Questa pagina descrive come utilizzare AutoML Tables per addestrare un modello personalizzato basato sul set di dati. Devi aver già creato un set di dati e importato i dati al suo interno.
Introduzione
Puoi creare un modello personalizzato addestrandolo utilizzando un set di dati preparato. AutoML Tables utilizza gli elementi del set di dati per addestrare il modello, testarlo e valutarne le prestazioni. Puoi esaminare i risultati, regolare il set di dati di addestramento in base alle esigenze e addestrare un nuovo modello.
Durante la preparazione per l'addestramento di un modello, aggiorni le informazioni sullo schema del set di dati. Questi aggiornamenti dello schema influiscono su qualsiasi modello futuro che utilizza quel set di dati. I modelli già in fase di addestramento non sono interessati.
L'addestramento di un modello può richiedere diverse ore. Puoi verificare l'avanzamento dell'addestramento nella console Google Cloud o utilizzando l'API Cloud AutoML.
Poiché AutoML Tables crea un nuovo modello ogni volta che inizi l'addestramento, il progetto può includere numerosi modelli. Puoi ottenere un elenco dei modelli presenti nel tuo progetto e eliminare i modelli che non ti servono più.
I modelli devono essere riaddestrati ogni sei mesi per poter continuare a fornire previsioni.
Addestramento di un modello
Console
Se necessario, apri la pagina Set di dati e fai clic sul set di dati che vuoi utilizzare.
Il set di dati si apre nella scheda Addestra.
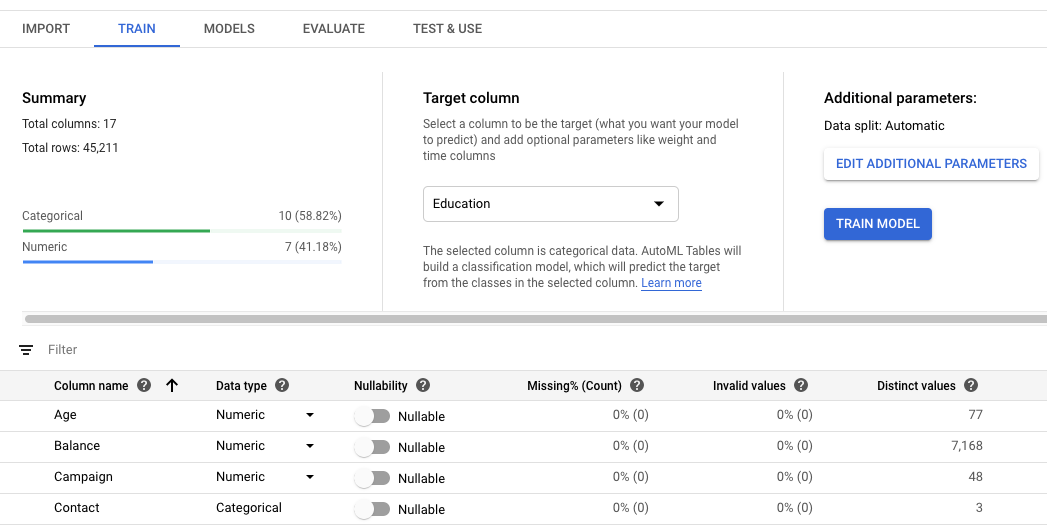
Seleziona la colonna di destinazione per il modello.
Si tratta del valore che il modello è addestrato a prevedere. Il tipo di dati determina se il modello risultante è di regressione (numerica) o di classificazione (categorica). Scopri di più.
Se il tipo di dati della colonna di destinazione è Categorical, deve avere un minimo di 2 e un massimo di 500 valori distinti.
Esamina Tipo di dati, Valore null e le statistiche dei dati per ogni colonna nel tuo set di dati.
Puoi fare clic sulle singole colonne per visualizzare ulteriori dettagli sulla colonna. Scopri di più sulla revisione dello schema.
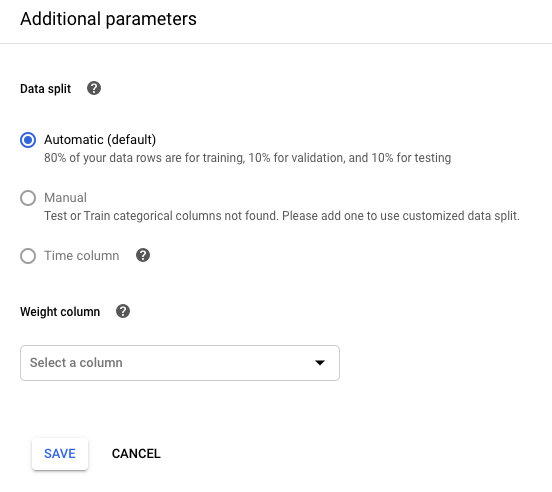
Se vuoi controllare la suddivisione dati, fai clic su Modifica parametri aggiuntivi e specifica una colonna di suddivisione dati o una colonna Tempo. Scopri di più.
