Questa pagina descrive come utilizzare le metriche di valutazione per il modello dopo l'addestramento e fornisce alcuni suggerimenti di base su come potresti migliorarne le prestazioni.
Introduzione
Dopo aver addestrato un modello, AutoML Tables utilizza il set di dati di test per valutare la qualità e l'accuratezza del nuovo modello e fornisce un set aggregato di metriche di valutazione che indicano le prestazioni del modello nel set di dati di test.
L'utilizzo delle metriche di valutazione per determinare la qualità del modello dipende dalle esigenze aziendali e dal problema che il modello è addestrato a risolvere. Ad esempio, il costo per i falsi positivi potrebbe essere più alto rispetto ai falsi negativi o viceversa. Per i modelli di regressione, il delta tra previsione e risposta corretta è importante? Questo tipo di domande influisce sul modo in cui guarderai le metriche di valutazione del modello.
L'inclusione di una colonna del peso nei dati di addestramento non influisce sulle metriche di valutazione. I pesi vengono presi in considerazione solo durante la fase di addestramento.
Metriche di valutazione per i modelli di classificazione
I modelli di classificazione forniscono le seguenti metriche:
AUC PR: l'area sotto la curva di precisione-richiamo (PR). Questo valore va da zero a uno, dove un valore più elevato indica un modello di qualità superiore.
AUC ROC: l'area sotto la curva della caratteristica operativa del ricevitore (ROC). L'intervallo varia da zero a uno, dove un valore più elevato indica un modello di qualità superiore.
Accuratezza: la frazione di previsioni di classificazione prodotte dal modello che sono state corrette.
Perdita di log: entropia incrociata tra le previsioni del modello e i valori target. L'intervallo va da zero a infinito, dove un valore più basso indica un modello di qualità migliore.
Punteggio F1: la media armonica di precisione e richiamo. F1 è una metrica utile per trovare un equilibrio tra precisione e richiamo qualora esista una distribuzione non uniforme delle classi.
Precisione: la frazione di previsioni positive prodotte dal modello che sono state corrette. (le previsioni positive sono i falsi positivi e i veri positivi combinati).
Richiamo: la frazione di righe con questa etichetta che il modello ha previsto correttamente. Chiamato anche "Tasso di veri positivi".
Percentuale di falsi positivi: la frazione di righe che il modello prevede che siano l'etichetta target, ma che non lo sono (falso positivo).
Queste metriche vengono restituite per ogni valore distinto della colonna target. Per i modelli di classificazione multiclasse, queste metriche vengono calcolate in micro-media e vengono restituite come metriche di riepilogo. Per i modelli di classificazione binaria, vengono utilizzate le metriche per la classe di minoranza come metriche di riepilogo. Le metriche con media micro sono il valore previsto di ogni metrica su un campione casuale dal tuo set di dati.
Oltre alle metriche sopra riportate, AutoML Tables offre altri due modi per comprendere il modello di classificazione, la matrice di confusione e un grafico sull'importanza delle caratteristiche.
Matrice di confusione: aiuta a capire dove si verificano errori di classificazione (quali classi vengono "confuse" tra loro). Ogni riga rappresenta i dati empirici reali per un'etichetta specifica e ogni colonna mostra le etichette previste dal modello.
Le matrici di confusione sono fornite solo per i modelli di classificazione con 10 o meno valori per la colonna di destinazione.

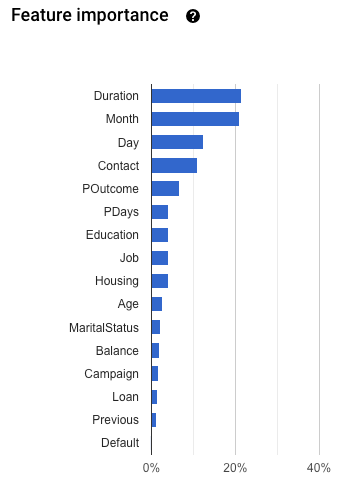
Importanza delle caratteristiche: AutoML Tables indica l'impatto di ogni caratteristica su questo modello. Viene visualizzata nel grafico Importanza delle caratteristiche. I valori vengono forniti come percentuale per ogni caratteristica: più alta è la percentuale, più la funzionalità ha influito sull'addestramento del modello.
