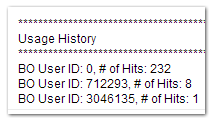
Puedes ver la dirección IP de algún cliente potencial que vio de forma anónima (ID de usuario 0) 232 páginas de nuestros libros, y algunos otros usuarios que tienen cuentas con nosotros ya están activos en esa IP.
En lugar de usar la interfaz de línea de comandos de BigQuery, este caso práctico se adaptaba mejor a OAuth de servidor a servidor con la biblioteca cliente de la API de Google para PHP. Esto nos permitió crear un servicio web que combina datos de diferentes fuentes y muestra el resultado a nuestro CRM. Una de esas fuentes es BigQuery. Un testimonio sorprendente de la velocidad de BigQuery es que ni siquiera tuve que implementar el servicio web de forma asíncrona. Los resultados de BigQuery se muestran dentro del tiempo de espera del servicio web que se solicita con CRM.
Ad-Hoc
Otros casos prácticos incluyen la consulta ad-hoc pura, que no está controlada por paneles, sino preguntas comerciales específicas.
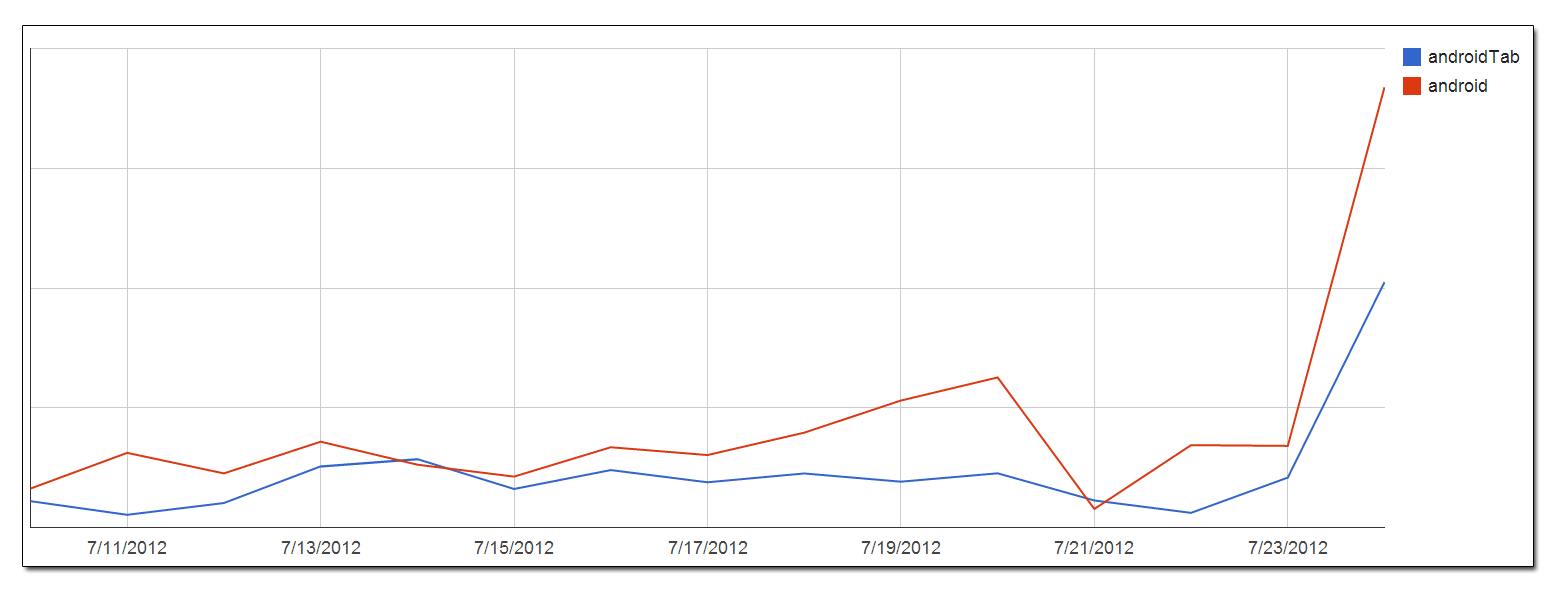
Cuando lanzamos nuestras aplicaciones de Android, fue fácil ejecutar una consulta en nuestros datos de uso para ver el uso de Android agrupado por día. En la herramienta navegador de BigQuery de Google, fue fácil exportar los resultados de la consulta como un archivo CSV y cargarlos en las Hojas de cálculo de Google para hacer un gráfico:
A continuación, se muestra un ejemplo de cómo ver a nuestros usuarios principales por número de búsquedas durante una hora particular del día:
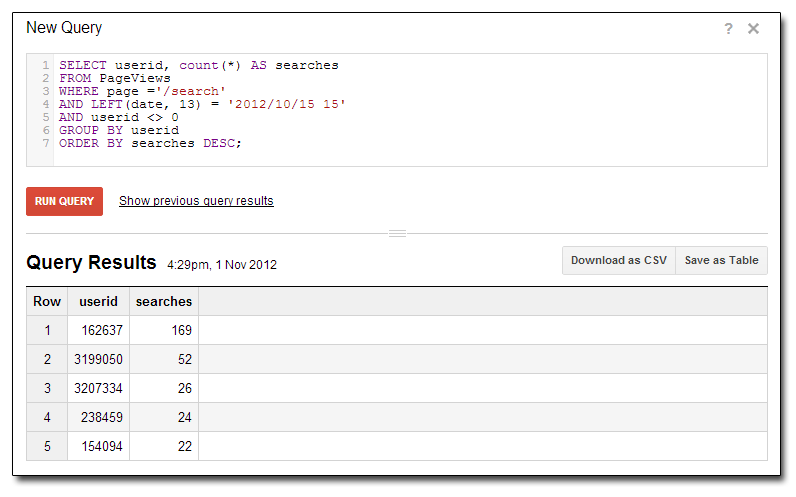
Realmente no hay límite para los tipos de información valiosa que puedes obtener investigando tus datos. Desde una perspectiva ad hoc, hay una gran sensación de poder responder a cualquier pregunta sobre tus miles de millones de filas de datos en segundos. Por ejemplo, puedes descubrir si ese tráfico extraño en tu sitio es un bot de spam del foro o un usuario malicioso.