Se vuoi ponderare gli esempi di addestramento in base al valore di una colonna, fai clic su Modifica parametri aggiuntivi e specifica la colonna appropriata. Scopri di più.
Esamina le statistiche e i dettagli riepilogativi per assicurarti che la qualità dei dati sia quella prevista e di aver identificato eventuali colonne che devono essere escluse quando crei il modello.
Per ulteriori informazioni, vedi Analisi dei dati di addestramento.
Quando lo schema del set di dati ti soddisfa, fai clic su Addestra modello nella parte superiore della schermata.
Quando apporti modifiche allo schema, AutoML Tables aggiorna le statistiche di riepilogo, il che può richiedere alcuni minuti. Non è necessario attendere il completamento di questo processo prima di iniziare l'addestramento del modello.
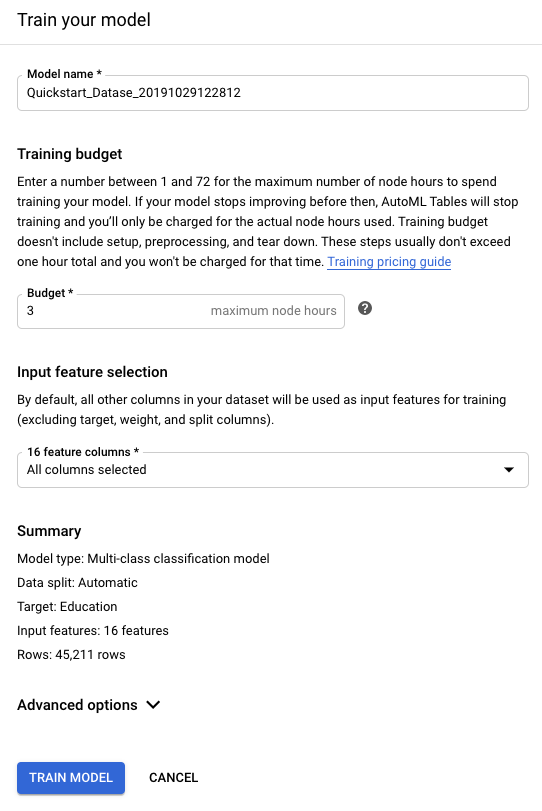
In Budget di addestramento, inserisci il numero massimo di ore di addestramento per questo modello.
Il budget per la formazione è compreso tra 1 e 72 ore. Questa è la quantità massima di tempo per l'addestramento che ti verrà addebitata.
Il tempo di addestramento suggerito dipende dalle dimensioni dei dati di addestramento. La tabella riportata di seguito mostra gli intervalli di tempo di addestramento suggeriti per numero di righe; anche un numero elevato di colonne aumenterà il tempo di addestramento.
Righe Tempo di addestramento suggerito Meno di 100.000 1-3 ore 100.000 - 1.000.000 1-6 ore 1.000.000 - 10.000.000 1-12 ore Più di 10.000.000 3-24 ore La creazione del modello include altre attività oltre all'addestramento, pertanto il tempo totale necessario per creare il modello è più lungo del tempo di addestramento. Ad esempio, se specifichi 2 ore di addestramento, potrebbero comunque essere necessarie 3 o più ore prima che il modello sia pronto per il deployment. Ti viene addebitato solo il tempo di addestramento effettivo.
Scopri di più sui prezzi dell'addestramento.
Se AutoML Tables rileva che il modello non migliora più prima che il budget di addestramento si esaurisca, l'addestramento viene interrotto. Se vuoi utilizzare l'intero tempo di addestramento previsto, apri Opzioni avanzate e disattiva Interruzione anticipata.
Nella sezione Selezione delle caratteristiche di input, escludi eventuali colonne scelte come target per l'esclusione nel passaggio di analisi dello schema.
Se non vuoi utilizzare l'obiettivo di ottimizzazione predefinito, apri Opzioni avanzate e seleziona la metrica per la quale vuoi ottimizzare AutoML Tables durante l'addestramento del modello. Scopri di più.
A seconda del tipo di dati della colonna di destinazione, potrebbe essere disponibile solo una scelta per l'obiettivo di ottimizzazione.