Controlla queste informazioni per assicurarti che tutte le funzionalità più importanti siano pertinenti ai tuoi dati e al tuo problema aziendale. Scopri di più sulla spiegabilità.
Come viene calcolata la precisione micro-media
La precisione micro-media viene calcolata sommando il numero di veri positivi (TP) per ogni valore potenziale della colonna target e dividendolo per il numero di veri positivi (TP) e veri negativi (TN) per ogni valore potenziale.
\[ precisione_{micro} = \dfrac{TP_1 + \ldots + TP_n} {TP_1 + \ldots + TP_n + FP_1 + \ldots + FP_n} \]
dove
- \(TP_1 + \ldots + TP_n\) è la somma dei veri positivi per ciascuna di n classi
- \(FP_1 + \ldots + FP_n\) è la somma dei falsi positivi per ciascuna di n classi
Soglia punteggio
La soglia di punteggio è un numero che va da 0 a 1. Consente di specificare il livello di confidenza minimo in cui un determinato valore di previsione deve essere considerato vero. Ad esempio, se è improbabile che una classe sia il valore effettivo, ti consigliamo di abbassarne la soglia; l'utilizzo di una soglia pari o superiore a 0,5 potrebbe comportare la previsione della classe molto raramente (o mai).
Una soglia più alta diminuisce i falsi positivi, a scapito di altri falsi negativi. Una soglia più bassa diminuisce i falsi negativi a scapito di altri falsi positivi.
In altre parole, la soglia del punteggio incide sulla precisione e sul richiamo. Una soglia più alta comporta un aumento della precisione (perché il modello non esegue mai una previsione, a meno che non sia estremamente sicura), mentre il richiamo (la percentuale di esempi positivi che il modello recupera correttamente) diminuisce.
Metriche di valutazione per i modelli di regressione
I modelli di regressione forniscono le seguenti metriche:
MAE: l'errore medio assoluto (MAE) è la differenza media assoluta tra i valori target e i valori previsti. Questa metrica va da zero a infinito; un valore più basso indica un modello di qualità migliore.
RMSE: la metrica dell'errore quadratico medio è una misura utilizzata di frequente delle differenze tra i valori previsti da un modello o uno strumento di stima e i valori osservati. Questa metrica va da zero a infinito; un valore più basso indica un modello di qualità migliore.
RMSLE: la metrica dell'errore logaritmico del quadrato medio della radice è simile all'errore logaritmico RMSE, tranne per il fatto che utilizza il logaritmo naturale dei valori previsti ed effettivi più 1. L'RMSLE penalizza maggiormente le sottoprevisioni rispetto alle sovrastime. Può essere una buona metrica anche quando non vuoi penalizzare in modo più pesante le differenze per valori di previsione grandi rispetto a quelli per valori di previsione piccoli. Questa metrica va da zero a infinito; un valore più basso indica un modello di qualità migliore. La metrica di valutazione RMSLE viene restituita solo se tutte le etichette e i valori previsti non sono negativi.
r^2: r al quadrato (r^2) è il quadrato del coefficiente di correlazione Pearson tra le etichette e i valori previsti. Questa metrica va da zero a uno; un valore più elevato indica un modello di qualità migliore.
MAPE: l'errore percentuale assoluto medio (MAPE) è la differenza percentuale media assoluta tra le etichette e i valori previsti. Questa metrica va da zero a infinito; un valore più basso indica un modello di qualità migliore.
Se la colonna di destinazione non contiene nessun valore, il MAPE non viene mostrato. In questo caso, il MAPE non è definito.
Importanza delle caratteristiche: AutoML Tables indica l'impatto di ogni caratteristica su questo modello. Viene visualizzata nel grafico Importanza delle caratteristiche. I valori vengono forniti come percentuale per ogni caratteristica: più alta è la percentuale, più la funzionalità ha influito sull'addestramento del modello.
Controlla queste informazioni per assicurarti che tutte le funzionalità più importanti siano pertinenti ai tuoi dati e al tuo problema aziendale. Scopri di più sulla spiegabilità.