Según lo recomendado por Google, hemos dividido nuestros datos por años:
Normalmente, sería un poco inconveniente tener que hacer una declaración de unión entre las tablas, pero BigQuery tiene un buen acceso directo para esto:
SELECT page
FROM PageViews2006, PageViews2007, PageViews2008
WHERE page CONTAINS('google')
GROUP BY page
Acabamos de juntar tantos años anteriores como necesitamos para ir a nuestras tablas fragmentadas por el tiempo y las uniremos, ya que hemos hecho lo mismo con nuestros esquemas. Al final de cada año, archivamos nuestra tabla "activa" y comenzamos una nueva. Este es el mejor de los dos mundos, ya que proporciona la accesibilidad de tener todos tus datos en una gran tabla con el rendimiento de tenerlos separados. A medida que crezcamos, tendrá sentido dividir aún más los datos en incrementos mensuales en lugar de anuales.
Resumen
Generar conocimiento significativo de grandes cantidades de datos de manera oportuna es un desafío que Safari Books Online, como muchos negocios, necesita resolver. Ser capaz de mantenerte al tanto de las tendencias a medida que suceden, mientras aún puedes hacer algo al respecto, en lugar de un mes después, es muy valioso. Esto conlleva a menores problemas de abuso y aumentos en los ingresos de primera línea recopilando información de mercadotecnia sobre temas de tendencias y recopilar información de clientes potenciales para cerrar ventas de manera más efectiva.
Futuro
Sentimos que solo estamos raspando la superficie de lo que es posible con BigQuery. Tener datos en una plataforma de alto rendimiento que puede consultarse es un gran recurso para nuestros proyectos planificados y para cualquier pregunta ad hoc no planificada que pueda surgir.