Fai clic su Addestra modello per iniziare l'addestramento del modello.
L'addestramento di un modello può richiedere diverse ore a seconda delle dimensioni del set di dati e del budget per l'addestramento. Puoi chiudere la finestra del browser senza influire sul processo di addestramento.
Una volta addestrato il modello, la scheda Modelli mostra metriche di alto livello, come precisione e richiamo.
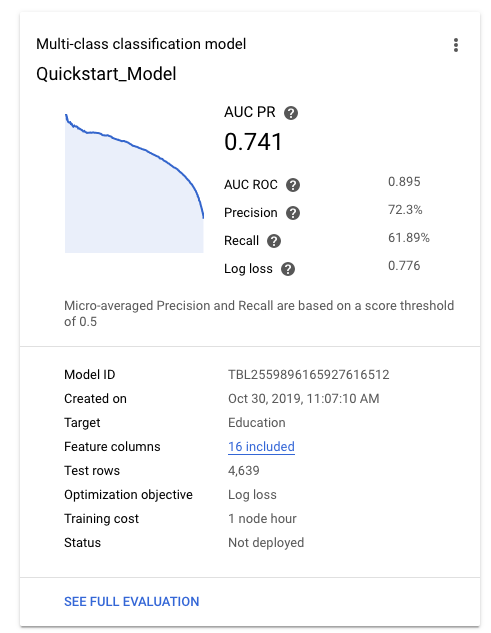
Per assistenza nella valutazione della qualità del modello, consulta Valutazione dei modelli.
REST
L'esempio seguente mostra come rivedere e aggiornare lo schema dei dati prima di addestrare il modello.
Se le tue risorse si trovano nella regione dell'UE, utilizza eu per {location}
e l'endpoint eu-automl.googleapis.com. In caso contrario, utilizza us-central1.
Scopri di più.
Al termine dell'importazione, elenca le specifiche della tabella per ottenere l'ID tabella.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione dell'UE. - project-id: il tuo ID progetto Google Cloud.
- location: la località per la risorsa:
us-central1per Globale oeuper l'Unione Europea. -
dataset-id: l'ID del set di dati. Ad esempio,
TBL6543.
Metodo HTTP e URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/
Per inviare la richiesta, espandi una di queste opzioni:
L'ID tabella è visualizzato in grassetto nel campo
name.-
endpoint:
Elenca le specifiche delle colonne.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione dell'UE. - project-id: il tuo ID progetto Google Cloud.
- location: la località per la risorsa:
us-central1per Globale oeuper l'Unione Europea. -
dataset-id: l'ID del set di dati. Ad esempio,
TBL6543. - table-id: l'ID della tabella.
Metodo HTTP e URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/
Per inviare la richiesta, espandi una di queste opzioni:
-
endpoint:
Se vuoi, configura la colonna di destinazione.
Si tratta del valore che il modello è addestrato a prevedere. Il tipo di dati determina se il modello risultante è di regressione (numerica) o di classificazione (categorica). Scopri di più.
Se il tipo di dati della colonna di destinazione è Categorical, deve avere un minimo di 2 e un massimo di 500 valori distinti.
Puoi anche specificare la colonna di destinazione quando addestra il modello. Se prevedi di farlo, conserva l'ID tabella e l'ID colonna di destinazione che preferisci per un utilizzo futuro.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione dell'UE. - project-id: il tuo ID progetto Google Cloud.
- location: la località per la risorsa:
us-central1per Globale oeuper l'Unione Europea. - dataset-id: l'ID del set di dati.
- target-column-id: l'ID della colonna di destinazione.
Metodo HTTP e URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
Corpo JSON della richiesta:
{ "tablesDatasetMetadata": { "targetColumnSpecId": "target-column-id" } }Per inviare la richiesta, espandi una di queste opzioni:
-
endpoint:
(Facoltativo) Aggiorna il campo
mlUseColumnSpecIdper specificare la suddivisione dei dati e il campoweightColumnSpecIdper utilizzare una colonna di ponderazione.Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione dell'UE. - project-id: il tuo ID progetto Google Cloud.
- location: la località per la risorsa:
us-central1per Globale oeuper l'Unione Europea. - dataset-id: l'ID del set di dati.
- split-column-id: l'ID della colonna di destinazione.
- weight-column-id: l'ID della colonna di destinazione.