Recupero delle metriche di valutazione per il tuo modello
Per valutare i risultati del modello sul set di dati di test, ispezioni le metriche di valutazione del modello.
Console
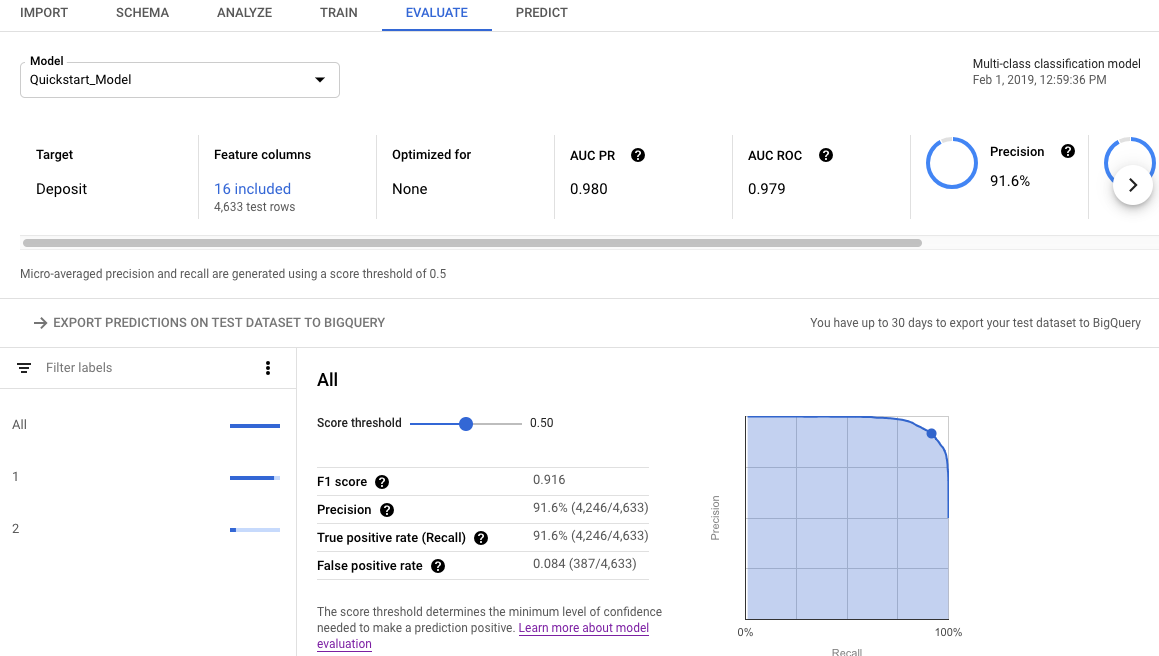
Per visualizzare le metriche di valutazione del modello utilizzando la console Google Cloud:
Vai alla pagina AutoML Tables nella console Google Cloud.
Seleziona la scheda Modelli nel riquadro di navigazione a sinistra, poi seleziona il modello per cui vuoi visualizzare le metriche di valutazione.
Apri la scheda Valuta.
Le metriche di valutazione riepilogative vengono visualizzate nella parte superiore dello schermo. Per i modelli di classificazione binaria, le metriche di riepilogo sono quelle della classe minoritaria. Per i modelli di classificazione multiclasse, le metriche di riepilogo sono le metriche micro-media.
Per le metriche di classificazione, puoi fare clic sui singoli valori target per visualizzare le metriche relative a quel valore.
REST
Per ottenere metriche di valutazione per il modello utilizzando l'API Cloud AutoML, utilizza il metodo modelEvaluations.list.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
-
endpoint:
automl.googleapis.comper la località globale eeu-automl.googleapis.comper la regione dell'UE. - project-id: il tuo ID progetto Google Cloud.
- location: la località per la risorsa:
us-central1per Globale oeuper l'Unione Europea. -
model-id: l'ID del modello da valutare. Ad esempio,
TBL543.
Metodo HTTP e URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/
Per inviare la richiesta, scegli una delle seguenti opzioni:
arricciatura
Esegui questo comando:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/"
PowerShell
Esegui questo comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/" | Select-Object -Expand Content
Java
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Node.js
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Python
La libreria client per AutoML Tables include metodi Python aggiuntivi che semplificano l'utilizzo dell'API AutoML Tables. Questi metodi fanno riferimento a set di dati e modelli per nome anziché per ID. I nomi dei set di dati e dei modelli devono essere univoci. Per maggiori informazioni, consulta la documentazione di riferimento per i client.
Se le risorse si trovano nella regione dell'UE, devi impostare esplicitamente l'endpoint. Scopri di più.
Comprensione dei risultati della valutazione mediante l'API
Quando utilizzi l'API Cloud AutoML per ottenere le metriche di valutazione dei modelli, viene restituita una grande quantità di informazioni. Comprendere come sono strutturati i risultati delle metriche può aiutarti a interpretarli e utilizzarli per valutare il tuo modello.
Risultati della classificazione
Per un modello di classificazione, i risultati includono più oggetti ModelEvaluation, ognuno dei quali contiene più oggetti ConfidenceMetricsEntry. Comprendere come sono strutturati i risultati ti aiuta a scegliere gli oggetti corretti da utilizzare durante la valutazione del modello.
Vengono restituiti due oggetti ModelEvaluation per ogni valore distinto della colonna di destinazione presente nei dati di addestramento. Inoltre, sono presenti due oggetti ModelEvaluation di riepilogo e un oggetto ModelEvaluation vuoto che può essere ignorato.
I due oggetti ModelEvaluation restituiti per uno specifico valore di etichetta mostrano il valore dell'etichetta nel campo displayName. Ognuna utilizza diversi valori di soglia di posizione: uno e MAX_INT (il numero più alto possibile). La soglia della posizione determina il numero di risultati considerati per una previsione.
Per un problema di classificazione, l'utilizzo di una soglia di posizione pari a uno è spesso la soluzione più adatta, perché viene scelta una sola etichetta per ogni input. Per problemi con più etichette, è possibile scegliere più di un'etichetta per input, quindi le metriche di valutazione restituite per la soglia di posizione MAX_INT potrebbero essere più utili. Dovresti determinare quali metriche utilizzare in base al caso d'uso specifico del tuo modello.
I due oggetti ModelEvaluation di riepilogo non includono il campo displayName, tranne che nella matrice di confusione. Inoltre, il valore del campo evaluatedExampleCount corrisponde al numero totale di righe nei dati di addestramento.
Per i modelli di classificazione multiclasse, gli oggetti di riepilogo forniscono le metriche di micro-media basate su tutte le metriche per etichetta.
Per i modelli di classificazione binaria, le metriche per la classe di minoranza vengono utilizzate come metriche di riepilogo. Utilizza l'oggetto ModelEvaluation con una soglia di posizione
per le metriche di riepilogo.
Ogni oggetto ModelEvaluation contiene fino a 100 oggetti ConfidenceMetricsEntry, a seconda dei dati di addestramento. Ogni oggetto ConfidenceMetricsEntry fornisce un valore diverso per la soglia di affidabilità (detta anche soglia del punteggio).
Gli oggetti Summary ModelEvaluation sono simili all'esempio riportato di seguito. Tieni presente che l'ordine di visualizzazione dei campi può variare.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/18011"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 1013
classification_evaluation_metrics {
au_roc: 0.99749845
log_loss: 0.01784837
au_prc: 0.99498594
confidence_metrics_entry {
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
confidence_metrics_entry {
confidence_threshold: 0.0149591835
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
...
confusion_matrix {
row {
example_count: 519
example_count: 2
example_count: 0
}
row {
example_count: 3
example_count: 75
example_count: 0
}
row {
example_count: 0
example_count: 0
example_count: 414
}
display_name: "RED"
display_name: "BLUE"
display_name: "GREEN"
}
}
}
Gli oggetti ModelEvaluation specifici delle etichette sono simili all'esempio riportato di seguito. Tieni presente che l'ordine di visualizzazione dei campi può variare.