Metodo HTTP e URL:
PATCH https://endpoint/v1beta1/projects/project-id/locations/location/datasets/dataset-id
Corpo JSON della richiesta:
{ "tablesDatasetMetadata": { "mlUseColumnSpecId": "split-column-id", "weightColumnSpecId": "weight-column-id" } }Per inviare la richiesta, espandi una di queste opzioni:
-
endpoint:
Controlla le statistiche delle colonne per assicurarti che i valori di
dataTypesiano corretti e che le colonne abbiano il valore corretto pernullable.Se un campo è contrassegnato come non null, significa che non aveva valori null per il set di dati di addestramento. Assicurati che questo vale anche per i dati di previsione; se una colonna è contrassegnata come non null e non viene fornito un valore al momento della previsione, viene restituito un errore di previsione per quella riga.
Controlla la qualità dei dati.
Addestrare il modello.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione dell'UE. - project-id: il tuo ID progetto Google Cloud.
- location: la località per la risorsa:
us-central1per Globale oeuper l'Unione Europea. - dataset-id: l'ID del set di dati.
- table-id: l'ID tabella, utilizzato per impostare la colonna di destinazione.
- target-column-id: l'ID della colonna di destinazione.
- model-display-name: il nome visualizzato del nuovo modello.
-
optimization-objective con la metrica da ottimizzare (facoltativo).
Consulta Informazioni sugli obiettivi di ottimizzazione del modello.
-
train-budget-milli-node-hours con il numero di milliore di nodo per l'addestramento. Ad esempio, 1000 = 1 ora.
Il tempo di addestramento suggerito dipende dalle dimensioni dei dati di addestramento. La tabella riportata di seguito mostra gli intervalli di tempo di addestramento suggeriti per numero di righe; anche un numero elevato di colonne aumenterà il tempo di addestramento.
Righe Tempo di addestramento suggerito Meno di 100.000 1-3 ore 100.000 - 1.000.000 1-6 ore 1.000.000 - 10.000.000 1-12 ore Più di 10.000.000 3-24 ore La creazione del modello include altre attività oltre all'addestramento, pertanto il tempo totale necessario per creare il modello è più lungo del tempo di addestramento. Ad esempio, se specifichi 2 ore di addestramento, potrebbero comunque essere necessarie 3 o più ore prima che il modello sia pronto per il deployment. Ti viene addebitato solo il tempo di addestramento effettivo.
Scopri di più sui prezzi dell'addestramento.
Se AutoML Tables rileva che il modello non migliora più prima che il budget di addestramento si esaurisca, l'addestramento viene interrotto. Se vuoi utilizzare l'intero tempo di addestramento previsto, imposta la proprietà
disableEarlyStoppingsull'oggettotablesModelMetadatasutrue.
Metodo HTTP e URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/
Corpo JSON della richiesta:
{ "datasetId": "dataset-id", "displayName": "model-display-name", "tablesModelMetadata": { "trainBudgetMilliNodeHours": "train-budget-milli-node-hours", "optimizationObjective": "optimization-objective", "targetColumnSpec": { "name": "projects/project-id/locations/location/datasets/dataset-id/tableSpecs/table-id/columnSpecs/target-column-id" } }, }Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{ "name": "projects/292381/locations/us-central1/operations/TBL64984", "metadata": { "@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata", "createTime": "2019-12-30T22:12:03.014058Z", "updateTime": "2019-12-30T22:12:03.014058Z", "cancellable": true, "createModelDetails": { "modelDisplayName": "new_model1" }, "worksOn": [ "projects/292381/locations/us-central1/datasets/TBL3718" ], "state": "RUNNING" } }L'addestramento di un modello è un'operazione a lunga esecuzione. Puoi eseguire il polling dello stato dell'operazione o attendere il ritorno dell'operazione. Scopri di più.
-
endpoint:
Java
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Node.js
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Python
La libreria client per AutoML Tables include metodi Python aggiuntivi che semplificano l'utilizzo dell'API AutoML Tables. Questi metodi fanno riferimento a set di dati e modelli per nome anziché per ID. I nomi dei set di dati e dei modelli devono essere univoci. Per maggiori informazioni, consulta la documentazione di riferimento per i client.
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Revisione dello schema
AutoML Tables deduce il tipo di dati e se una colonna è nullo per ogni colonna in base al tipo di dati originale (se è stato importato da BigQuery) e ai valori nella colonna. Devi controllare ogni colonna e assicurarti che sia corretta.
Usa l'elenco seguente per esaminare lo schema:
I campi che contengono testo in formato libero devono essere Testo.
I campi di testo sono separati in token da UnicodeScriptTokenizer, con i singoli token utilizzati per l'addestramento del modello. UnicodeScriptTokenizer tokenizza il testo tramite spazi vuoti, separando al contempo la punteggiatura dal testo e da lingue diverse.
Se il valore di una colonna fa parte di un insieme finito di valori, probabilmente dovrebbe essere di categoria, indipendentemente dal tipo di dati utilizzati nel campo.
Ad esempio, potresti avere codici per i colori: 1 = rosso, 2 = giallo e così via. Assicurati che questo campo sia stato designato come Categorico.
Un'eccezione a queste indicazioni è il caso in cui la colonna contenga stringhe composte da più parole. In questo caso, devi impostarla come colonna di testo, anche se ha una cardinalità bassa. AutoML Tables tokenizza le colonne di testo e potrebbe essere in grado di ricavare gli indicatori di previsione dai singoli token o dal loro ordine.
Se un campo è contrassegnato come non null, significa che non aveva valori null per il set di dati di addestramento. Assicurati che questo vale anche per i dati di previsione; se una colonna è contrassegnata come non null e non viene fornito un valore al momento della previsione, viene restituito un errore di previsione per quella riga.
Analisi dei dati di addestramento
Se una colonna ha un'alta percentuale di valori mancanti, assicurati che sia previsto e non sia dovuto a un problema di raccolta dei dati.
Assicurati che il numero di valori non validi sia relativamente basso o pari a zero.
Qualsiasi riga contenente uno o più valori non validi viene automaticamente esclusa dall'utilizzo per l'addestramento del modello.
Se i valori distinti di una colonna di categoria si avvicinano al numero di righe (ad esempio superiore al 90%), la colonna non fornirà un segnale di addestramento sufficiente. Deve essere escluso dall'addestramento. Le colonne ID devono essere sempre escluse.
Se il valore Correlazione con il target di una colonna è elevato, assicurati che sia previsto e non sia un indicatore della perdita di dati target.
Se la colonna sarà disponibile quando richiedi previsioni, probabilmente è una caratteristica con un'elevata potenza esplicativa e può essere inclusa. Tuttavia, a volte le caratteristiche con un'alta correlazione provengono dal target o raccolte successivamente. Queste caratteristiche devono essere escluse dall'addestramento perché non sono disponibili al momento della previsione, perciò il modello è inutilizzabile in produzione.
La correlazione viene calcolata per le colonne categoriche, numeriche e timestamp utilizzando la V di CRM. Per le colonne numeriche, viene calcolata utilizzando i conteggi dei bucket generati a partire dai quantili.
Informazioni sugli obiettivi di ottimizzazione del modello
L'obiettivo dell'ottimizzazione influisce sulla modalità di addestramento del modello e, di conseguenza, sulle sue prestazioni in produzione. La tabella seguente fornisce alcuni dettagli sui tipi di problemi per i quali ciascun obiettivo è ideale:
| Obiettivo ottimizzazione | Tipo di problema | Valore API | Utilizza questo scopo se vuoi... |
|---|---|---|---|
| AUC ROC | Classificazione | MAXIMIZE_AU_ROC |
Distinguere tra le classi. Valore predefinito per la classificazione binaria. |
| Perdita logaritmica | Classificazione | MINIMIZE_LOG_LOSS |
Mantieni le probabilità di previsione il più precise possibile. Obiettivo supportato solo per la classificazione multiclasse. |
| AUC PR | Classificazione | MAXIMIZE_AU_PRC |
Ottimizza i risultati per le previsioni per la classe meno comune. |
| Precisione al richiamo | Classificazione | MAXIMIZE_PRECISION_AT_RECALL |
Ottimizza la precisione con un valore di richiamo specifico. |
| Richiamo alla precisione | Classificazione | MAXIMIZE_RECALL_AT_PRECISION |
Ottimizza il richiamo con un valore di precisione specifico. |
| RMSE | Regressione | MINIMIZE_RMSE |
Acquisisci valori estremi in modo accurato. |
| MAE | Regressione | MINIMIZE_MAE |
Visualizza i valori estremi come outlier con un minore impatto sul modello. |
| RMSLE | Regressione | MINIMIZE_RMSLE |
Penalizza l'errore sulla dimensione relativa anziché sul valore assoluto. Utile in particolar modo quando i valori previsti ed effettivi possono essere molto grandi. |
Passaggi successivi
- Esamina l'architettura del modello.
- Valuta il modello.
- Ottieni previsioni batch dal tuo modello.
- Ottieni previsioni online dal tuo modello.
- Esporta il modello.
- Scopri di più sull'utilizzo delle operazioni a lunga esecuzione.