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/21860"
annotation_spec_id: "not available"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 521
classification_evaluation_metrics {
au_prc: 0.99933827
au_roc: 0.99889404
log_loss: 0.014250426
confidence_metrics_entry {
recall: 1.0
precision: 0.51431394
f1_score: 0.6792699
false_positive_rate: 1.0
true_positive_count: 521
false_positive_count: 492
position_threshold: 2147483647
}
confidence_metrics_entry {
confidence_threshold: 0.10562216
recall: 0.9980806
precision: 0.9904762
f1_score: 0.9942639
false_positive_rate: 0.010162601
true_positive_count: 520
false_positive_count: 5
false_negative_count: 1
true_negative_count: 487
position_threshold: 2147483647
}
...
}
display_name: "RED"
}
Risultati della regressione
Per un modello di regressione, dovresti vedere un output simile al seguente esempio:
{
"modelEvaluation": [
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/68066093",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418
},
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/852167724",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418,
"regressionEvaluationMetrics": {
"rootMeanSquaredError": 1.9845301,
"meanAbsoluteError": 1.48482,
"meanAbsolutePercentageError": 15.155516,
"rSquared": 0.6057632,
"rootMeanSquaredLogError": 0.16848126
}
}
]
}
Risoluzione dei problemi relativi ai modelli
Le metriche di valutazione del modello dovrebbero essere buone, ma non perfette. Scarse prestazioni del modello e prestazioni del modello perfette sono entrambi indicatori che si è verificato un problema durante il processo di addestramento.
Scarso rendimento
Se il tuo modello non produce le prestazioni desiderate, ecco alcune cose da provare.
Esamina lo schema.
Assicurati che tutte le colonne siano del tipo corretto e di aver escluso l'addestramento di colonne non predittive, ad esempio le colonne ID.
Rivedi i tuoi dati
Valori mancanti nelle colonne che non supportano valori null causano questa riga che viene ignorata. Assicurati che i dati non contengano troppi errori.
Esporta il set di dati di test ed esaminalo.
Esaminando i dati e analizzando quando il modello effettua previsioni errate, potresti determinare che hai bisogno di più dati di addestramento per un determinato risultato o che i dati di addestramento hanno introdotto perdite.
Aumentare la quantità di dati di addestramento.
Se non disponi di dati di addestramento sufficienti, la qualità del modello ne risenti. Assicurati che i dati di addestramento siano il più imparziali possibile.
Aumenta il tempo di addestramento
Se l'addestramento fosse breve, potresti ottenere un modello di qualità superiore consentendogli di eseguire l'addestramento per un periodo di tempo più lungo.
Prestazioni perfette
Se il modello ha restituito metriche di valutazione quasi perfette, potrebbe esserci qualcosa che non ha funzionato nei dati di addestramento. Ecco alcune cose da cercare:
Perdita target
La perdita di destinazione si verifica quando una caratteristica è inclusa nei dati di addestramento che non possono essere noti al momento dell'addestramento e che sono basati sul risultato. Ad esempio, se hai incluso un numero di acquirente abituale per un modello addestrato a decidere se un nuovo utente effettuerà un acquisto, quel modello avrà metriche di valutazione molto elevate, ma avrà un rendimento scarso sui dati reali, perché non è stato possibile includere il numero di acquirente abituale.
Per verificare la presenza di perdite target, esamina il grafico Importanza delle caratteristiche nella scheda Valuta per il modello. Assicurati che le colonne con un'elevata importanza siano effettivamente predittive e non perdano informazioni sul target.
Colonna Data/Ora
Se l'ora dei dati è importante, assicurati di aver utilizzato una colonna Tempo o una suddivisione manuale in base al tempo. In caso contrario, le tue metriche di valutazione potrebbero alterarsi. Scopri di più.
Download del set di dati di test in BigQuery
Puoi scaricare il set di dati di test, inclusa la colonna di destinazione, insieme al risultato del modello per ogni riga. L'ispezione delle righe errate può fornire indizi su come migliorarlo.
Apri AutoML Tables nella console Google Cloud.
Seleziona Modelli nel riquadro di navigazione a sinistra e fai clic sul modello.
Apri la scheda Valuta e fai clic su Esporta le previsioni sul set di dati di test in BigQuery.
Al termine dell'esportazione, fai clic su Visualizza i risultati delle valutazioni in BigQuery per visualizzare i dati.
Passaggi successivi
- Esegui il deployment del modello per ricevere previsioni online.
- Ricevi previsioni batch dal modello.